Criar uma consulta vetorial no Azure AI Search
Na Pesquisa de IA do Azure, se você tiver um índice de vetor, este artigo explicará como:
Este artigo usa REST para ilustração. Para obter exemplos de código em outros idiomas, consulte o repositório GitHub azure-search-vector-samples para soluções de ponta a ponta que incluem consultas de vetor.
Você também pode usar o Search Explorer no portal do Azure.
Pré-requisitos
IA do Azure Search, em qualquer região e camada.
Um índice de vetor na Pesquisa de IA do Azure. Verifique se há uma seção
vectorSearchem seu índice para confirmar um índice de vetor.Opcionalmente, adicione um vetorizador ao índice para conversão de texto para vetor interno ou de imagem para vetor durante consultas.
Visual Studio Code com um cliente REST e dados de exemplo se você quiser executar esses exemplos por conta própria. Para começar a usar o cliente REST, consulte Início Rápido: Pesquisa de IA do Azure usando o REST.
Converter uma entrada de cadeia de caracteres de consulta em um vetor
Para consultar um campo vetorial, a consulta em si deve ser um vetor.
Uma abordagem para converter a cadeia de caracteres de consulta de texto de um usuário em sua representação de vetor é chamar uma biblioteca de inserção ou API no código do aplicativo. Como prática recomendada, sempre use os mesmos modelos de inserção usados para gerar inserções nos documentos de origem. Você pode encontrar exemplos de código mostrando como gerar inserções no repositório azure-search-vector-samples.
Uma segunda abordagem é usar a vetorização integrada, atualmente disponível para o público geral, para que a Pesquisa de IA do Azure manipule suas entradas e saídas de vetorização de consulta.
Aqui está um exemplo de API REST de uma cadeia de caracteres de consulta enviada a uma implantação de um modelo de inserção do Azure OpenAI:
POST https://{{openai-service-name}}.openai.azure.com/openai/deployments/{{openai-deployment-name}}/embeddings?api-version={{openai-api-version}}
Content-Type: application/json
api-key: {{admin-api-key}}
{
"input": "what azure services support generative AI'"
}
A resposta esperada é 202 para uma chamada bem-sucedida para o modelo implantado.
O campo "embedding" no corpo da resposta é a representação vetorial da cadeia de caracteres de consulta "input". Para fins de teste, você copiaria o valor da matriz "embedding" em "vectorQueries.vector" em uma solicitação de consulta, usando a sintaxe mostrada nas próximas seções.
A resposta real dessa chamada POST para o modelo implantado inclui 1536 inserções, cortadas aqui apenas para os primeiros vetores para legibilidade.
{
"object": "list",
"data": [
{
"object": "embedding",
"index": 0,
"embedding": [
-0.009171937,
0.018715322,
...
-0.0016804502
]
}
],
"model": "ada",
"usage": {
"prompt_tokens": 7,
"total_tokens": 7
}
}
Nessa abordagem, o código do aplicativo é responsável por se conectar a um modelo, gerar inserções e lidar com a resposta.
Solicitação de consulta vetorial
Esta seção mostra a estrutura básica de uma consulta vetorial. Você pode usar o portal do Azure, as APIs REST ou os SDKs do Azure para formular uma consulta de vetor. Se você estiver migrando de 2023-07-01-Preview, haverá alterações significativas. Consulte Atualizar para a API REST mais recente para obter detalhes.
2024-07-01 é a versão estável da API REST para Search POST. Esta versão dá suporte a:
vectorQueriesé o constructo da busca em vetores.vectorQueries.kinddefinido comovectorpara uma matriz de vetores ou definido comotextse a entrada for uma cadeia de caracteres e você tiver um vetorizador.vectorQueries.vectoré a consulta (uma representação de vetor de texto ou uma imagem).vectorQueries.weight(opcional) especifica o peso relativo de cada consulta vetorial incluída nas operações de pesquisa (consulte Ponderação de vetor).exhaustive(opcional) invoca o KNN exaustivo no momento da consulta, mesmo que o campo seja indexado para HNSW.
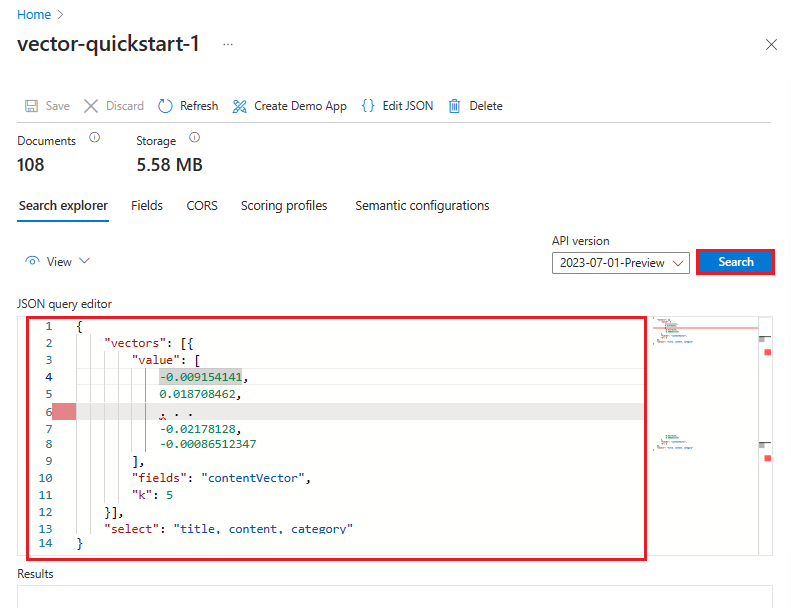
No exemplo a seguir, o vetor é uma representação dessa cadeia de caracteres: "quais serviços do Azure dão suporte à pesquisa de texto completo". A consulta tem como destino o campo contentVector. A consulta retorna k resultados. O vetor real tem 1536 inserções. Portanto, ele é cortado neste exemplo para fins de legibilidade.
POST https://{{search-service-name}}.search.windows.net/indexes/{{index-name}}/docs/search?api-version=2024-07-01
Content-Type: application/json
api-key: {{admin-api-key}}
{
"count": true,
"select": "title, content, category",
"vectorQueries": [
{
"kind": "vector",
"vector": [
-0.009154141,
0.018708462,
. . .
-0.02178128,
-0.00086512347
],
"exhaustive": true,
"fields": "contentVector",
"weight": 0.5,
"k": 5
}
]
}
Resposta da consulta vetorial
Na Pesquisa de IA do Azure, as respostas de consulta consistem em todos os campos retrievable por padrão. No entanto, é comum limitar os resultados da pesquisa a um subconjunto de campos retrievable listando-os em uma instrução select.
Em uma consulta de vetor, considere cuidadosamente se você precisa vetor de campos em uma resposta. Os campos de vetor não são legíveis por humanos, portanto, se você estiver enviando uma resposta por push para uma página da Web, deverá escolher campos que não são representativos do resultado. Por exemplo, se a consulta for executada em contentVector, você poderá retornar content.
Se você quiser campos de vetor no resultado, aqui está um exemplo da estrutura de resposta. contentVector é uma matriz de cadeia de caracteres de inserções, cortada aqui para fins de brevidade. A pontuação de pesquisa indica relevância. Outros campos não vetoriais são incluídos para contexto.
{
"@odata.count": 3,
"value": [
{
"@search.score": 0.80025613,
"title": "Azure Search",
"category": "AI + Machine Learning",
"contentVector": [
-0.0018343845,
0.017952163,
0.0025753193,
...
]
},
{
"@search.score": 0.78856903,
"title": "Azure Application Insights",
"category": "Management + Governance",
"contentVector": [
-0.016821077,
0.0037742127,
0.016136652,
...
]
},
{
"@search.score": 0.78650564,
"title": "Azure Media Services",
"category": "Media",
"contentVector": [
-0.025449317,
0.0038463024,
-0.02488436,
...
]
}
]
}
Pontos principais:
kdetermina quantos resultados vizinhos mais próximos são retornados, neste caso, três. As consultas vetoriais sempre retornamkresultados, supondo que pelo menoskdocumentos existam, mesmo que haja documentos com pouca similaridade, pois o algoritmo encontra qualquerkvizinho mais próximo ao vetor de consulta.O
@search.scoreé determinado pelo algoritmo de busca em vetores.Os campos nos resultados da pesquisa são todos
retrievablecampos ou campos em uma cláusulaselect. Durante a execução da consulta vetor, a correspondência é feita apenas em dados de vetor. No entanto, uma resposta pode incluir qualquer camporetrievableem um índice. Como não há nenhuma facilidade para decodificar um resultado de campo de vetor, a inclusão de campos de texto não vetoriais é útil para seus valores legíveis por humanos.
Vários campos vetoriais
Você pode definir a propriedade "vectorQueries.fields" como vários campos de vetor. A consulta de vetor é executada em cada campo de vetor que você fornece na lista fields. Ao consultar vários campos de vetor, verifique se cada um contém inserções do mesmo modelo de inserção e se a consulta também é gerada do mesmo modelo de inserção.
POST https://{{search-service-name}}.search.windows.net/indexes/{{index-name}}/docs/search?api-version=2024-07-01
Content-Type: application/json
api-key: {{admin-api-key}}
{
"count": true,
"select": "title, content, category",
"vectorQueries": [
{
"kind": "vector",
"vector": [
-0.009154141,
0.018708462,
. . .
-0.02178128,
-0.00086512347
],
"exhaustive": true,
"fields": "contentVector, titleVector",
"k": 5
}
]
}
Várias consultas vetoriais
A busca em vetores de várias consultas envia várias consultas em vários campos de vetor no índice de pesquisa. Um exemplo comum dessa solicitação de consulta é o uso de modelos como CLIP para uma busca em vetores multimodal em que o mesmo modelo pode vetorizar conteúdo de imagem e texto.
O exemplo de consulta a seguir procura similaridade em myImageVector e myTextVector, mas envia duas inserções de consulta diferentes, respectivamente, cada uma em execução em paralelo. Essa consulta produz um resultado com pontuação usando RRF (Fusão de Classificação Recíproca).
vectorQueriesfornece uma matriz de consultas vetoriais.vectorcontém os vetores de imagem e os vetores de texto no índice de pesquisa. Cada instância é uma consulta separada.fieldsespecifica qual campo vetorial será direcionado.ké o número de correspondências do vizinho mais próximo a serem incluídas nos resultados.
{
"count": true,
"select": "title, content, category",
"vectorQueries": [
{
"kind": "vector",
"vector": [
-0.009154141,
0.018708462,
. . .
-0.02178128,
-0.00086512347
],
"fields": "myimagevector",
"k": 5
},
{
"kind": "vector"
"vector": [
-0.002222222,
0.018708462,
-0.013770515,
. . .
],
"fields": "mytextvector",
"k": 5
}
]
}
Os resultados da pesquisa incluem uma combinação de texto e imagens, supondo que o índice de pesquisa inclua um campo para o arquivo de imagem (um índice de pesquisa não armazena imagens).
Consultar com vetorização integrada
Esta seção mostra uma consulta vetorial que invoca a vetorização integrada que converte um texto ou uma consulta de imagem em um vetor. Recomendamos a API REST 2024-07-01 estável, o Gerenciador de Pesquisa ou pacotes mais recentes do SDK do Azure para esse recurso.
Um pré-requisito é um índice de pesquisa que tem um vetorizador configurado e atribuído a um campo vetorial. O vetorizador fornece informações de conexão para um modelo de inserção usado no momento da consulta.
O Gerenciador de Pesquisa dá suporte à vetorização integrada no momento da consulta. Se o índice contiver campos de vetor e tiver um vetor, você poderá usar a conversão de texto para vetor interna.
Entre no portal do Azure com sua conta do Azure e acesse o serviço de IA do Azure Search.
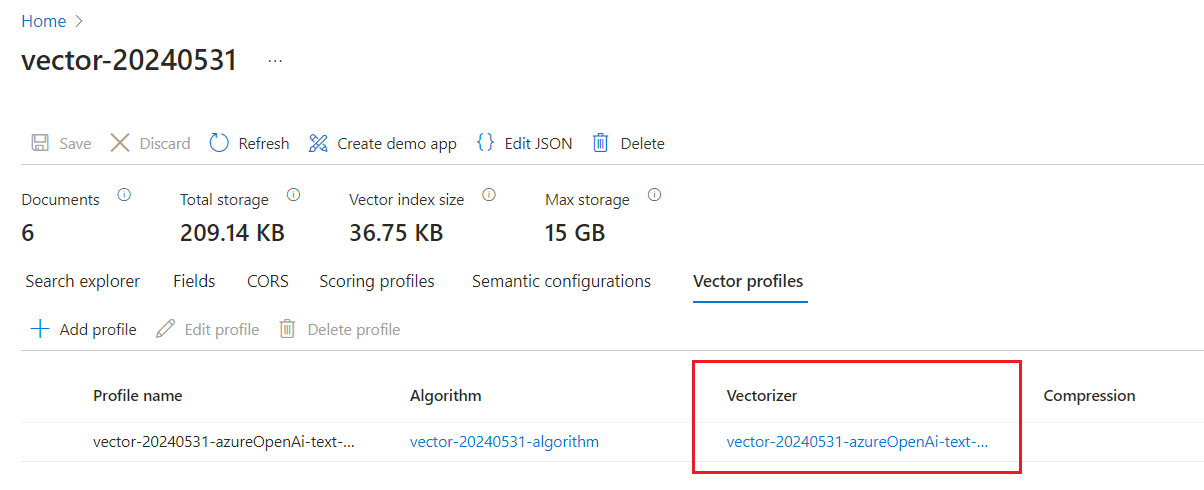
No menu à esquerda, expanda Gerenciamento de Pesquisa>Índices e selecione seu índice. O Gerenciador de Pesquisa é a primeira guia na página de índice.
Verifique Perfis de vetor para confirmar se você tem um vetor.
No Gerenciador de Pesquisa, você pode inserir uma cadeia de caracteres de texto na barra de pesquisa padrão no modo de exibição de consulta. O vetor interno converte sua cadeia de caracteres em um vetor, executa a pesquisa e retorna resultados.
Como alternativa, você pode selecionar Exibir>Exibição JSON para exibir ou modificar a consulta. Se os vetores estiverem presentes, o Gerenciador de Pesquisa configurará uma consulta vetorial automaticamente. Você pode usar a exibição JSON para selecionar campos usados na pesquisa e na resposta, adicionar filtros ou construir consultas mais avançadas, como híbrida. Um JSON de exemplo é fornecido na guia API REST desta seção.
Número de resultados classificados em uma resposta de consulta vetorial
Uma consulta vetorial especifica o parâmetro k, que determina quantas correspondências são retornadas nos resultados. O mecanismo de pesquisa sempre retorna o número k de correspondências. Se k for maior que o número de documentos no índice, o número de documentos determinará o limite superior do que pode ser retornado.
Se você estiver familiarizado com a pesquisa de texto completo, sabe que não deve esperar resultados se o índice não contiver um termo ou frase. No entanto, na busca em vetores, a operação de pesquisa está identificando vizinhos mais próximos e sempre retornará k resultados mesmo que os vizinhos mais próximos não sejam semelhantes. Portanto, é possível obter resultados para consultas sem sentido ou fora do tópico, especialmente se você não estiver usando prompts para definir limites. Os resultados menos relevantes têm uma pontuação de similaridade pior, mas ainda são os vetores "mais próximos" se não houver nada mais próximo. Dessa forma, uma resposta sem resultados significativos ainda pode retornar k resultados, mas a pontuação de similaridade de cada resultado seria baixa.
Uma abordagem híbrida que inclui a pesquisa de texto completo pode atenuar esse problema. Outra mitigação é definir um limite mínimo na pontuação da pesquisa, mas somente se a consulta for uma consulta de vetor único pura. As consultas híbridas não são propícias a limites mínimos porque os intervalos de RRF são muito menores e voláteis.
Os parâmetros de consulta que afetam a contagem de resultados incluem:
"k": nresultados de consultas somente de vetores"top": nresultados de consultas híbridas que incluem um parâmetro "search"
Tanto "k" quanto "top" são opcionais. Não especificado, 50 é o número padrão de resultados em uma resposta. Você pode definir "top" e "skip" para percorrer mais resultados ou alterar o padrão.
Algoritmos de classificação usados em uma consulta de vetor
A classificação dos resultados é calculada por uma das seguintes maneiras:
- Métrica de similaridade
- RRF (Fusão de Classificação Recíproca), se houver vários conjuntos de resultados da pesquisa.
Métrica de similaridade
A métrica de similaridade especificada na seção vectorSearch de índice para uma consulta vetorial somente. Os valores válidos são cosine, euclidean e dotProduct.
Os modelos de inserção do Azure OpenAI usam a similaridade de cosseno. Portanto, se você estiver usando os modelos de inserção do Azure OpenAI, cosine será a métrica recomendada. Outras métricas de classificação com suporte incluem euclidean e dotProduct.
Usando o RRF
Vários conjuntos são criados se a consulta destina-se a vários campos de vetor, executa várias consultas vetoriais em paralelo ou se a consulta é um híbrido de vetor e pesquisa de texto completo, com ou sem classificação semântica.
Durante a execução da consulta, uma consulta vetor só pode ser direcionada a um índice de vetor interno. Portanto, para vários campos vetoriais e várias consultas vetoriais, o mecanismo de pesquisa gera várias consultas direcionadas aos respectivos índices vetoriais de cada campo. A saída é um conjunto de resultados classificados para cada consulta, os quais são fundidos usando a RRF. Para obter mais informações, consulte Pontuação de relevância usando o RRF (Reciprocal Rank Fusion).
Ponderação de vetor
Adicione um parâmetro de consulta weight para especificar o peso relativo de cada consulta em vetores incluída nas operações de pesquisa. Esse valor é usado ao combinar os resultados de várias listas de classificação produzidas por duas ou mais consultas vetoriais na mesma solicitação ou na parte vetorial de uma consulta híbrida.
O padrão é 1,0 e o valor precisa ser um número positivo maior que zero.
Os pesos são usados ao calcular as pontuações de fusão de classificação recíproca de cada documento. O cálculo é multiplicador do valor de weight em relação à pontuação de classificação do documento dentro de seu respectivo conjunto de resultados.
O exemplo a seguir é uma consulta híbrida com duas cadeias de caracteres de consulta de vetor e uma cadeia de caracteres de texto. Os pesos são atribuídos às consultas de vetor. A primeira consulta é 0,5 ou metade do peso, reduzindo a importância dela na solicitação. A segunda consulta vetorial é duas vezes mais importante.
POST https://[service-name].search.windows.net/indexes/[index-name]/docs/search?api-version=2024-07-01
{
"vectorQueries": [
{
"kind": "vector",
"vector": [1.0, 2.0, 3.0],
"fields": "my_first_vector_field",
"k": 10,
"weight": 0.5
},
{
"kind": "vector",
"vector": [4.0, 5.0, 6.0],
"fields": "my_second_vector_field",
"k": 10,
"weight": 2.0
}
],
"search": "hello world"
}
A ponderação vetorial se aplica somente a vetores. A consulta de texto neste exemplo ("Olá, Mundo") tem um peso implícito de 1,0 ou peso neutro. No entanto, em uma consulta híbrida, você pode aumentar ou diminuir a importância dos campos de texto definindo o parâmetro maxTextRecallSize.
Definir limites para excluir resultados de baixa pontuação (versão prévia)
Como a pesquisa de vizinho mais próxima sempre retorna os vizinhos k solicitados, é possível obter correspondências de baixa pontuação como parte de atender ao requisito de número k nos resultados da pesquisa. Para excluir o resultado da pesquisa de baixa pontuação, você pode adicionar um parâmetro de consulta threshold que filtra os resultados com base em uma pontuação mínima. A filtragem ocorre antes de unir os resultados de conjuntos de recall diferentes.
Esse parâmetro ainda está em versão prévia. Recomendamos a versão prévia da API REST 2024-05-01-preview.
Neste exemplo, todas as correspondências que pontuam abaixo de 0,8 são excluídas dos resultados da pesquisa de vetor, mesmo que o número de resultados fique abaixo de k.
POST https://[service-name].search.windows.net/indexes/[index-name]/docs/search?api-version=2024-05-01-preview
Content-Type: application/json
api-key: [admin key]
{
"vectorQueries": [
{
"kind": "vector",
"vector": [1.0, 2.0, 3.0],
"fields": "my-cosine-field",
"threshold": {
"kind": "vectorSimilarity",
"value": 0.8
}
}
]
}
MaxTextSizeRecall para pesquisa híbrida (versão prévia)
As consultas vetoriais geralmente são usadas em constructos híbridos que incluem campos não vetoriais. Se você descobrir que os resultados classificados em BM25 estão super- ou subrepresentados em resultados de uma consulta híbrida, você pode definir maxTextRecallSize para aumentar ou diminuir os resultados classificados em BM25 fornecidos para a classificação híbrida.
Você só pode definir essa propriedade em solicitações híbridas que incluem componentes "search" e "vectorQueries".
Esse parâmetro ainda está em versão prévia. Recomendamos a versão prévia da API REST 2024-05-01-preview.
Para obter mais informações, consulte Definir maxTextRecallSize – Criar uma consulta híbrida.
Próximas etapas
Como próxima etapa, examine exemplos de código de consulta vetor em Python, C# ou JavaScript.