Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Dica
Microsoft Fabric Data Warehouse é um armazém relacional de escala empresarial com base de data lake, arquitetura pronta para o futuro, IA integrada e novos recursos. Se você não estiver familiarizado com o data warehouse, comece com Fabric Data Warehouse. As cargas de trabalho existentes de pools de SQL dedicados podem ser atualizadas para Fabric para acessar novos recursos em ciência de dados, análise em tempo real e relatórios.
Aplica-se a: Pools de SQL dedicados do Azure Synapse Analytics
Quando os usuários consultam uma tabela columnstore no pool SQL dedicado, o otimizador verifica os valores mínimo e máximo armazenados em cada segmento. Os segmentos que estão fora dos limites do predicado de consulta não são lidos do disco para a memória. Uma consulta pode terminar mais rapidamente, se o número de segmentos a serem lidos e o tamanho total forem pequenos.
Observação
Este artigo aplica-se aos Pools de SQL dedicado do Azure Synapse Analytics. Para obter informações sobre índices columnstore ordenados no SQL Server e em outras plataformas SQL, consulte Ajuste de desempenho com índices columnstore clusterizados ordenados.
Comparação entre os índices columnstore clusterizados ordenado e não ordenado
Por padrão, um componente interno (construtor de índice) cria um CCI (índice columnstore clusterizado) não ordenado em cada tabela criada sem uma opção de índice. Os dados de cada coluna são compactados em diferentes segmentos de rowgroup de CCI. Há metadados no intervalo de valores de cada segmento, de modo que os segmentos que estão fora dos limites do predicado de consulta não são lidos do disco durante a execução da consulta. O CCI oferece o nível mais alto de compactação de dados e reduz o tamanho dos segmentos a serem lidos para que as consultas possam ser executadas mais rapidamente. No entanto, como o construtor de índice não classifica os dados antes de compactá-los em segmentos, podem ocorrer segmentos com intervalos de valores sobrepostos, o que faz com que as consultas leiam mais segmentos do disco e demorem mais tempo para serem concluídas.
Ordenar índices columnstore clusterizados habilitando a eliminação eficiente do segmento. Isso resulta em um desempenho muito mais rápido que ignora grandes quantidades de dados ordenados e não correspondem ao predicado de consulta. Ao criar um CCI ordenado, o mecanismo do pool de SQL dedicado classifica os dados existentes na memória pelas chaves de ordem antes do construtor de índice os compactar em segmentos de índice. Com dados classificados, a sobreposição é reduzida, o que permite que as consultas tenham uma eliminação de segmento mais eficiente e um desempenho mais rápido, pois o número de segmentos a serem lidos do disco é menor. Se todos os dados puderem ser classificados na memória de uma vez, será possível evitar a sobreposição de segmento. Devido às grandes tabelas dos data warehouses, esse cenário não acontece com frequência.
Para verificar os intervalos de segmento de uma coluna, execute o seguinte comando com os nomes da tabela e da coluna:
SELECT o.name, pnp.index_id,
cls.row_count, pnp.data_compression_desc,
pnp.pdw_node_id, pnp.distribution_id, cls.segment_id,
cls.column_id,
cls.min_data_id, cls.max_data_id,
cls.max_data_id-cls.min_data_id as difference
FROM sys.pdw_nodes_partitions AS pnp
JOIN sys.pdw_nodes_tables AS Ntables ON pnp.object_id = NTables.object_id AND pnp.pdw_node_id = NTables.pdw_node_id
JOIN sys.pdw_table_mappings AS Tmap ON NTables.name = TMap.physical_name AND substring(TMap.physical_name,40, 10) = pnp.distribution_id
JOIN sys.objects AS o ON TMap.object_id = o.object_id
JOIN sys.pdw_nodes_column_store_segments AS cls ON pnp.partition_id = cls.partition_id AND pnp.distribution_id = cls.distribution_id
JOIN sys.columns as cols ON o.object_id = cols.object_id AND cls.column_id = cols.column_id
WHERE o.name = '<Table Name>' and cols.name = '<Column Name>' and TMap.physical_name not like '%HdTable%'
ORDER BY o.name, pnp.distribution_id, cls.min_data_id;
Observação
Em uma tabela de CCI ordenada, os novos dados resultantes do mesmo lote de operações DML ou de carregamento de dados são ordenados dentro desse lote, sem ordenação global de todos os dados na tabela. Os usuários podem RECRIAR o CCI ordenado para classificar todos os dados da tabela. No pool de SQL dedicado, a reconstrução do índice columnstore é uma operação offline. Para uma tabela particionada, o REBUILD é feito em uma partição por vez. Os dados da partição que está sendo reconstruída estão "offline" e indisponíveis até que a reconstrução seja concluída para essa partição.
Desempenho de consulta
O ganho de desempenho de uma consulta em um CCI ordenado depende dos padrões de consulta, do tamanho dos dados, de quão bem os dados estão classificados, da estrutura física dos segmentos, bem como da DWU e da classe de recurso escolhida para a execução da consulta. Os usuários devem revisar todos esses fatores antes de escolher as colunas de ordenação ao criar uma tabela de CCI ordenada.
Consultas com todos esses padrões normalmente são executadas mais rapidamente com o CCI ordenado.
- As consultas têm predicados de igualdade, desigualdade ou intervalo de valores.
- As colunas de predicado e de CCI ordenado são as mesmas.
Neste exemplo, a tabela T1 tem um índice columnstore agrupado ordenado na sequência de Col_C, Col_B e Col_A.
CREATE CLUSTERED COLUMNSTORE INDEX MyOrderedCCI ON T1
ORDER (Col_C, Col_B, Col_A);
O desempenho da consulta 1 e da consulta 2 pode se beneficiar mais do CCI ordenado do que das outras consultas, pois fazem referência a todas as colunas CCI ordenadas.
-- Query #1:
SELECT * FROM T1 WHERE Col_C = 'c' AND Col_B = 'b' AND Col_A = 'a';
-- Query #2
SELECT * FROM T1 WHERE Col_B = 'b' AND Col_C = 'c' AND Col_A = 'a';
-- Query #3
SELECT * FROM T1 WHERE Col_B = 'b' AND Col_A = 'a';
-- Query #4
SELECT * FROM T1 WHERE Col_A = 'a' AND Col_C = 'c';
Desempenho do carregamento de dados
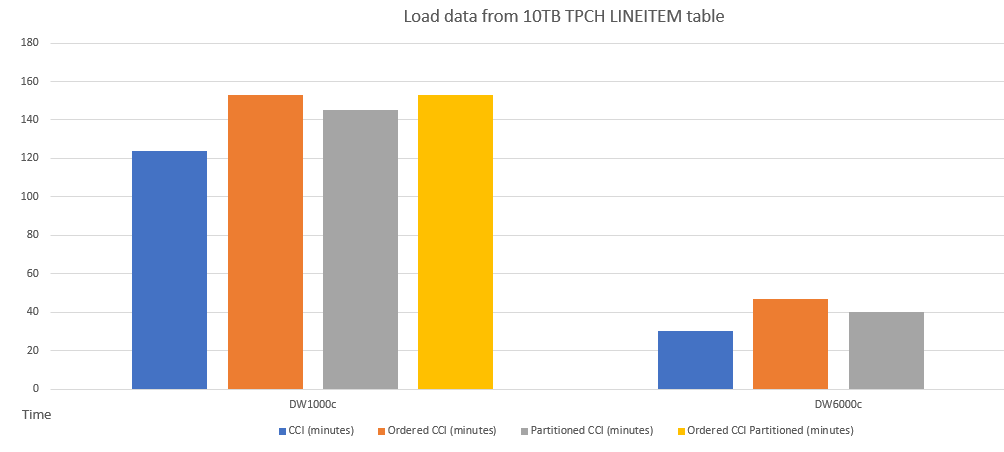
O desempenho do carregamento de dados em uma tabela de CCI ordenado é semelhante ao de uma tabela particionada. Carregar dados em uma tabela de CCI ordenado pode levar mais tempo do que em uma tabela de CCI não ordenado devido à operação de classificação de dados, no entanto, as consultas podem ser executadas posteriormente de maneira mais rápida com o CCI ordenado.
Aqui está um exemplo de comparação de desempenho do carregamento de dados em tabelas com esquemas diferentes.
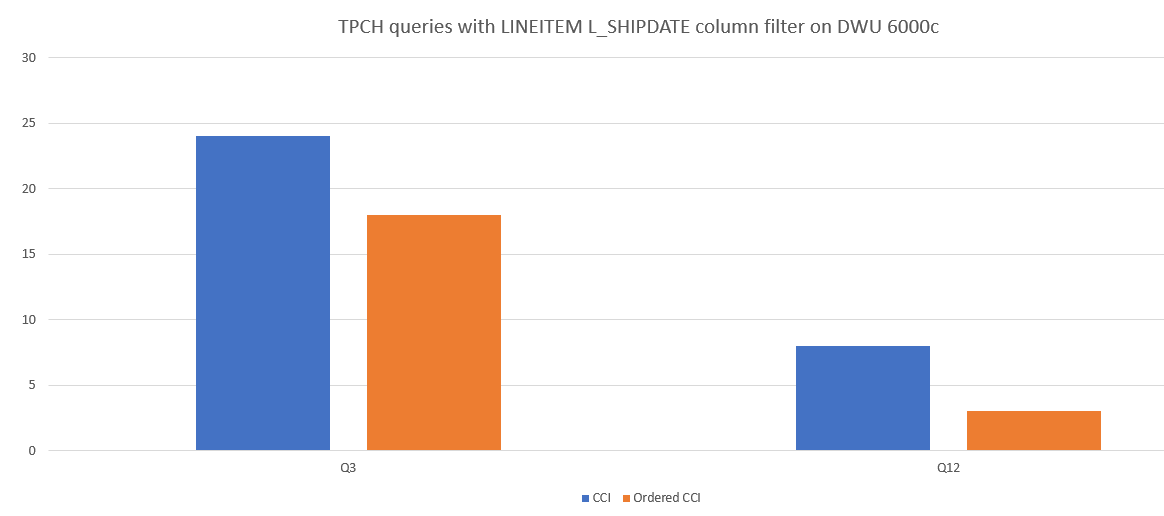
Aqui está um exemplo de comparação de desempenho de consulta entre CCI e CCI ordenado.
Reduzir a sobreposição de segmentos
O número de segmentos sobrepostos depende do tamanho dos dados a serem classificados, da memória disponível e da configuração de MAXDOP (grau máximo de paralelismo) durante a criação do CCI ordenado. As estratégias a seguir reduzem a sobreposição de segmento ao criar o CCI ordenado.
Use a classe de recurso
xlargercem uma DWU superior para permitir mais memória para a classificação de dados antes do construtor de índice compactá-los em segmentos. Depois que são colocados em um segmento de índice, os dados não podem ter seu local físico alterado. Não há classificação de dados em um segmento ou entre segmentos.Crie um CCI ordenado com
OPTION (MAXDOP = 1). Cada thread usado para a criação do CCI ordenado funciona em um subconjunto de dados e o classifica localmente. Não há classificação global entre os dados classificados por threads diferentes. O uso de threads paralelos pode reduzir o tempo de criação de um CCI ordenado, mas irá gerar mais segmentos sobrepostos do que ao usar um único thread. O uso de uma única operação threaded oferece a maior qualidade de compactação. Por exemplo:
CREATE TABLE Table1 WITH (DISTRIBUTION = HASH(c1), CLUSTERED COLUMNSTORE INDEX ORDER(c1) )
AS SELECT * FROM ExampleTable
OPTION (MAXDOP 1);
Observação
Atualmente, em pools de SQL dedicados no Azure Synapse Analytics, a opção MAXDOP só tem suporte na criação de uma tabela CCI ordenada usando o comando CREATE TABLE AS SELECT. A criação de um CCI ordenado por meio de comandos CREATE INDEX ou CREATE TABLE não oferece suporte à opção MAXDOP. Essa limitação não se aplica ao SQL Server 2022 e versões posteriores, em que você pode especificar MAXDOP com os comandos CREATE INDEX ou CREATE TABLE.
- Classifique previamente os dados pelas chaves de classificação antes de carregá-los em tabelas.
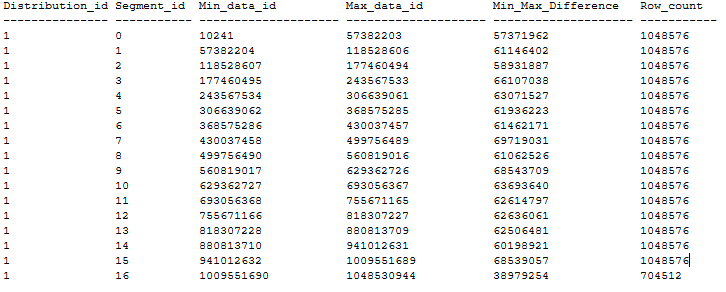
Aqui está um exemplo de uma distribuição de tabela CCI ordenada sem sobreposição de segmentos, seguindo as recomendações acima. A tabela de CCI ordenado é criada em um banco de dados DWU1000c por meio do CTAS de uma tabela de heap de 20 GB usando MAXDOP 1 e xlargerc. O CCI é ordenado em uma coluna BIGINT sem duplicatas.
Criar um CCI ordenado em tabelas grandes
A criação de um CCI ordenado é uma operação offline. Para tabelas sem partições, os dados não poderão ser acessados pelos usuários até que o processo de criação do CCI ordenado seja concluído. Para tabelas particionadas, como o mecanismo cria o CCI ordenado por partição, os usuários ainda podem acessar dados nas partições onde a criação de CCI ordenado não está em andamento. Você pode usar essa opção para minimizar o tempo de inatividade durante a criação de um CCI ordenado em tabelas grandes:
- Crie partições na tabela grande de destino (chamada
Table_A). - Crie uma tabela vazia de CCI ordenado (chamada
Table_B) com o mesmo esquema de tabela e partição daTable_A. - Alterne uma partição da
Table_Apara aTable_B. - Execute
ALTER INDEX <Ordered_CCI_Index> ON <Table_B> REBUILD PARTITION = <Partition_ID>para recompilar a partição comutada naTable_B. - Repita as etapas 3 e 4 para cada partição na
Table_A. - Depois que todas as partições forem alteradas da
Table_Apara aTable_Be recompiladas, descarteTable_Ae renomeieTable_BcomoTable_A.
Dica
Em uma tabela de pool de SQL dedicada com um CCI ordenado, ALTER INDEX REBUILD reclassificará os dados usando tempdb. Monitore o tempdb durante operações de recompilação. Se você precisar de mais espaço de tempdb, escale verticalmente o pool. Reduza novamente ao estado anterior assim que a reconstrução do índice for concluída.
Em uma tabela de pool de SQL dedicada com um CCI ordenado, ALTER INDEX REORGANIZE não reclassificará os dados. Para reclassificar os dados, use ALTER INDEX REBUILD.
Para saber mais sobre a manutenção de CCI ordenada, confira Otimizando índices columnstore clusterizados.
Diferenças de funcionalidade nos recursos do SQL Server 2022
O SQL Server 2022 (16.x) apresentou índices columnstore clusterizados e ordenados semelhantes à funcionalidade dos pools de SQL dedicados do Azure Synapse.
- Atualmente, apenas o SQL Server 2022 (16.x) e versões posteriores dão suporte a recursos de eliminação de segmento aprimorados de armazenamento de colunas em cluster para tipos de dados de cadeia de caracteres, binários e guid e o tipo de dados datetimeoffset para escala maior que dois. Anteriormente, essa eliminação de segmento se aplicava aos tipos de dados numéricos, de data e hora e ao tipo de dados datetimeoffset com escala menor ou igual a dois.
- Atualmente, apenas o SQL Server 2022 (16.x) e versões posteriores dão suporte à eliminação de grupos de linhas de armazenamento de colunas em cluster para o prefixo de
LIKEpredicados, por exemplocolumn LIKE 'string%'. A eliminação de segmento não é compatível com o uso sem prefixo de LIKE, comocolumn LIKE '%string'.
Para obter mais informações, confira Novidades nos Índices Columnstore.
Exemplos
a. Para verificar se há colunas ordenadas e verificar o ordinal de ordem:
SELECT object_name(c.object_id) table_name, c.name column_name, i.column_store_order_ordinal
FROM sys.index_columns i
JOIN sys.columns c ON i.object_id = c.object_id AND c.column_id = i.column_id
WHERE column_store_order_ordinal <>0;
B. Para alterar o ordinal de coluna, adicione ou remova colunas da lista de ordenação ou altere do CCI para o CCI ordenado:
CREATE CLUSTERED COLUMNSTORE INDEX InternetSales ON dbo.InternetSales
ORDER (ProductKey, SalesAmount)
WITH (DROP_EXISTING = ON);
Próximas etapas
- Para obter mais dicas de desenvolvimento, confira visão geral de desenvolvimento.
- Índices de columnstore: Visão geral
- O que há de novo nos índices de columnstore
- Índices columnstore – diretrizes de design
- Índices columnstore – desempenho de consultas