Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
O Armazenamento de Blobs do Azure é uma solução de armazenamento de objetos para a nuvem da Microsoft. Ele foi projetado para armazenar grandes quantidades de dados não estruturados, como texto, dados binários, documentos, arquivos de mídia e backups de aplicativos. Como um serviço de armazenamento fundamental do Azure, o Blob Storage oferece vários recursos de confiabilidade para garantir que seus dados permaneçam disponíveis e duráveis durante eventos planejados e não planejados.
Quando você usa o Azure, a confiabilidade é uma responsabilidade compartilhada. A Microsoft fornece uma variedade de recursos para dar suporte à resiliência e recuperação. Você é responsável por entender como esses recursos funcionam em todos os serviços que você usa e selecionar os recursos necessários para atender aos seus objetivos de negócios e metas de tempo de atividade.
Este artigo descreve como tornar o Armazenamento de Blobs resiliente a uma variedade de possíveis interrupções e problemas, incluindo falhas transitórias, interrupções de zona de disponibilidade e interrupções de região. Ele também descreve como você pode usar backups para se recuperar de outros tipos de problemas e realça algumas informações importantes sobre o SLA (contrato de nível de serviço) do Armazenamento de Blobs.
Observação
O Blob Storage faz parte da plataforma de Armazenamento do Azure. Alguns dos recursos do Armazenamento de Blobs são comuns em muitos serviços de Armazenamento do Azure. Neste artigo, usamos Armazenamento do Azure para nos referirmos a esses recursos.
Recomendações de implantação de produção
Para aprender como implantar o Blob Storage para atender aos requisitos de confiabilidade da sua solução e como a confiabilidade afeta outros aspectos da sua arquitetura, consulte Práticas recomendadas de arquitetura para o Blob Storage no Azure Well-Architected Framework.
Visão geral da arquitetura de confiabilidade
O Armazenamento do Azure oferece várias opções de redundância para ajudar a proteger seus dados contra diferentes tipos de falhas. Cada opção oferece um nível específico de redundância de dados, permitindo que você escolha o nível que melhor atenda aos requisitos da sua aplicação.
O armazenamento com redundância local (LRS) replica os dados em suas contas de armazenamento para uma ou mais zonas de disponibilidade do Azure localizadas na região primária de sua escolha. Embora não haja nenhuma opção para escolher sua zona de disponibilidade preferencial, o Azure pode mover ou expandir contas LRS entre zonas para melhorar o balanceamento de carga. Não há garantia de que seus dados serão distribuídos entre zonas. Para obter informações sobre zonas de disponibilidade, consulte O que são as Zonas de Disponibilidade?.

O armazenamento com redundância de zona (ZRS), o armazenamento com redundância geográfica (GRS) e o armazenamento com redundância de zona geográfica (GZRS) fornecem proteções extras. Este artigo descreve essas opções em detalhes.
Resiliência a falhas transitórias
Falhas transitórias são falhas curtas e intermitentes nos componentes. Elas ocorrem com frequência em um ambiente distribuído, como a nuvem, e são uma parte normal das operações. Falhas transitórias se corrigem após um curto período de tempo. É importante que seus aplicativos possam lidar com falhas transitórias, geralmente repetindo solicitações afetadas.
Todos os aplicativos hospedados na nuvem devem seguir as diretrizes transitórias de tratamento de falhas do Azure quando eles se comunicam com qualquer APIs, bancos de dados e outros componentes hospedados na nuvem. Para obter mais informações, confira Recomendações para tratamento de falhas transitórias.
Para gerenciar de forma eficaz as falhas transitórias ao usar o Blob Storage, implemente as seguintes recomendações:
Use as bibliotecas de clientes do Armazenamento do Azure, que incluem políticas de repetição internas com retirada exponencial e tremulação. Os SDKs .NET, Java, Python e JavaScript lidam automaticamente com novas tentativas para falhas transitórias. Para mais informações sobre opções de configuração de repetição, consulte Implementar uma política de repetição com .NET.
Configure valores de tempo limite apropriados para suas operações de blob com base no tamanho do blob e nas condições de rede. Blobs maiores exigem tempos limite mais longos, mas operações menores podem usar valores mais curtos para detectar falhas rapidamente.
Resiliência a falhas de zona de disponibilidade
As zonas de disponibilidade são grupos fisicamente separados de datacenters em uma região do Azure. Quando uma zona falha, os serviços podem fazer o failover de uma das zonas restantes.
O Blob Storage oferece suporte robusto a zonas de disponibilidade por meio de configurações ZRS, que distribuem automaticamente seus dados entre várias zonas de disponibilidade dentro de uma região. Diferente do armazenamento localmente redundante (LRS), o ZRS garante que o Azure replique seus dados de blob de forma síncrona em várias zonas de disponibilidade. O ZRS garante que seus dados permaneçam acessíveis mesmo que uma zona experimente uma interrupção.
A redundância de zona é habilitada no nível da conta de armazenamento e se aplica a todos os contêineres de blob nessa conta. Você não pode definir níveis diferentes de redundância para contêineres individuais. A configuração de redundância é aplicada a toda a conta de armazenamento. Quando uma zona de disponibilidade sofre uma interrupção, o Armazenamento do Azure roteia automaticamente as solicitações para zonas saudáveis sem exigir intervenção sua ou da sua aplicação.

Requirements
- Suporte à região: Você pode implantar contas de Armazenamento do Azure com redundância de zona em qualquer região que dê suporte a zonas de disponibilidade.
- Tipos de conta de armazenamento: a redundância de zona está disponível para os tipos de conta de armazenamento Standard de uso geral v2 e Premium de Blob de Blocos. Blobs de blocos, blobs de acréscimo e blobs de páginas oferecem suporte a configurações redundantes por zona, mas o tipo de conta de armazenamento que você utiliza determina quais recursos estarão disponíveis. Para obter mais informações, consulte Tipos de conta de armazenamento com suporte.
Custo
Ao habilitar o armazenamento com redundância de zona (ZRS), você é cobrado a uma taxa diferente do armazenamento com redundância local (LRS) devido à sobrecarga de armazenamento e replicação extra.
Para mais informações, consulte Preços do Blob Storage.
Configurar o suporte à zona de disponibilidade
- Crie uma conta de armazenamento de blobs com redundância por zona. Para criar uma nova conta de armazenamento com ZRS, consulte Criar uma conta de armazenamento e selecione ZRS, armazenamento georredundante por zona (GZRS) ou armazenamento georredundante por zona com acesso de leitura (RA-GZRS) como a opção de redundância durante a criação da conta.
Como alterar o tipo de replicação Para saber como alterar uma conta de armazenamento existente para armazenamento com redundância de zona (ZRS) e sobre as opções de configuração e os requisitos, consulte Como alterar a forma como uma conta de armazenamento é replicada.
Desabilite a redundância de zona. Converta contas ZRS novamente em uma configuração não zonal, como armazenamento com redundância local (LRS), usando o mesmo processo de alteração de configuração de redundância.
Comportamento quando todas as zonas estão saudáveis
Esta seção descreve o que esperar quando uma conta de armazenamento de filas é configurada para redundância de zona e todas as zonas de disponibilidade estão operacionais.
Roteamento de tráfego entre zonas: o Armazenamento do Azure com armazenamento com redundância de zona (ZRS) distribui automaticamente solicitações entre clusters de armazenamento em várias zonas de disponibilidade. A distribuição de tráfego é transparente para aplicativos e não requer nenhuma configuração do lado do cliente.
Replicação de dados entre zonas: todas as operações de gravação no ZRS são replicadas de forma síncrona em todas as zonas de disponibilidade dentro da região. Quando você carrega ou modifica dados, a operação não é considerada concluída até que os dados sejam replicados com êxito em todas as zonas de disponibilidade. Essa replicação síncrona garante consistência forte e perda de dados zero durante falhas de zona.
Comportamento durante uma falha de zona
Esta seção descreve o que esperar quando uma conta de armazenamento de blobs é configurada para ZRS e há uma interrupção da zona de disponibilidade.
- Detecção e resposta: a Microsoft detecta automaticamente falhas de zona e inicia processos de recuperação. Nenhuma ação do cliente é necessária para contas ZRS (armazenamento com redundância de zona). Se uma zona ficar indisponível, o Azure realizará atualizações de rede, como a renomeação do DNS (Sistema de Nomes de Domínio).
- Notificação: a Microsoft não notifica você automaticamente quando uma zona está inativa. No entanto, você pode usar o Azure Resource Health para monitorar a integridade de um recurso individual e pode configurar alertas do Resource Health para notificá-lo de problemas. Você também pode usar a Integridade do Serviço do Azure para entender a integridade geral do serviço, incluindo quaisquer falhas de zona, e pode configurar alertas de Integridade do Serviço para notificá-lo de problemas.
Solicitações ativas: As solicitações em voo podem ser descartadas durante o processo de recuperação e devem ser repetidas. Os aplicativos devem implementar a lógica de repetição para lidar com essas interrupções temporárias.
Perda de dados esperada: Nenhuma perda de dados ocorre durante falhas de zona porque os dados são replicados de forma síncrona em várias zonas antes da conclusão das operações de gravação.
Tempo de inatividade esperado: uma pequena quantidade de tempo de inatividade, normalmente, alguns segundos, pode ocorrer durante a recuperação automática, pois o tráfego é redirecionado para zonas saudáveis. Ao criar aplicativos para ZRS, siga práticas para manipulação de falha transitórias, incluindo a implementação de políticas de novas tentativas com retirada exponencial.
- Redirecionamento de tráfego: Se uma zona de disponibilidade ficar offline, o Azure inicia alterações de rede, como o redirecionamento do Sistema de Nomes de Domínio (DNS). Essas atualizações garantem que o tráfego seja redirecionado para as zonas de disponibilidade saudáveis restantes. O serviço mantém a funcionalidade completa utilizando as zonas sobreviventes e não requer intervenção do cliente.
Recuperação de zona
Quando a zona de disponibilidade com falha é recuperada, o Armazenamento do Azure restaura automaticamente as operações normais em todas as zonas de disponibilidade. O serviço garante automaticamente a consistência dos dados sincronizando todas as operações que ocorreram durante o período de interrupção.
Testar falhas em zonas
Quando você usa o armazenamento com redundância de zona (ZRS), o Armazenamento do Azure gerencia automaticamente a replicação, o roteamento de tráfego e as respostas de zona para baixo. Como esse recurso é totalmente gerenciado, você não precisa iniciar nem validar processos de falha da zona de disponibilidade.
Resiliência a falhas em toda a região
O Armazenamento do Azure, incluindo o Armazenamento de Blobs do Azure, os Arquivos do Azure, o Armazenamento de Tabelas do Azure e o Armazenamento de Filas do Azure, fornece uma variedade de recursos de redundância geográfica e failover para atender a diferentes requisitos.
Importante
O armazenamento com redundância geográfica (GRS) só funciona em regiões emparelhadas do Azure. Se a região da sua conta de armazenamento não estiver emparelhada, considere usar as soluções personalizadas de várias regiões para resiliência.
Armazenamento georredundante para regiões emparelhadas
O Armazenamento do Azure fornece vários tipos de GRS em regiões emparelhadas. Seja qual for o tipo de GRS usado, os dados na região secundária são sempre replicados usando armazenamento com redundância local (LRS). Essa abordagem fornece proteção contra falhas de hardware na região secundária.
O GRS fornece suporte para failovers planejados e não planejados para a região emparelhada do Azure quando há uma interrupção na região primária. O GRS replica de forma assíncrona os dados da região primária para a região emparelhada.
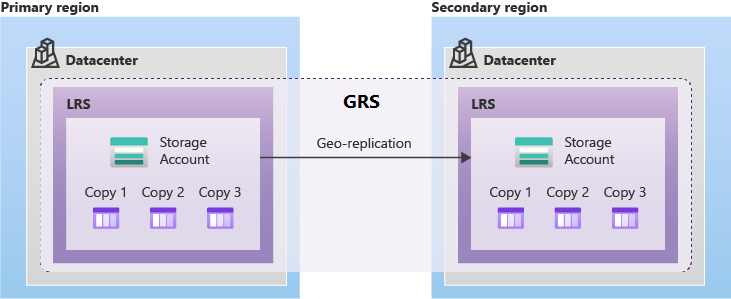
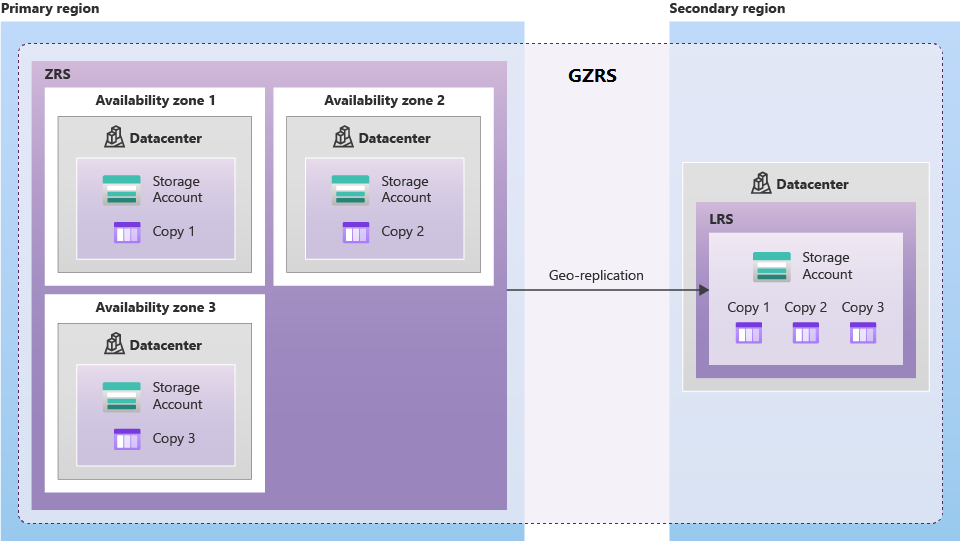
O armazenamento com redundância de zona geográfica (GZRS) replica dados em várias zonas de disponibilidade na região primária e na região emparelhada.


- O armazenamento com redundância geográfica com acesso de leitura (RA-GRS) e o armazenamento com redundância geográfica de zona de acesso de leitura (RA-GZRS) estendem o GRS e o GZRS, com o benefício adicional de acesso de leitura ao ponto de extremidade secundário. Essas opções são ideais para aplicativos criados para aplicativos comercialmente críticos de alta disponibilidade. No caso improvável de o ponto de extremidade primário sofrer uma interrupção, os aplicativos configurados para acesso de leitura à região secundária podem continuar operando.
Tipos de failover
O Armazenamento do Azure dá suporte a três tipos de failover para cenários diferentes.
Failover não planejado gerenciado pelo cliente: você será responsável por iniciar a recuperação se houver uma falha de armazenamento em toda a região em sua região primária.
Failover planejado gerenciado pelo cliente: Você será responsável por iniciar a recuperação se outra parte da sua solução tiver uma falha em sua região primária e precisar mudar toda a solução para uma região secundária. Use um failover planejado quando o armazenamento permanecer operacional na região primária, mas você precisar fazer failover de toda a solução para uma região secundária, como em simulações de recuperação de desastres projetadas para atender aos requisitos de conformidade e auditoria.
Failover gerenciado pela Microsoft: em circunstâncias excepcionais, a Microsoft pode iniciar o failover para todas as contas GRS (armazenamento com redundância geográfica) em uma região. No entanto, o failover gerenciado pela Microsoft é um último recurso e deve ser executado somente após um longo período de interrupção. Você não deve confiar no failover gerenciado pela Microsoft.
As contas de GRS podem usar qualquer um desses tipos de failover. Você não precisa pré-configurar uma conta de armazenamento para usar qualquer um dos tipos de failover antecipadamente.
Requirements
Suporte à região: As configurações com redundância geográfica do Armazenamento do Azure usam regiões emparelhadas do Azure para replicação de região secundária. A região secundária é determinada automaticamente com base na seleção da região primária e não pode ser personalizada. Para obter uma lista completa de regiões emparelhadas do Azure, consulte a lista de regiões do Azure.
Se a região da sua conta de armazenamento não estiver emparelhada, considere usar as soluções personalizadas de várias regiões para resiliência.
- Tipos de conta de armazenamento: O GRS (armazenamento com redundância geográfica) e o failover e o failback iniciados pelo cliente estão disponíveis em todas as regiões emparelhadas do Azure que dão suporte a contas de Armazenamento do Azure v2 de uso geral.
Considerações
Ao implementar o Blob Storage multirregional, considere os seguintes fatores principais:
Latência de replicação assíncrona: a replicação de dados para a região secundária é assíncrona, o que significa que há um atraso entre quando os dados são gravados na região primária e quando ficam disponíveis na região secundária. Esse atraso poderá resultar em uma possível perda de dados se ocorrer uma falha na região primária antes que os dados recentes sejam replicados. A perda de dados é medida pelo objetivo de ponto de recuperação (RPO). Você pode esperar que o atraso de replicação seja inferior a 15 minutos, mas esse tempo é uma estimativa e não é garantido.
Você pode verificar a propriedade Hora da Última Sincronização para entender quantos dados podem ser perdidos se sua conta de armazenamento tiver um failover não planejado.
Acesso à região secundária: Com o armazenamento com redundância geográfica (GRS) e configurações de armazenamento com redundância de zona geográfica (GZRS), a região secundária não será acessível para leituras até que ocorra um failover.
O armazenamento com redundância geográfica de acesso de leitura (RA-GRS) e as configurações de armazenamento com redundância de zona geográfica de acesso de leitura (RA-GZRS) fornecem acesso de leitura à região secundária durante operações normais, mas devido à latência de replicação assíncrona, eles podem retornar dados ligeiramente desatualizados.
- Limitações de recursos: alguns recursos do Armazenamento do Azure não têm suporte ou têm limitações quando você usa GRS (armazenamento com redundância geográfica) ou failover gerenciado pelo cliente. Examine a compatibilidade de recursos antes de implementar a redundância geográfica.
Custo
As configurações da conta de Armazenamento do Microsoft Azure de várias regiões incorrem em custos adicionais para replicação e armazenamento entre regiões na região secundária. A transferência de dados entre regiões do Azure é cobrada com base nas taxas de largura de banda entre regiões padrão.
Para mais informações, consulte Preços do Blob Storage.
Configurar o suporte a várias regiões
- Crie uma nova conta de armazenamento com redundância geográfica (GRS). Para criar uma conta de GRS, consulte Como criar uma conta de armazenamento e selecionar GRS, armazenamento com redundância geográfica de acesso de leitura (RA-GRS), armazenamento com redundância de zona geográfica (GZRS) ou armazenamento com redundância de zona geográfica de acesso de leitura (RA-GZRS) durante a criação da conta.
Habilite a redundância geográfica em uma conta de armazenamento existente. Para converter uma conta de armazenamento existente em GRS (armazenamento com redundância geográfica), consulte Alterar como uma conta de armazenamento é replicada.
Aviso
Depois que sua conta for reconfigurada para redundância geográfica, pode levar uma quantidade significativa de tempo até que os dados existentes na nova região primária sejam totalmente copiados para a nova secundária.
Para evitar uma grande perda de dados, verifique o valor da propriedade Hora da Última Sincronização antes de iniciar um failover não planejado. Para avaliar a possível perda de dados, compare a hora da última sincronização com a última vez em que os dados foram gravados na nova primária.
Habilitar a redundância geográfica Converta contas GRS novamente em configurações de região única, como armazenamento com redundância local (LRS ) ou armazenamento com redundância de zona (ZRS) usando o mesmo processo de alteração de configuração de redundância.
Comportamento quando todas as regiões estão saudáveis
Esta seção descreve o que esperar quando uma conta de armazenamento é configurada para redundância geográfica e todas as regiões estão operacionais.
Roteamento de tráfego entre regiões: o Armazenamento do Azure usa uma abordagem ativa-passiva em que todas as operações de gravação e a maioria das operações de leitura são direcionadas para a região primária.
Para configurações de armazenamento com redundância geográfica de acesso de leitura (RA-GRS) e armazenamento com redundância de zona geográfica de acesso de leitura (RA-GZRS), os aplicativos podem, opcionalmente, ler da região secundária acessando o ponto de extremidade secundário. Essa abordagem requer a configuração explícita do aplicativo e não é automática. Além disso, devido ao atraso de replicação assíncrona, os dados na região secundária podem estar ligeiramente desatualizados.
Replicação de dados entre regiões: as operações de gravação são confirmadas pela primeira vez na região primária usando os seguintes tipos de redundância configurados:
- Armazenamento com redundância local (LRS) para armazenamento com redundância geográfica (GRS) e RA-GRS
- Armazenamento com redundância de zona (ZRS) para armazenamento com redundância de zona geográfica (GZRS) e RA-GZRS
Após a conclusão bem-sucedida na região primária, os dados são replicados de forma assíncrona para a região secundária em que são armazenados usando LRS.
A natureza assíncrona da replicação entre regiões significa que normalmente há um tempo de retardo entre quando os dados são gravados na região primária e quando estão disponíveis na região secundária. Você pode monitorar o tempo de replicação usando a propriedade Hora da Última Sincronização.
Comportamento durante uma falha de região
Esta seção descreve o que esperar quando uma conta de armazenamento é configurada para redundância geográfica e há uma interrupção na região primária.
Failover gerenciado pelo cliente (não planejado): Use um failover não planejado quando o armazenamento na região primária não estiver disponível.
Detecção e resposta: Caso sua conta de armazenamento não esteja disponível em sua região primária, você pode considerar iniciar um failover não planejado gerenciado pelo cliente. Para tomar essa decisão, considere os seguintes fatores:
Se o Azure Resource Health mostra problemas ao acessar a conta de armazenamento em sua região primária
Se a Microsoft aconselhou você a executar failover para outra região
Aviso
Um failover não planejado pode resultar em perda de dados. Antes de iniciar um failover gerenciado pelo cliente, decida se a restauração do serviço justifica o risco de perda de dados.
Notificação: a Microsoft não notifica você automaticamente quando uma região está inoperante. No entanto:
Você pode usar o Azure Resource Health para monitorar a integridade de um recurso individual e configurar alertas do Resource Health para notificá-lo de problemas.
Você pode usar a Integridade do Serviço do Azure para entender a integridade geral do serviço, incluindo quaisquer falhas na região, e pode configurar alertas de Integridade do Serviço para notificá-lo de problemas.
Solicitações ativas: Durante o processo de failover, os pontos de extremidade da conta de armazenamento primário e secundário ficam temporariamente indisponíveis para leituras e gravações. Todas as solicitações ativas podem ser descartadas e os aplicativos cliente precisam tentar novamente após a conclusão do failover.
Perda de dados esperada: a perda de dados é comum durante um failover não planejado devido ao atraso de replicação assíncrona, o que significa que as gravações recentes podem não ser replicadas. Você pode verificar a propriedade Hora da Última Sincronização para entender quantos dados podem ser perdidos durante um failover não planejado. A perda de dados esperada geralmente é chamada de RPO (objetivo de ponto de recuperação). Normalmente, você pode esperar que o RPO seja inferior a 15 minutos, mas esse tempo não é garantido.
Tempo de inatividade esperado: A quantidade de tempo de inatividade esperado geralmente é chamada de RTO (objetivo de tempo de recuperação). O failover gerenciado pelo cliente normalmente é concluído dentro de 60 minutos, dependendo do tamanho e da complexidade da conta.
Redirecionamento de tráfego: À medida que o failover é concluído, o Azure atualiza automaticamente os pontos de extremidade da conta de armazenamento para que os aplicativos não precisem ser reconfigurados. Se o aplicativo mantiver as entradas do DNS (Sistema de Nomes de Domínio) armazenadas em cache, talvez seja necessário limpar o cache para garantir que o aplicativo envie tráfego para a nova região primária.
Configuração pós-failover: depois que um failover não planejado for concluído, sua conta de armazenamento na região de destino usará a camada LRS (armazenamento com redundância local). Se você precisar replicá-lo geograficamente novamente, será necessário habilitar novamente o armazenamento com redundância geográfica (GRS) e aguardar que os dados sejam replicados para a nova região secundária.
Para obter mais informações sobre como iniciar o failover gerenciado pelo cliente, consulte Como o failover gerenciado pelo cliente (não planejado) funciona e Como iniciar um failover de conta de armazenamento.
Failover gerenciado pelo cliente (planejado): uma recuperação panejada destina-se a ser usado quando o armazenamento permanece operacional na região primária, mas você precisa fazer failover de toda a solução para uma região secundária por outro motivo. Por exemplo, outro serviço do Azure pode estar enfrentando um problema e você precisa mudar para usar uma região secundária para toda a sua solução. Ou você pode usar um failover planejado para realizar um teste de recuperação de desastre (DR) para fins de atendimento a normas e auditoria.
Detecção e resposta: Você é responsável por decidir fazer failover. Normalmente, você toma essa decisão se precisar fazer failover entre regiões, mesmo que sua conta de armazenamento esteja íntegra. Por exemplo, você pode disparar um *failover* quando houver uma falha grave de outro componente de aplicativo da qual não é possível se recuperar na região primária.
Notificação: a Microsoft não notifica você automaticamente quando uma região está inoperante. No entanto:
Você pode usar o Azure Resource Health para monitorar a integridade de um recurso individual e configurar alertas do Resource Health para notificá-lo de problemas.
Você pode usar a Integridade do Serviço do Azure para entender a integridade geral do serviço, incluindo quaisquer falhas na região, e pode configurar alertas de Integridade do Serviço para notificá-lo de problemas.
Solicitações ativas: Durante o processo de failover, os pontos de extremidade da conta de armazenamento primário e secundário ficam temporariamente indisponíveis para leituras e gravações. Todas as solicitações ativas podem ser descartadas e os aplicativos cliente precisam tentar novamente após a conclusão do failover.
Perda de dados esperada: Nenhuma perda de dados é esperada porque o processo de failover é concluído somente depois que todos os dados são sincronizados, o que resulta em um RPO de zero.
Tempo de inatividade esperado: O failover normalmente é concluído dentro de 60 minutos, o que significa que o RTO esperado é de 60 minutos, dependendo do tamanho e da complexidade da conta. Durante o processo de failover, os pontos de extremidade da conta de armazenamento primário e secundário ficam temporariamente indisponíveis para leituras e gravações.
Redirecionamento de tráfego: À medida que o failover é concluído, o Azure atualiza automaticamente os pontos de extremidade da conta de armazenamento para que os aplicativos não precisem ser reconfigurados. Se o aplicativo mantiver as entradas DNS armazenadas em cache, talvez seja necessário limpar o cache para garantir que o aplicativo envie tráfego para a nova região primária.
Configuração pós-failover: Depois que um failover planejado for concluído, sua conta de armazenamento na região de destino continuará sendo replicada geograficamente e permanecerá na camada GRS.
Para obter mais informações sobre como iniciar o failover gerenciado pelo cliente, consulte Como o failover gerenciado pelo cliente (planejado) funciona e Como iniciar um failover de conta de armazenamento.
Failover gerenciado pela Microsoft: No raro caso de um grande desastre em que a Microsoft determina que a região primária é permanentemente irrecuperável, um failover automático para a região secundária pode ser iniciado. A Microsoft lida com todo o processo e nenhuma ação do cliente é necessária. O tempo decorrido antes do failover depende da gravidade do desastre e do tempo necessário para avaliar a situação.
Notificação: a Microsoft não notifica você automaticamente quando uma região está inoperante. No entanto:
Você pode usar o Azure Resource Health para monitorar a integridade de um recurso individual e configurar alertas do Resource Health para notificá-lo de problemas.
Você pode usar a Integridade do Serviço do Azure para entender a integridade geral do serviço, incluindo quaisquer falhas na região, e pode configurar alertas de Integridade do Serviço para notificá-lo de problemas.
Importante
Use as opções de failover gerenciadas pelo cliente para desenvolver, testar e implementar seus planos de recuperação de desastre. Não confie no failover gerenciado pela Microsoft, que só pode ser usado em circunstâncias extremas. Um failover gerenciado pela Microsoft provavelmente é iniciado para uma região inteira. Ele não pode ser iniciado para contas de armazenamento individuais, assinaturas ou clientes. O failover pode ocorrer em horários diferentes para diferentes serviços do Azure. É recomendável usar o failover gerenciado pelo cliente.
Recuperação de região
O processo de failback difere significativamente entre cenários de failover gerenciados pela Microsoft e gerenciados pelo cliente.
Failover gerenciado pelo cliente (não planejado): após um failover não planejado, a conta de armazenamento é configurada com LRS (armazenamento com redundância local). Para realizar o failback, você precisará restabelecer a relação GRS e aguardar a replicação dos dados.
Failover gerenciado pelo cliente (planejado): após um failover planejado, a conta de armazenamento permanece replicada geograficamente. Você poderá iniciar outro failover gerenciado pelo cliente para fazer failback para a região primária original. As mesmas considerações de failover se aplicam.
Failover gerenciado pela Microsoft: se a Microsoft iniciar um failover, é provável que ocorreu um desastre significativo na região primária e a região primária pode não ser recuperável. Quaisquer linhas do tempo ou planos de recuperação dependem da extensão dos esforços regionais de desastre e recuperação. Você deve monitorar as comunicações de Integridade do Serviço do Azure para obter detalhes.
Teste de falhas na região
Você pode simular falhas regionais para testar os procedimentos de recuperação de desastre.
Teste de failover planejado: para contas de armazenamento com redundância geográfica (GRS), você pode executar operações de recuperação panejada durante as janelas de manutenção para testar o processo completo de failover e failback. Embora a recuperação panejada não exija perda de dados, ele envolve tempo de inatividade durante o failover e o failback.
Teste de ponto de extremidade secundário: para configurações de armazenamento com redundância geográfica de acesso de leitura (RA-GRS) e armazenamento com redundância de zona geográfica de acesso de leitura (RA-GZRS), teste regularmente as operações de leitura no ponto de extremidade secundário para garantir que seu aplicativo possa ler com êxito os dados da região secundária.
Soluções personalizadas de várias regiões para resiliência
Os recursos de failover entre regiões do Armazenamento do Azure podem ser inadequados devido aos seguintes motivos:
Sua conta de armazenamento está em uma região não emparelhada.
Seus objetivos de disponibilidade operacional não são satisfeitos pelo tempo de recuperação ou perda de dados que as opções de failover internas fornecem.
Você precisa fazer failover para uma região que não seja o par da região primária.
Você precisa de uma configuração ativa/ativa entre as regiões.
Esta seção fornece uma visão geral de alto nível de algumas abordagens a serem consideradas. Uma visão geral abrangente das topologias de implantação de várias regiões para o Armazenamento do Azure está fora do escopo deste artigo.
Você pode implantar o Armazenamento do Azure em várias regiões usando contas de armazenamento separadas em cada região. Essa abordagem fornece flexibilidade na seleção de região, a capacidade de usar regiões não emparelhadas e um controle mais granular sobre o tempo de replicação e a consistência dos dados. Ao implementar várias contas de armazenamento entre regiões, você precisa configurar a replicação de dados entre regiões, implementar políticas de failover e balanceamento de carga e garantir a consistência dos dados entre regiões.
A replicação de objetos oferece uma opção extra para replicação de dados entre regiões, fornecendo a cópia assíncrona de blobs de blocos entre contas de armazenamento. Diferente das opções integradas de armazenamento georredundante que usam regiões emparelhadas fixas, a replicação de objetos permite replicar dados entre contas de armazenamento em qualquer região do Azure, incluindo regiões não emparelhadas. Essa abordagem fornece controle total sobre regiões de origem e destino, políticas de replicação e os contêineres e prefixos de blob específicos a serem replicados.
Você pode configurar a replicação de objetos para replicar todos os blobs dentro de um contêiner ou subconjuntos específicos com base em prefixos e marcas de blobs. A replicação é assíncrona e ocorre em segundo plano. Você pode configurar várias políticas de replicação e até mesmo a replicação em cadeia em várias contas de armazenamento para criar topologias sofisticadas de várias regiões.
A replicação de objeto não é compatível com todas as contas de armazenamento. Por exemplo, ela não funciona com contas de armazenamento que usam namespaces hierárquicos (também conhecidas como contas do Azure Data Lake Storage Gen2).
Para mais informações, consulte Replicação de objetos para blobs de blocos e Configurar replicação de objetos.
Backup e recuperação
O Blob Storage fornece vários mecanismos de proteção de dados que complementam a redundância para estratégias abrangentes de backup. A redundância integrada do serviço protege contra falhas de infraestrutura, e os recursos extras de backup protegem contra exclusão acidental, corrupção e atividades maliciosas.
A restauração pontual (PITR) permite restaurar dados de blobs de blocos para um estado anterior dentro de um período de retenção configurado de até 365 dias. A Microsoft gerencia totalmente esse recurso. Ele também fornece recursos granulares de recuperação no nível do contêiner ou do blob. Os dados do PITR são armazenados na mesma região que a conta de origem e permanecem acessíveis mesmo durante interrupções regionais, caso você utilize configurações georredundantes.
O versionamento de blobs mantém automaticamente versões anteriores dos blobs quando eles são modificados ou excluídos. Cada versão é armazenada como um objeto separado e pode ser acessada de forma independente. As versões são armazenadas na mesma região que o blob atual e seguem a mesma configuração de redundância que a conta de armazenamento.
A exclusão reversível fornece uma rede de segurança para blobs e contêineres excluídos acidentalmente retendo dados excluídos por um período configurável. Os dados excluídos de forma reversível permanecem na mesma conta e região de armazenamento, o que os torna imediatamente disponíveis para recuperação. Para contas com redundância geográfica, os dados excluídos suavemente também são replicados para a região secundária.
As instantâneas de blobs criam cópias somente leitura, em um ponto específico no tempo, dos blobs que você pode usar em cenários de backup e recuperação. Os instantâneos são armazenados na mesma conta de armazenamento e seguem as mesmas configurações de redundância e replicação geográfica que o blob base.
Para requisitos de backup entre regiões, considere usar o Azure Backup para blobs, que fornece gerenciamento centralizado de backup e pode armazenar os dados de backup em regiões diferentes dos dados de origem. Esse serviço fornece opções de backup operacional e em cofre, que possuem políticas de retenção configuráveis e recursos de restauração. Para obter mais informações, consulte Visão geral do Backup para blobs.
Para a maioria das soluções, você não deve depender exclusivamente de backups. Em vez disso, use as outras funcionalidades descritas neste guia para dar suporte aos seus requisitos de resiliência. No entanto, os backups protegem contra alguns riscos que outras abordagens não protegem. Para obter mais informações, consulte O que são redundância, replicação e backup?.
Contrato de nível de serviço
O SLA (contrato de nível de serviço) para o Armazenamento do Azure descreve a disponibilidade esperada do serviço e as condições que devem ser atendidas para atingir essa expectativa de disponibilidade. O SLA de disponibilidade para o qual você está qualificado depende da camada de armazenamento e do tipo de replicação que você usa. Para obter mais informações, consulte SLAs para Serviços Online.