Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Neste início rápido, você aprenderá a criar um Pool do Apache Spark sem servidor no Azure Synapse usando ferramentas da Web. Em seguida, você aprenderá a se conectar ao Pool do Apache Spark e executar consultas SQL do Spark em arquivos e tabelas. O Apache Spark permite análises rápidas de dados e computação de cluster usando processamento na memória. Para obter informações sobre o Spark no Azure Synapse, consulte Visão geral: Apache Spark no Azure Synapse.
Importante
A cobrança das instâncias do Spark será proporcional por minuto, independentemente de elas estarem sendo usadas ou não. Desligue a instância do Spark depois de terminar de usá-la ou defina um tempo limite curto. Para saber mais, confira a seção Recursos de limpeza deste artigo.
Se você não tiver uma assinatura do Azure, crie uma conta gratuita antes de começar.
Pré-requisitos
- É necessário ter uma assinatura do Azure. Se necessário, crie uma conta gratuita do Azure
- Workspace do Synapse Analytics
- Pool do Apache Spark sem servidor
Entre no Portal do Azure
Entre no portal do Azure.
Caso você não tenha uma assinatura do Azure, crie uma conta gratuita do Azure antes de começar.
Criar um notebook
Um notebook é um ambiente interativo que dá suporte a várias linguagens de programação. O notebook permite que você interaja com seus dados, combine código com Markdown e texto e faça visualizações simples.
Na exibição do portal do Azure do workspace do Azure Synapse que deseja usar, selecione Iniciar o Synapse Studio.
Depois que o Synapse Studio for iniciado, selecione Desenvolver. Em seguida, selecione o ícone "+" para adicionar um novo recurso.
Nessa opção, selecione Notebook. Um notebook será criado e aberto com um nome gerado automaticamente.

Na janela Propriedades, forneça um nome para o notebook.
Na barra de ferramentas, clique em Publicar.
Se houver apenas um Pool do Apache Spark no workspace, ele será selecionado por padrão. Use a lista suspensa para selecionar o Pool do Apache Spark correto se nenhum for selecionado.
Clique em Adicionar código. O idioma padrão é
Pyspark. Você usará uma combinação do PySpark e do Spark SQL; portanto, a escolha padrão é boa. Outras linguagens com suporte são o Scala e o .NET para Spark.Em seguida, você criará um objeto simples DataFrame do Spark para processamento. Nesse caso, você o criará com base no código. Há três linhas e três colunas:
new_rows = [('CA',22, 45000),("WA",35,65000) ,("WA",50,85000)] demo_df = spark.createDataFrame(new_rows, ['state', 'age', 'salary']) demo_df.show()Agora, execute a célula usando um dos seguintes métodos:
Pressione SHIFT+ENTER.
Selecione o ícone de reprodução azul à esquerda da célula.
Selecione o botão Executar todos na barra de ferramentas.
Se a instância do Pool do Apache Spark ainda não estiver em execução, ela será iniciada automaticamente. Você poderá ver o status da instância do Pool do Apache Spark abaixo da célula que está sendo executada e também no painel de status na parte inferior do notebook. Dependendo do tamanho do pool, a inicialização deverá levar de 2 a 5 minutos. Quando o código terminar a execução, serão exibidas informações abaixo da célula, mostrando a duração da execução e a execução. Na célula de saída, você verá a saída.
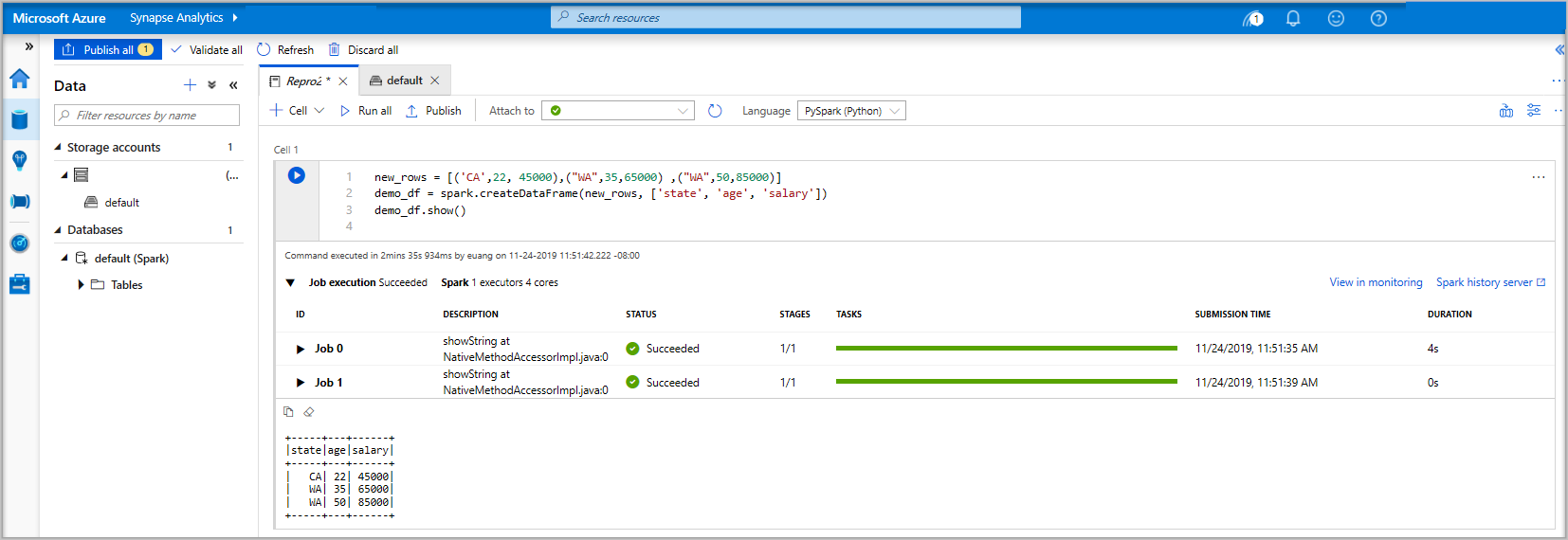
Os dados agora existem em um DataFrame e, nele, você poderá usá-los de várias maneiras diferentes. Você precisará dele em formatos diferentes para o restante deste início rápido.
Insira o código abaixo em outra célula e execute-o; isso criará uma tabela do Spark, um CSV e um arquivo Parquet com as cópias dos dados:
demo_df.createOrReplaceTempView('demo_df') demo_df.write.csv('demo_df', mode='overwrite') demo_df.write.parquet('abfss://<<TheNameOfAStorageAccountFileSystem>>@<<TheNameOfAStorageAccount>>.dfs.core.windows.net/demodata/demo_df', mode='overwrite')Se você usar o gerenciador de armazenamento, poderá ver o impacto das duas maneiras diferentes de gravar um arquivo usadas acima. Quando nenhum sistema de arquivos for especificado, o padrão será usado, nesse caso,
default>user>trusted-service-user>demo_df. Os dados são salvos na localização do sistema de arquivos especificada.Observe que, nos formatos "CSV" e "Parquet", as operações de gravação com a qual um diretório é criado com muitos arquivos particionados.


Executar Instruções Spark SQL
A linguagem SQL (Structured Query Language) é a mais comum e amplamente usada para consultar e definição de dados. O Spark SQL funciona como uma extensão do Apache Spark para processar dados estruturados, usando a sintaxe SQL familiar.
Cole o código a seguir em uma célula vazia e, em seguida, execute o código. O comando lista as tabelas no pool.
%%sql SHOW TABLESAo usar um notebook com o pool do Apache Spark do Azure Synapse, você obtém um
sqlContextpredefinido que pode ser usado para executar consultas usando o Spark SQL. O%%sqlinstrui o notebook a usar osqlContextpredefinido para executar a consulta. A consulta recupera as dez primeiras linhas de uma tabela do sistema fornecida com todos os pools do Apache Spark do Azure Synapse por padrão.Execute outra consulta para ver os dados em
demo_df.%%sql SELECT * FROM demo_dfO código produz duas células de saída: uma que contém os resultados de dados e a outra, que mostra a exibição do trabalho.
Por padrão, a visualização dos resultados mostra uma grade. No entanto, há um seletor de exibição sob a grade que permite alternar entre as exibições de grade e de gráfico.

No seletor Exibir, escolha Gráfico.
Escolha o ícone Exibir opções no lado direito.
No campo Tipo de gráfico, selecione "gráfico de barras".
No campo de coluna do eixo X, selecione "estado".
No campo de coluna do eixo Y, selecione "salário".
No campo Agregação, selecione "AVG".
Selecione Aplicar.

É possível obter a mesma experiência de executar o SQL, mas sem precisar alternar linguagens. Faça isso substituindo a célula SQL acima por esta célula do PySpark; a experiência de saída é a mesma porque o comando display é usado:
display(spark.sql('SELECT * FROM demo_df'))Cada uma das células executadas anteriormente tinha a opção de acesso ao Servidor de Histórico e ao Monitoramento. Ao clicar nos links, você será levado a diferentes partes da experiência do usuário.
Observação
Algumas das documentações oficiais do Apache Spark dependem do uso do console do Spark, que não está disponível no Spark do Azure Synapse. Use as experiências de notebook ou do IntelliJ.
Limpar os recursos
O Azure Synapse salva os dados no Azure Data Lake Storage. Você poderá deixar uma instância do Spark desligada com segurança quando ela não estiver em uso. Você é cobrado por um Pool do Apache Spark sem servidor, desde que ele esteja em execução, mesmo quando não estiver em uso.
Como os preços do pool são muitas vezes mais altos do que os preços do armazenamento, faz sentido, do ponto de vista econômico, deixar as instâncias do Spark desligadas quando não estão em uso.
Para garantir que a instância do Spark seja desligada, encerre todas as sessões conectadas (notebooks). O pool é desligado quando o tempo ocioso especificado no Pool do Apache Spark é atingido. Escolha também Encerrar sessão na barra de status na parte inferior do notebook.
Próximas etapas
Neste guia de início rápido, você aprendeu a criar um Pool do Apache Spark sem servidor e a executar uma consulta SQL básica do Spark.