Tutorial: Inteligência de documentos com serviços de IA do Azure
IA do Azure para Informação de Documentos é um Serviço de IA do Azure que permite criar um software de processamento de documento automatizado usando a tecnologia de aprendizado de máquina. Neste tutorial, você aprenderá a enriquecer facilmente seus dados no Azure Synapse Analytics. Você usará a Inteligência de documentos para analisar formulários e documentos, extrair texto e dados e retornar uma saída em JSON estruturada. Você obtém resultados com rapidez e precisão, adaptados ao seu conteúdo específico, sem intervenção manual excessiva nem ampla experiência em ciência de dados.
Este tutorial demonstra como usar a Inteligência de Documentos com o SynapseML para:
- Extrair de texto e layout de um determinado documento
- Detectar e extrair dados de destinatários
- Detectar e extrair dados de cartões de visita
- Detectar e extrair dados de faturas
- Detectar e extrair dados de documentos de identificação
Se você não tiver uma assinatura do Azure, crie uma conta gratuita antes de começar.
Pré-requisitos
- Workspace do Azure Synapse Analytics com uma conta de armazenamento do Azure Data Lake Storage Gen2 configurada como o armazenamento padrão. Você precisa ser Colaborador de Dados do Storage Blob do sistema de arquivos Data Lake Storage Gen2 com o qual você trabalha.
- Pool do Spark no workspace do Azure Synapse Analytics. Para obter detalhes, confira Criar um Pool do Spark no Azure Synapse.
- Etapas de pré-configuração descritas no tutorial Como configurar os serviços de IA do Azure no Azure Synapse.
Introdução
Abra o Synapse Studio e crie um notebook. Para começar, importe o SynapseML.
import synapse.ml
from synapse.ml.cognitive import *
Configurar o serviço de informações do documento
Use a Informação de documentos que você configurou nas etapas de pré-configuração .
ai_service_name = "<Your linked service for Document Intelligence>"
Analisar Layout
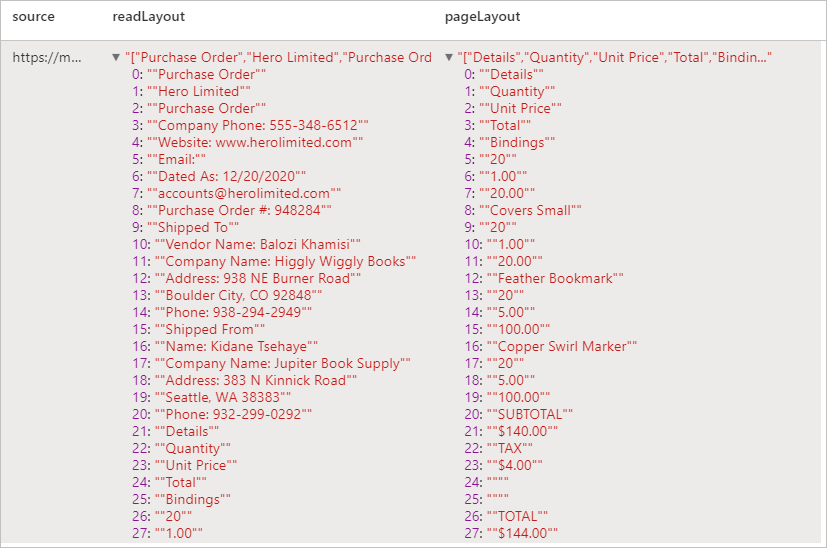
Extrair informações de texto e layout de um determinado documento. O documento de entrada deve ser de um dos tipos de conteúdo com suporte – 'application/pdf', 'image/jpeg', 'image/png' ou 'image/tiff'.
Exemplo de entrada

from pyspark.sql.functions import col, flatten, regexp_replace, explode, create_map, lit
imageDf = spark.createDataFrame([
("<replace with your file path>/layout.jpg",)
], ["source",])
analyzeLayout = (AnalyzeLayout()
.setLinkedService(ai_service_name)
.setImageUrlCol("source")
.setOutputCol("layout")
.setConcurrency(5))
display(analyzeLayout
.transform(imageDf)
.withColumn("lines", flatten(col("layout.analyzeResult.readResults.lines")))
.withColumn("readLayout", col("lines.text"))
.withColumn("tables", flatten(col("layout.analyzeResult.pageResults.tables")))
.withColumn("cells", flatten(col("tables.cells")))
.withColumn("pageLayout", col("cells.text"))
.select("source", "readLayout", "pageLayout"))
Resultados esperados
Analisar Recibos
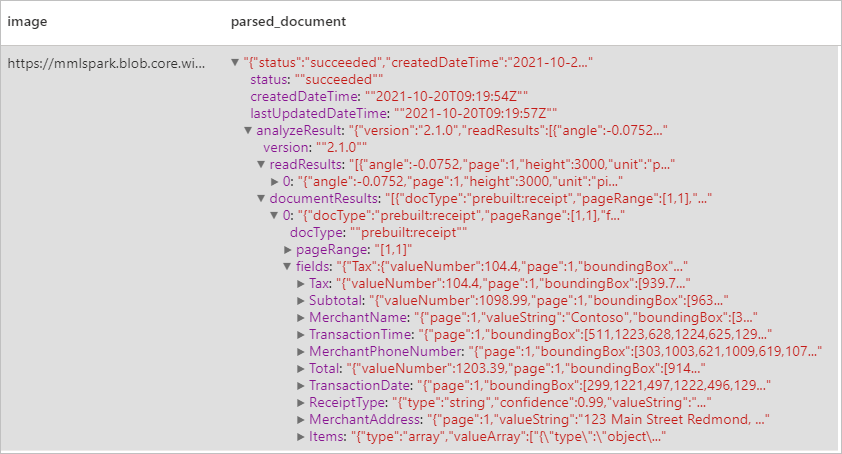
Detecta e extrai dados de recibos usando OCR (reconhecimento óptico de caracteres) e nosso modelo de recibo, permitindo que você extraia facilmente dados estruturados de recibos, como nome do comerciante, número de telefone do comerciante, data da transação, total da transação e muito mais.
Exemplo de entrada

imageDf2 = spark.createDataFrame([
("<replace with your file path>/receipt1.png",)
], ["image",])
analyzeReceipts = (AnalyzeReceipts()
.setLinkedService(ai_service_name)
.setImageUrlCol("image")
.setOutputCol("parsed_document")
.setConcurrency(5))
results = analyzeReceipts.transform(imageDf2).cache()
display(results.select("image", "parsed_document"))
Resultados esperados
Analisar cartões de visita
Detecta e extrai dados de cartões de visita usando OCR (reconhecimento óptico de caracteres) e nosso modelo de cartão de visita, permitindo que você extraia facilmente dados estruturados de cartões de visita, como nomes de contato, nomes de empresa, números de telefone, emails e muito mais.
Exemplo de entrada

imageDf3 = spark.createDataFrame([
("<replace with your file path>/business_card.jpg",)
], ["source",])
analyzeBusinessCards = (AnalyzeBusinessCards()
.setLinkedService(ai_service_name)
.setImageUrlCol("source")
.setOutputCol("businessCards")
.setConcurrency(5))
display(analyzeBusinessCards
.transform(imageDf3)
.withColumn("documents", explode(col("businessCards.analyzeResult.documentResults.fields")))
.select("source", "documents"))
Resultados esperados

Analisar faturas
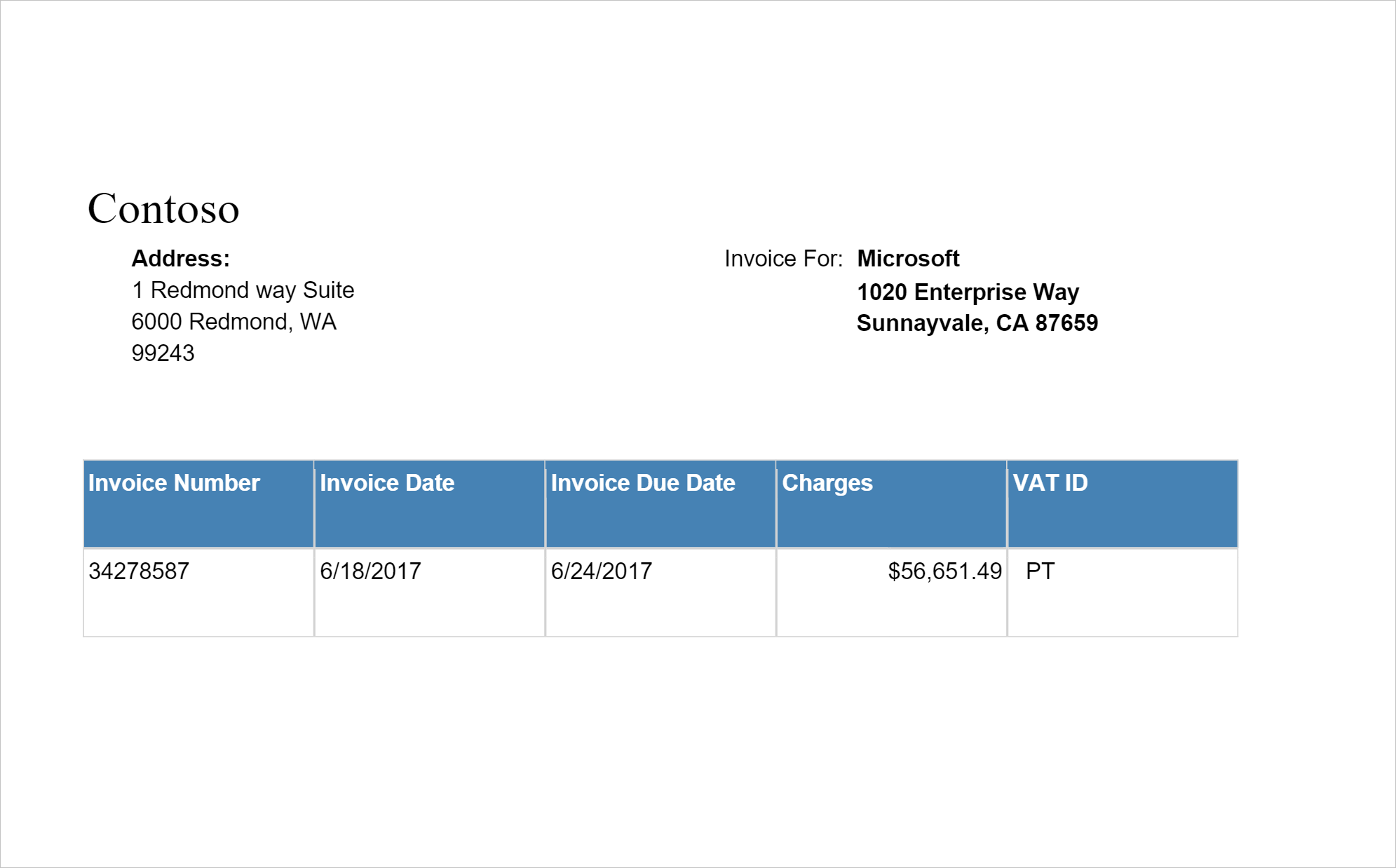
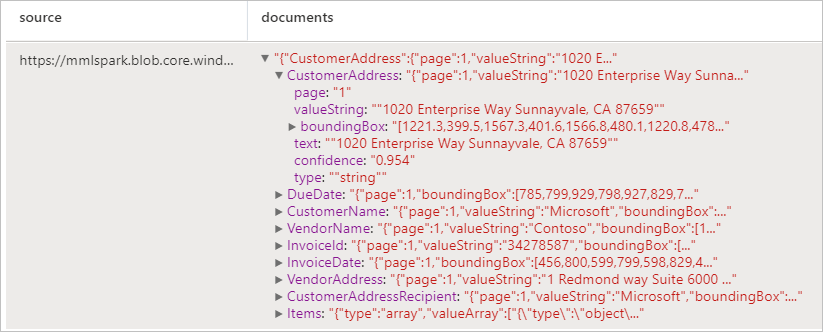
Detecta e extrai dados de faturas usando OCR (reconhecimento óptico de caracteres) e nossos modelos de aprendizado profundo com reconhecimento de faturas, permitindo que você extraia facilmente dados estruturados de faturas, como cliente, fornecedor, ID da fatura, data de vencimento da fatura, total, valor da fatura devido, valor do imposto, enviar para, faturar para, itens de linha e muito mais.
Exemplo de entrada
imageDf4 = spark.createDataFrame([
("<replace with your file path>/invoice.png",)
], ["source",])
analyzeInvoices = (AnalyzeInvoices()
.setLinkedService(ai_service_name)
.setImageUrlCol("source")
.setOutputCol("invoices")
.setConcurrency(5))
display(analyzeInvoices
.transform(imageDf4)
.withColumn("documents", explode(col("invoices.analyzeResult.documentResults.fields")))
.select("source", "documents"))
Resultados esperados
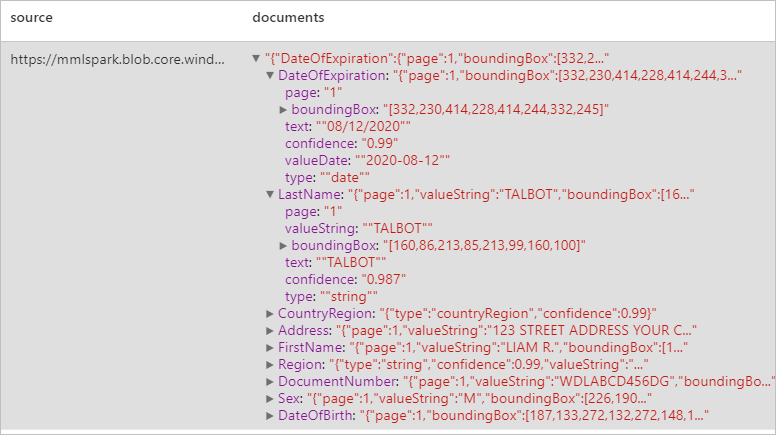
Analisar documentos de identidade
Detecta e extrai dados de documentos de identificação usando OCR (reconhecimento óptico de caracteres) e nosso modelo de documento de identificação, permitindo que você extraia facilmente dados estruturados de documentos de identificação, como nome, sobrenome, data de nascimento, número do documento e muito mais.
Exemplo de entrada

imageDf5 = spark.createDataFrame([
("<replace with your file path>/id.jpg",)
], ["source",])
analyzeIDDocuments = (AnalyzeIDDocuments()
.setLinkedService(ai_service_name)
.setImageUrlCol("source")
.setOutputCol("ids")
.setConcurrency(5))
display(analyzeIDDocuments
.transform(imageDf5)
.withColumn("documents", explode(col("ids.analyzeResult.documentResults.fields")))
.select("source", "documents"))
Resultados esperados
Limpar os recursos
Para garantir que a instância do Spark seja desligada, encerre todas as sessões conectadas (notebooks). O pool é desligado quando o tempo ocioso especificado no Pool do Apache Spark é atingido. Você também pode selecionar encerrar sessão na barra de status na parte superior direita do notebook.

Próximas etapas
Comentários
Em breve: Ao longo de 2024, eliminaremos os problemas do GitHub como o mecanismo de comentários para conteúdo e o substituiremos por um novo sistema de comentários. Para obter mais informações, consulte https://aka.ms/ContentUserFeedback.
Enviar e exibir comentários de