Tutorial: Treinar um modelo de classificação com AutoML sem código no Estúdio do Azure Machine Learning
Neste tutorial, você aprenderá a treinar um modelo de classificação com machine learning automatizado sem código (AutoML) usando o Azure Machine Learning no estúdio do Azure Machine Learning. Esse modelo de classificação prevê se um cliente assina um depósito de prazo fixo com uma instituição financeira.
Com o ML automatizado, você pode automatizar tarefas intensivas e demoradas. O aprendizado de máquina automatizado itera rapidamente em muitas combinações de algoritmos e hiperparâmetros para ajudar você a encontrar o melhor modelo com base em uma métrica de sucesso de sua escolha.
Você não escreve nenhum código neste tutorial. Você usa a interface do estúdio para executar o treinamento. Você aprenderá a realizar as seguintes tarefas:
- Criar um workspace do Azure Machine Learning
- Executar um experimento de aprendizado de máquina automatizado
- Explore os detalhes do modelo
- Implante o modelo recomendado
Pré-requisitos
Uma assinatura do Azure. Se você não tiver uma assinatura do Azure, crie uma conta gratuita.
Baixe o arquivo de dados bankmarketing_train.csv. A coluna y indica se um cliente assinou um depósito a prazo fixo, que é posteriormente identificado como a coluna de destino para as previsões neste tutorial.
Observação
Esse conjunto de dados de marketing bancário é disponibilizado sob a licença Creative Commons (CCO: Domínio Público). Todos os direitos no conteúdo individual do banco de dados são licenciados sob a Licença de Conteúdo do Banco de Dados e estão disponíveis no Kaggle. Esse conjunto de dados estava originalmente disponível no banco de dados de aprendizado de máquina da UCI.
[Moro et al., 2014] S. Moro, P. Cortez and P. Rita. Uma abordagem controlada por dados para prever o sucesso do telemarketing bancário. Sistemas de suporte a decisões, Elsevier, 62:22-31, junho de 2014.
Criar um workspace
Um Workspace do Azure Machine Learning é o recurso fundamental na nuvem que você usa para experimentar, treinar e implantar modelos de machine learning. Ele vincula sua assinatura do Azure e o grupo de recursos a um objeto facilmente consumido no serviço.
Conclua as etapas a seguir para criar um workspace e continuar o tutorial.
Entre no Estúdio do Azure Machine Learning.
Selecione Criar workspace.
Forneça as informações a seguir para configurar o novo workspace:
Campo Descrição Nome do workspace Insira um nome único que identifique seu workspace. Os nomes devem ser únicos em todo o grupo de recursos. Use um nome que seja fácil de lembrar e diferenciar de workspaces criados por outras pessoas. O nome do workspace não diferencia maiúsculas de minúsculas. Subscription Selecione a assinatura do Azure que você deseja usar. Resource group Use um grupo de recursos existente na sua assinatura ou insira um nome para criar um grupo de recursos. Um grupo de recursos mantém os recursos relacionados a uma solução do Azure. Você precisa de um colaborador ou da função de proprietário para usar um grupo de recursos existente. Para obter mais informações, consulte Gerenciar acesso a um workspace do Azure Machine Learning. Region Selecione a região do Azure mais próxima aos usuários e recursos de dados para criar o workspace. Selecione Criar para criar o workspace.
Para obter mais informações sobre recursos do Azure, consulte Criar o workspace.
Para outras formas de criar um espaço de trabalho no Azure, Gerencie os espaços de trabalho do Azure Machine Learning no portal ou com o Python SDK (v2).
Criar um trabalho de Azure Machine Learning automatizado
Conclua as etapas de configuração e execução do teste a seguir usando o estúdio do Azure Machine Learning em https://ml.azure.com. O Machine Learning Studio é uma interface da Web consolidada que inclui ferramentas de aprendizado de máquina para executar cenários de ciência de dados para profissionais de ciência de dados de todos os níveis de habilidade. O estúdio não é compatível com navegadores Internet Explorer.
Selecione a assinatura e o workspace criado.
No painel de navegação, selecione Criação>de ML Automatizado.
Como este tutorial é seu primeiro experimento de ML automatizado, você verá uma lista vazia e links para a documentação.
Selecione Novo trabalho de ML automatizado.
Em Método de treinamento, selecione Treinar automaticamente e, em seguida selecione Iniciar a configuração do trabalho.
Nas Configurações básicas, selecione Criar novo e, em seguida para Nome do experimento, insira my-1st-automl-experiment.
Selecione Avançar para carregar seu conjunto de dados.

Crie e carregue um conjunto de dados como um ativo de dados
Antes de configurar seu experimento, carregue o arquivo de dados em seu espaço de trabalho na forma de um ativo de dados do Azure Machine Learning. Para este tutorial, você pode pensar em um ativo de dados como seu conjunto de dados para o trabalho de ML automatizado. Essa ação permite que você garanta que os dados estejam formatados corretamente para o experimento.
Em Tipos de tarefa &dados, para Selecionar tipo de tarefa, escolha Classificação.
Em Selecionar dados, escolha Criar.
No formulário de tipo de dados, dê um nome ao ativo de dados e forneça uma descrição opcional.
Para Tipo, selecione Tabular. Atualmente, a interface ML automatizada dá suporte apenas a TabularDatasets.
Selecione Avançar.
No formulário Fonte de dados, selecione De arquivos locais. Selecione Avançar.
No tipo de armazenamento de destino, selecione o armazenamento de dados padrão que foi configurado automaticamente durante a criação do workspace: workspaceblobstore. Você carrega seu arquivo de dados para esse local para disponibilizá-lo para seu workspace.
Selecione Avançar.
Em seleção de arquivo ou pasta, selecione Carregar arquivos ou pasta>Carregar arquivos.
Escolha o arquivo bankmarketing_train.csv no computador local. Você baixou esse arquivo como um pré-requisito.
Selecione Avançar.
Quando o upload é concluído, a área de visualização de dados é preenchida com base no tipo de arquivo.
No formulário Configurações, examine os valores de seus dados. Em seguida, selecione Avançar.
Campo Descrição Valor para o tutorial Formato de arquivo Define o layout e o tipo de dados armazenados em um arquivo. Delimitado Delimitador Um ou mais caracteres para especificar o limite entre regiões separadas e independentes em texto sem formatação ou outros fluxos de dados. Vírgula Codificação Identifica qual tabela de esquema de bit para caractere usar para ler seu conjunto de dados. UTF-8 Cabeçalhos de coluna Indica como os cabeçalhos do conjunto de dados, se houver, são tratados. Todos os arquivos têm os mesmos cabeçalhos Ignorar linhas Indica quantas linhas, se houver, serão ignoradas no conjunto de registros. Nenhum O formulário Esquema permite configurar ainda mais os dados do experimento. Neste exemplo, selecione o botão de alternância day_of_week para que ele não seja incluído. Selecione Avançar.
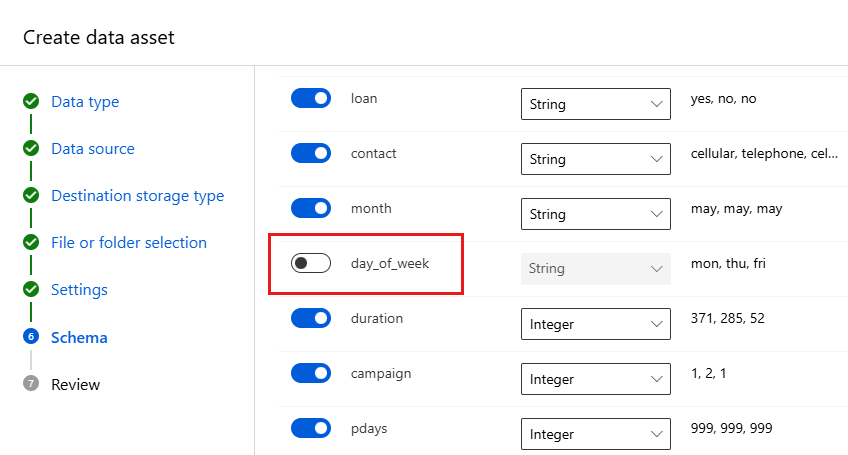
No formulário Revisão, verifique suas informações e selecione Criar.
Selecione seu conjunto de dados na lista.
Examine os dados selecionando o ativo de dados e examinando a guia visualização. Verifique se ele não inclui day_of_week e selecione Fechar.
Selecione Avançar para prosseguir para as configurações de tarefa.
Configurar trabalho
Depois de carregar e configurar seus dados, você poderá configurar seu experimento. Essa configuração inclui tarefas de design de experimento, como selecionar o tamanho do seu ambiente de computação e especificar qual coluna você deseja prever.
Preencha o formulário de Configurações da tarefa da seguinte forma:
Selecione y (Cadeia de caracteres) como a coluna de destino, que é o que você deseja prever. Essa coluna indica se o cliente assinou um depósito a prazo ou não.
Selecione Exibir definições de configuração adicionais e preencha os campos da seguinte maneira. Essas configurações destinam-se a controlar melhor o trabalho de treinamento. Caso contrário, os padrões são aplicados com base na seleção e nos dados de experimento.
Configurações adicionais Descrição Valor para o tutorial Métrica principal Métrica de avaliação usada para medir o algoritmo de aprendizado de máquina. AUCWeighted Explicar o melhor modelo Mostra automaticamente a explicabilidade no melhor modelo criado pelo ML automatizado. Habilitar Modelos bloqueados Algoritmos que você deseja excluir do trabalho de treinamento Nenhum Selecione Salvar.
Em Validar e testar:
- Para tipo de validação, selecione validação cruzada k-fold.
- Para Número de validações cruzadas, selecione 2.
Selecione Avançar.
Selecione cluster de computação como seu tipo de computação.
Um destino de computação é um ambiente de recursos local ou baseado em nuvem usado para executar o script de treinamento ou hospedar a implantação do serviço. Para este experimento, você pode experimentar uma computação sem servidor baseada em nuvem (versão prévia) ou criar sua própria computação baseada em nuvem.
Observação
Para usar a computação sem servidor, habilite o recurso de visualização, selecione Sem servidor e ignore este procedimento.
Para criar seu próprio destino de computação, em Selecionar tipo de computação, selecione Cluster de computação para configurar seu destino de computação.
Popule o formulário Máquina Virtual para configurar sua computação. Selecione Novo.
Campo Descrição Valor para o tutorial Location A região da qual você gostaria de executar o computador Oeste dos EUA 2 Tipo de máquina virtual Selecione a prioridade que o experimento deve ter Dedicado Tipo de máquina virtual Selecione o tipo da máquina virtual da computação. CPU (Unidade de Processamento Central) Tamanho da máquina virtual Selecione o tamanho da máquina virtual da computação. É fornecida uma lista de tamanhos recomendados com base em seus dados e no tipo de experimento. Standard_DS12_V2 Selecione Avançar para ir para o formulário Configurações Avançadas.
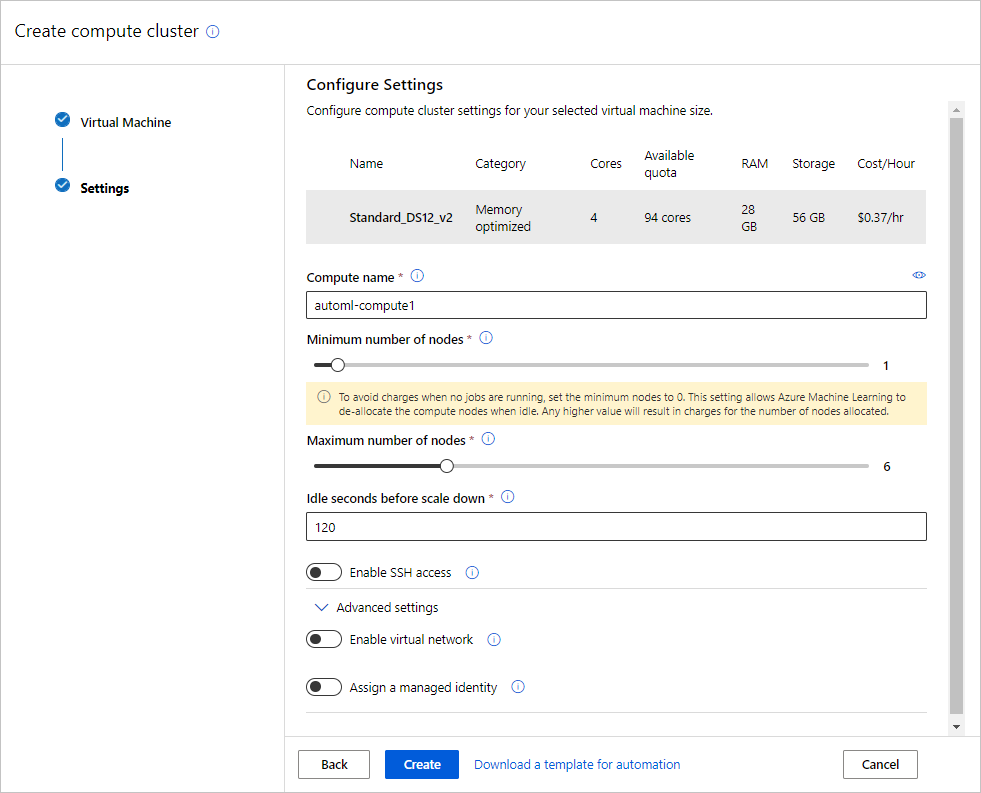
Campo Descrição Valor para o tutorial Nome da computação Um nome exclusivo que identifique o contexto de computação. automl-compute Mín./máx. de nós Para analisar os dados, é necessário especificar um ou mais nós. Número mín. de nós: 1
Número máx. de nós: 6Segundos de espera antes de reduzir verticalmente Tempo de espera antes que o cluster seja reduzido verticalmente automaticamente para a contagem mínima de nós. 120 (padrão) Configurações avançadas Definições para configurar e autorizar uma rede virtual para seu experimento. Nenhum Selecione Criar.
A criação de uma computação pode levar minutos para ser concluída.
Após a criação, selecione seu novo destino de computação na lista. Selecione Avançar.
Selecione Enviar trabalho de treinamento para executar o experimento. A tela Visão geral é aberta com o Status na parte superior à medida que a preparação do experimento começa. Esse status é atualizado conforme o progresso do experimento. As notificações também aparecem no estúdio para informá-lo sobre o status do experimento.

Importante
A preparação leva de 10 a 15 minutos para preparar a execução do experimento. Durante a execução, são necessários mais 2 a 3 minutos para cada iteração.
Em produção, provavelmente, isso demorará mais. Mas para este tutorial, você pode começar a explorar os algoritmos testados na guia Modelos conforme eles são concluídos enquanto os outros continuam a ser executados.
Explorar modelos
Navegue até a guia Modelos + trabalhos filho para ver os algoritmos (modelos) testados. Por padrão, o trabalho ordena os modelos por pontuação de métrica conforme eles são concluídos. Para este tutorial, o modelo que pontua mais alto com base na métrica AUCWeighted escolhida está na parte superior da lista.
Enquanto você aguarda a conclusão de todos os modelos de experimento, selecione o Nome do algoritmo de um modelo concluído para explorar seus detalhes de desempenho. Selecione a Visão Geral e as guias Métricas para obter informações sobre o trabalho.
A animação a seguir exibe as propriedades, as métricas e os gráficos de desempenho do modelo selecionado.

Exibir explicações do modelo
Enquanto aguarda a conclusão dos modelos, você também pode dar uma olhada nas explicações de modelo e ver quais recursos de dados (brutos ou com engenharia) influenciaram as previsões de um modelo específico.
Essas explicações de modelo podem ser geradas sob demanda. O painel explicações do modelo que faz parte da guia Explicações (versão prévia) resume essas explicações.
Para gerar explicações de modelo:
Nos links de navegação na parte superior da página, selecione o nome do trabalho para voltar à tela Modelos.
Selecione a guia Modelos + trabalhos filho.
Para esse tutorial, selecione o primeiro modelo MaxAbsScaler, LightGBM.
Selecione Explicar modelo. À direita, o painel Explicar modelo é exibido.
Selecione seu tipo de computação e, em seguida, selecione a instância ou o cluster: automl-compute que você criou anteriormente. Essa computação inicia um trabalho filho para gerar as explicações do modelo.
Selecione Criar. Uma mensagem de sucesso verde é exibida.
Observação
O trabalho de explicação leva cerca de 2 a 5 minutos para ser concluído.
Selecione Explicações (versão prévia). Essa guia é preenchida após a conclusão da execução da explicação.
À esquerda, expanda o painel. Em Recursos, selecione a linha que diz bruto.
Selecione a guia Agregar importância do recurso. Esse gráfico mostra quais recursos de dados influenciaram as previsões do modelo selecionado.
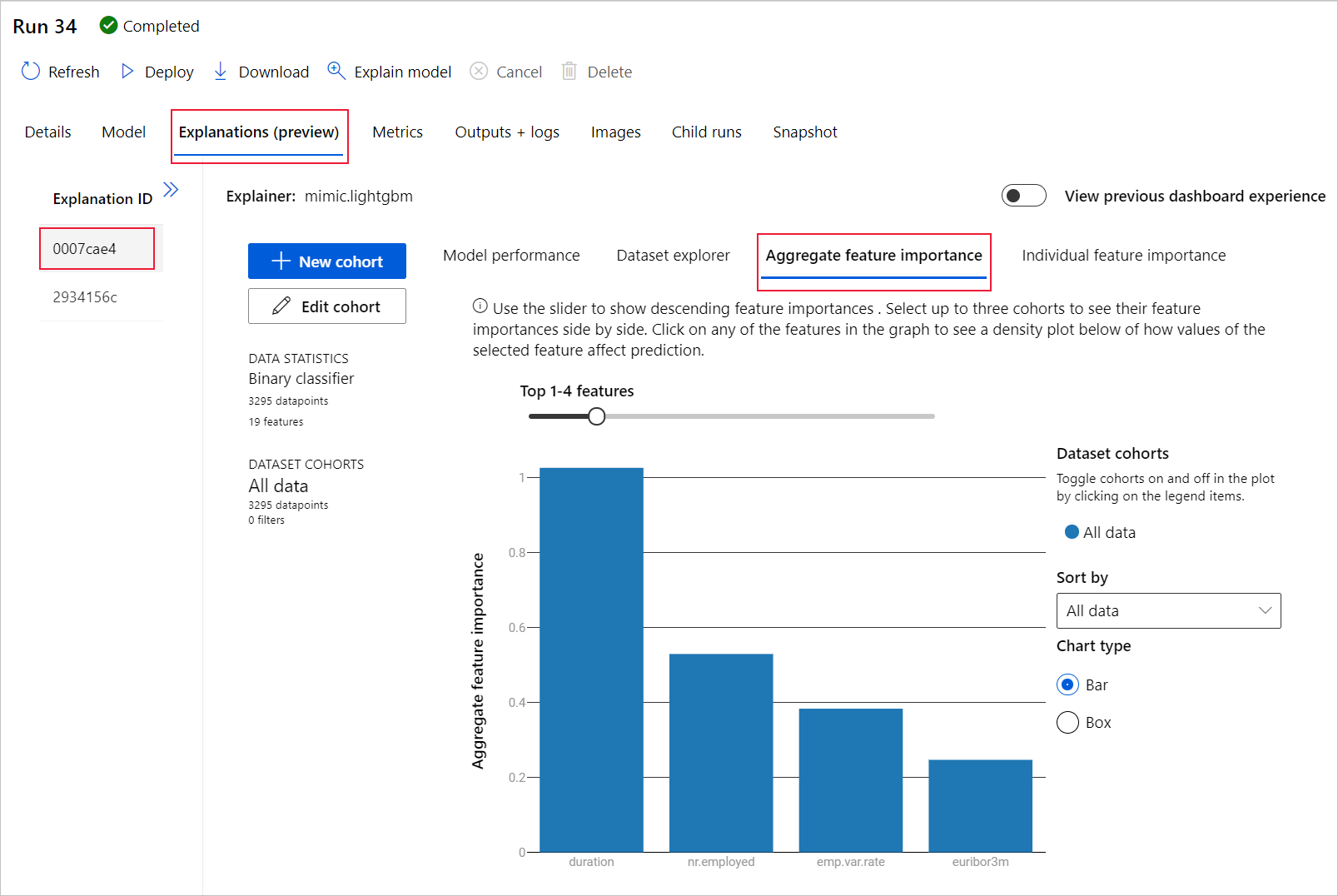
Nesse exemplo, a duração parece ter mais influência sobre as previsões desse modelo.

Implantar o melhor modelo
A interface de machine learning automatizado permite que você implante o melhor modelo como um serviço Web. A implantação é a integração do modelo para que ele possa prever novos dados e identificar possíveis áreas de oportunidade. Para este experimento, a implantação em um serviço Web significa que a instituição financeira agora tem uma solução Web iterativa e escalonável para identificar clientes potenciais para depósito a prazo fixo.
Verifique se a execução do experimento está concluída. Para fazer isso, navegue de volta para a página de trabalho pai selecionando o nome do trabalho na parte superior da tela. Um status Concluído é mostrado na parte superior esquerda da tela.
Depois que a execução experimental for concluída, a página Detalhes será populada com uma seção Resumo do melhor modelo. Neste contexto de experimento, VotingEnsemble é considerado o melhor modelo, com base na métrica AUCWeighted.
Implante este modelo. A implantação leva cerca de 20 minutos para ser concluída. O processo de implantação envolve várias etapas, incluindo o registro do modelo, a geração de recursos e a configuração deles para o serviço Web.
Selecione VotingEnsemble para abrir a página específica do modelo.
Selecione Implantar>serviço Web.
Preencha o painel Implantar um Modelo da seguinte maneira:
Campo Valor Nome my-automl-deploy Descrição Minha primeira implantação de experimento de aprendizado de máquina automatizado Tipo de computação Selecionar Instância de Contêiner do Azure Habilitar autenticação Desabilite. Usar ativos da implantação personalizada Desabilitar. Permite que o arquivo de driver padrão (script de pontuação) e o arquivo de ambiente sejam gerados automaticamente. Para este exemplo, use os padrões fornecidos no menu Avançado.
Selecione Implantar.
Uma mensagem de êxito verde aparece na parte superior da tela Trabalho. No painel Resumo do modelo, uma mensagem de status é exibida no status Implantar. Selecione Atualizar periodicamente para verificar o status da implantação.
Você tem um serviço Web operacional para gerar previsões.
Prossiga para o Conteúdo relacionado para saber mais sobre como consumir seu novo serviço Web e testar suas previsões usando o Suporte interno do Power BI no Azure Machine Learning.
Limpar os recursos
Os arquivos de implantação são maiores que os dados e os arquivos de teste, portanto, eles custam mais para serem armazenados. Se você quiser manter o workspace e os arquivos de experimento, exclua apenas os arquivos de implantação para minimizar os custos para sua conta. Se você não planeja usar nenhum dos arquivos, exclua todo o grupo de recursos.
Excluir a instância de implantação
Excluir apenas a instância de implantação do Azure Machine Learning em https://ml.azure.com/.
Acesse Azure Machine Learning. Navegue até o workspace e, no painel Ativos, selecione Pontos de extremidade.
Selecione a implantação que você deseja excluir e selecione Excluir.
Selecione Continuar.
Exclua o grupo de recursos
Importante
Os recursos que você criou podem ser usados como pré-requisitos em outros tutoriais e artigos de instruções do Azure Machine Learning.
Se você não pretende usar nenhum dos recursos criados, exclua-os para não gerar custos:
No portal do Azure, na caixa de pesquisa, insira Grupos de recursos e selecione-o nos resultados.
Selecione o grupo de recursos que você criou por meio da lista.
Na página Visão geral, selecione Excluir grupo de recursos.
Insira o nome do grupo de recursos. Em seguida, selecione Excluir.
Conteúdo relacionado
Neste tutorial de machine learning automatizado, você usou a interface de ML automatizado do Azure Machine Learning para criar e implantar um modelo de classificação. Para obter mais informações e próximas etapas, consulte estes recursos:
- Saiba mais sobre o aprendizado de máquina automatizado.
- Saiba mais sobre métricas e gráficos de classificação: Artigo sobre avaliação de resultados de experimentos de aprendizado de máquina automatizado.
- Saiba mais sobre como configurar o AutoML para NLP.
Além disso, experimente o machine learning automatizado para estes outros tipos de modelo:
- Para obter um exemplo de previsão sem código, consulte Tutorial: Prever a demanda com aprendizado de máquina automatizado sem código no estúdio do Azure Machine Learning.
- Para obter um primeiro exemplo de código de um modelo de detecção de objetos, confira o Tutorial: treinar um modelo de detecção de objetos com o AutoML e o Python.