Otimizar trabalhos do Apache Spark no Azure Synapse Analytics
Saiba como otimizar uma configuração de cluster do Apache Spark para sua carga de trabalho específica. O desafio mais comum é a demanda de memória, devido a configurações incorretas (particularmente, executores com o tamanho incorreto), operações de execução longa e tarefas que resultam em operações cartesianas. É possível acelerar os trabalhos com o armazenamento em cache apropriado e permitir distorção de dados. Para obter o melhor desempenho, monitore e revise as execuções de trabalho do Spark de execução longa e consumo de recursos.
As seções a seguir descrevem as recomendações e otimizações de trabalho do Spark comuns.
Escolha a abstração de dados
As versões anteriores do Spark usam RDDs para dados abstratos e o Spark 1.3 e 1.6 introduziram DataFrames e DataSets, respectivamente. Considere os seguintes méritos relativos:
- DataFrames
- Melhor escolha na maioria das situações.
- Fornece otimização de consulta através do Catalyst.
- Geração de código em estágio inteiro.
- Acesso direto à memória.
- Baixa sobrecarga de coleta de lixo (GC).
- Não é tão amigável para desenvolvedores como os Conjuntos de Dados, pois não há verificações de tempo de compilação ou programação de objeto de domínio.
- Conjuntos de Dados
- Bom em pipelines ETL complexos, onde o impacto no desempenho é aceitável.
- Não é bom em agregações onde o impacto no desempenho pode ser considerável.
- Fornece otimização de consulta através do Catalyst.
- Amigável para o desenvolvedor ao fornecer programação de objeto de domínio e verificações de tempo de compilação.
- Adicionar sobrecarga de serialização/desserialização.
- Alta sobrecarga de GC.
- Interrompe a geração de código em estágio inteiro.
- RDDs
- Não é necessário usar RDDs, a menos que você precise criar um RDD personalizado.
- Nenhuma otimização de consulta através do Catalyst.
- Nenhuma geração de código em estágio inteiro.
- Alta sobrecarga de GC.
- Deve usar as API herdadas do Spark 1.x.
Usar o formato de dados ideal
O Spark fornece suporte a muitos formatos, como csv, json, xml, parquet, orc e avro. O Spark pode ser estendido para fornecer suporte a muitos outros formatos com fontes de dados externos - para obter mais informações, consulte Pacotes do Apache Spark.
O melhor formato para desempenho é parquet com compactação snappy, que é o padrão no Spark 2.x. O parquet armazena dados em formato colunar e é altamente otimizado no Spark. Além disso, embora a compactação Snappy possa resultar em arquivos maiores do que, digamos, a compactação Gzip. Devido à natureza divisível desses arquivos, eles serão descompactados mais rapidamente.
Usar o cache
O Spark fornece os próprios mecanismos de cache nativo que podem ser utilizados através de diferentes métodos, como .persist(), .cache() e CACHE TABLE. Esse cache nativo é efetivo com pequenos conjuntos de dados, bem como em pipelines ETL, onde é necessário armazenar em cache resultados intermediários. No entanto, atualmente, o cache nativo do Spark não funciona bem com o particionamento, pois uma tabela armazenada em cache não mantém os dados de particionamento.
Usar a memória de maneira eficiente
O Spark opera colocando dados na memória, de modo que gerenciar recursos de memória é um aspecto chave da otimização da execução de trabalhos do Spark. Há várias técnicas que podem ser aplicadas para usar a memória do cluster de maneira eficiente.
- Preferir partições de dados menores e considerar o tamanho, os tipos e a distribuição de dados na sua estratégia de particionamento.
- Considerar a serialização de dados Kryo, mais recente e eficiente, em vez da serialização Java padrão.
- Monitorar e sintonizar as definições da configuração do Spark.
Para sua referência, a estrutura da memória do Spark e alguns parâmetros da memória do executor chave são mostrados na próxima imagem.
Considerações de memória do Spark
O Apache Spark no Azure Synapse usa o YARN Apache Hadoop YARN; o YARN controla a soma máxima da memória usada por todos os contêineres em cada nó do Spark. O diagrama a seguir mostra os objetos de chave e os respectivos relacionamentos.
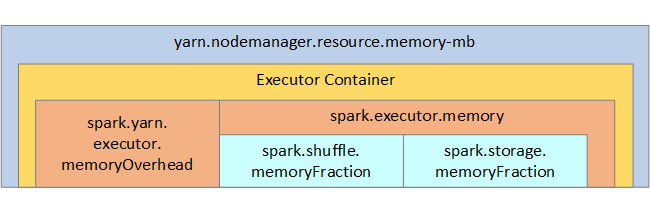
Para endereçar mensagens de "memória insuficiente", tente:
- Revisar as ordens aleatórias de armazenamento do DAG. Reduzir com a redução do lado do mapa, fazer a pré-partição (ou bucket) dos dados de origem, maximizar as ordens aleatórias simples e reduzir a quantidade de dados enviados.
- Preferir
ReduceByKeycom o limite de memória fixa paraGroupByKey, que fornece agregações, janelas e outras funções, mas tem limite de memória ilimitado. - Preferir
TreeReduce, que faz mais trabalho nos executores ou partições, paraReduce, que faz todo o trabalho no driver. - Aproveitar os Conjuntos de Dados em vez dos objetos RDD de nível inferior.
- Criar ComplexTypes que encapsulam ações, como "Top N", várias agregações ou operações de janelas.
Otimizar a serialização de dados
Os trabalhos do Spark são distribuídos, por isso a serialização de dados apropriada é importante para obter o melhor desempenho. Há duas opções de serialização para Spark:
- A serialização Java é o padrão.
- A serialização Kryo é um formato mais recente e pode resultar em serialização mais rápida e compacta do que Java. O Kryo exige que você registre as classes no programa e não dá suporte a todos os tipos serializáveis.
Usar bucketing
O bucketing é semelhante ao particionamento de dados, mas cada bucket pode conter um conjunto de valores de colunas em vez de apenas um. O Bucketing funciona bem para particionamento em números de valores grandes (em milhões ou mais), como identificadores de produto. Um bucket é determinado por hash e chave de bucket da linha. As tabelas em bucket oferecem otimizações exclusivas porque armazenam metadados como foram particionados e classificados.
Alguns recursos de bucket avançados são:
- Otimização de consulta baseada em informações meta de bucket.
- Agregações otimizadas.
- Junções otimizadas.
É possível utilizar particionamento e bucket ao mesmo tempo.
Ordens aleatórias e junções otimizadas
Se houver trabalhos lentos em uma Junção ou Ordem Aleatória, provavelmente a causa será a distorção de dados, que é a assimetria nos dados de trabalho. Por exemplo, um trabalho de mapa pode levar 20 segundos, mas executar um trabalho onde os dados são unidos ou em ordem aleatória leva horas. Para corrigir a distorção de dados, é necessário incluir sal na chave inteira ou usar um sal isolado para apenas um subconjunto de chaves. Se você estiver usando um sal isolado, deverá filtrar adicionalmente para isolar o subconjunto de chaves com sal nas junções de mapa. Outra opção é primeiro introduzir uma coluna de bucket e pré-agregado em buckets.
Outro fator que causa junções lentas pode ser o tipo de junção. Por padrão, o Spark usa o tipo de junção SortMerge. Este tipo de junção é mais adequado para conjuntos de dados grandes, mas, de outra forma, é computacionalmente caro porque primeiro deve classificar os lados esquerdo e direito dos dados antes de mesclá-los.
Uma junção Broadcast é mais adequada para conjuntos de dados menores ou, onde um lado da junção é muito menor do que o outro lado. Esse tipo de junção difunde um lado para todos os executores e, portanto, requer mais memória para difusões em geral.
É possível alterar o tipo de junção na configuração, definindo spark.sql.autoBroadcastJoinThreshold ou você pode definir uma dica de junção usando as APIs do DataFrame (dataframe.join(broadcast(df2))).
// Option 1
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", 1*1024*1024*1024)
// Option 2
val df1 = spark.table("FactTableA")
val df2 = spark.table("dimMP")
df1.join(broadcast(df2), Seq("PK")).
createOrReplaceTempView("V_JOIN")
sql("SELECT col1, col2 FROM V_JOIN")
Se você estiver usando tabelas em bucket, terá um terceiro tipo de junção, a junção Merge. Um conjunto de dados corretamente pré-particionado e pré-classificado ignorará a fase de classificação cara de uma junção SortMerge.
A ordem de questões de junção, particularmente em consultas mais complexas. Inicie com as junções mais seletivas. Além disso, mova junções que aumentam o número de linhas após as agregações, quando possível.
Para gerenciar o paralelismo em junções cartesianas, você pode adicionar estruturas aninhadas, janelas e talvez ignorar uma ou mais etapas do trabalho do Spark.
Selecionar o tamanho correto de executor
Ao decidir a configuração de executor, considere a sobrecarga de coleta de lixo Java (GC).
Fatores para reduzir o tamanho do executor:
- Reduzir o tamanho do heap abaixo de 32 GB para manter a sobrecarga de GC < 10%.
- Reduzir o número de núcleos para manter a sobrecarga de GC < 10%.
Fatores para aumentar o tamanho do executor:
- Reduzir a sobrecarga de comunicação entre os executores.
- Reduzir o número de conexões abertas entre executores (N2) em clusters maiores (> 100 executores).
- Aumentar o tamanho do heap para acomodar tarefas intensivas de memória.
- Opcional: Reduzir a sobrecarga da memória por executor.
- Opcional: Aumentar a utilização e a simultaneidade ao sobrecarregar a CPU.
Como regra geral, ao selecionar o tamanho do executor:
- Inicie com 30 GB por executor e distribua núcleos de computadores disponíveis.
- Aumente o número de núcleos de executor para clusters maiores (> 100 executores).
- Modificar o tamanho com base em execuções de avaliação e nos fatores anteriores, como a sobrecarga do GC.
Ao executar consultas simultâneas, considere o seguinte:
- Inicie com 30 GB por executor e todos os núcleos de computadores.
- Crie várias aplicações do Spark paralelas com subscrição excessiva de CPU (cerca de 30% de melhoria de latência).
- Distribua consultas em aplicativos paralelos.
- Modificar o tamanho com base em execuções de avaliação e nos fatores anteriores, como a sobrecarga do GC.
Monitore o desempenho da consulta para verificar exceções ou outros problemas de desempenho, observando a exibição da linha do tempo, o gráfico SQL, as estatísticas de trabalho e, assim por diante. Às vezes, um ou alguns dos executores são mais lentos que os outros e as tarefas demoram muito mais tempo para serem executadas. Isso geralmente ocorre em clusters maiores (> 30 nós). Nesse caso, divida o trabalho em um número maior de tarefas para que o agendador possa compensar tarefas lentas.
Por exemplo, tenha pelo menos duas vezes mais tarefas que o número de núcleos de executor no aplicativo. Você também pode habilitar a execução especulativa de tarefas com conf: spark.speculation = true.
Otimizar a execução do trabalho
- Armazene em cache conforme necessário, por exemplo, se você utilizar os dados duas vezes, armazene-os em cache.
- Difundir variáveis a todos os executores. As variáveis são serializadas apenas uma vez, resultando em pesquisas mais rápidas.
- Use o pool de threads no driver, o que resulta em operação mais rápida para muitas tarefas.
A chave para desempenho de consultas do Spark 2.x é o mecanismo Tungsten, que depende da geração de código de estágio inteiro. Em alguns casos, a geração de código de estágio inteiro pode ser desabilitada.
Por exemplo, se você utilizar um tipo não mutável (string) na expressão de agregação, SortAggregate aparecerá em vez de HashAggregate. Por exemplo, para um melhor desempenho, tente o seguinte e, em seguida, habilite novamente a geração de código:
MAX(AMOUNT) -> MAX(cast(AMOUNT as DOUBLE))