Princípios de recuperação de desastre e preparação
Neste artigo, abordaremos princípios importantes de recuperação de desastre (DR) para Instâncias Grandes do HANA (também conhecidas como Infraestrutura BareMetal). Vamos percorrer as etapas necessárias a serem tomadas na preparação para a recuperação de desastre. Você também verá como obter o RTO (objetivo de tempo de recuperação) e o RPO (objetivo de ponto de recuperação) em um desastre.
Princípios de DR para Instâncias Grandes do HANA
O SAP HANA nas Instâncias Grandes oferece uma funcionalidade de recuperação de desastre entre carimbos do SAP HANA nas Instâncias Grandes em diferentes regiões do Azure. Por exemplo, digamos que você implante o SAP HANA nas Instâncias Grandes na região Oeste dos EUA do Azure. Em seguida, você pode usar o SAP HANA nas Instâncias Grandes na região Leste dos EUA como sua unidade de recuperação de desastre. A recuperação de desastre não está configurada automaticamente porque ela requer que você pague por outra unidade do HANA em Instâncias Grandes na região de recuperação de desastre. A configuração de recuperação de desastre funciona para configurações de expansão e escaláveis.
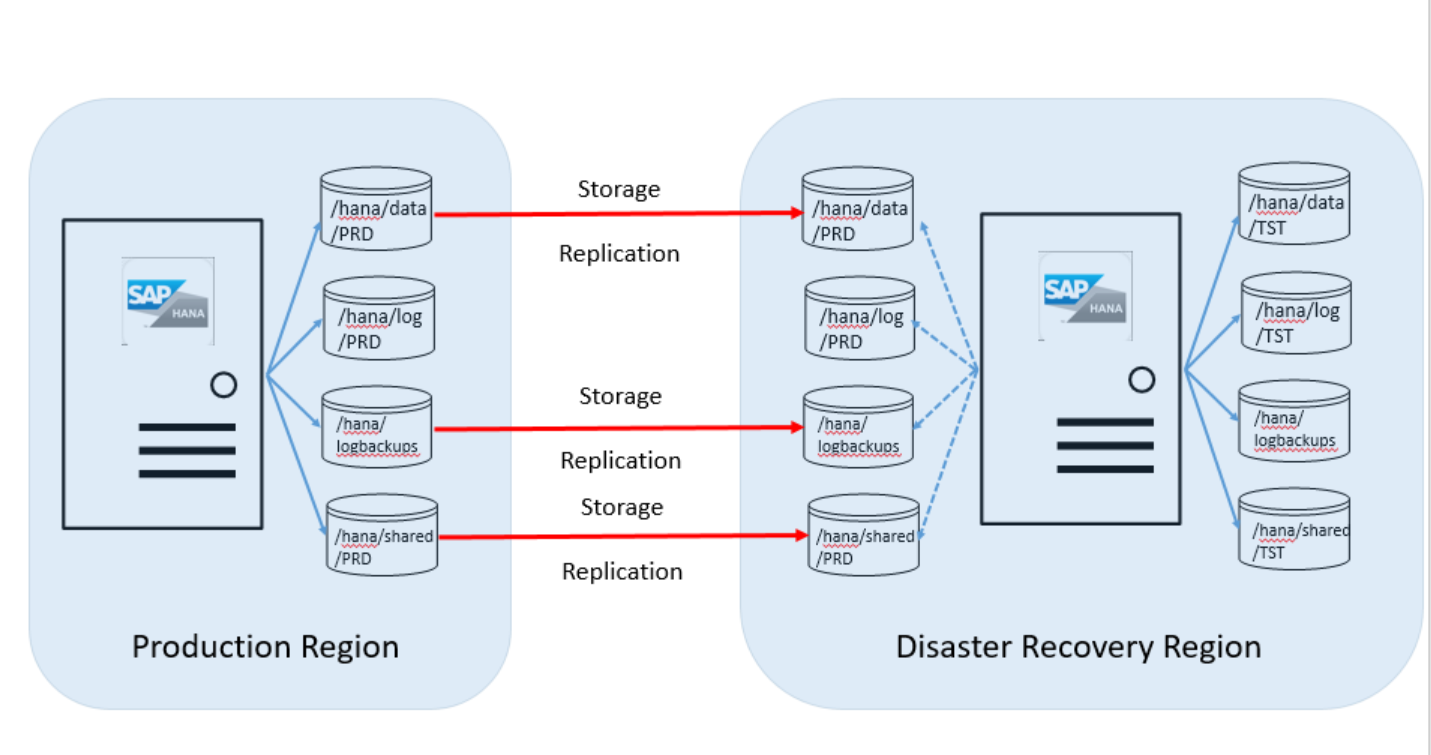
A maioria dos clientes usam a unidade na região de recuperação de desastre para executar os sistemas de não produção que usam uma instância instalada do HANA. A unidade de Instância Grande HANA deve ser da mesma SKU que a SKU usada para fins de produção. A imagem a seguir mostra como é a configuração do disco entre a unidade do servidor na região de produção do Azure e a região de recuperação de desastre:
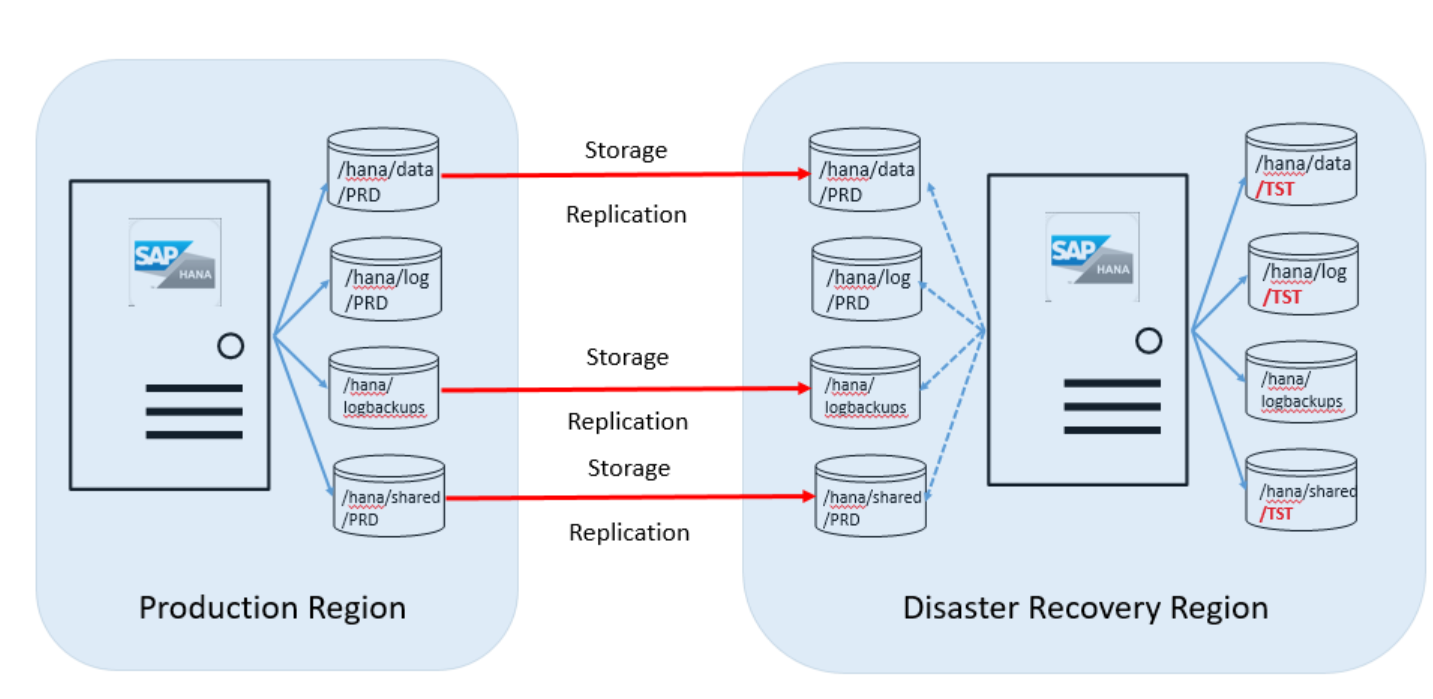
Conforme mostrado neste gráfico de visão geral, é necessário solicitar um segundo conjunto de volumes de disco. Os volumes de disco de destino associados ao servidor do HANA em Instâncias Grandes no site de DR têm o mesmo tamanho que os volumes de produção.
Os volumes a seguir são replicados da região de produção para o local da recuperação de desastre:
- /hana/data
- /hana/logbackups
- /hana/shared (inclui /usr/sap)
O volume /hana/log não é replicado. O log de transações do SAP HANA não é necessário ao restaurar a partir desses volumes.
Replicação de armazenamento do HANA em Instâncias Grandes
A base da funcionalidade da DR na infraestrutura do HANA em Instâncias Grandes é a sua replicação de armazenamento. A funcionalidade usada no lado do armazenamento não é um fluxo constante de alterações replicadas de maneira assíncrona conforme as alterações ocorrem no volume de armazenamento. Em vez disso, ela é um mecanismo que depende da criação de instantâneos desses volumes com regularidade. O delta entre um instantâneo já replicado e um novo que ainda não foi replicado é, então, transferido para o site de recuperação de desastre em volumes de disco de destino. Esses instantâneos são armazenados nos volumes. Se houver um failover de recuperação de desastre, eles precisam ser restaurados nesses volumes.
A primeira transferência dos dados completos do volume deve ser feita antes que a quantidade de dados se torne menor do que os deltas entre instantâneos. Como resultado, os volumes no site de recuperação de desastre contêm todos os instantâneos de volume tirados no local de produção. Eventualmente, é possível usar esse sistema de DR para obter um status anterior para recuperar dados perdidos, sem reverter o sistema de produção.
Se houver uma implantação de MCOD com várias instâncias do SAP HANA independentes em uma unidade do HANA nas Instâncias Grandes, espera-se que todas as instâncias do SAP HANA tenham o armazenamento replicado do lado da recuperação de desastre.
Nos casos em que você usa a Replicação de Sistema do HANA como funcionalidade de alta disponibilidade no seu site de produção e também usa a replicação baseada em armazenamento para o site de DR, os volumes de ambos os nós do site primário para a instância de DR são replicados. Você deve adquirir armazenamento adicional (do mesmo tamanho do nó primário) no site de DR para acomodar a replicação dos nós primário e secundário para a DR.
Observação
A funcionalidade de replicação de armazenamento do SAP HANA nas Instâncias Grandes espelha e replica os instantâneos de armazenamento. Se você não tirar instantâneos de armazenamento conforme descrito em Backup e restauração, não será possível nenhuma replicação para o site de DR. A execução do instantâneo de armazenamento é um pré-requisito para a replicação de armazenamento para o local recuperação de desastres.
Preparação do cenário de recuperação de desastre
Nesse cenário de recuperação de desastre, você tem um sistema de produção sendo executado no SAP HANA nas Instâncias Grandes na região do Azure de produção. Para as etapas a seguir, digamos que o SID desse sistema HANA seja "PRD". Você também tem um sistema que não é de produção em execução no HANA em Instâncias Grandes na região do Azure de DR. O SID é "TST". A imagem a seguir mostra essa configuração:
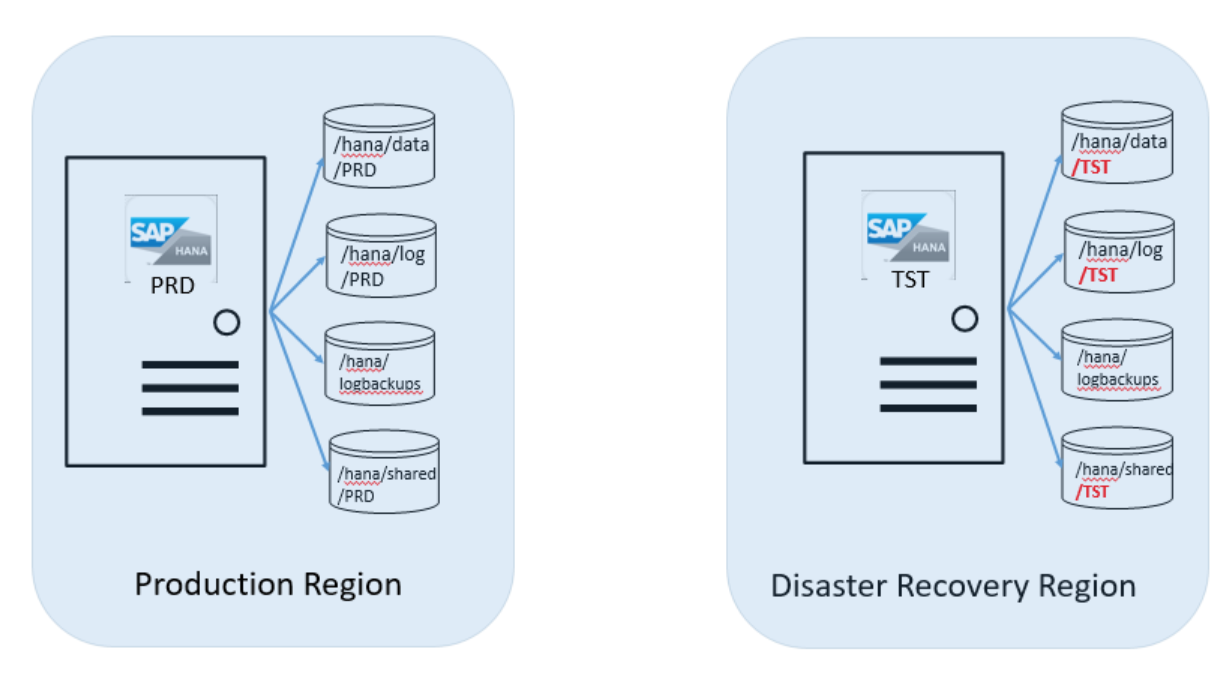
Suponhamos que a instância do servidor ainda não tenha sido ordenada com o volume de armazenamento extra definido. Em seguida, o SAP HANA no Gerenciamento de Serviços do Azure anexa os volumes adicionados. Eles são um destino para a réplica de produção para a Instância Grande do HANA onde você está executando a instância do TST HANA. É necessário fornecer o SID da sua instância HANA de produção. Depois que o Gerenciamento de Serviços do SAP HANA no Azure confirmar a anexação desses volumes, será necessário montar esses volumes na unidade do SAP HANA nas Instâncias Grandes.
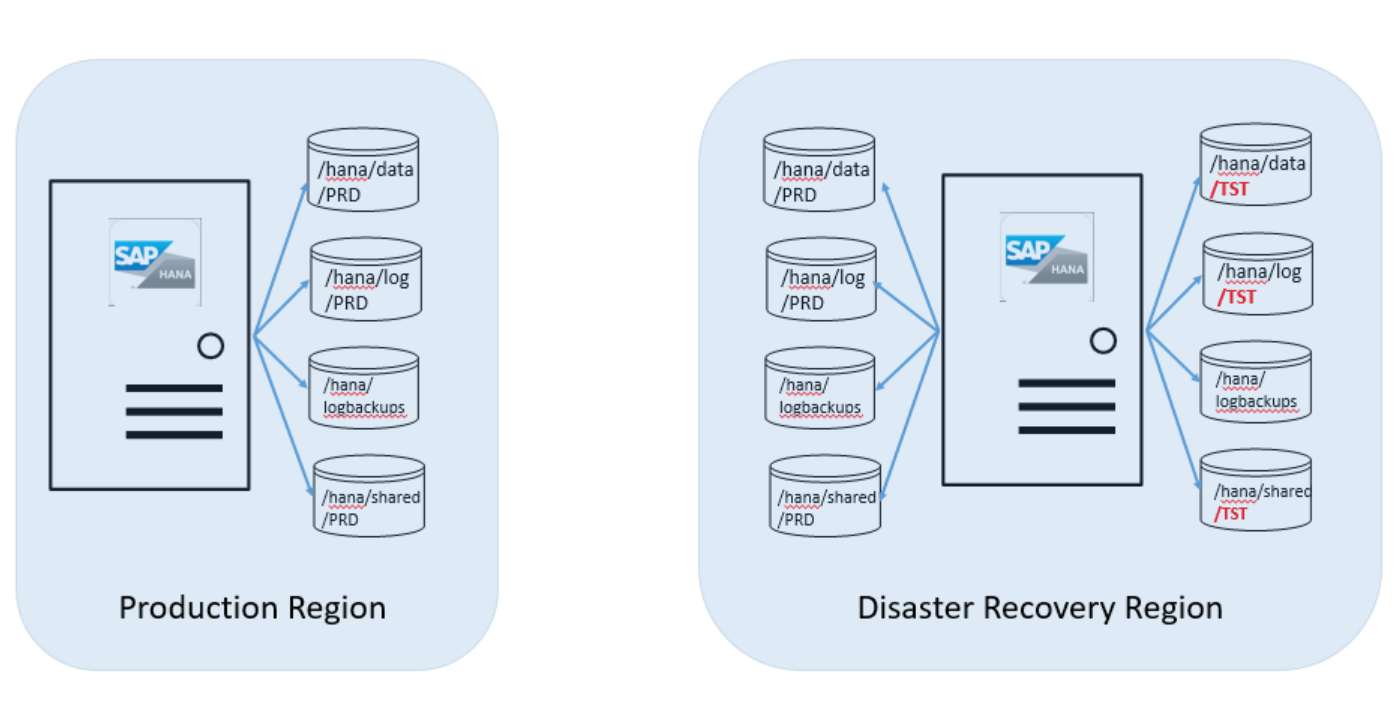
A próxima etapa é instalar a segunda instância do SAP HANA na unidade do SAP HANA nas Instâncias Grandes na região do Azure de recuperação de desastre onde você está executando a instância do TST HANA. A instância do SAP HANA recém-instalada precisa ter o mesmo SID. Os usuários criados precisam ter os mesmos UID e ID de grupo da instância de produção. Leia Backup e restauração para obter detalhes. Se a instalação for bem-sucedida, será necessário:
- Execute a etapa 2 da preparação de instantâneo do armazenamento descrita em Backup e restauração.
- Criar uma chave pública para a unidade de DR do SAP HANA nas Instâncias Grandes, caso ainda não tenha feito isso. Veja a etapa 3 da preparação de instantâneo do armazenamento descrita em Backup e restauração.
- Mantenha HANABackupCustomerDetails.txt com a nova instância do HANA e teste se a conectividade com o armazenamento funciona corretamente.
- Pare a instância do SAP HANA recém-instalada na unidade do SAP HANA nas Instâncias Grandes na região de DR do Azure.
- Desmonte esses volumes PRD e entre em contato com o Gerenciamento de Serviços do SAP HANA no Azure. Os volumes não podem permanecer montados na unidade, pois eles não podem ser acessados enquanto estão em funcionamento como o destino de replicação de armazenamento.
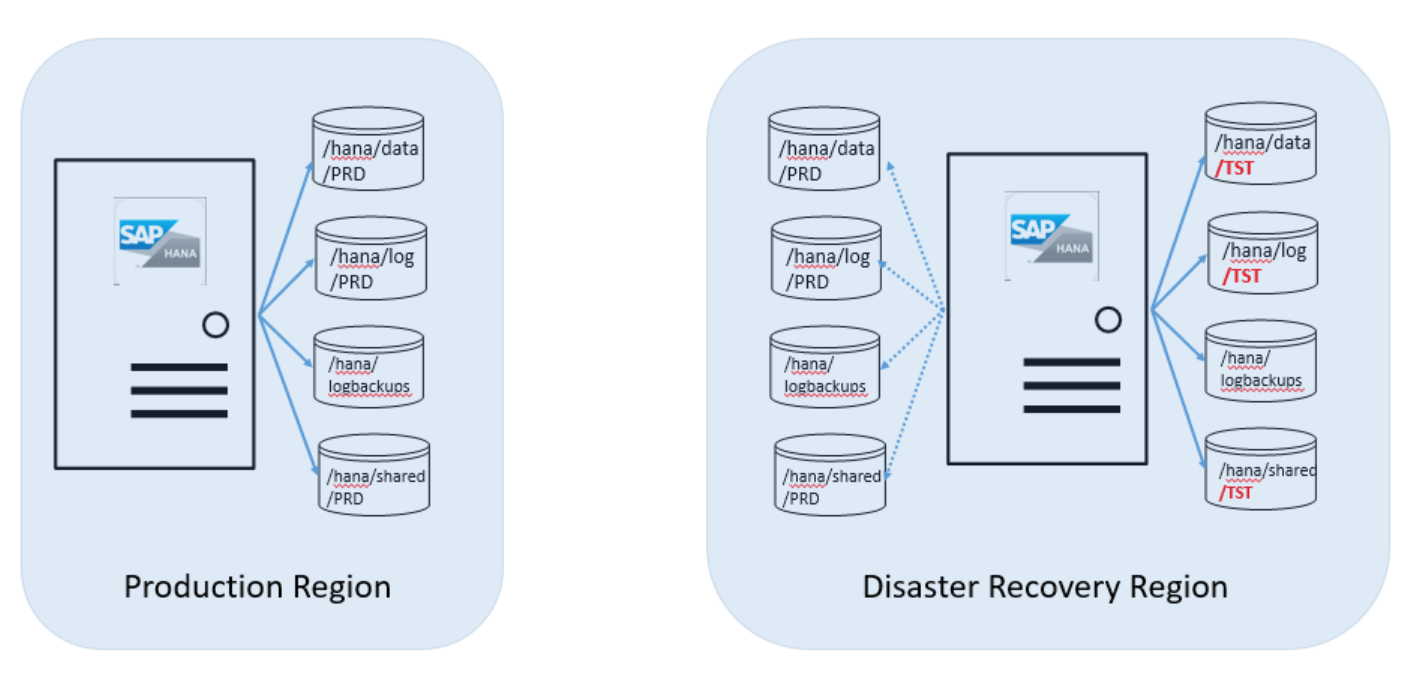
A equipe de operações estabelece o relacionamento de replicação entre os volumes PRD na região do Azure de produção e os volumes PRD na região do Azure de recuperação de desastre.
Importante
O volume /hana/log não é replicado porque não é necessário restaurar o banco de dados do SAP HANA replicado para um estado consistente no local de recuperação de desastre.
Em seguida, defina o agendamento de backup de instantâneo de armazenamento para obter o RTO e o RPO em caso de desastre. Para minimizar o objetivo de ponto de recuperação, defina os intervalos de replicação a seguir no serviço de Instância Grande do HANA:
- Para os volumes cobertos pelo instantâneo combinado (tipo de instantâneo hana), defina para replicar a cada 15 minutos para os destinos de volume de armazenamento equivalentes no site de recuperação de desastre.
- Para o volume de backup de log de transações (tipo de instantâneo logs), defina para replicar a cada 3 minutos para os destinos de volume de armazenamento equivalentes no site de recuperação de desastre.
Para minimizar o RPO:
- Execute um instantâneo de armazenamento do tipo hana a cada período de 30 minutos a uma hora. Para mais informações, consulte Fazer backup usando a ferramenta de Instantâneo consistente com o Aplicativo Azure.
- Execute backups de log de transações do SAP HANA a cada 5 minutos.
- Execute um instantâneo de armazenamento do tipo logs a cada 5-15 minutos. Com esse período de intervalo, você obtém um RPO de cerca de 15 a 25 minutos.
Com essa configuração, a sequência de backups de log de transações, os instantâneos de armazenamento e a replicação do volume de backup de log de transações do HANA e /hana/data e /hana/shared (inclui /usr/sap) podem ter a aparência dos dados mostrados neste gráfico:
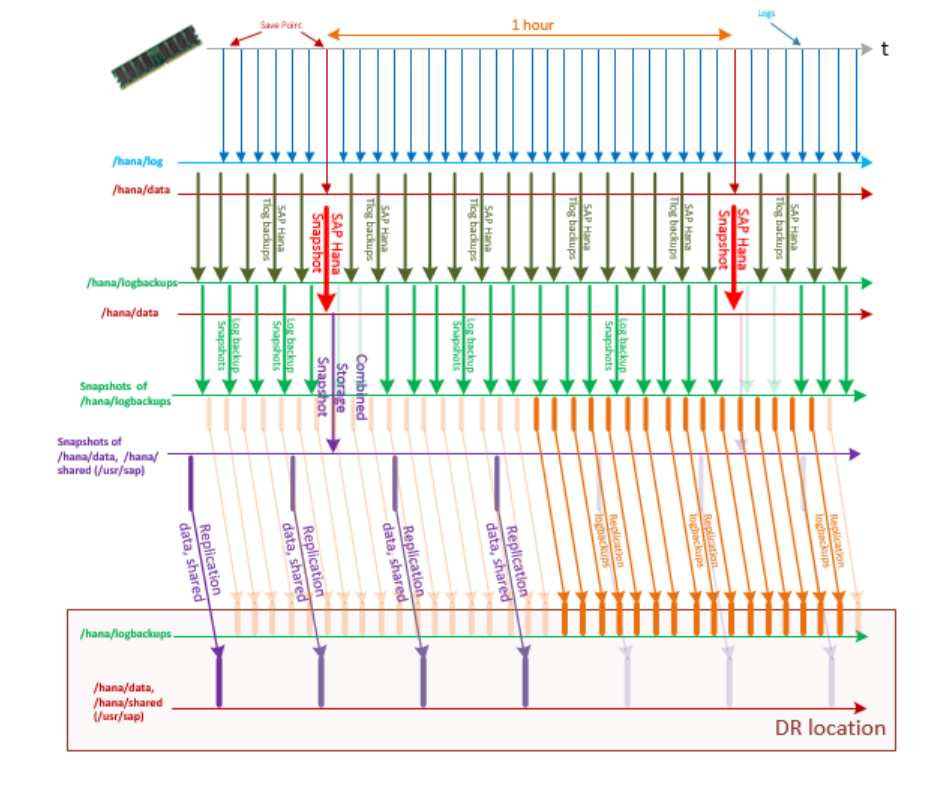
Para alcançar um RPO ainda melhor, no caso de recuperação de desastre, você pode copiar os backups de log de transações do HANA do SAP HANA (Instâncias Grandes) do Azure e para outra região do Azure. Para obter essa redução adicional de RPO, execute as etapas a seguir:
- Faça backup do log de transações do HANA com a maior frequência possível para /hana/logbackups.
- Use rsync para copiar os backups de log de transações para as máquinas virtuais do Azure hospedadas pelo compartilhamento NFS. As máquinas virtuais (VMs) estão nas redes virtuais do Azure na região de produção do Azure e na região de recuperação de desastre. É necessário conectar ambas as redes virtuais do Azure ao circuito que conecta as Instâncias Grandes do SAP HANA de produção ao Azure. Para mais informações, consulte Considerações de rede para recuperação de desastre com o SAP HANA nas Instâncias Grandes.
- Mantenha os backups de log de transações na região da VM anexados ao armazenamento exportado de NFS.
- No caso de um failover de desastre, complemente os backups de log de transações que encontrar no volume /hana/logbackups com backups de log de transações mais recentes tirados do compartilhamento de NFS no site de recuperação de desastre.
- Inicie um backup de log de transações para restaurar para o backup mais recente que foi salvo na região de recuperação de desastre.
A replicação de dados é iniciada quando as operações do SAP HANA nas Instâncias Grandes confirmam a configuração do relacionamento de replicação e você inicia os backups de instantâneos de armazenamento de execução.
Conforme a replicação avança, os instantâneos nos volumes PRD nas regiões do Azure de recuperação de desastre não são restaurados. Os instantâneos são apenas armazenados. Se os volumes forem montados nesse estado, eles representarão o estado em que você desmontou esses volumes após a instância do PRD SAP HANA ter sido instalada na unidade de servidor na região do Azure de recuperação de desastre. Eles também representam backups de armazenamento que ainda não foram restaurados.
No caso de um failover, também é possível optar por restaurar para um instantâneo de armazenamento mais antigo em vez do instantâneo de armazenamento mais recente.
Próximas etapas
Saiba mais sobre o processo de failover na recuperação de desastre.
Comentários
Em breve: Ao longo de 2024, eliminaremos os problemas do GitHub como o mecanismo de comentários para conteúdo e o substituiremos por um novo sistema de comentários. Para obter mais informações, consulte https://aka.ms/ContentUserFeedback.
Enviar e exibir comentários de