Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
O Azure Synapse Analytics oferece vários mecanismos de análise para ajudar você a ingerir, transformar, modelar, analisar e distribuir seus dados. Um Pool do Apache Spark fornece funcionalidades de software livre de computação de Big Data. Depois de criar um pool do Apache Spark em seu workspace do Synapse, os dados poderão ser carregados, modelados, processados e distribuídos para obter insights analíticos mais rápidos.
Neste início rápido, você aprenderá a usar o portal do Azure para criar um Pool do Apache Spark em um workspace do Synapse.
Importante
A cobrança das instâncias do Spark será proporcional por minuto, independentemente de elas estarem sendo usadas ou não. Desligue a instância do Spark depois de terminar de usá-la ou defina um tempo limite curto. Para saber mais, confira a seção Recursos de limpeza deste artigo.
Se você não tiver uma assinatura do Azure, crie uma conta gratuita antes de começar.
Pré-requisitos
- É necessário ter uma assinatura do Azure. Se necessário, crie uma conta gratuita do Azure
- Você usará o workspace do Synapse.
Entre no Portal do Azure
Entre no Portal do Azure
Navegue até o workspace do Synapse
Navegue até o workspace do Synapse em que o pool do Apache Spark será criado digitando o nome do serviço (ou o nome do recurso diretamente) na barra de pesquisa.
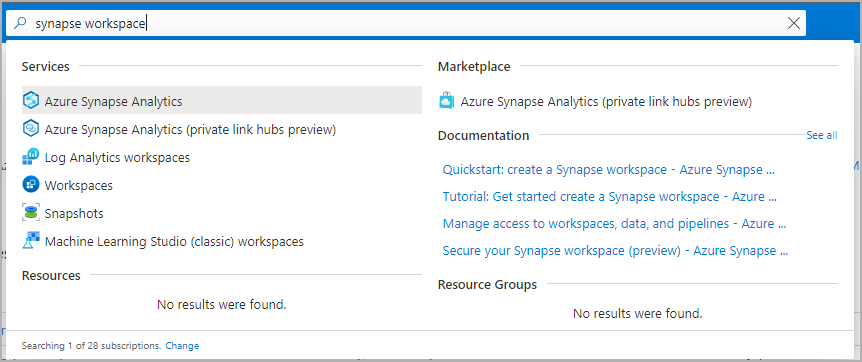
Na lista de espaços de trabalho, digite o nome (ou parte do nome) do espaço de trabalho para abrir. Para este exemplo, usamos um workspace chamado contosoanalytics.
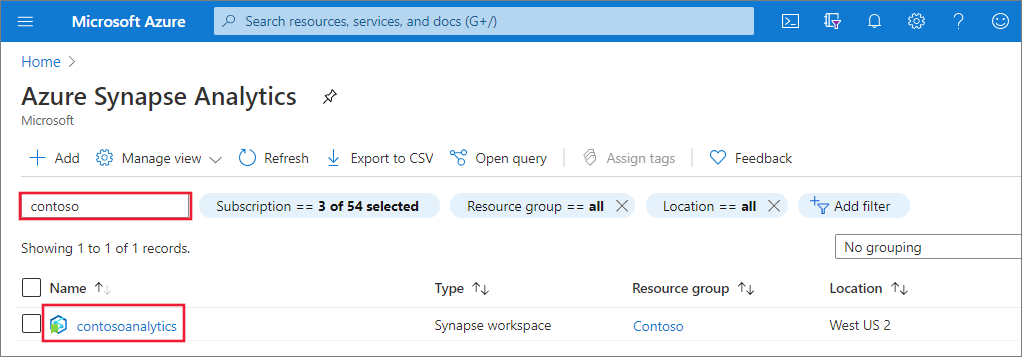


Criar um Pool do Apache Spark
No workspace do Synapse em que deseja criar o Pool do Apache Spark, selecione em Novo Pool do Apache Spark.
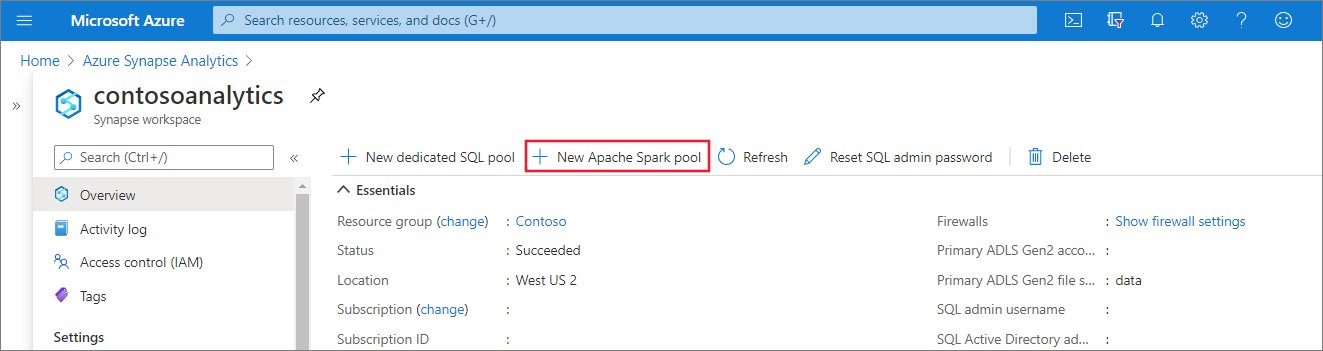
Insira os seguintes detalhes na guia Informações Básicas:
Configurações Valor sugerido Descrição Nome do Pool do Apache Spark Um nome de pool válido, como contososparkEsse é o nome que o Pool do Apache Spark terá. Tamanho do nó Pequeno (4 vCPU/32 GB) Defina isso com o menor tamanho para reduzir os custos deste início rápido Autoescala Desabilitado Não precisamos de dimensionamento automático para este início rápido Número de nós 5 Use um tamanho pequeno para limitar os custos deste início rápido 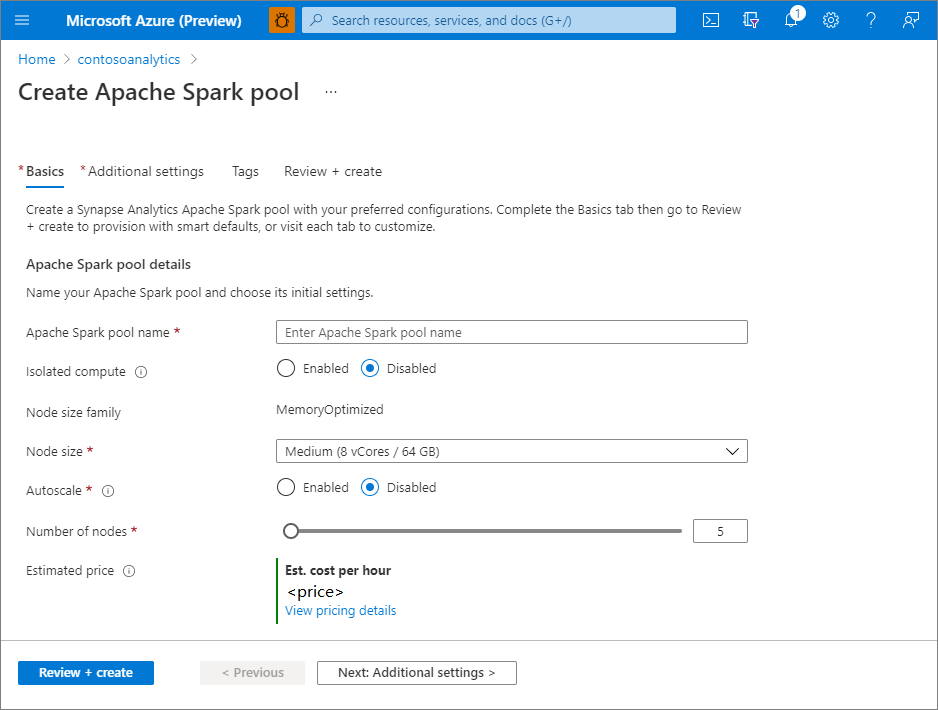
Importante
Há limitações específicas relacionadas aos nomes que os pools do Apache Spark podem usar. Os nomes precisam conter apenas letras ou números, ter 15 caracteres ou menos, começar com uma letra, ser exclusivos no workspace e não devem conter palavras reservadas.
Selecione Avançar: configurações adicionais e examine as configurações padrão. Não modifique nenhuma configuração padrão.
Selecione Avançar: marcas. Considere usar rótulos do Azure. Por exemplo, use o rótulo "Proprietário" ou "CreatedBy" para identificar quem criou o recurso e o rótulo "Ambiente" para indicar se o recurso está em Produção, Desenvolvimento etc. Para mais informações, confira Desenvolver sua estratégia de nomenclatura e marcação para recursos do Azure.
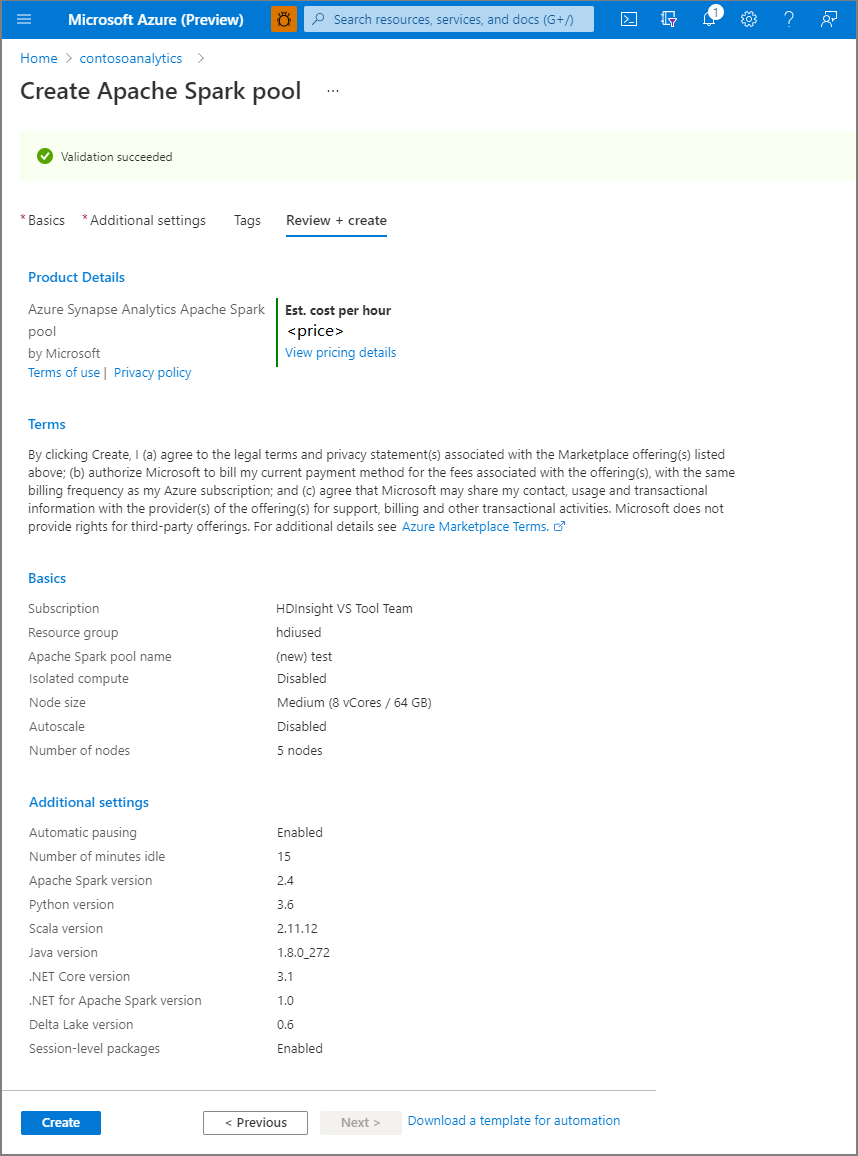
Selecione Examinar + criar.
Verifique se os detalhes estão corretos com base no que foi inserido anteriormente e selecione Criar.
Neste ponto, o fluxo de provisionamento de recursos será iniciado, indicando quando estiver concluído.
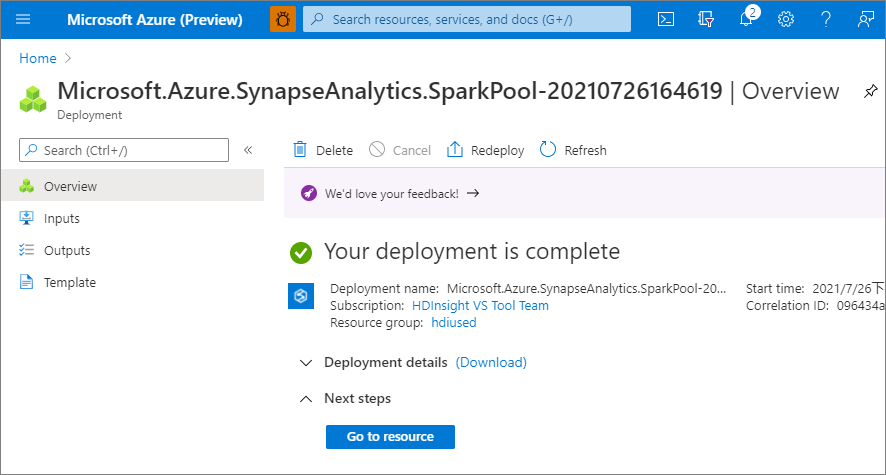
Após a conclusão do provisionamento, se você navegar novamente até o workspace, será mostrada uma nova entrada para o Pool do Apache Spark recém-criado.
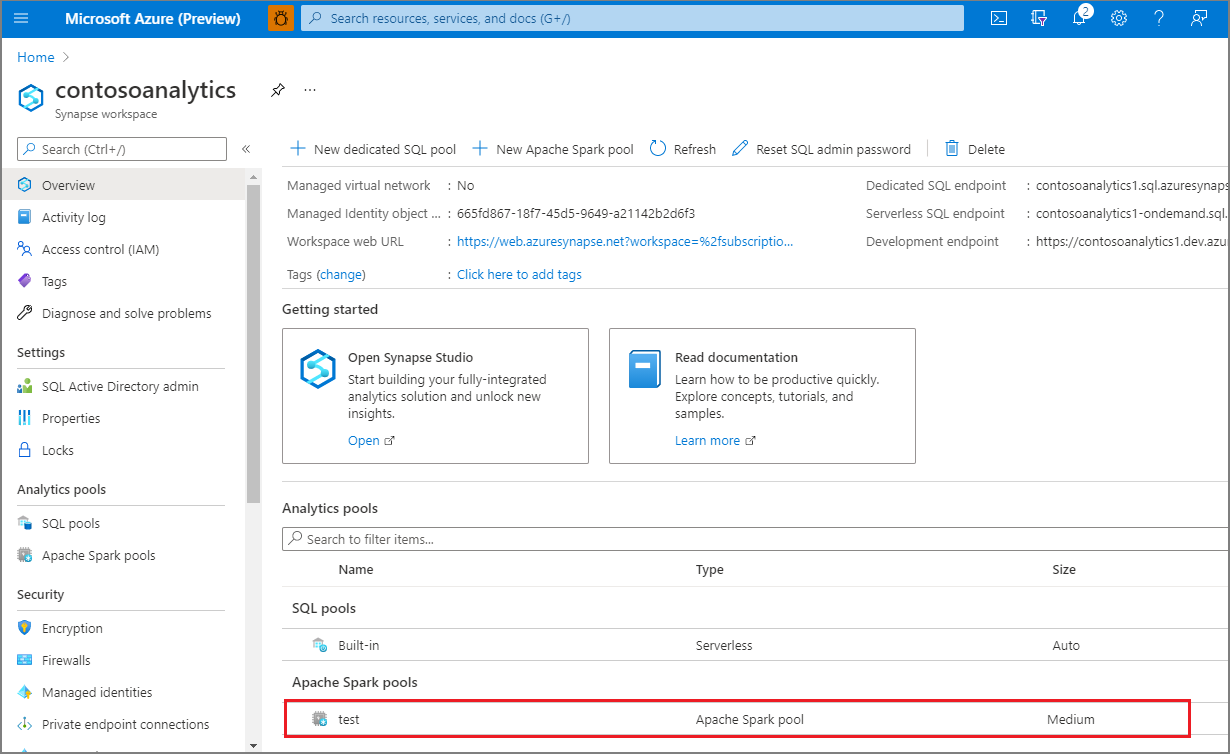
Neste ponto, não há recursos em execução, nenhum custo pelo Spark e você criou metadados sobre as instâncias do Spark que deseja criar.







Limpar os recursos
As etapas a seguir excluem o pool do Apache Spark do workspace.
Aviso
A exclusão de um Pool do Apache Spark removerá o mecanismo de análise do workspace. Não será mais possível se conectar ao pool e todas as consultas, os pipelines e os notebooks que usam esse Pool do Apache Spark deixarão de funcionar.
Se você quiser excluir o pool do Apache Spark, execute as seguintes etapas:
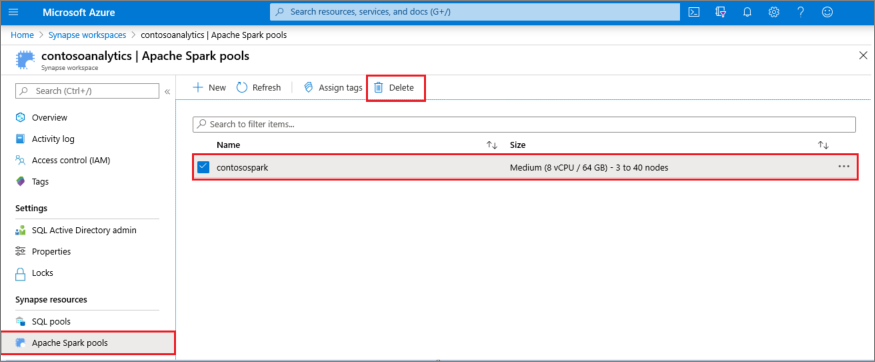
- Navegue até o painel de pools do Apache Spark no workspace.
- Escolha o pool do Apache Spark a ser excluído (neste caso, contosospark).
- Selecione Excluir.
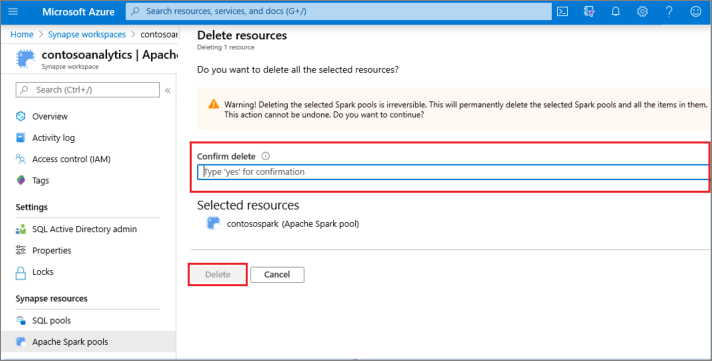
- Confirme a exclusão e selecione o botão Excluir.
- Quando o processo for concluído com êxito, o Pool do Apache Spark não estará mais listado nos recursos do workspace.
