Acompanhar os experimentos de ML do Azure Synapse Analytics com MLflow e o Azure Machine Learning
Neste artigo, saiba como habilitar o MLflow para se conectar ao Azure Machine Learning enquanto trabalha em um workspace do Azure Synapse Analytics. Você pode aproveitar essa configuração para acompanhamento, gerenciamento de modelos e implantação de modelo.
O MLflow é uma biblioteca de open-source para gerenciar o ciclo de vida dos experimentos de aprendizado de máquina. MLFlow Tracking é um componente do MLflow que registra e rastreia suas métricas de execução de treinamento e artefatos do modelo. Saiba mais sobre MLflow.
Se você tiver um Projeto do MLflow para treinar com Azure Machine Learning, confira Treinar modelos de ML com os Projetos do MLflow e o Azure Machine Learning (versão prévia).
Pré-requisitos
Instalar bibliotecas
Para instalar bibliotecas em seu cluster dedicado no Azure Synapse Analytics:
Crie um arquivo
requirements.txtcom os pacotes necessários para seus experimentos, mas verifique se ele também inclui os seguintes pacotes:requirements.txt
mlflow azureml-mlflow azure-ai-mlNavegue até o portal do Workspace do Azure Analytics.
Navegue até a guia Gerenciar e selecione Pools do Apache Spark.
Clique nos três pontos ao lado do nome do cluster e selecione Pacotes.
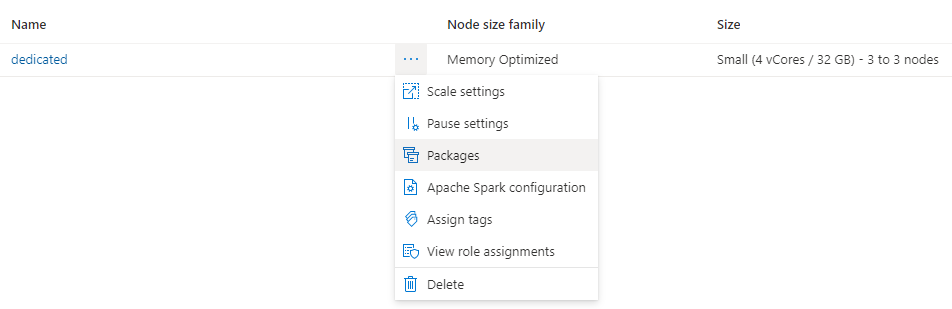
Na seção Arquivos de requisitos, clique em Carregar.
Carregue o arquivo
requirements.txt.Aguarde a reinicialização do cluster.
Acompanhar experimentos com o MLflow
O Azure Synapse Analytics pode ser configurado para acompanhar experimentos usando o MLflow para o workspace do Azure Machine Learning. O Azure Machine Learning fornece um repositório centralizado para gerenciar todo o ciclo de vida de experimentos, modelos e implantações. Ele também tem a vantagem de habilitar o caminho mais fácil para a implantação usando opções de implantação do Azure Machine Learning.
Configurando seus notebooks para usar o MLflow conectado ao Azure Machine Learning
Para usar o Azure Machine Learning como repositório centralizado para experimentos, você pode aproveitar o MLflow. Em cada notebook em que está trabalhando, você precisa configurar o URI de acompanhamento para apontar para o workspace que você usará. Este exemplo mostra como isso pode ser feito:
Configurar o URI de acompanhamento
Obtenha o URI de acompanhamento para seu workspace:
APLICA-SE A:
 Extensão de ML da CLI do Azurev2 (atual)
Extensão de ML da CLI do Azurev2 (atual)Faça logon e configure o seu workspace:
az account set --subscription <subscription> az configure --defaults workspace=<workspace> group=<resource-group> location=<location>Você pode obter o URI de acompanhamento usando o comando
az ml workspace:az ml workspace show --query mlflow_tracking_uri
Ao configurar o URI de acompanhamento:
Em seguida, o método
set_tracking_uri()aponta o URI de acompanhamento de MLflow para esse URI.import mlflow mlflow.set_tracking_uri(mlflow_tracking_uri)Dica
Ao trabalhar em ambientes compartilhados, como um cluster do Azure Databricks, um cluster do Azure Synapse Analytics ou semelhante, é útil definir a variável de ambiente
MLFLOW_TRACKING_URIno nível do cluster para configurar automaticamente o URI de acompanhamento do MLflow para apontar para o Azure Machine Learning para todas as sessões em execução no cluster, em vez de fazê-lo por sessão.
Configurar autenticação
Após configurar o acompanhamento, você também precisará configurar como a autenticação precisa acontecer com o workspace associado. Por padrão, o plug-in do Azure Machine Learning para MLflow executará a autenticação interativa abrindo o navegador padrão para solicitar credenciais. Consulte Configurar o MLflow para o Azure Machine Learning: configurar a autenticação para conhecer outras maneiras de configurar a autenticação para o MLflow em workspaces do Azure Machine Learning.
Para trabalhos interativos em que há um usuário conectado à sessão, você pode contar com a Autenticação Interativa e, portanto, nenhuma ação adicional é necessária.
Aviso
A autenticação por navegador interativo bloqueia a execução do código quando solicita credenciais. Essa abordagem não é adequada para autenticação em ambientes não assistidos, como trabalhos de treinamento. Recomendamos que você configure um modo de autenticação diferente.
Para cenários em que a execução não assistida é necessária, você precisa configurar uma entidade de serviço para se comunicar com o Azure Machine Learning.
import os
os.environ["AZURE_TENANT_ID"] = "<AZURE_TENANT_ID>"
os.environ["AZURE_CLIENT_ID"] = "<AZURE_CLIENT_ID>"
os.environ["AZURE_CLIENT_SECRET"] = "<AZURE_CLIENT_SECRET>"
Dica
Ao trabalhar em ambientes compartilhados, recomendamos que você configure essas variáveis de ambiente na computação. Como melhor prática, gerencie-os como segredos em uma instância do Azure Key Vault.
Por exemplo, no Azure Databricks, você pode usar segredos em variáveis de ambiente da seguinte maneira na configuração do cluster: AZURE_CLIENT_SECRET={{secrets/<scope-name>/<secret-name>}}. Para obter mais informações sobre como implementar essa abordagem no Azure Databricks, confira Referenciar um segredo em uma variável de ambiente ou consulte a documentação da sua plataforma.
Nomes do experimento no Azure Machine Learning
Por padrão, o Azure Machine Learning acompanha as execuções em um experimento padrão chamado Default. Geralmente, é uma boa ideia definir o experimento em que você vai trabalhar. Use a seguinte sintaxe para definir o nome do experimento:
mlflow.set_experiment(experiment_name="experiment-name")
Acompanhamento de parâmetros, métricas e artefatos
Você pode usar o MLflow no Azure Synapse Analytics da mesma maneira que está acostumado. Para obter detalhes, consulte Log e exibir arquivos de log e métricas.
Registrando modelos no registro com MLflow
Os modelos podem ser registrados no workspace do Azure Machine Learning, que oferece um repositório centralizado para gerenciar o ciclo de vida. O exemplo a seguir registra um modelo treinado com o Spark MLLib e também o grava no registro.
mlflow.spark.log_model(model,
artifact_path = "model",
registered_model_name = "model_name")
Se um modelo registrado com o nome não existir, o método registrará um novo modelo, criará a versão 1 e retornará um objeto ModelVersion MLflow.
Se um modelo registrado com o nome já existir, o método criará uma versão do modelo e retornará o objeto de versão.
Você pode gerenciar modelos registrados no Azure Machine Learning usando o MLflow. Confira Gerenciar registros de modelos no Azure Machine Learning com o MLflow para obter mais detalhes.
Implantando e consumindo modelos registrados em Azure Machine Learning
Os modelos registrados no serviço do Azure Machine Learning usando o MLflow podem ser consumidos como:
Um ponto de extremidade do Azure Machine Learning (em tempo real e lote): essa implantação permite que você aproveite recursos de implantação do Azure Machine Learning para inferência em tempo real e em lote no ACI (Instâncias de Contêiner do Azure), no AKS (Azure Kubernetes) ou em nossos pontos de extremidade gerenciados.
Objetos de modelo de MLFlow ou UDFs Pandas, que podem ser usados em notebooks do Azure Synapse Analytics em pipelines de streaming ou em lote.
Implantar modelos para ponto de extremidade do Azure Machine Learning
Você pode aproveitar o plugin azureml-mlflow para implantar um modelo em seu workspace do Azure Machine Learning. Confira Como implantar a página de modelos do MLflow para obter detalhes completos sobre como implantar modelos nos diferentes destinos.
Importante
Os modelos precisam ser registrados no registro Azure Machine Learning para implantá-los. Não há suporte para a implantação de modelos não registrados no Azure Machine Learning.
Implantar modelos para pontuação de lote usando UDFs
Você pode escolher clusters do Azure Synapse Analytics para pontuação de lote. O modelo do MLFlow é carregado e usado como um UDF do Spark Pandas para pontuar novos dados.
from pyspark.sql.types import ArrayType, FloatType
model_uri = "runs:/"+last_run_id+ {model_path}
#Create a Spark UDF for the MLFlow model
pyfunc_udf = mlflow.pyfunc.spark_udf(spark, model_uri)
#Load Scoring Data into Spark Dataframe
scoreDf = spark.table({table_name}).where({required_conditions})
#Make Prediction
preds = (scoreDf
.withColumn('target_column_name', pyfunc_udf('Input_column1', 'Input_column2', ' Input_column3', …))
)
display(preds)
Limpar recursos
Caso deseje manter o workspace do Azure Synapse Analytics, mas não precise mais do workspace do Azure Machine Learning, exclua o workspace do Azure Machine Learning. Se você não planeja usar as métricas registradas e os artefatos no workspace, a opção de excluí-los individualmente não fica disponível neste momento. Em vez disso, exclua o grupo de recursos que contém a conta de armazenamento e o workspace, para que você não incorra nenhum encargo:
No portal do Azure, selecione Grupos de recursos no canto esquerdo.
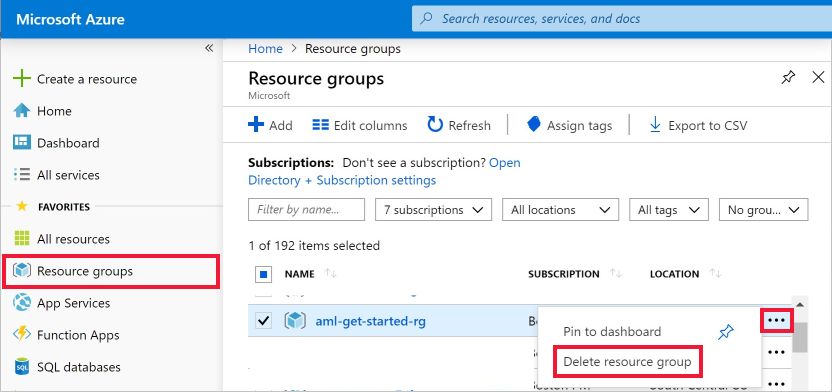
Selecione o grupo de recursos criado na lista.
Selecione Excluir grupo de recursos.
Insira o nome do grupo de recursos. Em seguida, selecione Excluir.