Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Na Pesquisa de IA do Azure, a capacidade é baseada em réplicas e partições que podem ser dimensionadas para sua carga de trabalho. As réplicas são cópias do mecanismo de pesquisa. As partições são unidades de armazenamento. Cada novo serviço de pesquisa começa com um cada, mas você pode adicionar ou remover réplicas e partições independentemente para acomodar cargas de trabalho flutuantes. Adicionar capacidade aumenta o custo de execução de um serviço de pesquisa.
As características físicas de réplicas e partições, como velocidade de processamento e E/S de disco, variam de acordo com o tipo de preço. Em um serviço de pesquisa padrão, as réplicas e partições são mais rápidas e maiores do que as de um serviço básico.
A alteração de capacidade não é instantânea. Pode levar até uma hora para comissionar ou descomissionar partições, especialmente em serviços com grandes quantidades de dados.
Ao escalar um serviço de pesquisa, você pode escolher entre as seguintes ferramentas e abordagens:
Observação
Se o serviço tiver sido criado antes de abril ou maio de 2024, uma atualização única para limites de armazenamento mais altos poderá estar disponível sem custo adicional. Para obter mais informações, consulte Atualizar seu serviço de pesquisa.
Conceitos: unidades de pesquisa, réplicas, partições
A capacidade é expressa em unidades de pesquisa que podem ser alocadas em combinações de partições e replicas.
| Conceito | Definição |
|---|---|
| Unidade de pesquisa | Um incremento da capacidade total disponível (36 unidades). É necessário um mínimo de uma unidade para executar o serviço. A primeira réplica e o par de partições é a primeira unidade de pesquisa. No entanto, cada instância extra de uma réplica ou de uma partição consome uma unidade de pesquisa extra. Por exemplo, você começa com uma réplica e partição (uma unidade de pesquisa), adiciona uma segunda réplica e agora está consumindo duas unidades de pesquisa. Uma unidade de pesquisa também é a unidade de cobrança do serviço Azure AI Search. |
| Réplica | Instâncias do serviço de pesquisa, usadas principalmente para equilibrar a carga das operações de consulta. Cada réplica hospeda uma cópia de um índice. Se você alocar três réplicas, terá três cópias de um índice disponíveis para atender às solicitações de consulta. |
| Partição | Armazenamento físico e E/S para operações de leitura/gravação (por exemplo, ao recompilar ou atualizar um índice). Cada partição tem uma fatia do índice total. Se você alocar três partições, o índice será dividido em terços. |
Revise a tabela de partições e réplicas para ver as possíveis combinações que não ultrapassem o limite de 36 unidades.
Quando adicionar capacidade
Inicialmente, um serviço é alocado a um nível mínimo de recursos compostos por uma partição e uma réplica. A camada escolhida determina o tamanho e a velocidade da partição, e cada camada é otimizada levando em consideração um conjunto de características que se ajustam a vários cenários. Se você escolher uma camada superior, poderá precisar de menos partições do que se você usar a S1. Uma das perguntas que você precisa responder ao conduzir testes autodirigidos é se uma partição maior e mais cara oferece melhor desempenho do que duas partições mais baratas em um serviço provisionado em um nível inferior.
Um único serviço deve ter recursos suficientes para manipular todas as cargas de trabalho (indexação e consultas). Nenhuma carga de trabalho é executada em segundo plano. Você pode agendar a indexação para horários em que as solicitações de consulta são naturalmente menos frequentes, mas o serviço não prioriza uma tarefa em vez de outra. Além disso, certa quantidade de redundância otimizará o desempenho da consulta quando os serviços ou nós forem atualizados internamente.
As diretrizes para determinar se a capacidade deve ser adicionada incluem:
- Atender aos critérios de alta disponibilidade do SLA.
- A frequência de erros HTTP 503 está aumentando.
- Grandes volumes de consulta são esperados.
- Uma atualização única para uma infraestrutura mais recente e partições maiores não é suficiente.
- O número atual de partições não é adequado para indexação de cargas de trabalho.
Como regra geral, os aplicativos de pesquisa tendem a precisar de mais réplicas do que partições, especialmente quando as operações de serviço são direcionadas para demandas de consulta. Cada réplica é uma cópia do seu índice e permite que o serviço realize o balanceamento de carga das solicitações nas várias cópias. O Azure AI Search gerencia todo o balanceamento de carga e a replicação de um índice e você pode alterar o número de réplicas alocadas para seu serviço a qualquer momento. É possível alocar até 12 réplicas em um serviço de pesquisa Standard e três réplicas em um serviço de pesquisa Básico. A alocação de réplicas pode ser feita no portal do Azure ou por meio de opções programáticas.
Partições extras são úteis para cargas de trabalho de indexação intensiva. As partições extras distribuem as operações de leitura/gravação em um número maior de recursos de computação.
Por fim, índices maiores levam mais tempo para consultar. Assim, você poderá perceber que cada aumento incremental em partições requer um aumento proporcional, mas menor, em réplicas. A complexidade e o volume de suas consultas influenciam a rapidez com que a execução da consulta é realizada.
Observação
Adicionar mais réplicas ou partições aumenta o custo da execução do serviço e pode causar pequenas variações na ordenação dos resultados. Verifique a calculadora de preços para entender as implicações de cobrança da adição de mais nós. O gráfico abaixo pode ajudar você a fazer referência cruzada do número de unidades de pesquisa necessárias para uma configuração específica. Para obter mais informações sobre como réplicas extras afetam o processamento de consultas, consulte Ordenando resultados.
Como atualizar a capacidade
Alguns recursos do Azure AI Search só estão disponíveis para novos serviços. Uma dessas funcionalidades é a maior capacidade de armazenamento, que se aplica aos serviços criados após abril de 2024. No entanto, se você criou seu serviço antes de abril de 2024, poderá obter maior capacidade sem recriar seu serviço executando uma atualização única. Para obter mais informações, consulte Atualizar seu serviço de pesquisa.
Como alterar a capacidade
Para aumentar ou diminuir a capacidade do serviço, você tem duas opções:
Adicionar ou remover partições e réplicas
Entre no portal do Azure e selecione seu serviço de pesquisa.
No painel à esquerda, selecione Configurações>Escala.
A captura de tela a seguir mostra um serviço Standard provisionado com uma réplica e uma partição. A fórmula na parte inferior indica quantas unidades de pesquisa estão sendo usadas (1). Se o preço unitário era US$ 100 (preço fictício), o custo mensal da execução desse serviço seria de US$ 100 em média.
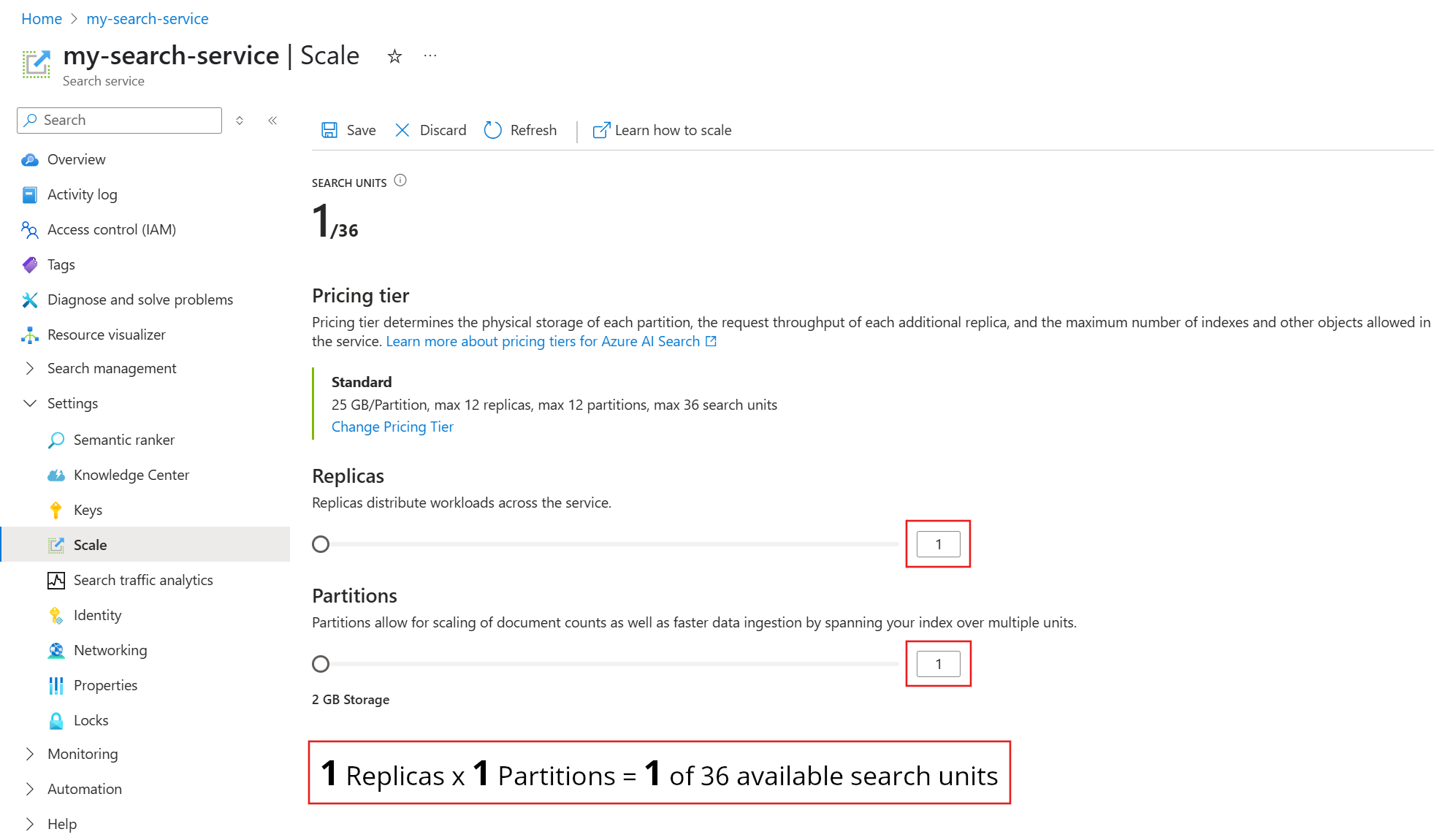
Use o controle deslizante para aumentar ou diminuir o número de partições. Selecione Salvar.
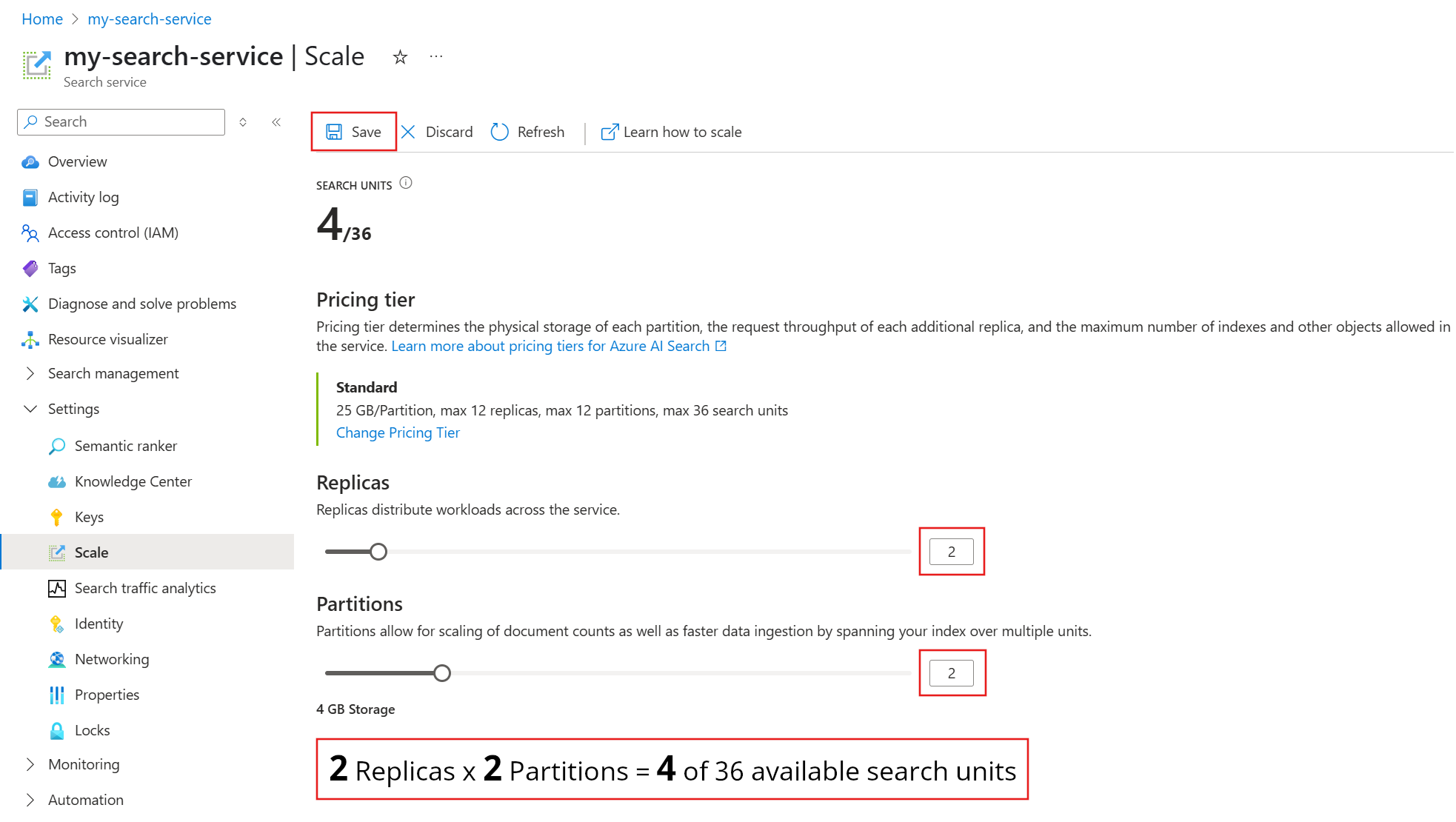
Este exemplo adiciona uma segunda réplica e partição. Observe a contagem de unidades de pesquisa. No momento, a contagem é quatro porque a fórmula de cobrança é o resultado das réplicas multiplicadas pelas partições (2 x 2). Dobrar a capacidade mais que dobra o custo da execução do serviço. Se o custo da unidade de pesquisa fosse US$ 100, a nova fatura mensal seria US$ 400.
Para obter os custos atuais por unidade de cada camada, visite a página de preços.
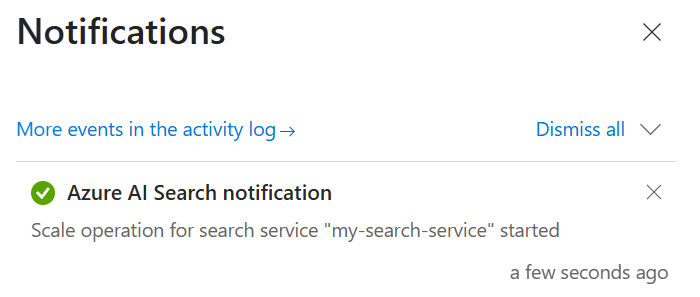
Verifique suas notificações para confirmar se a operação foi iniciada.
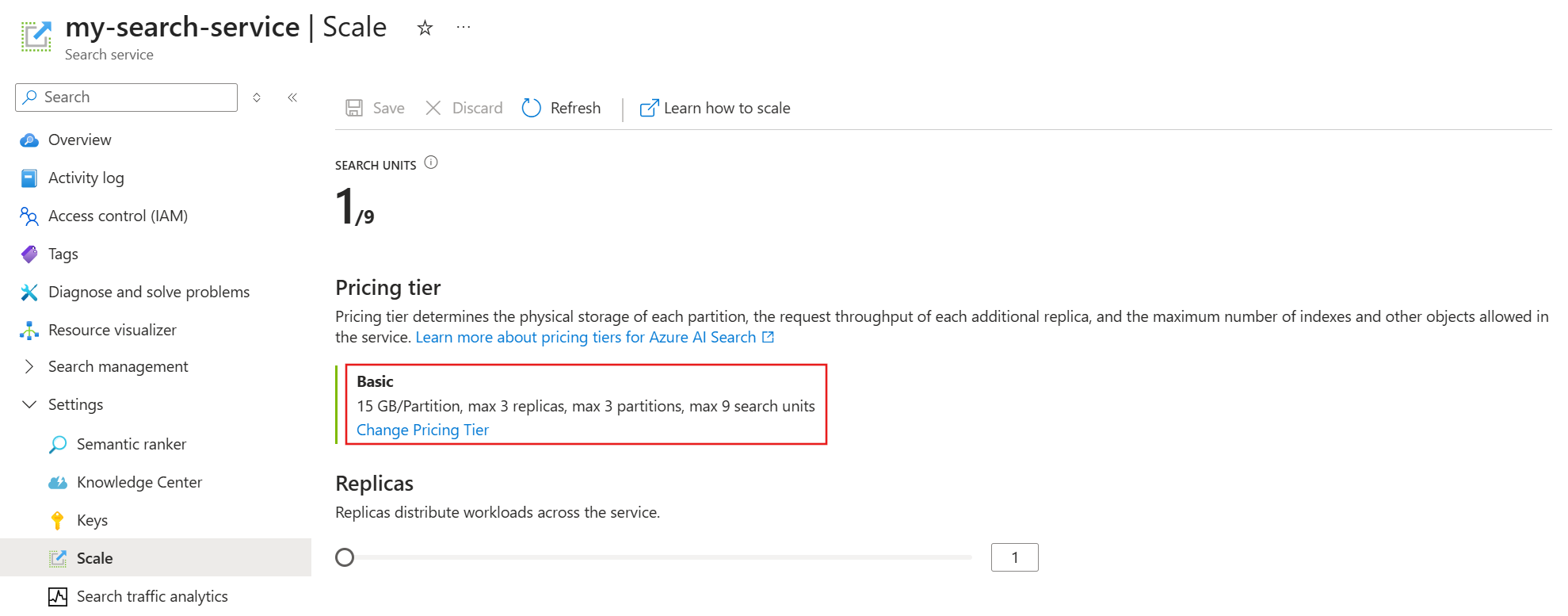
Essa operação pode levar várias horas para ser concluída. Você não pode cancelar o processo depois que ele é iniciado e não há monitoramento em tempo real de ajustes de réplica e partição. No entanto, a mensagem a seguir é exibida enquanto as alterações estão em andamento.





Alterar sua faixa de preço
Observação
A versão prévia 2025-02-01 dá suporte a alterações entre as camadas Basic e Standard (S1, S2 e S3). Atualmente, você só pode alternar de uma camada inferior para uma camada mais alta, como ir de Basic para S1. Sua região também não pode ter restrições de capacidade na camada superior.
Seu tipo de preço determina o armazenamento máximo do serviço de pesquisa. Se você precisar de mais capacidade, poderá alternar para um tipo de preço diferente que acomode suas necessidades de armazenamento.
Além da capacidade, alterar o tipo de preço afeta a carga de trabalho e os limites máximos do serviço. Antes de continuar, compare os limites de serviço da camada atual e da camada desejada. Estes incluem limites em:
- Armazenamento de partição
- Índices
- Vetores
- Indexadores
- Recursos de link privado compartilhados
- Sinônimos
- Aliases de índice
- Limitação do classificador semântico
Geralmente, mudar para uma camada mais alta aumenta o limite de armazenamento e o limite de vetor, aumenta a taxa de transferência de solicitação e diminui a latência.
Para alterar o tipo de preço:
Entre no portal do Azure e selecione seu serviço de pesquisa.
No painel à esquerda, selecione Configurações>Escala.
Na camada atual, selecione Alterar Tipo de Preço.
Na página Selecionar Tipo de Preço , escolha uma camada mais alta na lista. Atualmente, você só pode mover para cima entre Basic, S1, S2 e S3. Outros tipos de preços não estão disponíveis e aparecem esmaecidos.
Para alternar para a camada superior, selecione Selecionar.
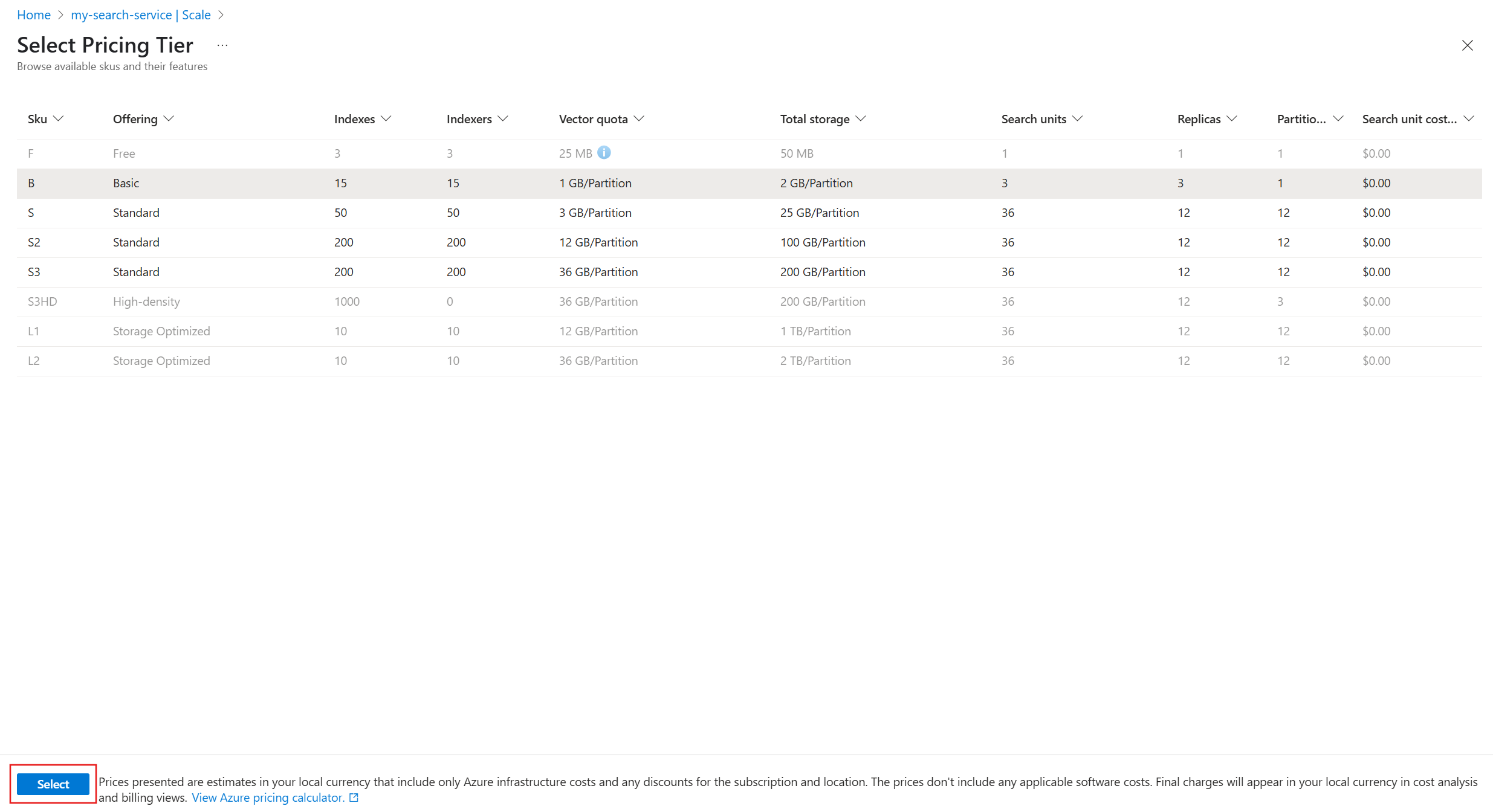
Essa operação pode levar várias horas para ser concluída. Você não pode cancelar o processo depois que ele é iniciado e não há monitoramento em tempo real das alterações de camada. No entanto, na página Visão geral , um status de provisionamento indica que a operação está em andamento para seu serviço.
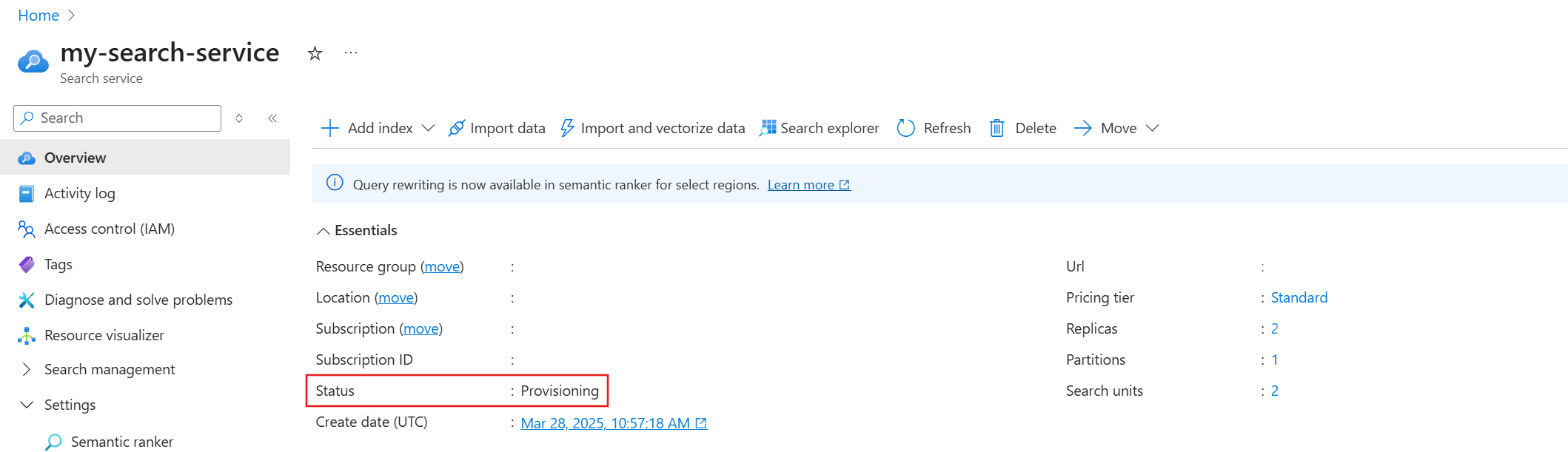



Como as solicitações de escala são administradas
Após o recebimento de uma solicitação de escala, o serviço de pesquisa:
- Verifica se a solicitação é válida.
- Inicia o backup de dados e informações do sistema.
- Verifica se o serviço já está em um estado de provisionamento (atualmente adicionando ou eliminando réplicas ou partições).
- Inicia o provisionamento.
A escala de um serviço pode levar apenas 15 minutos ou mais de uma hora, dependendo do tamanho do serviço e do escopo da solicitação. O backup pode levar vários minutos, dependendo da quantidade de dados e do número de partições e réplicas.
As etapas acima não são totalmente consecutivas. Por exemplo, o sistema iniciará o provisionamento quando ele puder fazer isso com segurança, o que pode ser enquanto o backup estiver terminando.
Erros durante o escalonamento
A mensagem de erro "Operações de atualização de serviço não são permitidas no momento porque estamos processando uma solicitação anterior" é causada pela repetição de uma solicitação para diminuir ou aumentar a escala quando o serviço já está processando uma solicitação anterior.
Resolva esse erro verificando o status do serviço para verificar o status de provisionamento:
- Use a API REST de gerenciamento, o Azure PowerShell ou a CLI do Azure para obter o status do serviço.
- Use Obter serviço (REST) ou equivalente para o PowerShell ou a Interface de Linha de Comando (CLI).
- Verifique a resposta de “provisioningState”: “provisioning”
Se o status for “Provisionamento”, aguarde a conclusão da solicitação. O status deve ser "Succeeded" ou "Failed" para que seja possível tentar realizar outra solicitação. Não há status para backup. O backup é uma operação interna e é improvável que seja um fator em quaisquer interrupções de um exercício de larga escala.
Se o serviço de pesquisa parecer travado em um estado de provisionamento, verifique se há índices órfãos inutilizáveis, sem volumes de consulta e sem atualizações de índice. Um índice inutilizável pode bloquear alterações na capacidade do serviço. Em especial, procure índices que estão criptografados por CMK, cujas chaves estão inválidas. Você deve excluir o índice ou restaurar as chaves para colocar o índice online novamente e desbloquear a operação de escala.
Combinações de partição e réplica
O gráfico a seguir se aplica à camada Standard e superior. Ele mostra todas as combinações possíveis de partições e réplicas, sujeitas ao máximo de 36 unidades de pesquisa por serviço.
| 1 partição | 2 partições | 3 partições | 4 partições | 6 partições | 12 partições | |
|---|---|---|---|---|---|---|
| 1 réplica | 1 SU | 2 SU | 3 SU | 4 SU | 6 SU | 12 SU |
| 2 réplicas | 2 SU | 4 SU | 6 SU | 8 SU | 12 SU | 24 SU |
| 3 réplicas | 3 SU | 6 SU | 9 SU | 12 SU | 18 SU | 36 SU |
| 4 réplicas | 4 SU | 8 SU | 12 SU | 16 SU | 24 SU | N/D |
| 5 réplicas | 5 SU | 10 SU | 15 SU | 20 SU | 30 SU | N/A |
| 6 réplicas | 6 SU | 12 SU | 18 SU | 24 SU | 36 SU | N/A |
| 12 réplicas | 12 SU | 24 SU | 36 SU | N/A | N/A | N/A |
Os serviços de pesquisa básicos têm contagens de unidades de pesquisa menores.
Nos serviços de pesquisa criados antes de 3 de abril de 2024, os serviços Básicos podem ter exatamente uma partição e até três réplicas, para um limite máximo de três SUs. O único recurso ajustável são as réplicas. No entanto, você pode aumentar a contagem de partições atualizando seu serviço.
Nos serviços de pesquisa criados após 3 de abril de 2024 em regiões com suporte, os serviços básicos podem ter até três partições e três réplicas. O limite máximo de unidade de armazenamento é nove para dar suporte a um complemento completo de partições e réplicas.
Para os serviços de pesquisa em qualquer camada faturável, independentemente da data de criação, você precisará de, no mínimo, duas réplicas para alta disponibilidade em consultas.
Para ver as taxas de cobrança por camada e moeda, consulte a página de preços da Pesquisa de IA do Azure.
Estimar a capacidade usando uma camada faturável
O tamanho dos índices que você espera criar determina as necessidades de armazenamento. Não há nenhuma heurística sólida nem generalizações que ajudem na obtenção de estimativas. A única maneira de determinar o tamanho de um índice é criando um. Seu tamanho se baseia na tokenização e nas inserções, e se você habilitar sugeridores, filtragem e classificação, ou pode aproveitar a compactação de vetores.
Recomendamos fazer uma estimativa em uma camada faturável, Básico ou superior. A camada Gratuita é executada em recursos físicos compartilhados por vários clientes e está sujeita a fatores fora do seu controle. Apenas os recursos dedicados de um serviço de pesquisa com cobrança podem acomodar tempos de amostragem e processamento maiores para estimativas mais realistas da quantidade de índices, tamanho e volumes de consulta durante o desenvolvimento.
Examine os limites de serviço em cada camada para determinar se as camadas mais baixas podem dar suporte ao número de índices que você precisa. Considere se você precisa de várias cópias de um índice para desenvolvimento ativo, testes e produção.
Um serviço de pesquisa está sujeito a limites de objetos (número máximo de índices, indexadores, conjuntos de habilidades etc.) e limites de armazenamento. O limite que for atingido primeiro é o limite efetivo.
Crie um serviço em uma camada faturável. As camadas são otimizadas para determinadas cargas de trabalho. Por exemplo, a camada Otimizada para Armazenamento tem um limite de 10 índices porque foi projetada para dar suporte a um número baixo de índices grandes.
Comece em um nível mais baixo, como Básica ou S1, se você não tiver certeza da carga projetada.
Comece em um nível alto, como S2 ou até mesmo S3, se o teste incluir cargas de consulta e indexação em grande escala.
Comece com Otimizado para Armazenamento, em L1 ou L2, se você estiver indexando uma grande quantidade de dados e a carga de consulta for relativamente baixa, assim como em um aplicativo de negócios interno.
Criar um índice inicial para determinar como a fonte de dados traduz para um índice. Essa é a única maneira de estimar o tamanho do índice. Os atributos nas definições de campo afetam os requisitos de armazenamento físico:
Para a pesquisa de palavras-chave, marcar os campos como filtráveis e classificáveis aumenta o tamanho do índice.
Para busca em vetores, você pode definir parâmetros para reduzir o tamanho do vetor.
Monitorar armazenamento, limites de serviço, volume de consulta e latência no portal do Azure. O portal do Azure mostra as consultas por segundo, consultas limitadas e latência de pesquisa. Todos esses valores podem ajudar você a decidir se selecionou a camada certa.
Adicione réplicas para alta disponibilidade ou para mitigar o desempenho lento de consultas.
Não há diretrizes sobre quantas réplicas são necessárias para acomodar as cargas de consulta. O desempenho da consulta depende da complexidade da consulta e das cargas de trabalho concorrentes. Embora a adição de réplicas definitivamente melhore o desempenho, o resultado não é estritamente linear: a adição de três réplicas não garante o triplo da taxa de transferência. Para obter diretrizes sobre como estimar a QPS da sua solução, confira Análise de desempenhoe Monitorar consultas.
Para um índice invertido, o tamanho e a complexidade são determinados pelo conteúdo, não necessariamente pela quantidade de dados que você alimenta nele. Uma fonte de dados grande com alta redundância pode resultar em um índice menor do que um conjunto de dados menor que contém um conteúdo altamente variável. Portanto, é raramente possível inferir o tamanho de índice com base no tamanho do conjunto de dados original.
Os requisitos de armazenamento poderão aumentar se você incluir dados que nunca serão pesquisados. Idealmente, os documentos contêm apenas os dados necessários para a experiência de pesquisa.
Considerações sobre o contrato de nível de serviço
As versões prévias do recurso e a Camada gratuita não são cobertas pelos SLAs (contratos de nível de serviço). Para todas as camadas faturáveis, os SLAs entram em vigor quando você provisiona redundância suficiente para o serviço.
Duas ou mais réplicas satisfazem os SLAs de consulta (leitura).
Três ou mais réplicas satisfazem os SLAs de consulta e indexação (leitura e gravação).
O número de partições não afeta os SLAs.