Tutorial: Indexar dados SQL do Azure usando o SDK do .NET
Configure um indexador para extrair dados pesquisáveis do Banco de Dados SQL do Azure, enviando-os para um índice de pesquisa no Azure AI Search.
Esse tutorial usa C# e o Azure SDK para .NET para executar as seguintes tarefas:
- Criar uma fonte de dados que se conecta ao Banco de Dados SQL do Azure
- Criar um indexador
- Executar um indexador para carregar dados em um índice
- Consultar um índice como uma etapa de verificação
Se você não tiver uma assinatura do Azure, crie uma conta gratuita antes de começar.
Pré-requisitos
- Banco de Dados SQL do Azure usando autenticação do SQL Server
- Visual Studio
- Pesquisa de IA do Azure. Criar ou encontrar um serviço de pesquisa existente
Observação
Você pode usar um serviço de pesquisa gratuito para este tutorial. A camada gratuita limita você a três índices, três indexadores e três fontes de dados. Este tutorial cria um de cada. Antes de começar, reserve um espaço no seu serviço para aceitar os novos recursos.
Baixar arquivos
O código-fonte deste tutorial se encontra na pasta DotNetHowToIndexer do repositório GitHub Azure-Samples/search-dotnet-getting-started.
1 – Criar serviços
Este tutorial usa o Azure AI Search para indexação e consultas e o Banco de Dados SQL do Azure como uma fonte de dados externa. Se possível, crie ambos os serviços na mesma região e no mesmo grupo de recursos para facilitar a proximidade e a capacidade de gerenciamento. Na prática, o Banco de Dados SQL do Azure pode estar em qualquer região.
Começar com o Banco de Dados SQL do Azure
Esse tutorial fornece o arquivo hotéis.sql no download de amostra para preencher o banco de dados. O Azure AI Search consome conjuntos de linhas bidimensionais, como aqueles gerados em uma exibição ou consulta. O arquivo SQL na solução de exemplo cria e preenche uma única tabela.
Se você tiver um recurso existente do Banco de Dados SQL do Azure, poderá adicionar a tabela de hotéis a ele, começando na etapa Abrir consulta.
Crie um banco de dados SQL do Azure usando as instruções em Início Rápido: crie um único banco de dados.
A configuração do servidor para o banco de dados é importante.
Escolha a opção de autenticação do SQL Server que solicita que você especifique um nome de usuário e uma senha. Você precisa disso para a cadeia de conexão ADO.NET usada pelo indexador.
Escolha uma conexão pública. Isso torna esse tutorial mais fácil de concluir. Público não é recomendado para produção e recomendamos excluir esse recurso no final do tutorial.

No portal do Azure, acesse o novo recurso.
Adicione uma regra de firewall para permitir o acesso do seu cliente, usando as instruções em Início Rápido: Criar uma regra de firewall no nível do servidor no portal do Azure. Você pode executar
ipconfigem um prompt de comando para obter seu endereço IP.Use o editor de consultas para carregar os dados de amostra. No painel de navegação, selecione Editor de consultas (versão prévia) e insira o nome de usuário e a senha do administrador do servidor.
Se você receber um erro de acesso negado, copie o endereço IP do cliente da mensagem de erro, abra a página de segurança de rede do servidor e adicione uma regra de entrada que permita o acesso do seu cliente.
No Editor de consultas, selecione Abrir consulta e navegue até o local do arquivo hotels.sql no computador local.
Selecione o arquivo e selecione Abrir. O script deve ser semelhante à captura de tela a seguir:

Selecione Executar para executar a consulta. No painel Resultados, você deve receber uma mensagem de consulta bem-sucedida, para três linhas.
Para retornar um conjunto de linhas desta tabela, você pode executar a consulta a seguir como uma etapa de verificação:
SELECT * FROM HotelsCopie a cadeia de conexão ADO.NET do banco de dados. Em Configurações>Cadeias de Conexão, copie a cadeia de conexão ADO.NET de maneira semelhante ao exemplo abaixo.
Server=tcp:<YOUR-DATABASE-NAME>.database.windows.net,1433;Initial Catalog=hotels-db;Persist Security Info=False;User ID=<YOUR-USER-NAME>;Password=<YOUR-PASSWORD>;MultipleActiveResultSets=False;Encrypt=True;TrustServerCertificate=False;Connection Timeout=30;
Você precisará dessa cadeia de conexão no próximo exercício, ao configurar seu ambiente.
Azure AI Search
O próximo componente é o Azure AI Search, que pode ser criado no portal. Use a Camada gratuita para concluir este passo a passo.
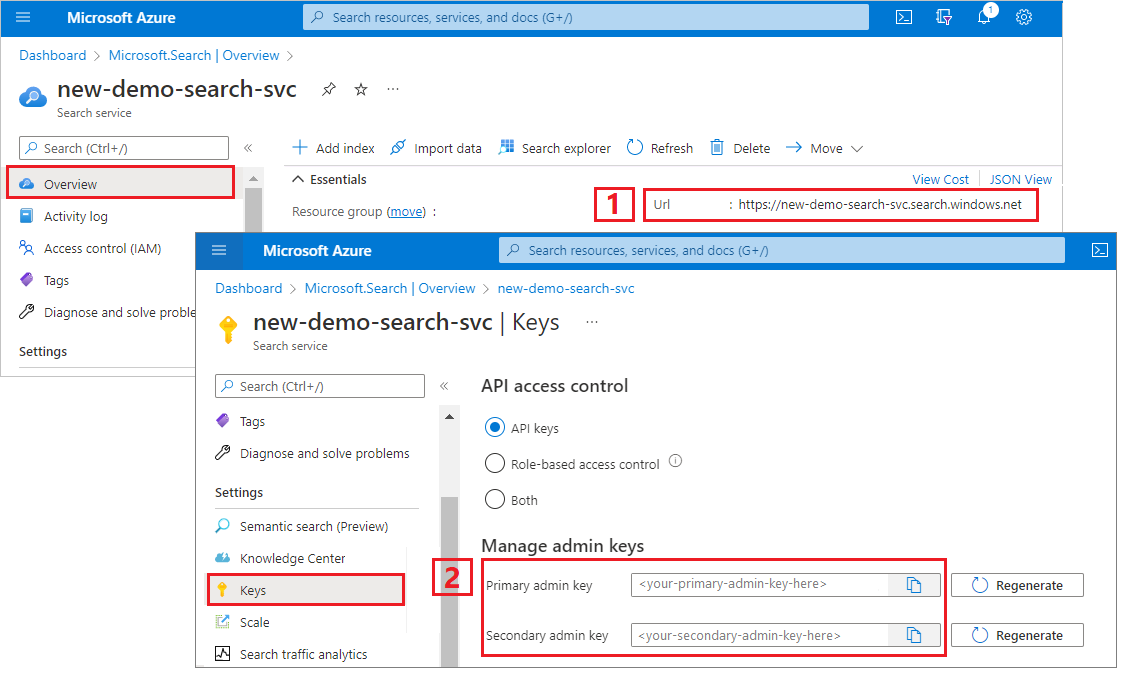
Obter uma chave de api de administrador e uma URL para o Azure AI Search
As chamadas à API exigem a URL do serviço e uma chave de acesso. Um serviço de pesquisa é criado com ambos, portanto, se você adicionou o Azure AI Search à sua assinatura, siga estas etapas para obter as informações necessárias:
Entre no portal do Azure e, na página Visão geral do serviço de pesquisa, obtenha a URL. Um ponto de extremidade de exemplo pode parecer com
https://mydemo.search.windows.net.Em Configurações>Chaves, obtenha uma chave de administração para adquirir todos os direitos sobre o serviço. Há duas chaves de administração intercambiáveis, fornecidas para a continuidade dos negócios, caso seja necessário sobrepor uma. É possível usar a chave primária ou secundária em solicitações para adicionar, modificar e excluir objetos.
2 – Configurar o ambiente
Inicie o Visual Studio e abra DotNetHowToIndexers.sln.
No Gerenciador de Soluções, abra appsettings.json para fornecer informações de conexão.
Em
SearchServiceEndPoint, se a URL completa na página de visão geral do serviço for "https://my-demo-service.search.windows.net"", então o valor a ser fornecido será a URL inteira.Por
AzureSqlConnectionString, o formato da cadeia de caracteres é semelhante a este:"Server=tcp:<your-database-name>.database.windows.net,1433;Initial Catalog=hotels-db;Persist Security Info=False;User ID=<your-user-name>;Password=<your-password>;MultipleActiveResultSets=False;Encrypt=True;TrustServerCertificate=False;Connection Timeout=30;"{ "SearchServiceEndPoint": "<placeholder-search-full-url>", "SearchServiceAdminApiKey": "<placeholder-admin-key-for-search-service>", "AzureSqlConnectionString": "<placeholder-ADO.NET-connection-string", }Substitua a senha do usuário na cadeia de conexão SQL por uma senha válida. Embora os nomes de banco de dados e de usuário sejam copiados, a senha deverá ser inserida manualmente.
3 – Criar o pipeline
Os indexadores exigem um objeto de fonte de dados e um índice. O código relevante encontra-se em dois arquivos:
hotel.cs, que contém um esquema que define o índice
Program.cs, que contém funções para criar e gerenciar estruturas no seu serviço
Em hotel.cs
O esquema de índice define a coleção de campos, incluindo atributos especificando as operações permitidas, por exemplo, se um campo é de texto completo que pode ser pesquisado, filtrado ou classificado, conforme mostrado na definição de campo a seguir para HotelName. Um SearchableField pode ser pesquisado por texto completo por definição. Outros atributos são atribuídos explicitamente.
. . .
[SearchableField(IsFilterable = true, IsSortable = true)]
[JsonPropertyName("hotelName")]
public string HotelName { get; set; }
. . .
Um esquema também pode incluir outros elementos, incluindo perfis de pontuação para acelerar uma pontuação de pesquisa, analisadores personalizados e outros constructos. No entanto, neste caso, o esquema é definido de forma esparsa, consistindo somente em campos encontrados nos conjuntos de dados de exemplo.
Em Program.cs
O programa principal inclui lógica para a criação de um cliente indexador, um índice, uma fonte de dados e um indexador. O código verifica e exclui os recursos existentes do mesmo nome, sob a suposição de que você pode executar este programa várias vezes.
O objeto de fonte de dados é definido com configurações específicas de recursos do Banco de Dados SQL do Azure, incluindo a indexação parcial ou incremental para usar os recursos internos de detecção de alterações do SQL do Azure. O banco de dados de hotéis de demonstração de origem no SQL do Azure tem uma coluna de "exclusão reversível" chamada IsDeleted. Quando essa coluna está definida como true no banco de dados, o indexador remove o documento correspondente do índice do Azure AI Search.
Console.WriteLine("Creating data source...");
var dataSource =
new SearchIndexerDataSourceConnection(
"hotels-sql-ds",
SearchIndexerDataSourceType.AzureSql,
configuration["AzureSQLConnectionString"],
new SearchIndexerDataContainer("hotels"));
indexerClient.CreateOrUpdateDataSourceConnection(dataSource);
Um objeto de indexador é independente da plataforma, com a chamada, a programação e a configuração sendo as mesmas independentemente da origem. Esse indexador de exemplo inclui uma agenda e uma opção de redefinir que limpa o histórico do indexador e chama um método para criar e executar o indexador imediatamente. Para criar ou atualizar um indexador, use CreateOrUpdateIndexerAsync.
Console.WriteLine("Creating Azure SQL indexer...");
var schedule = new IndexingSchedule(TimeSpan.FromDays(1))
{
StartTime = DateTimeOffset.Now
};
var parameters = new IndexingParameters()
{
BatchSize = 100,
MaxFailedItems = 0,
MaxFailedItemsPerBatch = 0
};
// Indexer declarations require a data source and search index.
// Common optional properties include a schedule, parameters, and field mappings
// The field mappings below are redundant due to how the Hotel class is defined, but
// we included them anyway to show the syntax
var indexer = new SearchIndexer("hotels-sql-idxr", dataSource.Name, searchIndex.Name)
{
Description = "Data indexer",
Schedule = schedule,
Parameters = parameters,
FieldMappings =
{
new FieldMapping("_id") {TargetFieldName = "HotelId"},
new FieldMapping("Amenities") {TargetFieldName = "Tags"}
}
};
await indexerClient.CreateOrUpdateIndexerAsync(indexer);
As execuções do indexador geralmente são agendadas, mas, durante o desenvolvimento, talvez seja interessante executar o indexador imediatamente usando RunIndexerAsync.
Console.WriteLine("Running Azure SQL indexer...");
try
{
await indexerClient.RunIndexerAsync(indexer.Name);
}
catch (RequestFailedException ex) when (ex.Status == 429)
{
Console.WriteLine("Failed to run indexer: {0}", ex.Message);
}
4 – Compilar a solução
Pressione F5 para compilar e executar sua solução. O programa é executado no modo de depuração. Uma janela de console relata o status de cada operação.

O código é executado localmente no Visual Studio, conectando-se ao serviço de pesquisa no Azure, que, por sua vez, conecta-se ao Banco de Dados SQL do Azure e recupera o conjunto de dados. Com essas muitas operações, há vários pontos potenciais de falha. Se você receber um erro, verifique as seguintes condições primeiro:
As informações de conexão do serviço de pesquisa fornecidas são a URL completa. Se você digitou somente o nome do serviço, as operações são interrompidas durante a criação do índice, com um erro de falha de conexão.
Informações de conexão do banco de dados em appsettings.json. Elas devem ser limitadas à cadeia de conexão ADO.NET obtida no portal, modificadas para incluir um nome de usuário e senha válidos para o seu banco de dados. A conta de usuário deve ter permissão para recuperar dados. Seu endereço IP de cliente local precisa ter acesso de entrada permitido por meio do firewall.
Limites de recursos. Não esqueça que a Camada gratuita tem um limite de três índices, indexadores e fontes de dados. Um serviço no limite máximo não pode criar novos objetos.
5 – Pesquisar
Use o portal do Azure para verificar a criação do objeto e, em seguida, use o Gerenciador de pesquisa para consultar o índice.
Entre no portal do Azure e, no painel de navegação esquerdo do serviço de pesquisa, abra cada página por vez para verificar se o objeto foi criado. Índices, Indexadores e Fontes de dados terão "hotels-sql-idx", "hotels-sql-indexer" e "hotels-sql-ds", respectivamente.
Na guia Índices, selecione o índice Hotels-sql-idx. Na página de hotéis, o Gerenciador de pesquisa é a primeira guia.
Selecione Pesquisar para emitir uma consulta vazia.
As três entradas no índice são retornadas como documentos JSON. O Gerenciador de pesquisa retorna documentos em JSON para que você possa exibir toda a estrutura.

Em seguida, mude para JSON View para poder inserir os parâmetros de consulta:
{ "search": "river", "count": true }Essa consulta invoca a pesquisa de texto completo no termo
river, e o resultado inclui uma contagem dos documentos correspondentes. Retornar a contagem de correspondência de documentos é útil em cenários de teste, quando você tiver um índice grande com milhares ou milhões de documentos. Nesse caso, apenas um documento corresponde à consulta.Por último, insira parâmetros que limitem os resultados da pesquisa aos campos de interesse:
{ "search": "river", "select": "hotelId, hotelName, baseRate, description", "count": true }A resposta da consulta é reduzida para os campos selecionados, resultando em uma saída mais concisa.
Redefinir e execute novamente
Nos primeiros estágios experimentais de desenvolvimento, a abordagem mais prática para iterações de design é excluir os objetos da IA do Azure Search e permitir que seu código os reconstrua. Nomes de recurso são exclusivos. Excluir um objeto permite que você recriá-la usando o mesmo nome.
O código de exemplo deste tutorial verifica se há objetos existentes e os exclui, de modo que você possa executar novamente o código.
Use também o portal para excluir índices, indexadores e fontes de dados.
Limpar os recursos
Quando você está trabalhando em sua própria assinatura, no final de um projeto, é uma boa ideia remover os recursos que já não são necessários. Recursos deixados em execução podem custar dinheiro. Você pode excluir os recursos individualmente ou excluir o grupo de recursos para excluir todo o conjunto de recursos.
Você pode localizar e gerenciar recursos no portal usando o link Todos os recursos ou Grupos de recursos no painel de navegação à esquerda.
Próximas etapas
Agora que você está familiarizado com os conceitos básicos da indexação do Banco de Dados SQL, vamos examinar mais de perto a configuração do indexador.