Início Rápido: Ingerir dados usando o Azure Synapse Pipelines (versão prévia)
Neste início rápido, você aprenderá a carregar dados de uma fonte de dados no pool do Azure Synapse Data Explorer.
Pré-requisitos
Uma assinatura do Azure. Criar uma conta gratuita do Azure.
Criar um pool do Data Explorer usando o Synapse Studio ou o portal do Azure
Criar um banco de dados do Data Explorer.
No Synapse Studio, no painel esquerdo, selecione Dados.
Selecione + (Adicionar novo recurso) >Pool do Data Explorer e use as seguintes informações:
Configuração Valor sugerido Descrição Nome do pool contosodataexplorer O nome do pool do Data Explorer a ser usado Nome TestDatabase O nome do banco de dados deve ser exclusivo dentro do cluster. Período de retenção padrão 365 O período de tempo (em dias) durante o qual há a garantia de que os dados serão mantidos disponíveis para consulta. O período é medido a partir do momento em que os dados são incluídos. Período de cache padrão 31 O período de tempo (em dias) durante o qual os dados consultados com frequência devem ser mantidos disponíveis no armazenamento SSD ou RAM, em vez de no armazenamento de longo prazo. Selecione Criar para criar o banco de dados. A criação geralmente leva menos de um minuto.
Criar uma tabela
- No Synapse Studio, no painel do lado esquerdo, selecione Desenvolver.
- Em Scripts KQL, selecione + (Adicionar novo recurso) >Script KQL. No painel do lado direito, você pode nomear o script.
- No menu Conexão, selecione contosodataexplorer.
- No menu Usar banco de dados, selecione TestDatabase.
- Cole o comando a seguir e selecione Executar para criar uma tabela.
.create table StormEvents (StartTime: datetime, EndTime: datetime, EpisodeId: int, EventId: int, State: string, EventType: string, InjuriesDirect: int, InjuriesIndirect: int, DeathsDirect: int, DeathsIndirect: int, DamageProperty: int, DamageCrops: int, Source: string, BeginLocation: string, EndLocation: string, BeginLat: real, BeginLon: real, EndLat: real, EndLon: real, EpisodeNarrative: string, EventNarrative: string, StormSummary: dynamic)Dica
Verifique se a tabela foi criada com êxito. No painel esquerdo, selecione Dados, selecione o menu contosodataexplorer e, em seguida, selecione Atualizar. Em contosodataexplorer, expanda Tabelas e verifique se a tabela StormEvents é exibida na lista.
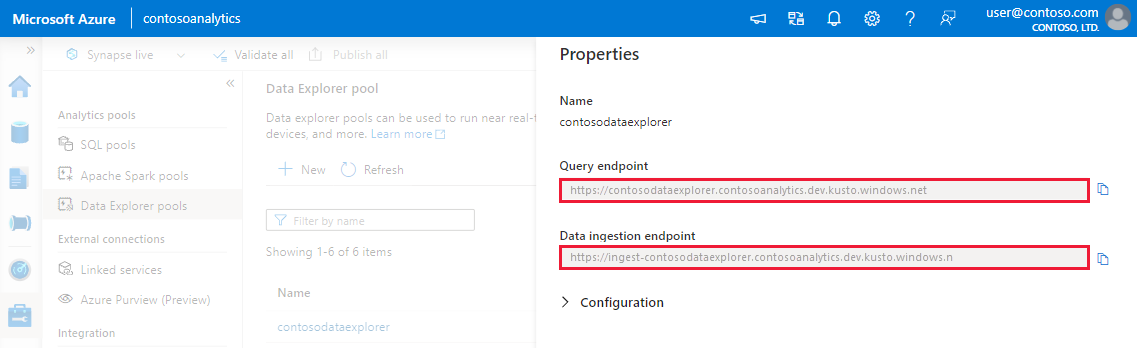
Obtenha os pontos de extremidade de Consulta e Ingestão de Dados. Você precisará do ponto de extremidade de consulta para configurar o serviço vinculado.
No Synapse Studio, no painel do lado esquerdo, selecione Gerenciar>Pools do Data Explorer.
Selecione o pool do Data Explorer que você deseja usar para exibir os detalhes correspondentes.
Anote os pontos de extremidade de Consulta e Ingestão de Dados. Use o ponto de extremidade de Consulta como o cluster ao configurar conexões com seu pool do Data Explorer. Ao configurar SDKs para ingestão de dados, use o ponto de extremidade de ingestão de dados.
Criar um serviço vinculado
No Azure Synapse Analytics, um serviço vinculado é onde você define as informações de conexão com outros serviços. Nesta seção, você criará um serviço vinculado para Azure Data Explorer.
No Synapse Studio, no painel do lado esquerdo, selecione Gerenciar>Serviços vinculados.
Selecione + Novo.

Selecione o serviço Azure Data Explorer na galeria e, em seguida, selecione Continuar.

Na página Novos Serviços Vinculados, use as seguintes informações:
Configuração Valor sugerido Description Nome contosodataexplorerlinkedservice O nome do novo serviço vinculado do Azure Data Explorer. Método de autenticação Identidade gerenciada O método de autenticação para o novo serviço. Método de seleção de conta Inserir manualmente O método para especificar o ponto de extremidade de consulta. Ponto de extremidade https://contosodataexplorer.contosoanalytics.dev.kusto.windows.net O ponto de extremidade consulta que você anotou anteriormente. Banco de dados TestDatabase O banco de dados em que você deseja ingerir dados. 
Selecione Testar conectividade para validar as configurações e escolha Criar.
Criar um pipeline para ingerir dados
Um pipeline contém o fluxo lógico para uma execução de um conjunto de atividades. Nesta seção, você criará um pipeline que contém uma atividade de cópia que ingere dados de sua fonte preferencial em um pool do Data Explorer.
No Synapse Studio, no painel do lado esquerdo, selecione Integrar.
Selecione +>Pipeline. No painel do lado direito, você pode nomear o pipeline.

Em Atividades>Mover e Transformar, arraste Copiar dados na tela do pipeline.
Selecione a atividade de cópia e acesse a guia Origem. Selecione ou crie um conjunto de dados de origem como a origem da qual copiar dados.
Vá para a guia Coletor. Selecione em Novo para criar um novo conjunto de dados do coletor.

Selecione o conjunto de dados Azure Data Explorer na galeria e, em seguida, selecione Continuar.
No painel Definir propriedades, use as informações a seguir e selecione OK.
Configuração Valor sugerido Description Nome AzureDataExplorerTable O nome do novo pipeline. Serviço vinculado contosodataexplorerlinkedservice O serviço vinculado que você criou anteriormente. Tabela StormEvents A tabela que você criou anteriormente. 
Para validar o pipeline, selecione Validar na barra de ferramentas. Você verá o resultado da saída de validação do Pipeline no lado direito da página.
Depurar e publicar o pipeline
Depois de concluir a configuração do pipeline, você poderá efetuar uma execução de depuração antes de publicar seus artefatos para verificar se tudo está correto.
Na barra de ferramentas, selecione Depurar. Você verá o status da execução do pipeline na guia Saída na parte inferior da janela.
Depois que o pipeline for executado com sucesso, na barra de ferramentas superior, selecione Publicar tudo. Esta ação publica as entidades (conjuntos de dados e pipelines) criadas por você anteriormente no serviço do Synapse Analytics.
Aguarde até que você veja a mensagem Publicado com êxito. Para ver as mensagens de notificação, selecione o botão de sino no canto superior direito.
Acionar e monitorar o pipeline
Nesta seção, você dispara manualmente o pipeline publicado na etapa anterior.
Selecione Adicionar gatilho na barra de ferramentas e selecione Disparar Agora. Na página Execução de pipeline, selecione OK.
Vá para a guia Monitorar localizada na barra lateral esquerda. Você verá uma execução do pipeline que é disparada por um gatilho manual.
Quando a execução do pipeline for concluída com êxito, selecione o link na coluna Nome do pipeline para exibir os detalhes da execução da atividade ou para executar novamente o pipeline. Neste exemplo, há apenas uma atividade, então você vê apenas uma entrada na lista.
Para obter detalhes sobre a operação de cópia, selecione o link Detalhes (ícone de óculos) na coluna Nome de atividade. Você pode monitorar detalhes como o volume de dados copiados da fonte para o coletor, taxa de transferência de dados, etapas de execução com duração correspondente e configurações usadas.
Para voltar à exibição de execuções de pipeline, selecione o link Todos os pipelines são executados na parte superior. Selecione Atualizar para atualizar a lista.
Verifique se os dados estão gravados corretamente no pool do Data Explorer.