Visão geral da ingestão de dados do Azure Synapse Data Explorer (versão prévia)
A ingestão de dados é o processo usado para carregar os registros de dados de uma ou mais fontes a fim de importar esses dados para uma tabela no pool do Azure Synapse Data Explorer. Depois de ingeridos, os dados ficam disponíveis para consulta.
O serviço de gerenciamento de dados do Azure Synapse Data Explorer, que é responsável pela ingestão de dados, implementa o seguinte processo:
- Efetua pull de dados em lotes ou streaming de uma fonte externa e lê solicitações de uma fila pendente do Azure.
- O fluxo de dados em lote para o mesmo banco de dados e tabela é otimizado para a taxa de transferência de ingestão.
- Os dados iniciais são validados e o formato é convertido quando necessário.
- Outras formas de manipulação de dados inclui realizar a correspondência de esquema, organização, indexação, codificação e compactação dos dados.
- Os dados são persistidos no armazenamento de acordo com a política de retenção definida.
- O commit dos dados ingeridos é feito no mecanismo, onde eles ficam disponíveis para consulta.
Formatos de dados, propriedades e permissões compatíveis
Propriedades de ingestão : são as propriedades que afetam o modo como os dados serão ingeridos (por exemplo, marcação, mapeamento, tempo de criação etc.).
Permissões: Para ingerir dados, o processo requer permissões de nível de ingestão de banco de dados. Outras ações, como consulta, podem exigir permissões de administrador de banco de dados, de usuário de banco de dados ou de administrador de tabela.
Ingestão em lote vs por streaming
A ingestão em lote faz o envio em lote de dados e é otimizada para alta taxa de transferência de ingestão. Esse método é o tipo de ingestão preferencial e de melhor desempenho. Os dados são enviados em lote de acordo com as propriedades de ingestão. Pequenos lotes de dados são mesclados e otimizados para resultados rápidos de consulta. A política de ingestão em lote pode ser definida em bancos de dados ou tabelas. Por padrão, o valor máximo de envio em lote é de 5 minutos, 1000 itens ou um tamanho total de 1 GB. O limite do tamanho de dados para um comando de ingestão em lote é de 4 GB.
A ingestão de streaming é a ingestão contínua de dados provenientes de uma fonte de streaming. A ingestão de streaming permite latência quase em tempo real para pequenos conjuntos de dados por tabela. Os dados são inicialmente ingeridos no repositório de linha e, em seguida, são movidos para as extensões do repositório de coluna.
Métodos e ferramentas de ingestão
O Azure Synapse Data Explorer é compatível com vários métodos de ingestão, cada qual com cenários de destino próprios. Esses métodos incluem ferramentas de ingestão, conectores e plug-ins para diversos serviços, pipelines gerenciados, ingestão programática usando SDKs e acesso direto à ingestão.
Ingestão usando pipelines gerenciados
Para organizações que desejam ter o gerenciamento (limitação, novas tentativas, monitores, alertas e muito mais) feito por um serviço externo, é provável que o uso de um conector seja a solução mais apropriada. A ingestão na fila é apropriada para grandes volumes de dados. O Azure Synapse Data Explorer é compatível com os seguintes Azure Pipelines:
- Hub de Eventos : um pipeline que transfere eventos de serviços para o Azure Synapse Data Explorer. Para obter mais informações, confira Ingerir dados do Hub de Eventos no Azure Synapse Data Explorer.
- Pipelines do Synapse: um serviço de integração de dados totalmente gerenciado para cargas de trabalho analíticas em pipelines do Synapse se conecta com mais de 90 fontes compatíveis a fim de fornecer transferência de dados eficiente e resiliente. Os pipelines do Synapse preparam, transformam e enriquecem os dados para fornecer insights que podem ser monitorados de maneiras diferentes. Esse serviço pode ser usado como uma solução individual, em uma linha do tempo periódica ou disparado por eventos específicos.
Ingestão programática usando SDKs
O Azure Synapse Data Explorer fornece SDKs que podem ser usados para consulta e ingestão de dados. A ingestão programática é otimizada para redução de custos de ingestão (COGs), minimizando as transações de armazenamento durante e após o processo de ingestão.
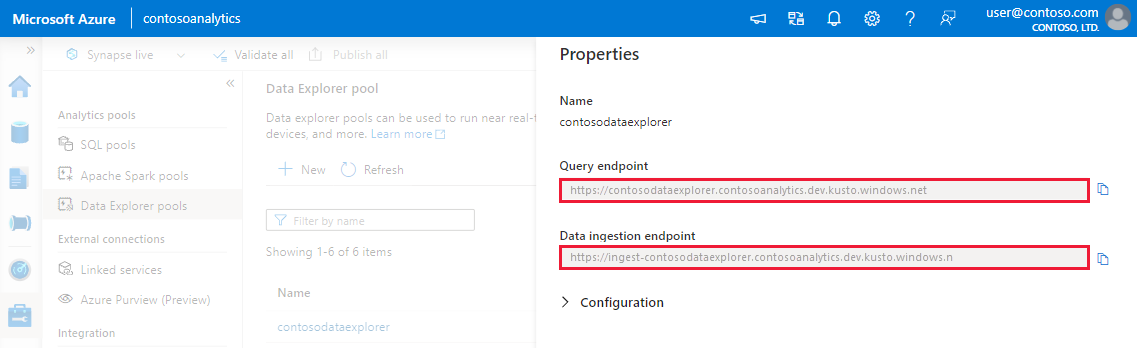
Antes de começar, use as etapas a seguir para obter os pontos de extremidade do pool do Data Explorer para configurar a ingestão programática.
No Synapse Studio, no painel do lado esquerdo, selecione Gerenciar>Pools do Data Explorer.
Selecione o pool do Data Explorer que você deseja usar para exibir os detalhes correspondentes.
Anote os pontos de extremidade de Consulta e Ingestão de Dados. Use o ponto de extremidade de Consulta como o cluster ao configurar conexões com seu pool do Data Explorer. Ao configurar SDKs para ingestão de dados, use o ponto de extremidade de ingestão de dados.
Projetos de software livre e SDKs disponíveis
Ferramentas
- Ingestão com um clique : permite a você ingerir dados rapidamente criando e ajustando tabelas de um amplo intervalo de tipos de origem. A ingestão com um clique sugere automaticamente tabelas e estruturas de mapeamento com base na fonte de dados no Azure Synapse Data Explorer. A ingestão com um clique pode ser usada para ingestão única ou para definir a ingestão contínua por meio da Grade de Eventos no contêiner em que os dados foram ingeridos.
Comandos de controle de ingestão da Linguagem de Consulta do Azure Data Explorer
Há vários métodos pelos quais os dados podem ser ingeridos diretamente para o mecanismo por meio de comandos da KQL (Linguagem de Consulta do Azure Data Explorer). Como esse método ignora os serviços de Gerenciamento de Dados, ele é apropriado apenas para exploração e prototipagem. Não use esse método em cenários de produção ou de alto volume.
Ingestão embutida: um comando de controle .ingest inline é enviado para o mecanismo, com os dados a serem ingeridos como parte do texto do próprio comando. Esse método se destina a fins de teste improvisado.
Ingestão de consulta: Um comando de controle .set, .append, .set-or-append ou .set-or-replace é enviado ao mecanismo, com os dados especificados indiretamente como os resultados de uma consulta ou de um comando.
Ingestão de armazenamento (pull) : Um comando de controle .ingest into é enviado ao mecanismo, com os dados armazenados em algum armazenamento externo (por exemplo, o Armazenamento de Blobs do Azure) acessível ao mecanismo e apontado pelo comando.
Para obter um exemplo de como usar comandos de controle de ingestão, confira Analisar com o Data Explorer.
Processo de ingestão
Depois de escolher o método de ingestão mais adequado para suas necessidades, execute as seguintes etapas:
Definir política de retenção
Os dados ingeridos em uma tabela no Azure Synapse Data Explorer estão sujeitos à política de retenção efetiva da tabela. A menos que seja definida explicitamente em uma tabela, a política de retenção efetiva é derivada da política de retenção do banco de dados. A retenção frequente é uma função do tamanho do cluster e da política de retenção. A ingestão de mais dados do que o espaço disponível forçará os primeiro dos dados ingressados à retenção a frio.
Verifique se a política de retenção do banco de dados é apropriada para as suas necessidades. Caso contrário, substitua-a explicitamente no nível de tabela. Para obter mais informações, confira a política de retenção.
Criar uma tabela
Para ingerir dados, uma tabela precisa ser criada com antecedência. Use uma das seguintes opções:
Criar uma com um comando. Para obter um exemplo de como usar o comando criar uma tabela, confira Analisar com o Data Explorer.
Crie uma tabela usando a Ingestão com um clique.
Observação
Se um registro estiver incompleto ou um campo não puder ser analisado como o tipo de dados necessário, as colunas da tabela correspondentes serão preenchidas com valores nulos.
Criar mapeamento de esquema
O mapeamento de esquema ajuda a associar os campos de dados de origem às colunas da tabela de destino. O mapeamento permite que você pegue dados de diferentes fontes na mesma tabela, com base nos atributos definidos. Diferentes tipos de mapeamentos são compatíveis, orientado a linhas (CSV, JSON e AVRO) e orientado a colunas (Parquet). Na maioria dos métodos, os mapeamentos também podem ser previamente criados na tabela e referenciados no parâmetro do comando de ingestão.
Definir política de atualização (opcional)
Alguns mapeamentos do formato de dados (Parquet, JSON e Avro) são compatíveis com as transformações simples e úteis de tempo de ingestão. Quando o cenário requer processamento mais complexo no momento da ingestão, use a política de atualização, que permite um processamento mais leve usando comandos da Linguagem de Consulta do Azure Data Explorer. A política de atualização executa automaticamente extratos e transformações em dados ingeridos na tabela original e ingere os dados resultantes em uma ou mais tabelas de destino. Defina a política de atualização.