Controlar a versão e acompanhar os conjuntos de dados do Azure Machine Learning
APLICA-SE A SDK do Python azureml v1
SDK do Python azureml v1
Neste artigo, você aprenderá a controlar a versão e a acompanhar os conjuntos de dados do Azure Machine Learning para reprodução. O controle de versão do conjunto de dados é uma maneira de indicar o estado de seus dados de forma que você possa aplicar uma versão específica do conjunto para experimentos futuros.
Cenários típicos de controle de versão:
- Quando novos dados estão disponíveis para novo treinamento
- Quando você estiver aplicando estratégias diferentes de preparação de dados ou de engenharia de recursos
Pré-requisitos
Para este tutorial, é necessário:
O SDK do Azure Machine Learning para Python instalado. Este SDK inclui o pacote azureml-datasets.
Um workspace do Azure Machine Learning. Recupere um existente executando o código a seguir ou crie um novo workspace.
import azureml.core from azureml.core import Workspace ws = Workspace.from_config()
Registrar e recuperar versões do conjunto de dados
Ao registrar um conjunto de dados, você pode controlar a versão, reutilizá-la e compartilhá-la entre experimentos e colegas. Você pode registrar vários conjuntos de dados com o mesmo nome e recuperar uma versão específica por meio do nome e do número dela.
Registrar uma versão de conjunto de dados
O código a seguir registra uma nova versão do conjunto de dados titanic_ds definindo o parâmetro create_new_version como True. Se não houver um conjunto de dados titanic_ds registrado no workspace, o código criará um conjunto com o nome titanic_ds e definirá a respectiva versão como 1.
titanic_ds = titanic_ds.register(workspace = workspace,
name = 'titanic_ds',
description = 'titanic training data',
create_new_version = True)
Recuperar um conjunto de dados por nome
Por padrão, o método get_by_name () na classe Dataset retorna a versão mais recente do conjunto de dados registrado com o workspace.
O código a seguir obtém a versão 1 do conjunto de dados titanic_ds.
from azureml.core import Dataset
# Get a dataset by name and version number
titanic_ds = Dataset.get_by_name(workspace = workspace,
name = 'titanic_ds',
version = 1)
Melhores práticas de controle de versão
Ao criar uma versão de conjunto de dados, você não está criando uma cópia extra dos dados com o workspace. Uma vez que os conjuntos de dados são referências aos dados em seu serviço de armazenamento, você tem uma única fonte de verdade, gerenciada pelo seu serviço de armazenamento.
Importante
Se os dados referenciados pelo conjunto de dados forem substituídos ou excluídos, chamar uma versão específica do conjunto de dados não reverterá a alteração.
Quando você carrega dados de um conjunto, o conteúdo atual dos dados referenciado pelo conjunto de dados é sempre carregado. Para garantir que cada versão do conjunto de dados seja reproduzível, recomendamos não modificar o conteúdo de dados referenciado pela versão do conjunto de dados. Quando chegarem novos dados, salve os arquivos de dados novos em uma pasta de dados separada e crie uma nova versão do conjunto de dados a fim de incluí-los na nova pasta.
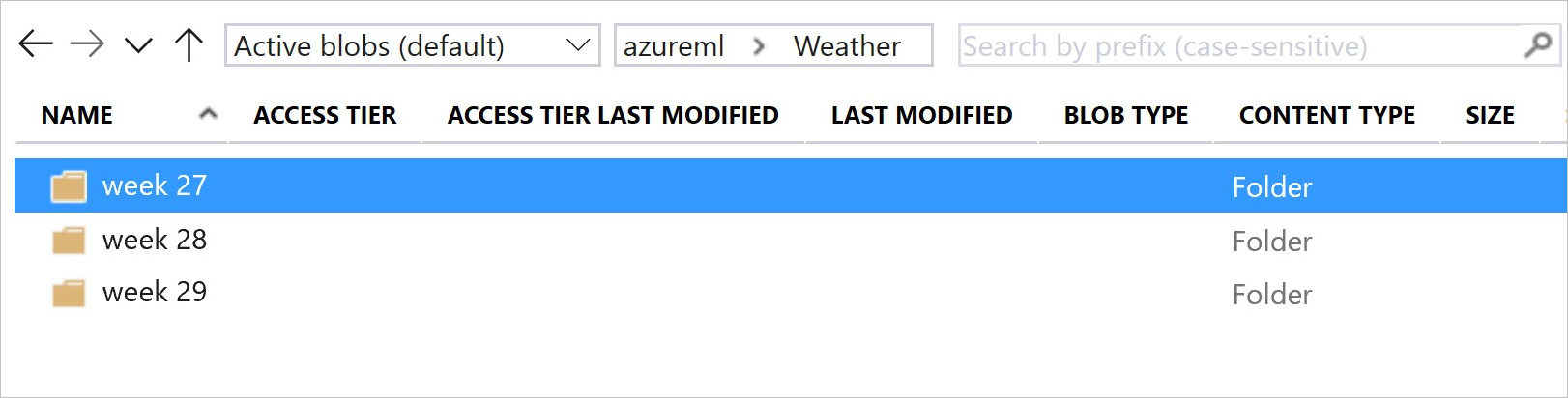
A imagem e o código de exemplo seguintes mostram a maneira recomendada de estruturar suas pastas de dados e criar versões do conjuntos de dados que fazem referência a essas pastas:
from azureml.core import Dataset
# get the default datastore of the workspace
datastore = workspace.get_default_datastore()
# create & register weather_ds version 1 pointing to all files in the folder of week 27
datastore_path1 = [(datastore, 'Weather/week 27')]
dataset1 = Dataset.File.from_files(path=datastore_path1)
dataset1.register(workspace = workspace,
name = 'weather_ds',
description = 'weather data in week 27',
create_new_version = True)
# create & register weather_ds version 2 pointing to all files in the folder of week 27 and 28
datastore_path2 = [(datastore, 'Weather/week 27'), (datastore, 'Weather/week 28')]
dataset2 = Dataset.File.from_files(path = datastore_path2)
dataset2.register(workspace = workspace,
name = 'weather_ds',
description = 'weather data in week 27, 28',
create_new_version = True)
Controlar a versão de um conjunto de dados de saída de um pipeline de ML
Você pode usar um conjunto de dados como entrada e saída de cada etapa de pipeline de ML. Quando você executa os pipelines novamente, a saída de cada etapa de pipeline é registrada como uma nova versão do conjunto de dados.
Os pipelines de ML preenchem a saída de cada etapa em uma nova pasta toda vez que o pipeline é reexecutado. Esse comportamento permite que os conjuntos de dados de saída com controle de versão sejam reproduzíveis. Saiba mais sobre conjuntos de dados em pipelines.
from azureml.core import Dataset
from azureml.pipeline.steps import PythonScriptStep
from azureml.pipeline.core import Pipeline, PipelineData
from azureml.core. runconfig import CondaDependencies, RunConfiguration
# get input dataset
input_ds = Dataset.get_by_name(workspace, 'weather_ds')
# register pipeline output as dataset
output_ds = PipelineData('prepared_weather_ds', datastore=datastore).as_dataset()
output_ds = output_ds.register(name='prepared_weather_ds', create_new_version=True)
conda = CondaDependencies.create(
pip_packages=['azureml-defaults', 'azureml-dataprep[fuse,pandas]'],
pin_sdk_version=False)
run_config = RunConfiguration()
run_config.environment.docker.enabled = True
run_config.environment.python.conda_dependencies = conda
# configure pipeline step to use dataset as the input and output
prep_step = PythonScriptStep(script_name="prepare.py",
inputs=[input_ds.as_named_input('weather_ds')],
outputs=[output_ds],
runconfig=run_config,
compute_target=compute_target,
source_directory=project_folder)
Acompanhar dados em seus experimentos
O Azure Machine Learning acompanha seus dados em todo o experimento como conjuntos de dados de entrada e saída.
A seguir estão os cenários em que os dados são acompanhados como conjuntos de dados de entrada.
Como objeto
DatasetConsumptionConfigpor meio do parâmetroinputsouargumentsdo seu objetoScriptRunConfigao enviar o trabalho do experimento.Quando métodos como get_by_name () ou get_by_id () são chamados em seu script. Para esse cenário, o nome exibido é o que foi atribuído ao conjunto de dados quando você o registrou no workspace.
A seguir estão os cenários em que os dados são acompanhados como conjuntos de dados de saída.
Passe um objeto
OutputFileDatasetConfigpor meio dos parâmetrosoutputsouargumentsao enviar um trabalho de experimento. Os objetosOutputFileDatasetConfigtambém podem ser usados para persistir os dados entre as etapas do pipeline. Confira Mover dados entre as etapas do pipeline de ML.Registrar um conjunto de dados em seu script. Para esse cenário, o nome exibido é o que foi atribuído ao conjunto de dados quando você o registrou no workspace. No exemplo a seguir,
training_dsé o nome que seria exibido.training_ds = unregistered_ds.register(workspace = workspace, name = 'training_ds', description = 'training data' )Envie um trabalho filho com um conjunto de dados não registrado no script. Isso resulta em um conjunto de dados anônimo salvo.
Rastrear conjuntos de dados em trabalhos de experimento
Para cada experimento de Machine Learning, você pode rastrear facilmente os conjuntos de dados usados como entrada com o objeto Job do experimento.
O código seguinte usa o método get_details() para controlar quais conjuntos de dados de entrada foram usados com a execução do experimento:
# get input datasets
inputs = run.get_details()['inputDatasets']
input_dataset = inputs[0]['dataset']
# list the files referenced by input_dataset
input_dataset.to_path()
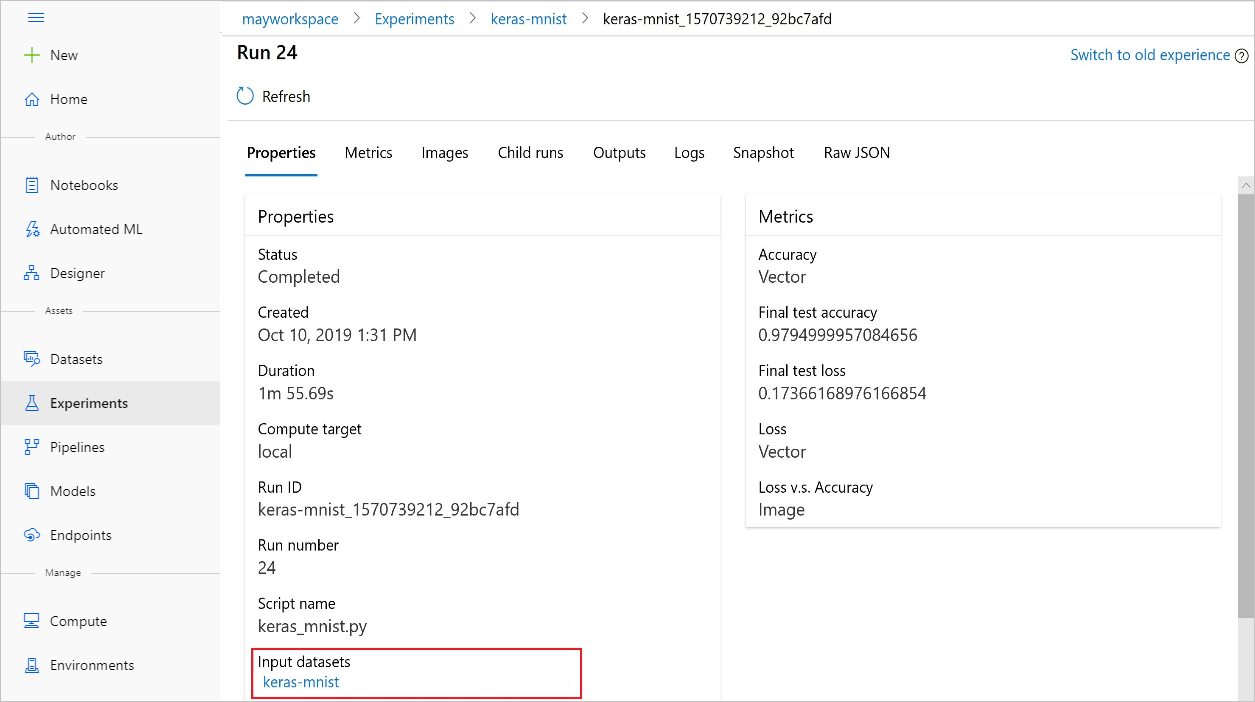
Os input_datasets de experimentos também poder ser encontrados usando o Estúdio do Azure Machine Learning.
A imagem a seguir mostra onde encontrar o conjunto de dados de entrada de um experimento no Estúdio do Azure Machine Learning. Para este exemplo, vá para o painel Experimentos e abra a guia Propriedades para uma execução específica de seu experimento, keras-mnist.
Use o código seguinte para registrar modelos com conjuntos de dados:
model = run.register_model(model_name='keras-mlp-mnist',
model_path=model_path,
datasets =[('training data',train_dataset)])
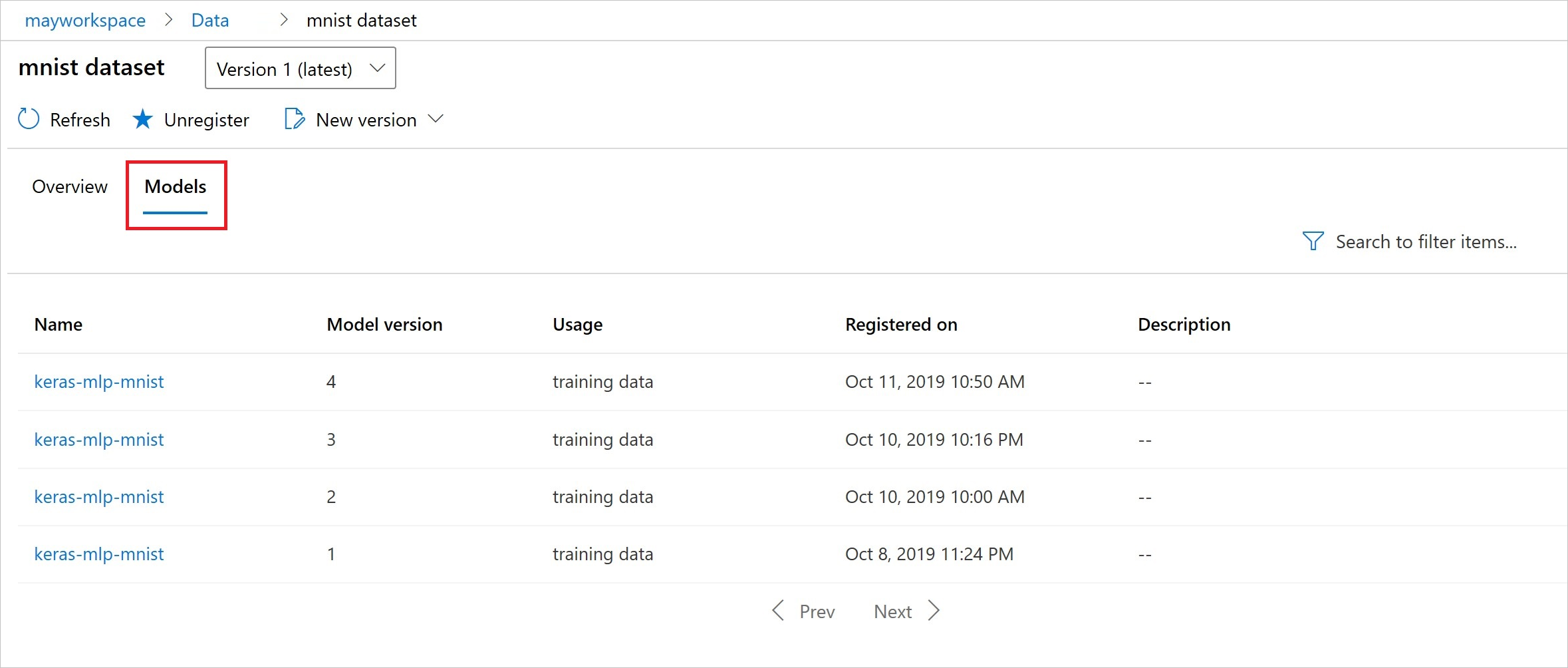
Após o registro, você poderá ver a lista de modelos registrados com o conjunto de dados usando o Python ou ir para o estúdio.
A exibição a seguir é do painel Conjuntos de dados em Ativos. Selecione o conjunto de dados e depois a guia Modelos para obter uma lista dos modelos registrados com o conjunto de dados.