Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
O Azure Synapse Analytics é um serviço de análise que reúne data warehouse corporativo e análise de Big Data. Ele dá a liberdade para consultar dados conforme desejado.
Observação
Para obter mais informações sobre o Azure Synapse Analytics, assista a este vídeo que explica os Aprimoramentos na movimentação de dados.
Componentes de arquitetura do SQL do Synapse
O pool de SQL dedicado (antigo SQL DW) usa uma arquitetura de expansão para distribuir o processamento computacional dos dados em vários nós de expansão. A unidade de escala é uma abstração de poder de computação que é conhecida como unidade de data warehouse. A computação é separada do armazenamento, o que permite que você dimensione a computação independentemente dos dados em seu sistema.
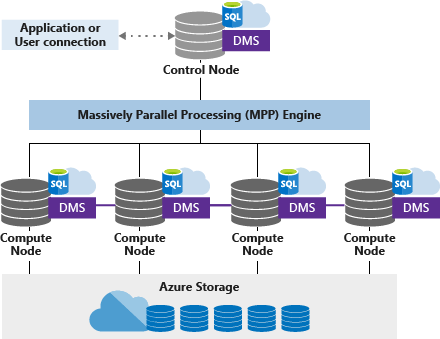
O pool de SQL dedicado (antigo SQL DW) usa uma arquitetura baseada em nó. Aplicativos conectam e emitem comandos T-SQL para um nó de Controle. O nó de Controle executa o mecanismo de consulta distribuída, que otimiza consultas para processamento paralelo e, em seguida, passa as operações para nós de Computação para realizar seu trabalho em paralelo.
Os nós de Computação armazenam todos os dados de usuário no Armazenamento do Azure e executam as consultas paralelas. O serviço de movimentação de dados (DMS) é um serviço de nível de sistema interno que move dados entre os nós, conforme necessário para executar consultas em paralelo e retornar resultados precisos.
Com armazenamento e computação desacoplados, ao usar um pool de SQL dedicado (antigo SQL DW), é possível:
- Utilize computação independentemente do tamanho de suas necessidades de armazenamento.
- Aumentar ou reduzir a potência de computação em um pool de SQL dedicado (antigo SQL DW) sem mover os dados.
- Pause a capacidade de computação ao deixar dados intactos para que você só pague pelo armazenamento.
- Retomar a capacidade de computação durante horas operacionais.
Armazenamento do Azure
O pool de SQL dedicado (antigo SQL DW) aproveita o Armazenamento do Microsoft Azure para manter os dados do usuário seguros. Como os dados são armazenados e gerenciados pelo armazenamento do Azure, é gerada uma cobrança separada para o consumo de armazenamento. Os dados em si são fragmentados em distribuições, para otimizar o desempenho do sistema. Você pode escolher qual padrão de fragmentação usar para distribuir os dados quando você define a tabela. Esses padrões de fragmentação são compatíveis com:
- Hash
- Rodízio
- Replicar
Nó de controle
O nó de controle é o cérebro da arquitetura. É o front-end que interage com todos os aplicativos e conexões. O mecanismo de consulta distribuída é executado no nó de controle para otimizar e coordenar consultas paralelas. Quando você envia uma consulta T-SQL, o nó de Controle a transforma em consultas que são executadas em cada distribuição paralelamente.
Nós de computação
Os nós de computação fornecem capacidade de computação. Distribuições são mapeados para nós de computação para processamento. À medida que você paga por mais recursos de computação, as distribuições são remapeadas para os nós de computação disponíveis. O número de intervalos de nós de 1 a 60 de computação e é determinado pelo nível de serviço para o SQL do Synapse.
Cada nó de computação tem uma ID de nó que está visível nas exibições do sistema. Você pode ver a ID do nó de Computação olhando para a coluna node_id nas exibições do sistema cujos nomes começam com sys.pdw_nodes. Para obter uma lista das exibições de sistema, confira Exibições do sistema SQL do Synapse.
Serviço de movimentação de dados
O Serviço de movimentação de dados (DMS) é a tecnologia de transporte de dados que coordena a movimentação de dados entre os nós de computação. Algumas consultas exigem a movimentação de dados para garantir que as consultas paralelas retornem resultados precisos. Quando a movimentação de dados é necessária, DMS garante que os dados corretos cheguem ao local correto.
Distribuições
Uma distribuição é a unidade básica de armazenamento e processamento para consultas paralelas que são executadas em dados distribuídos. Quando SQL do Synapse executa uma consulta, o trabalho é dividido em 60 consultas menores que são executadas em paralelo.
Cada uma das 60 consultas menores é executada em uma das distribuições de dados. Cada nó de computação gerencia um ou mais de 60 distribuições. Um pool de SQL dedicado (antigo SQL DW) com recursos de computação máximos tem uma distribuição por nó de computação. Um pool de SQL dedicado (antigo SQL DW) com recursos de computação mínimos tem todas as distribuições em um nó de computação.
Observação
Para obter recomendações sobre a melhor estratégia de distribuição de tabela a ser usada com base em suas cargas de trabalho, confira o Assistente de Distribuição do SQL do Azure Synapse.
Tabelas distribuídas em hash
Uma tabela de hash distribuída pode fornecer o melhor desempenho de consulta para junções e agregações em tabelas grandes.
Para fragmentar dados em uma tabela distribuída por hash, uma função de hash é usada para atribuir de forma determinística cada linha a uma distribuição. Na definição de tabela, uma das colunas é designada como a coluna de distribuição. A função de hash usa valores na coluna de distribuição para atribuir cada linha a uma distribuição.
O diagrama a seguir ilustra como uma (tabela não distribuída) completa é armazenada como uma tabela distribuída em hash.

- Cada linha pertence a uma distribuição.
- Um algoritmo de hash determinístico atribui cada linha a uma distribuição.
- O número de linhas de tabela por distribuição varia conforme mostrado pelos diferentes tamanhos de tabelas.
Há considerações de desempenho para a seleção de uma coluna de distribuição, como distinção, distorção de dados e tipos de consultas executadas no sistema.
Tabelas distribuídas round robin
Uma tabela de round-robin é a tabela mais simples para criar e oferece um desempenho rápido quando usada como uma tabela de preparo para cargas.
Uma tabela distribuída round-robin distribui dados uniformemente entre a tabela, mas sem qualquer otimização adicional. Uma distribuição é escolhida primeiramente de forma aleatória e, em seguida, buffers de linhas são atribuídos a distribuições em sequência. É rápido carregar dados em uma tabela de round-robin, mas o desempenho da consulta geralmente pode ser melhor com tabelas de hash distribuídas. Junções de tabelas de round-robin exigem nova recombinação de dados, e isso leva tempo adicional.
Tabelas replicadas
Uma tabela replicada fornece o melhor desempenho de consulta para tabelas pequenas.
Uma tabela replicada faz cache de uma cópia completa da tabela em cada nó de computação. Consequentemente, replicar uma tabela elimina a necessidade de transferir dados entre nós de Computação antes de uma junção ou agregação. Tabelas replicadas são melhor usadas com tabelas pequenas. Armazenamento adicional é necessário e há custos adicionais ao gravar dados que tornam grandes tabelas inexequíveis.
O diagrama a seguir mostra uma tabela replicada armazenada em cache na primeira distribuição em cada nó de computação.

Conteúdo relacionado
Agora que você já sabe um pouco sobre o Azure Synapse, saiba como criar rapidamente um pool de SQL dedicado (antigo SQL DW) e carregar dados de exemplo. Se você ainda não conhece o Azure, poderá achar os Conceitos fundamentais do Azure útil à medida que encontrar nova terminologia. Ou, dê uma olhada em alguns desses outros recursos do Azure Synapse.