Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
APLICA-SE A:  Banco de Dados do Azure para PostgreSQL - Servidor Flexível
Banco de Dados do Azure para PostgreSQL - Servidor Flexível
O servidor flexível do Banco de Dados do Azure para PostgreSQL oferece a capacidade de ampliar a funcionalidade do seu banco de dados usando as extensões. As extensões agrupam vários objetos SQL relacionados em um único pacote que pode ser carregado ou removido do seu banco de dados com um comando. Depois de serem carregadas no banco de dados, as extensões funcionam como recursos internos.
Como usar as extensões PostgreSQL
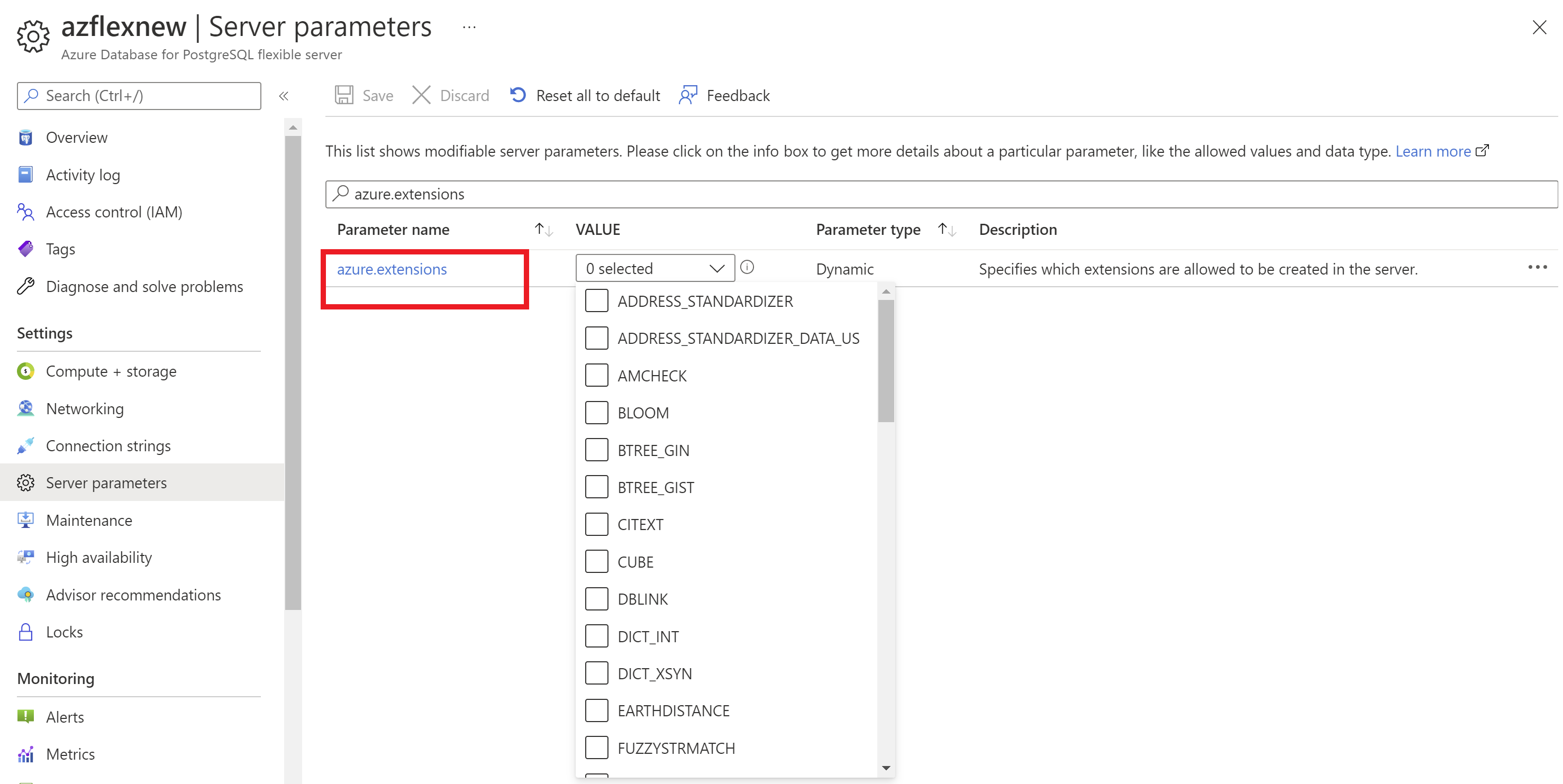
Antes de instalar as extensões do servidor flexível do Banco de Dados do Azure para PostgreSQL, você precisa autorizar o uso dessas extensões.
Usando o portal do Azure:
- Selecione sua instância do servidor flexível do Banco de Dados do Azure para PostgreSQL.
- No menu de recursos, na seção Configurações, selecione Parâmetros do servidor.
- Pesquise o parâmetro
azure.extensions. - Selecione as extensões que deseja autorizar.

Usando a CLI do Azure:
Você pode colocar extensões na lista de permitidos por meio do comando parameter set da CLI.
az postgres flexible-server parameter set --resource-group <resource_group> --server-name <server> --subscription <subscription_id> --name azure.extensions --value <extension_name>,<extension_name>
Usando o Modelo do ARM: O exemplo a seguir permite listar as extensões dblink, dict_xsyn, pg_buffercache em um servidor cujo nome é postgres-test-server:
{
"$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"parameters": {
"flexibleServers_name": {
"defaultValue": "postgres-test-server",
"type": "String"
},
"azure_extensions_set_value": {
"defaultValue": " dblink,dict_xsyn,pg_buffercache",
"type": "String"
}
},
"variables": {},
"resources": [
{
"type": "Microsoft.DBforPostgreSQL/flexibleServers/configurations",
"apiVersion": "2021-06-01",
"name": "[concat(parameters('flexibleServers_name'), '/azure.extensions')]",
"properties": {
"value": "[parameters('azure_extensions_set_value')]",
"source": "user-override"
}
}
]
}
shared_preload_libraries é um parâmetro de configuração do servidor que determina quais bibliotecas devem ser carregadas quando o servidor flexível do Banco de Dados do Azure para PostgreSQL é iniciado. Todas as bibliotecas que usam memória compartilhada devem ser carregadas por meio desse parâmetro. Se sua extensão precisar ser adicionada às bibliotecas de pré-carregamento compartilhadas, siga estas etapas:
Usando o portal do Azure:
- Selecione sua instância do servidor flexível do Banco de Dados do Azure para PostgreSQL.
- No menu de recursos, na seção Configurações, selecione Parâmetros do servidor.
- Pesquise o parâmetro
shared_preload_libraries. - Selecione as bibliotecas que deseja adicionar.
:::image type="content" source="./media/concepts-extensions/shared-libraries.png" alt-text="Screenshot showing Azure Database for PostgreSQL -setting shared preload libraries parameter setting for extensions installation." lightbox="./media/concepts-extensions/shared-libraries.png":::
```Using [Azure CLI](/cli/azure/):
You can set `shared_preload_libraries` via CLI [parameter set](/cli/azure/postgres/flexible-server/parameter?view=azure-cli-latest&preserve-view=true) command.
```azurecli
az postgres flexible-server parameter set --resource-group <resource_group> --server-name <server> --subscription <subscription_id> --name shared_preload_libraries --value <extension_name>,<extension_name>
Criar extensão
Depois que as extensões forem incluídas na lista de permissões e carregadas, elas deverão ser instaladas em cada banco de dados no qual você planeja usá-las.
- Um usuário deve ser membro da função
azure_pg_adminpara criar uma extensão. Um membro da funçãoazure_pg_adminpode conceder privilégios a outros usuários para criar extensões. - Para instalar uma extensão específica, execute o comando CREATE EXTENSION. Esse comando carrega os objetos empacotados em seu banco de dados.
Observação
As extensões de terceiros oferecidas no servidor flexível do Banco de Dados do Azure para PostgreSQL são códigos licenciados de código aberto. Atualmente, não oferecemos extensões ou versões de extensões de terceiros com modelos de licenciamento Premium ou proprietário.
A instância servidor flexível do Banco de Dados do Azure para PostgreSQL dá suporte a um subconjunto das principais extensões do PostgreSQL, conforme listado na tabela a seguir. Essas informações também estão disponíveis por meio da execução de SHOW azure.extensions;. As extensões não listadas neste documento não têm suporte no servidor flexível do Banco de Dados do Azure para PostgreSQL. Você não pode criar ou carregar sua própria extensão no servidor flexível do Banco de Dados do Azure para PostgreSQL.
Versões da extensão
As seguintes extensões estão disponíveis no servidor flexível do Banco de Dados do Azure para PostgreSQL:
Observação
As extensões na tabela a seguir com a marca ✔️ exigem que suas bibliotecas correspondentes sejam habilitadas no parâmetro de servidor shared_preload_libraries.
| Nome da extensão | Descrição | PostgreSQL 17 | PostgreSQL 16 | PostgreSQL 15 | PostgreSQL 14 | PostgreSQL 13 | PostgreSQL 12 | PostgreSQL 11 |
|---|---|---|---|---|---|---|---|---|
| address_standardizer | Usado para analisar um endereço em elementos constituintes. Geralmente usado para oferecer suporte a etapa de normalização de endereços de geocodificação. | 3.5.0 | 3.3.3 | 3.3.1 | 3.2.3 | 3.2.3 | 3.2.3 | 3.2.3 |
| address_standardizer_data_us | Exemplo de conjunto de dados de padronizador de endereço dos EUA | 3.5.0 | 3.3.3 | 3.3.1 | 3.2.3 | 3.2.3 | 3.2.3 | 3.2.3 |
| idade (versão prévia) | Fornece funcionalidades de banco de dados de grafo | N/D | 1.5.0 ✔️ | 1.5.0 ✔️ | 1.5.0 ✔️ | 1.5.0 ✔️ | N/D | N/D |
| amcheck | Funções para verificar a integridade da relação | 1.4 | 1,3 | 1,3 | 1,3 | 1.2 | 1.2 | 1,1 |
| anon (versão prévia) | Ferramentas de anonimização de dados | 1.3.2 ✔️ | 1.3.2 ✔️ | 1.3.2 ✔️ | 1.3.2 ✔️ | 1.3.2 ✔️ | 1.3.2 ✔️ | 1.3.2 ✔️ |
| azure_ai | Integração da IA do Azure e do ML Services para PostgreSQL | N/D | 1.1.0 | 1.1.0 | 1.1.0 | 1.1.0 | 1.1.0 | N/D |
| azure_storage | Integração do Azure para PostgreSQL | N/D | 1.5 ✔️ | 1.5 ✔️ | 1.5 ✔️ | 1.5 ✔️ | 1.5 ✔️ | N/D |
| bloom | Método de acesso bloom – índice baseado no arquivo de assinatura | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| btree_gin | Suporte para indexação de tipos de dados comuns no GIN | 1,3 | 1,3 | 1,3 | 1,3 | 1,3 | 1,3 | 1,3 |
| btree_gist | Suporte para indexação de tipos de dados comuns no GiST | 1.7 | 1.7 | 1.7 | 1.6 | 1.5 | 1.5 | 1.5 |
| citext | Tipo de dados das cadeias de caracteres que não diferenciam maiúsculas de minúsculas | 1.6 | 1.6 | 1.6 | 1.6 | 1.6 | 1.6 | 1.5 |
| cube | Tipo de dados dos cubos multidimensionais | 1.5 | 1.5 | 1.5 | 1.5 | 1.4 | 1.4 | 1.4 |
| dblink | Conectar-se a outros bancos de dados PostgreSQL de dentro de um banco de dados | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 |
| dict_int | Modelo de dicionário de pesquisa de texto de inteiros | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| dict_xsyn | Modelo de dicionário de pesquisa de texto do processamento de sinônimo estendido | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| earthdistance | Calcular grandes distâncias de círculo na superfície da Terra | 1,1 | 1,1 | 1,1 | 1,1 | 1,1 | 1,1 | 1,1 |
| fuzzystrmatch | Determinar semelhanças e distância entre as cadeias de caracteres | 1,2 | 1.2 | 1,1 | 1,1 | 1,1 | 1,1 | 1,1 |
| hstore | Tipo de dados para armazenar conjuntos de pares (chave, valor) | 1.8 | 1.8 | 1.8 | 1.8 | 1.7 | 1.6 | 1.5 |
| hypopg | Índices hipotéticos para o PostgreSQL | 1.4.0 | 1.4.0 | 1.4.0 | 1.4.0 | 1.4.0 | 1.4.0 | 1.4.0 |
| intagg | Agregador e enumerador de inteiros (obsoleto) | 1,1 | 1,1 | 1,1 | 1,1 | 1,1 | 1,1 | 1,1 |
| intarray | Suporte a funções, operadores e índice das matrizes 1-D de inteiros | 1.5 | 1.5 | 1.5 | 1.5 | 1,3 | 1.2 | 1.2 |
| isn | Tipos de dados dos padrões internacionais de numeração de produtos | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 |
| lo | Manutenção de Objeto Grande | 1,1 | 1,1 | 1,1 | 1,1 | 1,1 | 1,1 | 1,1 |
| login_hook | Login_hook – gatilho para executar login_hook.login() no momento do logon | 1.5 | 1.5 | 1.4 | 1.4 | 1.4 | 1.4 | 1.4 |
| ltree | Tipo de dados das estruturas hierárquicas semelhantes a árvores | 1,3 | 1.2 | 1.2 | 1.2 | 1.2 | 1,1 | 1,1 |
| oracle_fdw | Wrapper de dados estrangeiros para bancos de dados Oracle | 1,2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | N/D |
| orafce | Funções e operadores que emulam um subconjunto de funções e pacotes do Oracle RDBMS | 4.9 | 4.4 | 3.24 | 3,18 | 3,18 | 3,18 | 3.7 |
| pageinspect | Inspecionar o conteúdo das páginas do banco de dados em um nível baixo | 1.12 | 1.12 | 1.11 | 1.9 | 1.8 | 1.7 | 1.7 |
| pgaudit | Fornece funcionalidade de auditoria | 16.0 ✔️ | 16.0 ✔️ | 1.7 ✔️ | 1.6.2 ✔️ | 1.5 ✔️ | 1.4.3 ✔️ | 1.3.2 ✔️ |
| pg_buffercache | Examinar o cache de buffer compartilhado | 1.5 | 1.4 | 1,3 | 1,3 | 1,3 | 1,3 | 1,3 |
| pg_cron | Agendador de trabalhos para PostgreSQL | 1.6 ✔️ | 1.6 ✔️ | 1.6 ✔️ | 1.6 ✔️ | 1.6 ✔️ | 1.6 ✔️ | 1.4-1 ✔️ |
| pgcrypto | Funções criptográficas | 1,3 | 1,3 | 1,3 | 1,3 | 1,3 | 1,3 | 1,3 |
| pg_freespacemap | Examinar o mapa de espaço livre (FSM) | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 |
| pg_hint_plan | Torna possível ajustar os planos de execução do PostgreSQL usando as chamadas dicas nos comentários do SQL. | 1.7.0 ✔️ | 1.6.0 ✔️ | 1.5 ✔️ | 1.4 ✔️ | 1.3.7 ✔️ | 1.3.7 ✔️ | 1.3.7 ✔️ |
| pglogical | Replicação lógica do PostgreSQL | 2.4.5 ✔️ | 2.4.4 ✔️ | 2.4.2 ✔️ | 2.4.1 ✔️ | 2.4.1 ✔️ | 2.4.1 ✔️ | 2.4.1 ✔️ |
| pg_partman | Extensão usada para gerenciar tabelas particionadas por hora ou ID | 5.0.1 ✔️ | 5.0.1 ✔️ | 4.7.1 ✔️ | 4.6.1 ✔️ | 4.5.0 ✔️ | 4.5.0 ✔️ | 4.5.0 ✔️ |
| pg_prewarm | Dados de relação pré-guerra | 1.2 ✔️ | 1.2 ✔️ | 1.2 ✔️ | 1.2 ✔️ | 1.2 ✔️ | 1.2 ✔️ | 1.2 ✔️ |
| pg_repack | Reorganiza as tabelas em bancos de dados PostgreSQL com bloqueios mínimos | 1.4.7 | 1.4.7 | 1.4.7 | 1.4.7 | 1.4.7 | 1.4.7 | 1.4.7 |
| pgrouting | Extensão de PgRouting | N/D | N/D | 3.5.0 | 3.3.0 | 3.3.0 | 3.3.0 | 3.3.0 |
| pgrowlocks | Mostrar informações de bloqueio em nível de linha | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1,2 |
| pg_squeeze | Uma ferramenta para remover o espaço não usado de uma relação. | 1.7 ✔️ | 1.6 ✔️ | 1.6 ✔️ | 1.5 ✔️ | 1.5 ✔️ | 1.5 ✔️ | 1.5 ✔️ |
| pg_stat_statements | Acompanhar as estatísticas de execução de todas as instruções SQL executadas | 1.11 ✔️ | 1.10 ✔️ | 1.10 ✔️ | 1.9 ✔️ | 1.8 ✔️ | 1.7 ✔️ | 1.6 ✔️ |
| pgstattuple | Mostrar estatísticas de nível de tupla | 1.5 | 1.5 | 1.5 | 1.5 | 1.5 | 1.5 | 1.5 |
| pg_trgm | Medição de similaridade de texto e pesquisa de índice com base em trigramas | 1.6 | 1.6 | 1.6 | 1.6 | 1.5 | 1.4 | 1.4 |
| pg_visibility | Examinar as informações de visibilidade do mapa de visibilidade (VM) e do nível da página | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1,2 |
| plpgsql | Linguagem de procedimento PL/pgSQL | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| plv8 | Linguagem de procedimento confiável PL/JavaScript (v8) | 3.1.7 | 3.1.7 | 3.1.7 | 3.0.0 | 3.0.0 | 3.0.0 | 3.0.0 |
| postgis | Funções e tipos espaciais de geometria e geografia do PostGIS | 3.5.0 | 3.3.3 | 3.3.1 | 3.2.3 | 3.2.3 | 3.2.3 | 3.2.3 |
| postgis_raster | Funções e tipos de rasterização de PostGIS | 3.5.0 | 3.3.3 | 3.3.1 | 3.2.3 | 3.2.3 | 3.2.3 | 3.2.3 |
| postgis_sfcgal | Funções SFCGAL do PostGIS | 3.5.0 | 3.3.3 | 3.3.1 | 3.2.3 | 3.2.3 | 3.2.3 | 3.2.3 |
| postgis_tiger_geocoder | Geocodificador PostGIS Tiger e geocodificador reverso | 3.5.0 | 3.3.3 | 3.3.1 | 3.2.3 | 3.2.3 | 3.2.3 | 3.2.3 |
| postgis_topology | Tipos e funções espaciais da topologia do PostGIS | 3.5.0 | 3.3.3 | 3.3.1 | 3.2.3 | 3.2.3 | 3.2.3 | 3.2.3 |
| postgres_fdw | Wrapper de dados estrangeiros dos servidores PostgreSQL remotos | 1,1 | 1,1 | 1,1 | 1,1 | 1.0 | 1.0 | 1.0 |
| postgres_protobuf | Buffers de protocolo para PostgreSQL | 0,2 | 0,2 | 0,2 | 0,2 | 0,2 | 0,2 | N/D |
| semver | Tipo de dados de versão semântica | 0.32.1 | 0.32.1 | 0.32.0 | 0.32.0 | 0.32.0 | 0.32.0 | 0.32.0 |
| session_variable | Session_variable – registro e manipulação de variáveis e constantes de sessão | 3.3 | 3.3 | 3.3 | 3.3 | 3.3 | 3.3 | 3.3 |
| sslinfo | Informações sobre os certificados SSL | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 |
| tablefunc | Funções que manipulam tabelas inteiras, incluindo a tabela de referência cruzada | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| tds_fdw | Wrapper de dados estrangeiro para consultar um banco de dados TDS (Sybase ou Microsoft SQL Server) | 2.0.3 | 2.0.3 | 2.0.3 | 2.0.3 | 2.0.3 | 2.0.3 | 2.0.3 |
| timescaledb | Permite inserções escalonáveis e consultas complexas em dados de série temporal | N/D | 2.13.0 ✔️ | 2.10.0 ✔️ | 2.10.0 ✔️ | 2.10.0 ✔️ | 2.10.0 ✔️ | 1.7.4 ✔️ |
| tsm_system_rows | Método TABLESAMPLE, que aceita o número de linhas como um limite | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| tsm_system_time | Método TABLESAMPLE, que aceita o tempo em milissegundos como um limite | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| unaccent | Dicionário de pesquisa de texto que remove ênfases | 1,1 | 1,1 | 1,1 | 1,1 | 1,1 | 1,1 | 1,1 |
| uuid-ossp | Gerar identificadores universais exclusivos (UUIDs) | 1,1 | 1,1 | 1,1 | 1,1 | 1,1 | 1,1 | 1,1 |
| vector | Tipos de dados de vetor e métodos de acesso ivfflat e hnsw | 0.7.0 | 0.7.0 | 0.7.0 | 0.7.0 | 0.7.0 | 0.7.0 | 0.5.1 |
Atualizar extensões do PostgreSQL
Atualizações in-loco de extensões de banco de dados são permitidas por meio de um comando simples. Esse recurso permite que os clientes atualizem automaticamente suas extensões de terceiros para as versões mais recentes, mantendo sistemas atuais e seguros sem esforço manual.
Atualizar extensões
Para atualizar uma extensão instalada para a versão mais recente disponível com suporte pelo Azure, use o seguinte comando SQL:
ALTER EXTENSION <extension_name> UPDATE;
Esse comando simplifica o gerenciamento de extensões de banco de dados, permitindo que os usuários atualizem manualmente para a versão mais recente aprovada pelo Azure, melhorando a compatibilidade e a segurança.
Limitações
Embora a atualização de extensões seja simples, há certas limitações:
- Seleção de uma versão específica: O comando não dá suporte à atualização para versões intermediárias de uma extensão. Ele sempre atualiza para a versão mais recente disponível.
- Downgrade: não dá suporte ao downgrade de uma extensão para uma versão anterior. Se for necessário fazer um downgrade, ele poderá exigir assistência de suporte e dependerá da disponibilidade da versão anterior.
Extensões instaladas
Para listar as extensões instaladas no momento no banco de dados, use o seguinte comando SQL:
SELECT * FROM pg_extension;
Extensões disponíveis e suas versões
Para verificar quais versões de uma extensão estão disponíveis para a instalação atual do seu banco de dados, consulte a exibição pg_available_extensions do catálogo do sistema. Por exemplo, para determinar a versão disponível para a extensão azure_ai, execute:
SELECT * FROM pg_available_extensions WHERE name = 'azure_ai';
Esses comandos fornecem informações necessárias sobre as configurações de extensão do banco de dados, ajudando a manter seus sistemas de forma eficiente e segura. Ao habilitar atualizações fáceis para as versões de extensão mais recentes, o Banco de Dados do Azure para PostgreSQL continua a dar suporte ao gerenciamento robusto, seguro e eficiente de seus aplicativos de banco de dados.
Considerações específicas do servidor flexível do Banco de Dados do Azure para PostgreSQL
A seguir, há uma lista de extensões com suporte que exigem algumas considerações específicas quando usadas no serviço de servidor flexível do Banco de Dados do Azure para PostgreSQL. A lista está em ordem alfabética.
dblink
O dblink permite que você se conecte de uma instância do servidor flexível do Banco de Dados do Azure para PostgreSQL a outra, ou a outro banco de dados no mesmo servidor. O servidor flexível do Banco de Dados do Azure para PostgreSQL dá suporte a conexões de entrada e saída para qualquer servidor PostgreSQL. O servidor de envio precisa permitir conexões de saída para o servidor de recebimento. Dessa forma, o servidor de recebimento precisa permitir conexões do servidor de envio por meio de seu firewall.
Se você planeja usar essa extensão, recomendamos implantar seus servidores com integração de rede virtual. Por padrão, a integração da rede virtual permite conexões entre servidores na rede virtual. Você também pode optar por usar grupos de segurança de rede da rede virtual para personalizar o acesso.
pg_buffercache
pg_buffercache pode ser usado para estudar o conteúdo de shared_buffers. Usando essa extensão, você consegue saber se uma relação específica é armazenada em cache ou não (em shared_buffers). Essa extensão pode ajudar você a solucionar problemas de desempenho (problemas de desempenho relacionados ao cache).
Essa extensão está integrada à instalação principal do PostgreSQL e é fácil de instalar.
CREATE EXTENSION pg_buffercache;
pg_cron
pg_cron é um agendador de trabalhos simples e baseado em CRON para PostgreSQL, que é executado dentro do banco de dados como uma extensão. A extensão pg_cron pode ser usada para executar tarefas de manutenção agendadas em um banco de dados do PostgreSQL. Por exemplo, você pode executar o vácuo periódico de uma tabela ou remover trabalhos de dados antigos.
pg_cron pode executar vários trabalhos em paralelo, mas no máximo uma instância de um trabalho é executada por vez. Se uma segunda execução for iniciada antes da conclusão da primeira, a segunda execução ficará fila e será iniciada assim que a primeira for concluída. Dessa forma, é garantido que os trabalhos sejam executados exatamente quantas vezes forem agendado e não sejam executados simultaneamente.
Alguns exemplos:
Para excluir dados antigos no sábado às 3h30 (GMT).
SELECT cron.schedule('30 3 * * 6', $$DELETE FROM events WHERE event_time < now() - interval '1 week'$$);
Para executar o aspirador todos os dias às 10h (GMT) no banco de dados padrão postgres.
SELECT cron.schedule('0 10 * * *', 'VACUUM');
Para cancelar o agendamento de todas as tarefas do pg_cron.
SELECT cron.unschedule(jobid) FROM cron.job;
Para ver todos os trabalhos agendados no momento com pg_cron.
SELECT * FROM cron.job;
Para executar o aspirador todos os dias às 10:00 (GMT) no banco de dados "testcron" na conta de função azure_pg_admin.
SELECT cron.schedule_in_database('VACUUM','0 10 * * * ','VACUUM','testcron',null,TRUE);
Observação
A extensão pg_cron é pré-carregada em shared_preload_libraries para cada instância do servidor flexível do Banco de Dados PostgreSQL do Azure dentro do banco de dados postgres para fornecer a você a capacidade de agendar trabalhos a serem executados em outros bancos de dados dentro da instância de servidor flexível do Banco de Dados do Azure para PostgreSQL sem comprometer a segurança. Entretanto, por motivos de segurança, você ainda precisa permitir a lista pg_cron e instalá-la usando o comando CREATE EXTENSION.
A partir com a versão do pg_cron 1.4, você pode usar as funções cron.schedule_in_database e cron.alter_job para agendar seu trabalho em um banco de dados específico e atualizar um agendamento existente, respectivamente.
Alguns exemplos:
Para excluir dados antigos no sábado, às 3h30 (GMT) no DBName do banco de dados.
SELECT cron.schedule_in_database('JobName', '30 3 * * 6', $$DELETE FROM events WHERE event_time < now() - interval '1 week'$$,'DBName');
Observação
A função cron_schedule_in_database permite o nome de usuário como parâmetro opcional. Definir o nome do usuário como um valor não nulo requer privilégio de superusuário do PostgreSQL e não é suportado no servidor flexível do Banco de Dados do Azure para PostgreSQL. Os exemplos anteriores mostram a execução dessa função com o parâmetro opcional de nome de usuário omitido ou definido como nulo, o que executa o trabalho no contexto do usuário que está agendando o trabalho, que deve ter privilégios da função azure_pg_admin.
Para atualizar ou alterar o nome do banco de dados do agendamento existente
SELECT cron.alter_job(job_id:=MyJobID,database:='NewDBName');
pg_failover_slots
A extensão PG Failover Slots aprimora o servidor flexível do Banco de Dados do Azure para PostgreSQL ao operar com servidores habilitados para replicação lógica e alta disponibilidade. Ela aborda efetivamente o desafio dentro do mecanismo PostgreSQL padrão que não preserva slots de replicação lógica após um failover. A manutenção desses slots é fundamental para evitar pausas de replicação ou incompatibilidades de dados durante as alterações de função de servidor primário, garantindo a continuidade operacional e a integridade dos dados.
A extensão simplifica o processo de failover gerenciando a transferência, a limpeza e a sincronização necessárias de slots de replicação, fornecendo assim uma transição perfeita durante as alterações de função de servidor. A extensão tem suporte para as versões 11 a 16 do PostgreSQL.
Você pode encontrar mais informações e como usar a extensão de Slots de Failover PG na página do GitHub.
Habilitar pg_failover_slots
Para habilitar a extensão PG Failover Slots para sua instância do servidor flexível do Banco de Dados do Azure para PostgreSQL, você precisa modificar a configuração do servidor incluindo a extensão nas bibliotecas de pré-carregamento compartilhadas do servidor e ajustando um parâmetro específico do servidor. Veja o processo:
- Adicione
pg_failover_slotsàs bibliotecas de pré-carregamento compartilhadas do servidor atualizando o parâmetroshared_preload_libraries. - Altere o parâmetro do servidor
hot_standby_feedbackparaon.
Qualquer alteração no parâmetro shared_preload_libraries exige uma reinicialização do servidor para entrar em vigor.
Usando o portal do Azure:
- Selecione sua instância do servidor flexível do Banco de Dados do Azure para PostgreSQL.
- No menu de recursos, na seção Configurações, selecione Parâmetros do servidor.
- Procure o parâmetro
shared_preload_librariese edite seu valor para incluirpg_failover_slots. - Pesquise o parâmetro
hot_standby_feedbacke defina seu valor comoon. - Escolha Salvar para preservar as alterações. Agora, você tem a opção de Salvar e reiniciar. Escolha essa opção para garantir que as alterações tenham efeito, pois a modificação de
shared_preload_librariesexige a reinicialização do servidor.
Ao selecionar Salvar e reiniciar, o servidor será reinicializado automaticamente, aplicando as alterações que acabaram de ser feitas. Quando o servidor estiver online novamente, a extensão PG Failover Slots estará habilitada e operacional em sua instância primária do servidor flexível do Banco de Dados do Azure para PostgreSQL, pronta para lidar com slots de replicação lógica durante failovers.
pg_hint_plan
pg_hint_plan possibilita ajustar os planos de execução do PostgreSQL usando as chamadas "dicas" nos comentários do SQL, como:
/*+ SeqScan(a) */
pg_hint_plan lê frases de dica em um comentário de formulário especial fornecido com a instrução SQL de destino. O formulário especial começa pela sequência de caracteres "/*+" e termina com "*/". As frases de dica consistem no nome da dica e nos seguintes parâmetros, entre parênteses e delimitados por espaços. Novas linhas para legibilidade podem delimitar cada frase sugerida.
Exemplo:
/*+
HashJoin(a b)
SeqScan(a)
*/
SELECT *
FROM pgbench_branches b
JOIN pgbench_accounts an ON b.bid = a.bid
ORDER BY a.aid;
O exemplo anterior faz com que o planejador use os resultados de um seq scan na tabela a para ser combinado com a tabela b como um hash join.
Para instalar o pg_hint_plan, além disso, para permitir listá-lo, conforme mostrado em como usar as extensões do PostgreSQL, você precisa incluí-lo nas bibliotecas de pré-carregamento compartilhadas do servidor. Uma alteração no parâmetro shared_preload_libraries do Postgres exige uma shared_preload_libraries para entrar em vigor. Altere os parâmetros usando o portal do Azure ou a CLI do Azure.
Usando o portal do Azure:
- Selecione sua instância do servidor flexível do Banco de Dados do Azure para PostgreSQL.
- No menu de recursos, na seção Configurações, selecione Parâmetros do servidor.
- Procure o parâmetro
shared_preload_librariese edite seu valor para incluirpg_hint_plan. - Escolha Salvar para preservar as alterações. Agora, você tem a opção de Salvar e reiniciar. Escolha essa opção para garantir que as alterações tenham efeito, pois a modificação de
shared_preload_librariesexige a reinicialização do servidor. Agora você pode habilitar pg_hint_plan em seu servidor flexível do Banco de Dados do Azure para PostgreSQL. Conecte-se ao banco de dados e emita o seguinte comando:
CREATE EXTENSION pg_hint_plan;
pg_prewarm
A extensão pg_prewarm carrega dados relacionais no cache. O pré-aquecimento dos caches significa que as consultas têm tempos de resposta melhores na primeira execução após uma reinicialização. A funcionalidade de preaquecimento automático não está disponível atualmente no servidor flexível do Banco de Dados do Azure para PostgreSQL.
pg_repack
Uma pergunta típica que as pessoas fazem quando tentam usar essa extensão pela primeira vez é: O pg_repack é uma extensão ou um executável do lado do cliente, como o psql ou o pg_dump?
A resposta é que, na verdade, ele é ambos. pg_repack/lib contém o código da extensão, incluindo o esquema e os artefatos SQL que ele cria, e a biblioteca C que implementa o código de várias dessas funções. Por outro lado, pg_repack/bin mantém o código do aplicativo cliente, que sabe como interagir com os artefatos de programação criados pela extensão. Esse aplicativo cliente tem como objetivo facilitar a complexidade da interação com as diferentes interfaces exibidas pela extensão do lado do servidor, oferecendo ao usuário algumas opções de linha de comando que são mais fáceis de entender. O aplicativo cliente sem a extensão criada no banco de dados para o qual ele está apontado é inútil. A extensão do lado do servidor, por si só, seria totalmente funcional, mas exigiria que o usuário entendesse um padrão de interação complicado que consiste na execução de consultas para recuperar dados que são usados como entrada para as funções implementadas pela extensão.
Permissão negada para reempacotamento do esquema
Até o momento, devido à maneira como concedemos permissões ao esquema de reempacotamento criado por esta extensão, só há suporte para executar a funcionalidade pg_repack a partir do contexto de azure_pg_admin.
Você pode notar que se o proprietário de uma tabela, que não é azure_pg_admin, tentar executar o pg_repack, ele acabará recebendo um erro como o seguinte:
NOTICE: Setting up workers.conns
ERROR: pg_repack failed with error: ERROR: permission denied for schema repack
LINE 1: select repack.version(), repack.version_sql()
Para evitar esse erro, certifique-se de executar o pg_repack no contexto de azure_pg_admin.
pg_stat_statements
A extensão pg_stat_statements fornece uma exibição de todas as consultas que foram executadas em seu banco de dados. Isso é útil para entender como é o desempenho da carga de trabalho de consulta em um sistema de produção.
A extensão pg_stat_statements é pré-carregada em shared_preload_libraries em cada instância de servidor flexível do Banco de Dados do Azure para PostgreSQL para fornecer a você formas de acompanhar as estatísticas de execução das instruções SQL.
No entanto, por razões de segurança, você ainda precisa adicionar à allowlist a extensão pg_stat_statements e instalá-la usando o comando CREATE EXTENSION.
A configuração pg_stat_statements.track, que controla quais instruções são contadas por extensão, tem top como padrão, que significa que todas as instruções emitidas diretamente por clientes são rastreadas. Dois outros níveis de rastreamento são none e all. Essa configuração é configurável como um parâmetro de servidor.
O pg_stat_statements oferece informações de execução de consulta como benefício, mas prejudica o desempenho do servidor, pois registra todas as instruções SQL. Se você não está usando ativamente a extensão pg_stat_statements, recomendamos que você defina pg_stat_statements.track como none. Alguns serviços de monitoramento de terceiros podem depender do pg_stat_statements para fornecer análises de desempenho de consultas. Portanto, confirme se este é o seu caso ou não.
postgres_fdw
postgres_fdw permite que você se conecte de uma instância do servidor flexível do Banco de Dados do Azure para PostgreSQL a outra, ou a outro banco de dados no mesmo servidor. O servidor flexível do Banco de Dados do Azure para PostgreSQL dá suporte a conexões de entrada e saída para qualquer servidor PostgreSQL. O servidor de envio precisa permitir conexões de saída para o servidor de recebimento. Dessa forma, o servidor de recebimento precisa permitir conexões do servidor de envio por meio de seu firewall.
Se você planeja usar essa extensão, recomendamos implantar seus servidores com integração de rede virtual. Por padrão, a integração da rede virtual permite conexões entre servidores na rede virtual. Você também pode optar por usar grupos de segurança de rede da rede virtual para personalizar o acesso.
pgstattuple
Ao usar a extensão 'pgstattuple' para tentar obter estatísticas de tupla de objetos mantidos no esquema pg_toast em versões do Postgres 11 a 13, você receberá um erro de "permissão negada para o esquema pg_toast".
Permissão negada para o esquema pg_toast
Os clientes que usam as versões 11 a 13 do PostgreSQL no Banco de Dados do Azure para Servidor Flexível não podem usar a extensão pgstattuple em objetos dentro do esquema pg_toast.
No PostgreSQL 16 e 17, a função pg_read_all_data é concedida automaticamente a azure_pg_admin, permitindo que pgstattuple funcione corretamente. No PostgreSQL 14 e 15, os clientes podem conceder manualmente a função pg_read_all_data a azure_pg_admin para obter o mesmo resultado. No entanto, no PostgreSQL 11 a 13, a função pg_read_all_data não existe.
Os clientes não podem conceder diretamente as permissões necessárias. Se você precisar ser capaz de executar pgstattuple para acessar objetos no esquema pg_toast, prossiga para criar uma solicitação de suporte do Azure.
TimescaleDB
O TimescaleDB é um banco de dados de série temporal empacotado como uma extensão para PostgreSQL. Ele fornece funções analíticas orientadas a tempo, otimizações e escala o Postgres para cargas de trabalho de série temporal. Saiba mais sobre o TimescaleDB, uma marca registrada da Timescale, Inc. O servidor flexível do Banco de Dados do Azure para PostgreSQL fornece a edição Apache-2 do TimescaleDB.
Instalar o TimescaleDB
Para instalar o TimescaleDB, além de permitir a listagem, conforme mostrado acima, você precisa incluí-lo nas bibliotecas de pré-carregamento compartilhadas do servidor. Uma alteração no parâmetro shared_preload_libraries do Postgres exige uma shared_preload_libraries para entrar em vigor. Altere os parâmetros usando o portal do Azure ou a CLI do Azure.
Usando o portal do Azure:
- Selecione sua instância do servidor flexível do Banco de Dados do Azure para PostgreSQL.
- No menu de recursos, na seção Configurações, selecione Parâmetros do servidor.
- Procure o parâmetro
shared_preload_librariese edite seu valor para incluirTimescaleDB. - Escolha Salvar para preservar as alterações. Agora, você tem a opção de Salvar e reiniciar. Escolha essa opção para garantir que as alterações tenham efeito, pois a modificação de
shared_preload_librariesexige a reinicialização do servidor. Agora você pode habilitar o TimescaleDB em seu servidor flexível do Banco de Dados do Azure para PostgreSQL. Conecte-se ao banco de dados e emita o seguinte comando:
CREATE EXTENSION IF NOT EXISTS timescaledb CASCADE;
Dica
Se você receber um erro, confirme se você reiniciou o servidor depois de salvar shared_preload_libraries.
Agora você pode criar uma hipertabela do TimescaleDB do zero ou migrar os dados de série temporal existentes no PostgreSQL.
Restaurar um banco de dados da Escala de tempo usando pg_dump e pg_restore
Para restaurar um banco de dados da Escala de tempo usando pg_dump e pg_restore, você precisará executar dois procedimentos auxiliares no banco de dados de destino: timescaledb_pre_restore() e timescaledb_post restore().
Primeiro, prepare o banco de dados de destino:
--create the new database where you want to perform the restore
CREATE DATABASE tutorial;
\c tutorial --connect to the database
CREATE EXTENSION timescaledb;
SELECT timescaledb_pre_restore();
Agora você pode executar pg_dump no banco de dados original e executar pg_restore. Após a restauração, lembre-se de executar o seguinte comando no banco de dados restaurado:
SELECT timescaledb_post_restore();
Para obter mais detalhes sobre o método de restauração com banco de dados habilitado para Timescale, confira a documentação do Timescale.
Restaurando um banco de dados da Escala de tempo usando timescaledb-backup
Durante a execução do procedimento SELECT timescaledb_post_restore() listado acima, você poderá ver erro de permissões negadas ao atualizar o sinalizador timescaledb.restoring. Isso ocorre devido à permissão ALTER DATABASE limitada nos serviços de banco de dados de PaaS de nuvem. Nesse caso, você pode executar um método alternativo usando a ferramenta timescaledb-backup para fazer backup e restaurar o banco de dados do Timescale. Timescaledb-backup é um programa para tornar o despejo e a restauração de um banco de dados TimescaleDB mais simples e menos propenso a erros e aumentar seu desempenho.
Para isso, você deve fazer o que é mostrado abaixo
- Instale as ferramentas conforme detalhado aqui
- Crie uma instância de servidor flexível do Banco de Dados do Azure para PostgreSQL e um banco de dados de destino
- Habilitar a extensão do Timescale conforme mostrado acima
- Conceder a função
azure_pg_adminao usuário que será usada por ts-restore - Executar ts-restore para restaurar o banco de dados
Mais detalhes sobre esses utilitários podem ser encontrados aqui.
Extensões e atualização da versão principal
O servidor flexível do Banco de Dados do Azure para PostgreSQL introduziu um recurso de atualização de versão principal in-loco que executa uma atualização in-loco da instância do servidor flexível do Banco de Dados do Azure para PostgreSQL com apenas um clique. A atualização de versão principal in-loco simplifica o processo de atualização do servidor flexível do Banco de Dados do Azure para PostgreSQL, minimizando a interrupção dos usuários e aplicativos que acessam o servidor. A atualização de versão principal in-loco não dá suporte a extensões específicas e há algumas limitações para atualizar certas extensões. As extensões anon, Apache AGE, dblink, orafce, pgaudit, postgres_fdw, e Timescaledb não têm suporte para todas as versões do servidor flexível do Banco de Dados do Azure para PostgreSQL ao usar o recurso de atualização de versão principal in-loco.