Criar um indexador na IA do Azure Search
Use um indexador para automatizar a importação e a indexação de dados na IA do Azure Search. Um indexador é um objeto nomeado em um serviço de pesquisa que se conecta a uma fonte de dados externa do Azure, lê dados e os passa para um mecanismo de pesquisa para indexação. O uso de indexadores reduz significativamente a quantidade e a complexidade do código que você precisa gravar se estiver usando uma fonte de dados com suporte.
Os indexadores são suportados por dois fluxos de trabalho:
Indexação baseada em texto extrai cadeias de caracteres e metadados do conteúdo textual para cenários de pesquisa de texto completo.
Indexação baseada em habilidades, usando habilidades internas ou personalizadas que adicionam aprendizado de máquina integrado para análise sobre imagens e conteúdo grande não diferenciado, extraindo ou inferindo texto e estrutura. A indexação baseada em habilidades permite pesquisar conteúdo que, de outra forma, não é facilmente pesquisável por texto completo. Para saber mais, confira Enriquecimento de IA na IA do Azure Search.
Este artigo se concentra nas etapas básicas de criação de um indexador. Dependendo da fonte de dados e do fluxo de trabalho, pode ser necessária uma configuração adicional.
Pré-requisitos
Uma fonte de dados com suporte que contenha o conteúdo que você deseja ingerir.
Uma fonte de dados do indexador que configura uma conexão com dados externos.
Um índice de pesquisa que possa aceitar dados de entrada.
Estar abaixo dos limites máximos para sua camada de serviço. A Camada gratuita permite três objetos de cada tipo e de 1 a 3 minutos de processamento do indexador ou de 3 a 10 se houver um conjunto de habilidades.
Padrões do indexador
Ao criar um indexador, a definição seguirá um dos dois padrões: indexação baseada em texto ou enriquecimento de IA com habilidades. Os padrões são os mesmos, exceto que a indexação baseada em habilidades tem mais definições.
Exemplo do indexador para indexação baseada em texto
A indexação baseada em texto para pesquisa de texto completo é o principal caso de uso para indexadores e, para esse fluxo de trabalho, um indexador se parecerá com este exemplo.
{
"name": (required) String that uniquely identifies the indexer,
"description": (optional),
"dataSourceName": (required) String indicating which existing data source to use,
"targetIndexName": (required) String indicating which existing index to use,
"parameters": {
"batchSize": null,
"maxFailedItems": 0,
"maxFailedItemsPerBatch": 0,
"base64EncodeKeys": false,
"configuration": {}
},
"fieldMappings": (optional) unless field discrepancies need resolution,
"disabled": null,
"schedule": null,
"encryptionKey": null
}
Os indexadores têm os seguintes requisitos:
- Uma propriedade
"name"que identifica exclusivamente o indexador na coleção do indexador. - Uma propriedade
"dataSourceName"que aponta para um objeto de fonte de dados. Ela especifica uma conexão com os dados externos. - Uma propriedade
"targetIndexName"que aponta para o índice de pesquisa de destino.
Outros parâmetros são opcionais e modificam os comportamentos de tempo de execução, como quantos erros aceitar antes de falhar todo o trabalho. Os parâmetros necessários são especificados em todos os indexadores e estão documentados na Referência da API REST.
Indexadores específicos da fonte de dados para blobs, SQL e Azure Cosmos DB fornecem parâmetros "configuration" extras para comportamentos específicos da origem. Por exemplo, se a origem for um Armazenamento de Blobs, você poderá definir um parâmetro que filtra por extensões de arquivo: "parameters" : { "configuration" : { "indexedFileNameExtensions" : ".pdf,.docx" } }. Se a origem for SQL do Azure, você poderá definir um parâmetro de tempo limite de consulta.
Mapeamentos de campo são usados para mapear explicitamente campos de origem para destino se houver discrepâncias por nome ou tipo entre um campo na fonte de dados e um campo no índice de pesquisa.
Por padrão, um indexador é executado imediatamente quando você o criar no serviço de pesquisa. Se você não quiser a execução do indexador, defina "disabled" como true ao criar o indexador.
Você também pode especificar um agendamento ou definir uma chave de criptografia para criptografia complementar da definição do indexador.
Exemplo de indexador para indexação baseada em texto
Os indexadores também impulsionam o enriquecimento de IA. Todas as propriedades e parâmetros acima se aplicam, mas as seguintes propriedades são específicas ao enriquecimento de IA: "skillSetName", "cache", "outputFieldMappings".
{
"name": (required) String that uniquely identifies the indexer,
"dataSourceName": (required) String, provides raw content that will be enriched,
"targetIndexName": (required) String, name of an existing index,
"skillsetName" : (required for AI enrichment) String, name of an existing skillset,
"cache": {
"storageConnectionString" : (required if you enable the cache) Connection string to a blob container,
"enableReprocessing": true
},
"parameters": { },
"fieldMappings": (optional) Maps fields in the underlying data source to fields in an index,
"outputFieldMappings" : (required) Maps skill outputs to fields in an index,
}
O enriquecimento de IA é sua própria área de assunto e está fora do escopo deste artigo. Para obter mais informações, comece com enriquecimento de IA, Conjuntos de habilidades na IA do Azure Search, Criar um conjunto de habilidades, Mapear campos de saída de enriquecimento e Habilitar o cache para enriquecimento de IA.
Preparar dados externos
Os indexadores trabalham com conjuntos de dados. Quando você executar um indexador, ele se conectará à fonte de dados, recuperará os dados do contêiner ou da pasta e, opcionalmente, os serializará em JSON antes de passá-los para o mecanismo de pesquisa para indexação. Esta seção descreve os requisitos de dados de entrada para indexação baseada em texto.
| Dados de origem | Tarefas |
|---|---|
| Documentos JSON | Verifique se a estrutura ou a forma dos dados de entrada corresponde ao esquema do seu índice de pesquisa. A maioria dos índices de pesquisa é simples, em que a coleção de campos é composta por campos no mesmo nível. No entanto, estruturas hierárquicas ou aninhadas são possíveis por meio de campos e coleções complexas. |
| Relacional | Forneça-os como um conjunto de linhas nivelado, em que cada linha se torna um documento de pesquisa completo ou parcial no índice. Para mesclar dados relacionais em um conjunto de linhas, você deve criar uma exibição SQL ou compilar uma consulta que retorne os registros pai e filho na mesma linha. Por exemplo, o conjunto de dados interno de exemplos de hotéis é um banco de dados SQL com 50 registros (um para cada hotel) vinculados a registros de quarto em uma tabela relacionada. A consulta que mescla os dados coletivos em um conjunto de linhas incorpora todas as informações de quarto em documentos JSON em cada registro do hotel. As informações de quarto inseridas são geradas por uma consulta que usa uma cláusula FOR JSON AUTO. Saiba mais sobre essa técnica em definir uma consulta que retorna JSON inserido. Este é apenas um exemplo. Você pode encontrar outras abordagens que produzirão o mesmo resultado. |
| Arquivos | Um indexador geralmente cria um documento de pesquisa para cada arquivo, em que o documento de pesquisa consiste em campos para conteúdo e metadados. Dependendo do tipo de arquivo, o indexador às vezes pode analisar um arquivo em vários documentos de pesquisa. Por exemplo, em um arquivo CSV, cada linha pode se tornar um documento de pesquisa autônomo. |
Lembre-se de que você só precisa efetuar pull de dados pesquisáveis e filtráveis:
- Dados pesquisáveis são texto.
- Os dados filtráveis são alfanuméricos.
A IA do Azure Search não pode pesquisar dados binários em qualquer formato, embora possa extrair e inferir descrições de texto de arquivos de imagem (confira Enriquecimento de IA) para criar conteúdo pesquisável. Da mesma forma, textos grandes podem ser dividido e analisados por modelos de linguagem natural para localizar a estrutura ou informações relevantes, gerando novo conteúdo que você pode adicionar a um documento de pesquisa.
Considerando que os indexadores não corrigem problemas de dados, outras formas de limpeza ou manipulação de dados podem ser necessárias. Para obter mais informações, consulte a documentação do produto do seu produto de banco de dados do Azure.
Preparar uma fonte de dados
Os indexadores exigem uma fonte de dados que especifica o tipo, o contêiner e a conexão.
Verifique se você está usando um tipo de fonte de dados com suporte.
Criar uma definição de fonte de dados. A seguinte lista é de algumas das fontes de dados usadas com mais frequência:
Se a fonte de dados for um banco de dados, como SQL do Azure ou Cosmos DB, habilite o controle de alterações. O Armazenamento do Azure tem controle de alterações interno por meio da propriedade
LastModifiedem cada blob, arquivo e tabela. Os links acima para as várias fontes de dados explicam quais métodos de controle de alterações têm suporte de indexadores.
Preparar um índice
Os indexadores também exigem um índice de pesquisa. Lembre-se de que os indexadores passam os dados para o mecanismo de pesquisa para indexação. Assim como os indexadores têm propriedades que determinam o comportamento da execução, um esquema de índice tem propriedades que afetam de forma profunda como as cadeias de caracteres são indexadas (somente cadeias de caracteres são analisadas e indexadas).
Comece com Criar um índice de pesquisa.
Configure a coleção de campos e os atributos de campo.
Os campos são os únicos receptores de conteúdo externo. Dependendo de como os campos são atribuídos no esquema, os valores de cada campo são analisados, tokenizados ou armazenados como cadeias de caracteres verbatim para filtros, pesquisa difusa e consultas typeahead.
Os indexadores podem mapear automaticamente os campos de origem para os campos de índice de destino quando os nomes e os tipos são equivalentes. Se um campo não puder ser mapeado implicitamente, lembre-se de que você pode definir um mapeamento de campo explícito que informa ao indexador como rotear o conteúdo.
Examine as atribuições do analisador em cada campo. Os analisadores podem transformar cadeias de caracteres. Dessa forma, as cadeias de caracteres indexadas podem ser diferentes das que você passou. Você pode avaliar os efeitos de analisadores usando Analisar Texto (REST). Para mais informações sobre analisadores, confira Analisadores para processamento de texto.
Durante a indexação, um indexador verifica apenas os nomes e tipos de campo. Não há nenhuma etapa de validação que garanta que o conteúdo de entrada seja o correto para o campo de pesquisa correspondente no índice.
Criar um indexador
Quando estiver pronto para criar um indexador em um serviço de pesquisa remota, você precisará de um cliente de pesquisa. Um cliente de pesquisa pode ser o portal do Azure, um cliente REST, ou o código que cria uma instância de um cliente do indexador. Recomendamos o portal do Azure ou APIs REST para desenvolvimento antecipado e teste de prova de conceito.
Entre no portal do Azure.
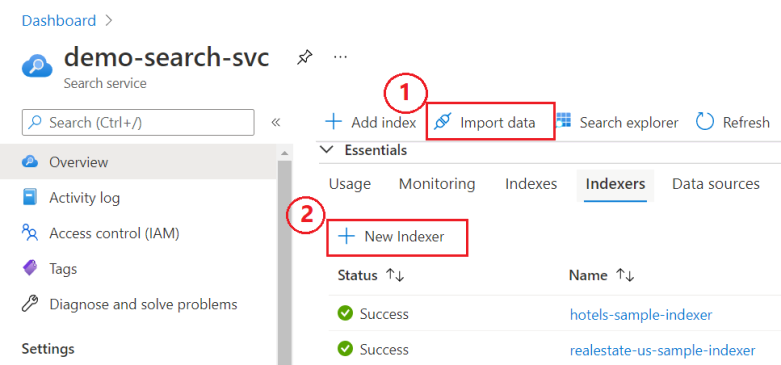
Na página Visão geral do serviço de pesquisa, escolha entre duas opções:
Assistente Importar Dados. O assistente é exclusivo, pois ele cria todos os elementos necessários. Outras abordagens exigem uma fonte de dados e um índice predefinidos.
Novo Indexador, um editor visual para especificar uma definição de indexador.
A captura de tela a seguir mostra onde você pode encontrar esses recursos no portal.
Executar o indexador
Por padrão, um indexador é executado imediatamente quando você o criar no serviço de pesquisa. Você pode substituir esse comportamento definindo "disabled" como true na definição do indexador. A execução do indexador é o momento da verdade, em que você descobrirá se há problemas com conexões, mapeamentos de campo ou a construção do conjunto de habilidades.
Há várias maneiras de executar um índice:
Executar na criação ou atualização do indexador (padrão).
Executar sob demanda quando não houver nenhuma alteração na definição ou preceder com a redefinição para indexação completa. Para obter mais informações, consulte Executar ou redefinir indexadores.
Agendar o processamento do indexador para invocar a execução em intervalos regulares.
A execução agendada geralmente é implementada quando você precisa de indexação incremental para que possa escolher as alterações mais recentes. Assim, o agendamento tem uma dependência na detecção de alterações.
Os indexadores são um dos poucos subsistemas que fazem chamadas de saída abertas para outros recursos do Azure. Em termos de funções do Azure, os indexadores não têm identidades separadas: uma conexão do mecanismo de pesquisa com outro recurso do Azure é feita usando a identidade gerenciada atribuída pelo usuário ou pelo sistema de um serviço de pesquisa. Se o indexador se conectar a um recurso do Azure em uma rede virtual, você deverá criar um link privado compartilhado para essa conexão. Para obter mais informações sobre conexões seguras, confira Segurança na Pesquisa de IA do Azure.
Verificar os resultados
Monitore o status do indexador para verificar o status. A execução bem-sucedida ainda pode incluir avisos e notificações. Certifique-se de verificar as notificações de status bem-sucedidas e com falha para obter detalhes sobre o trabalho.
Para verificação de conteúdo, execute consultas no índice preenchido que retornam documentos inteiros ou campos selecionados.
Detecção de alteração e estado interno
Se sua fonte de dados der suporte à detecção de alterações, um indexador poderá detectar alterações subjacentes nos dados e processar somente os documentos novos ou atualizados em cada execução de indexador, deixando o conteúdo inalterado no estado em que se encontra. Se o histórico de execução do indexador indicar que uma execução foi bem-sucedida com 0/0 documentos processados, significa que o indexador não encontrou nenhuma linha ou blobs novos ou alterados na fonte de dados subjacente.
A lógica de detecção de alterações é incorporada às plataformas de dados. O suporte que um indexador dá à detecção de alteração varia de acordo com a fonte de dados:
O Armazenamento do Azure tem uma detecção de alterações interna, o que significa que um indexador pode reconhecer automaticamente documentos novos e atualizados. Armazenamento de Blobs, Armazenamento de Tabelas do Azure e Azure Data Lake Storage Gen2 carimbam cada atualização de blob ou linha com uma data e hora. Um indexador usa automaticamente essas informações para determinar quais documentos atualizar no índice. Para obter mais informações sobre a detecção de exclusão, confira Excluir detecção usando indexadores para o Armazenamento do Microsoft Azure na IA do Azure Search.
As tecnologias de banco de dados de nuvem fornecem recursos opcionais de detecção de alterações em suas plataformas. Para essas fontes de dados, a detecção de alterações não é automática. Você precisa especificar na definição da fonte de dados qual política é usada:
Os indexadores acompanham o último documento processado da fonte de dados por meio de uma marca d´água alta interna. O marcador nunca é exposto na API, mas, internamente, o indexador acompanha onde ele parou. Quando a indexação é retomada, por meio de uma execução agendada ou de uma invocação por demanda, o indexador faz referência à marca d' água alta para que possa continuar de onde parou.
Se precisar remover a marca d' água alta para reindexar totalmente, você poderá usar Redefinir indexador. Para fazer uma reindexação mais seletiva, use Redefinir habilidades ou Redefinir documentos. Por meio das APIs de redefinição, você pode remover o estado interno e também liberar o cache se tiver habilitado o enriquecimento incremental. Para obter mais informações e a comparação de cada opção de redefinição, confira Executar ou redefinir indexadores, habilidades e documentos.
Próximas etapas
Comentários
Em breve: Ao longo de 2024, eliminaremos os problemas do GitHub como o mecanismo de comentários para conteúdo e o substituiremos por um novo sistema de comentários. Para obter mais informações, consulte https://aka.ms/ContentUserFeedback.
Enviar e exibir comentários de