Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
APLICA-SE A: Azure Machine Learning SDK v1 para Python
Azure Machine Learning SDK v1 para Python
Importante
Este artigo fornece informações sobre como usar o SDK do Azure Machine Learning v1. O SDK v1 foi preterido a partir de 31 de março de 2025. O suporte para ele terminará em 30 de junho de 2026. Você pode instalar e usar o SDK v1 até essa data. Seus fluxos de trabalho existentes usando o SDK v1 continuarão a operar após a data de fim do suporte. No entanto, eles podem ficar expostos a riscos de segurança ou a alterações interruptivas em caso de mudanças na arquitetura do produto.
Recomendamos que você faça a transição para o SDK v2 antes de 30 de junho de 2026. Para obter mais informações sobre o SDK v2, consulte o que é a CLI do Azure Machine Learning e o SDK do Python v2? e a referência do SDK v2.
Neste artigo, você aprenderá a treinar um modelo de regressão com o SDK do Python do Azure Machine Learning usando o ML Automatizado do Azure Machine Learning. O modelo de regressão prevê tarifas de passageiros para táxis que operam em Nova York (NYC). Você escreve código com o SDK do Python para configurar um workspace com dados preparados, treinar o modelo localmente com parâmetros personalizados e explorar os resultados.
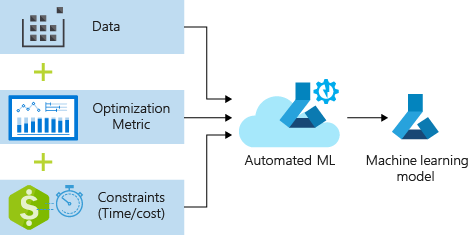
O processo aceita dados de treinamento e configurações. Ele itera automaticamente por meio de combinações de diferentes métodos de normalização/padronização de recursos, modelos e configurações de hiperparâmetro para chegar ao melhor modelo. O diagrama a seguir ilustra o fluxo de processo para o treinamento do modelo de regressão:
Pré-requisitos
Uma assinatura do Azure. Você pode criar uma conta gratuita ou paga do Azure Machine Learning.
Um workspace do Azure Machine Learning e uma instância de computação. Para preparar esses recursos, consulte Início Rápido: Introdução ao Azure Machine Learning.
Obtenha os dados de exemplo preparados para os exercícios do tutorial carregando um notebook em seu workspace:
Vá para o workspace no Estúdio do Azure Machine Learning, selecione Notebookse selecione a guia Exemplos.
Na lista de notebooks, expanda o nó Amostras>SDK v1>tutoriais>regression-automl-nyc-taxi-data.
Selecione o notebook regression-automated-ml.ipynb.
Para executar cada célula do notebook como parte deste tutorial, selecione Clonar este arquivo.
Abordagem alternativa: se preferir, você pode executar os exercícios do tutorial em um ambiente local. O tutorial está disponível no Repositório dos Notebooks do Azure Machine Learning Notebooks no GitHub. Para essa abordagem, siga essas etapas para obter os pacotes necessários:
Execute o comando
pip install azureml-opendatasets azureml-widgetsno computador local para obter os pacotes necessários.
Baixar e preparar dados
O pacote dos Conjunto de Dados em Aberto no Azure contém uma classe que representa cada fonte de dados (como NycTlcGreen) para filtrar facilmente os parâmetros de data antes de baixar.
O código a seguir importa os pacotes necessários:
from azureml.opendatasets import NycTlcGreen
import pandas as pd
from datetime import datetime
from dateutil.relativedelta import relativedelta
A primeira etapa é criar um dataframe para os dados de táxi. Quando você trabalha em um ambiente que não é do Spark, o pacote de Conjunto de Dados em Aberto Datasets permite baixar apenas um mês de dados por vez com determinadas classes. Essa abordagem ajuda a evitar o problema MemoryError que pode ocorrer com conjuntos de dados grandes.
Para baixar os dados de táxi, busque iterativamente um mês de cada vez. Antes de acrescentar o próximo conjunto de dados ao dataframegreen_taxi_df, crie amostras aleatórias de 2.000 registros de cada mês e, em seguida, pré-visualize os dados. Essa abordagem ajuda a evitar a sobrecarga do Dataframe.
O código a seguir cria o dataframe, busca os dados e os carrega no dataframe:
green_taxi_df = pd.DataFrame([])
start = datetime.strptime("1/1/2015","%m/%d/%Y")
end = datetime.strptime("1/31/2015","%m/%d/%Y")
for sample_month in range(12):
temp_df_green = NycTlcGreen(start + relativedelta(months=sample_month), end + relativedelta(months=sample_month)) \
.to_pandas_dataframe()
green_taxi_df = green_taxi_df.append(temp_df_green.sample(2000))
green_taxi_df.head(10)
A tabela a seguir mostra as muitas colunas de valores nos dados de táxi de exemplo:
| ID do fornecedor | lpepPickupDatetime | lpepDropoffDatetime | númeroDePassageiros | distância da viagem | puLocationId | doLocationId | pickupLongitude | pickupLatitude | dropoffLongitude | ... | tipo de pagamento | fareAmount | adicional | mtaTax | improvementSurcharge | tipAmount | valorPedágios | ehailFee | totalAmount | tipo de viagem |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 | 2015-01-30 18:38:09 | 2015-01-30 19:01:49 | 1 | 1.88 | Nenhum | Nenhum | -73.996155 | 40.690903 | -73.964287 | ... | 1 | 15,0 | 1,0 | 0,5 | 0,3 | 4,00 | 0,0 | Nenhum | 20.80 | 1,0 |
| 1 | 2015-01-17 23:21:39 | 2015-01-17 23:35:16 | 1 | 2.70 | Nenhum | Nenhum | -73.978508 | 40.687984 | -73.955116 | ... | 1 | 11.5 | 0,5 | 0,5 | 0,3 | 2.55 | 0,0 | Nenhum | 15.35 | 1,0 |
| 2 | 2015-01-16 01:38:40 | 2015-01-16 01:52:55 | 1 | 3,54 | Nenhum | Nenhum | -73.957787 | 40.721779 | -73.963005 | ... | 1 | 13.5 | 0,5 | 0,5 | 0,3 | 2,80 | 0,0 | Nenhum | 17.60 | 1,0 |
| 2 | 2015-01-04 17:09:26 | 2015-01-04 17:16:12 | 1 | 1.00 | Nenhum | Nenhum | -73.919914 | 40.826023 | -73.904839 | ... | 2 | 6.5 | 0,0 | 0,5 | 0,3 | 0,00 | 0,0 | Nenhum | 7.30 | 1,0 |
| 1 | 2015-01-14 10:10:57 | 2015-01-14 10:33:30 | 1 | 5.10 | Nenhum | Nenhum | -73.943710 | 40.825439 | -73.982964 | ... | 1 | 18,5 | 0,0 | 0,5 | 0,3 | 3.85 | 0,0 | Nenhum | 23.15 | 1,0 |
| 2 | 2015-01-19 18:10:41 | 2015-01-19 18:32:20 | 1 | 7.41 | Nenhum | Nenhum | -73.940918 | 40.839714 | -73.994339 | ... | 1 | 24.0 | 0,0 | 0,5 | 0,3 | 4,80 | 0,0 | Nenhum | 29,60 | 1,0 |
| 2 | 2015-01-01 15:44:21 | 2015-01-01 15:50:16 | 1 | 1,03 | Nenhum | Nenhum | -73.985718 | 40.685646 | -73.996773 | ... | 1 | 6.5 | 0,0 | 0,5 | 0,3 | 1.30 | 0,0 | Nenhum | 8.60 | 1,0 |
| 2 | 2015-01-12 08:01:21 | 2015-01-12 08:14:52 | 5 | 2.94 | Nenhum | Nenhum | -73.939865 | 40.789822 | -73.952957 | ... | 2 | 12.5 | 0,0 | 0,5 | 0,3 | 0,00 | 0,0 | Nenhum | 13:30 | 1,0 |
| 1 | 2015-01-16 21:54:26 | 2015-01-16 22:12:39 | 1 | 3,00 | Nenhum | Nenhum | -73.957939 | 40.721928 | -73.926247 | ... | 1 | 14.0 | 0,5 | 0,5 | 0,3 | 2,00 | 0,0 | Nenhum | 17:30 | 1,0 |
| 2 | 2015-01-06 06:34:53 | 2015-01-06 06:44:23 | 1 | 2.31 | Nenhum | Nenhum | -73.943825 | 40.810257 | -73.943062 | ... | 1 | 10.0 | 0,0 | 0,5 | 0,3 | 2,00 | 0,0 | Nenhum | 12,80 | 1,0 |
É útil remover algumas colunas que você não precisa para treinamento ou outra compilação de recursos. Por exemplo, você pode remover a coluna lpepPickupDatetime porque o ML Automatizado lida automaticamente com recursos baseados em tempo.
O código a seguir remove 14 colunas dos dados de exemplo:
columns_to_remove = ["lpepDropoffDatetime", "puLocationId", "doLocationId", "extra", "mtaTax",
"improvementSurcharge", "tollsAmount", "ehailFee", "tripType", "rateCodeID",
"storeAndFwdFlag", "paymentType", "fareAmount", "tipAmount"
]
for col in columns_to_remove:
green_taxi_df.pop(col)
green_taxi_df.head(5)
Limpar dados
A próxima etapa é limpar os dados.
O código a seguir executa a função describe() no novo dataframe para produzir estatísticas resumidas para cada campo:
green_taxi_df.describe()
A tabela a seguir mostra estatísticas resumidas dos campos restantes nos dados de exemplo:
| ID do fornecedor | númeroDePassageiros | distância da viagem | pickupLongitude | pickupLatitude | dropoffLongitude | dropoffLatitude | totalAmount | |
|---|---|---|---|---|---|---|---|---|
| contagem | 24.000,00 | 24.000,00 | 24.000,00 | 24.000,00 | 24.000,00 | 24.000,00 | 24.000,00 | 24.000,00 |
| média | 1.777625 | 1.373625 | 2,893981 | -73.827403 | 40.689730 | -73.819670 | 40.684436 | 14.892744 |
| std | 0.415850 | 1.046180 | 3.072343 | 2.821767 | 1.556082 | 2,901199 | 1.599776 | 12.339749 |
| mínimo | 1.00 | 0,00 | 0,00 | -74.357101 | 0,00 | -74.342766 | 0,00 | -120.80 |
| 25% | 2,00 | 1.00 | 1.05 | -73.959175 | 40.699127 | -73.966476 | 40.699459 | 8,00 |
| 50% | 2,00 | 1.00 | 1.93 | -73.945049 | 40.746754 | -73.944221 | 40.747536 | 11.30 |
| 75% | 2,00 | 1.00 | 3.70 | -73.917089 | 40.803060 | -73.909061 | 40.791526 | 17.80 |
| máximo | 2,00 | 8,00 | 154.28 | 0,00 | 41.109089 | 0,00 | 40.982826 | 425.00 |
As estatísticas de resumo revelam vários campos que são exceções, que são valores que reduzem a precisão do modelo. Para resolver esse problema, filtre os campos de latitude/longitude (lat/long) para que os valores estejam dentro dos limites da área de Manhattan. Isso filtra viagens de táxi mais longas ou viagens que são exceções no que diz respeito à sua relação com outros recursos.
Além disso, filtre o campo tripDistance para valores maiores que zero, mas menores que 50 km (a distância Haversine entre os dois pares lat/long). Isso elimina viagens mais longas que são exceção e que têm custo divergente.
Por fim, o campo totalAmount tem valores negativos para as tarifas de táxi, o que não faz sentido no contexto do modelo. O campo passengerCount também contém dados incorretos em que o valor mínimo é zero.
O código a seguir filtra essas anomalias de valor usando funções de consulta. Em seguida, o código remove as últimas colunas que não são necessárias para treinamento:
final_df = green_taxi_df.query("pickupLatitude>=40.53 and pickupLatitude<=40.88")
final_df = final_df.query("pickupLongitude>=-74.09 and pickupLongitude<=-73.72")
final_df = final_df.query("tripDistance>=0.25 and tripDistance<31")
final_df = final_df.query("passengerCount>0 and totalAmount>0")
columns_to_remove_for_training = ["pickupLongitude", "pickupLatitude", "dropoffLongitude", "dropoffLatitude"]
for col in columns_to_remove_for_training:
final_df.pop(col)
A última etapa nessa sequência é chamar a função describe() novamente nos dados para garantir que a limpeza funcione conforme o esperado. Agora você tem um conjunto preparado e limpo de dados de táxis, feriados e clima para usar no treinamento de modelo de machine learning:
final_df.describe()
Configurar o workspace
Crie um objeto de workspace a partir do workspace existente. Um Workspace é uma classe que aceita suas informações de recursos e assinatura do Azure. Ele também cria um recurso de nuvem para monitorar e acompanhar a execução do seu modelo.
O código a seguir chama a função Workspace.from_config() para ler o arquivo config.json e carregar os detalhes da autenticação em um objeto chamado ws.
from azureml.core.workspace import Workspace
ws = Workspace.from_config()
O objeto ws é usado em todo o restante do código neste tutorial.
Dividir os dados em conjuntos de treinamento e teste
Divida os dados em conjuntos de treinamento e teste usando a função train_test_split na biblioteca scikit-learn. Essa função separa os dados no conjunto de dados x (recursos) para treinamento do modelo e no conjunto de dados y (valores a serem previstos) para teste.
O parâmetro test_size determina a porcentagem de dados a ser alocada para teste. O parâmetro random_state define uma semente para o gerador aleatório, de modo que suas divisões de teste de treinamento sejam determinísticas.
O código a seguir chama a função train_test_split para carregar os conjuntos de dados x e y:
from sklearn.model_selection import train_test_split
x_train, x_test = train_test_split(final_df, test_size=0.2, random_state=223)
A finalidade desta etapa é preparar pontos de dados para testar o modelo concluído que não é usado para treinar o modelo. Esses pontos são usados para medir a precisão verdadeira. Um modelo bem treinado é aquele que pode fazer previsões precisas de dados não vistos. Agora, você tem dados preparados para treinar automaticamente um modelo de machine learning.
Treinar um modelo automaticamente
Para treinar o modelo automaticamente, execute as seguintes etapas:
Defina configurações para a execução do experimento. Anexe seus dados de treinamento à configuração e modifique as configurações que controlam o processo de treinamento.
Envie o experimento para ajuste do modelo. Depois de enviar o experimento, o processo itera diferentes algoritmos de aprendizado de máquina e configurações de hiperparâmetro, aderindo às restrições definidas. Ele escolhe o modelo mais adequado otimizando uma métrica de precisão.
Definir configurações de treinamento
Defina as configurações de modelos e os parâmetros do experimento para o treinamento. Exiba a lista completa das configurações. O envio do experimento com essas configurações padrão leva aproximadamente de 5 a 20 minutos. Para diminuir o tempo de execução, reduza o parâmetro experiment_timeout_hours.
| Propriedade | Valor neste tutorial | Descrição |
|---|---|---|
iteration_timeout_minutes |
10 | Limite de tempo em minutos para cada iteração. Aumente esse valor para conjuntos de dados maiores que precisam de mais tempo para cada iteração. |
experiment_timeout_hours |
0,3 | Quantidade máxima de tempo em horas que todas as iterações combinadas podem levar antes que o experimento seja encerrado. |
enable_early_stopping |
Verdadeiro | Sinalizador para permitir o encerramento antecipado se a pontuação não estiver melhorando em curto prazo. |
primary_metric |
correlação de Spearman | Métrica que você deseja otimizar. O modelo mais adequado é o escolhido com base nessa métrica. |
featurization |
automático | O valor automático permite que o experimento pré-processe os dados de entrada, incluindo o tratamento de dados ausentes, a conversão de texto em numérico e assim por diante. |
verbosity |
logging.INFO | Controla o nível de registro em log. |
n_cross_validations |
5 | Número de divisões de validação cruzada para executar quando os dados de validação não são especificados. |
O código a seguir envia o experimento:
import logging
automl_settings = {
"iteration_timeout_minutes": 10,
"experiment_timeout_hours": 0.3,
"enable_early_stopping": True,
"primary_metric": 'spearman_correlation',
"featurization": 'auto',
"verbosity": logging.INFO,
"n_cross_validations": 5
}
O código a seguir permite que você use as configurações de treinamento definidas como um parâmetro **kwargs para um objeto AutoMLConfig. Além disso, especifique os dados de treinamento e o tipo de modelo, que é regression, neste caso.
from azureml.train.automl import AutoMLConfig
automl_config = AutoMLConfig(task='regression',
debug_log='automated_ml_errors.log',
training_data=x_train,
label_column_name="totalAmount",
**automl_settings)
Observação
As etapas de pré-processamento do ML automatizado (normalização de recursos, manipulação de dados ausentes, conversão de texto em números etc.) tornam-se parte do modelo subjacente. Ao usar o modelo para previsões, as mesmas etapas de pré-processamento aplicadas durante o treinamento são aplicadas aos dados de entrada automaticamente.
Treinar o modelo de regressão automática
Criar um objeto de experimento em seu workspace. Um experimento atua como um contêiner para seus trabalhos individuais. Transmita o objeto automl_config definido para o experimento e defina a saída como Verdadeiro para exibir o andamento durante a execução.
Depois de iniciar o experimento, as atualizações de saída exibidas estão ativas à medida que o experimento é executado. Para cada iteração, você vê o tipo de modelo, a duração da execução e a precisão do treinamento. O campo BEST acompanha a melhor pontuação de treinamento em execução com base no tipo de métrica:
from azureml.core.experiment import Experiment
experiment = Experiment(ws, "Tutorial-NYCTaxi")
local_run = experiment.submit(automl_config, show_output=True)
Esta é a saída:
Running on local machine
Parent Run ID: AutoML_1766cdf7-56cf-4b28-a340-c4aeee15b12b
Current status: DatasetFeaturization. Beginning to featurize the dataset.
Current status: DatasetEvaluation. Gathering dataset statistics.
Current status: FeaturesGeneration. Generating features for the dataset.
Current status: DatasetFeaturizationCompleted. Completed featurizing the dataset.
Current status: DatasetCrossValidationSplit. Generating individually featurized CV splits.
Current status: ModelSelection. Beginning model selection.
****************************************************************************************************
ITERATION: The iteration being evaluated.
PIPELINE: A summary description of the pipeline being evaluated.
DURATION: Time taken for the current iteration.
METRIC: The result of computing score on the fitted pipeline.
BEST: The best observed score thus far.
****************************************************************************************************
ITERATION PIPELINE DURATION METRIC BEST
0 StandardScalerWrapper RandomForest 0:00:16 0.8746 0.8746
1 MinMaxScaler RandomForest 0:00:15 0.9468 0.9468
2 StandardScalerWrapper ExtremeRandomTrees 0:00:09 0.9303 0.9468
3 StandardScalerWrapper LightGBM 0:00:10 0.9424 0.9468
4 RobustScaler DecisionTree 0:00:09 0.9449 0.9468
5 StandardScalerWrapper LassoLars 0:00:09 0.9440 0.9468
6 StandardScalerWrapper LightGBM 0:00:10 0.9282 0.9468
7 StandardScalerWrapper RandomForest 0:00:12 0.8946 0.9468
8 StandardScalerWrapper LassoLars 0:00:16 0.9439 0.9468
9 MinMaxScaler ExtremeRandomTrees 0:00:35 0.9199 0.9468
10 RobustScaler ExtremeRandomTrees 0:00:19 0.9411 0.9468
11 StandardScalerWrapper ExtremeRandomTrees 0:00:13 0.9077 0.9468
12 StandardScalerWrapper LassoLars 0:00:15 0.9433 0.9468
13 MinMaxScaler ExtremeRandomTrees 0:00:14 0.9186 0.9468
14 RobustScaler RandomForest 0:00:10 0.8810 0.9468
15 StandardScalerWrapper LassoLars 0:00:55 0.9433 0.9468
16 StandardScalerWrapper ExtremeRandomTrees 0:00:13 0.9026 0.9468
17 StandardScalerWrapper RandomForest 0:00:13 0.9140 0.9468
18 VotingEnsemble 0:00:23 0.9471 0.9471
19 StackEnsemble 0:00:27 0.9463 0.9471
Explorar os resultados
Explore os resultados do treinamento automático com um widget do Jupyter. O widget permite que você veja um grafo e uma tabela de todas as iterações de trabalho individuais, em conjunto com metadados e métricas de precisão de treinamento. Além disso, você pode filtrar em métricas de precisão diferentes da métrica primária com o seletor de lista suspensa.
O código a seguir produz um grafo para explorar os resultados:
from azureml.widgets import RunDetails
RunDetails(local_run).show()
Os detalhes de execução do widget do Jupyter:

O gráfico de gráfico para o widget do Jupyter:

Recuperar o melhor modelo
O código a seguir permite que você selecione o melhor modelo em suas iterações. A função get_output retorna a melhor execução e o modelo ajustado para a última invocação de ajuste. Ao usar as sobrecargas na função get_output, você pode recuperar o modelo de melhor execução e ajuste para qualquer métrica registrada em log ou iteração em particular.
best_run, fitted_model = local_run.get_output()
print(best_run)
print(fitted_model)
Testar a melhor precisão do modelo
Use o melhor modelo para executar previsões no conjunto de dados de teste e prever as tarifas de táxi. A função predict usa o melhor modelo e prevê os valores de y, custo da corrida, do conjunto de dados x_test.
O código a seguir imprime os primeiros 10 valores de custo previstos do conjunto de dados y_predict:
y_test = x_test.pop("totalAmount")
y_predict = fitted_model.predict(x_test)
print(y_predict[:10])
Calcule o root mean squared error dos resultados. Converta o dataframe y_test em uma lista para comparar com os valores previstos. A função mean_squared_error usa duas matrizes de valores e calcula o erro médio ao quadrado entre elas. Usar a raiz quadrada do resultado gera um erro nas mesmas unidades que a variável y, custo. Indica aproximadamente o quão distantes as previsões das tarifas de táxi estão das tarifas reais.
from sklearn.metrics import mean_squared_error
from math import sqrt
y_actual = y_test.values.flatten().tolist()
rmse = sqrt(mean_squared_error(y_actual, y_predict))
rmse
Execute o código a seguir para calcular o MAPE (erro percentual absoluto médio) usando os conjuntos de dados y_actual e y_predict completos. Essa métrica calcula uma diferença absoluta entre cada valor previsto e real e somas todas as diferenças. Em seguida, expressa a soma como uma porcentagem do total de valores reais.
sum_actuals = sum_errors = 0
for actual_val, predict_val in zip(y_actual, y_predict):
abs_error = actual_val - predict_val
if abs_error < 0:
abs_error = abs_error * -1
sum_errors = sum_errors + abs_error
sum_actuals = sum_actuals + actual_val
mean_abs_percent_error = sum_errors / sum_actuals
print("Model MAPE:")
print(mean_abs_percent_error)
print()
print("Model Accuracy:")
print(1 - mean_abs_percent_error)
Esta é a saída:
Model MAPE:
0.14353867606052823
Model Accuracy:
0.8564613239394718
Nas duas métricas de precisão da previsão, você vê que o modelo é razoavelmente bom em prever as tarifas de táxi por meio dos recursos do conjunto de dados, normalmente dentro de +- $ 4,00 e com erro de aproximadamente 15%.
O processo tradicional de desenvolvimento de modelo de machine learning consome muitos recursos. Ele requer um investimento de tempo e conhecimento de domínio significativo para executar e comparar os resultados de dezenas de modelos. A utilização do machine learning automatizado é uma ótima maneira de testar rapidamente muitos modelos diferentes para seu cenário.
Limpar os recursos
Se você não planeja trabalhar em outros tutoriais do Azure Machine Learning, conclua as etapas a seguir para remover os recursos de que você não precisa mais.
Parar a computação
Se você usou uma computação, poderá parar a máquina virtual quando não a estiver usando e reduzir seus custos:
Acesse seu workspace no estúdio do Estúdio do Azure Machine Learning e selecione Computação.
Na lista, selecione a computação que você deseja parar e, em seguida, selecione Parar.
Quando estiver pronto para usar a computação novamente, você poderá reiniciar a máquina virtual.
Excluir outros recursos
Se você não planeja usar os recursos criados neste tutorial, poderá excluí-los e evitar incorrer em encargos adicionais.
Siga essas etapas para remover o grupo de recursos e todos os recursos:
No portal do Azure, acesse Grupo de recursos.
Na lista, selecione o grupo de recursos que você criou neste tutorial e selecione Excluir grupo de recursos.
Na página de confirmação, insira o nome do grupo de recursos e selecione Excluir.
Se você quiser manter o grupo de recursos e excluir apenas um único workspace, siga estas etapas:
No portal do Azure, vá para o grupo de recursos que contém o workspace que você deseja remover.
Selecione o workspace, selecione Propriedades e, em seguida, selecione Excluir.