Pools acelerados por GPU do Apache Spark no Azure Synapse Analytics (versão prévia)
O Apache Spark é uma estrutura de processamento paralelo que dá suporte ao processamento na memória para melhorar o desempenho de aplicativos de análise de Big Data. O Apache Spark no Azure Synapse Analytics é uma das implementações da Microsoft do Apache Spark na nuvem.
Agora, o Azure Synapse oferece a capacidade de criar pools do Azure Synapse habilitados para GPU para executar cargas de trabalho do Spark usando as bibliotecas RAPIDS subjacentes que aproveitam a grande capacidade de processamento paralelo das GPUs para acelerar o processamento. O RAPIDS Accelerator para Apache Spark permite que você execute seus aplicativos Spark existentes sem nenhuma alteração de código apenas habilitando uma definição de configuração, que vem pré-configurada em um pool habilitado para GPU. Você pode optar por ativar/desativar a aceleração de GPU baseada em RAPIDS na carga de trabalho ou em partes dela definindo esta configuração:
spark.conf.set('spark.rapids.sql.enabled','true/false')
Observação
Pools habilitados para GPU do Azure Synapse estão atualmente em Visualização Pública.
Aviso
- A versão prévia acelerada por GPU é limitada ao runtime do Apache Spark 3.2 (fim do suporte anunciado). O fim do suporte anunciado para o runtime do Azure Synapse para Apache Spark 3.2 foi anunciado em 8 de julho de 2023. Os runtimes com fim de suporte anunciado não receberão correções de bugs nem implementações de novos recursos. As correções de segurança sofrerão backporting com base na avaliação de risco. Esse runtime e a versão prévia acelerada por GPU correspondente no Spark 3.2 serão desativados e desabilitados a partir de 8 de julho de 2024.
- A versão prévia acelerada por GPU agora não tem suporte no runtime do Azure Synapse 3.1 (sem suporte). O runtime do Azure Synapse para Apache Spark 3.1 atingiu o fim do suporte em 26 de janeiro de 2023, tendo o suporte oficial sido descontinuado a partir de 26 de janeiro de 2024, bem como o endereçamento de tíquetes de suporte, correções de bug ou atualizações de segurança após essa data.
RAPIDS Accelerator para Apache Spark
O RAPIDS Accelerator do Spark é um plug-in que funciona substituindo o plano físico de um trabalho do Spark por operações de GPU com suporte e executando essas operações nas GPUs, acelerando assim o processamento. Essa biblioteca está atualmente em versão prévia e não dá suporte a todas as operações do Spark (veja uma lista de operadores com suporte no momento e mais suporte está sendo adicionado incrementalmente por meio de novas versões).
Opções de configuração de cluster
O plug-in RAPIDS Accelerator dá suporte apenas a um mapeamento um para um entre GPUs e executores. Isso significa que um trabalho do Spark precisaria solicitar recursos do executor e do driver que possam ser acomodados pelos recursos do pool (de acordo com o número de núcleos de CPU e de GPU disponíveis). Para atender a essa condição e garantir a utilização ideal de todos os recursos do pool, exigimos a seguinte configuração de drivers e executores em um aplicativo Spark em execução em pools habilitados para GPU:
| Tamanho do pool | Opções de tamanho do driver | Núcleos de driver | Memória do driver (GB) | Núcleos do executor | Memória do executor (GB) | Número de executores |
|---|---|---|---|---|---|---|
| GPU-Large | Driver pequeno | 4 | 30 | 12 | 60 | Número de nós no pool |
| GPU-Large | Driver médio | 7 | 30 | 9 | 60 | Número de nós no pool |
| GPU-XLarge | Driver médio | 8 | 40 | 14 | 80 | 4 * Número de nós no pool |
| GPU-XLarge | Driver grande | 12 | 40 | 13 | 80 | 4 * Número de nós no pool |
Qualquer carga de trabalho que não atender a uma das configurações acima não será aceita. Isso é feito para garantir que os trabalhos do Spark sejam executados com a configuração mais eficiente e eficaz utilizando todos os recursos disponíveis no pool.
O usuário pode definir a configuração acima por meio da carga de trabalho. Para notebooks, o usuário pode usar o comando magic %%configure para definir uma das configurações acima, conforme mostrado abaixo.
Por exemplo, usando um pool grande com três nós:
%%configure -f
{
"driverMemory": "30g",
"driverCores": 4,
"executorMemory": "60g",
"executorCores": 12,
"numExecutors": 3
}
Executar um trabalho do Spark de exemplo por meio do notebook em um pool do Azure Synapse acelerado por GPU
É desejável estar familiarizado com os conceitos básicos de como usar um notebook no Azure Synapse Analytics antes de continuar nesta seção. Vamos percorrer as etapas para executar um aplicativo Spark utilizando a aceleração de GPU. Você pode escrever um aplicativo Spark em todas as quatro linguagens com suporte no Azure Synapse, PySpark (Python), Spark (Scala), SparkSQL e .NET para Spark (C#).
Crie um pool habilitado para GPU.
Crie um notebook e anexe-o ao pool habilitado para GPU criado na primeira etapa.
Defina as configurações conforme explicado na seção anterior.
Crie um dataframe de exemplo copiando o código abaixo na primeira célula do notebook:
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
import org.apache.spark.sql.Row
import scala.collection.JavaConversions._
val schema = StructType( Array(
StructField("emp_id", IntegerType),
StructField("name", StringType),
StructField("emp_dept_id", IntegerType),
StructField("salary", IntegerType)
))
val emp = Seq(Row(1, "Smith", 10, 100000),
Row(2, "Rose", 20, 97600),
Row(3, "Williams", 20, 110000),
Row(4, "Jones", 10, 80000),
Row(5, "Brown", 40, 60000),
Row(6, "Brown", 30, 78000)
)
val empDF = spark.createDataFrame(emp, schema)
- Agora, faremos uma agregação obtendo o salário máximo por ID de departamento e mostraremos o resultado:
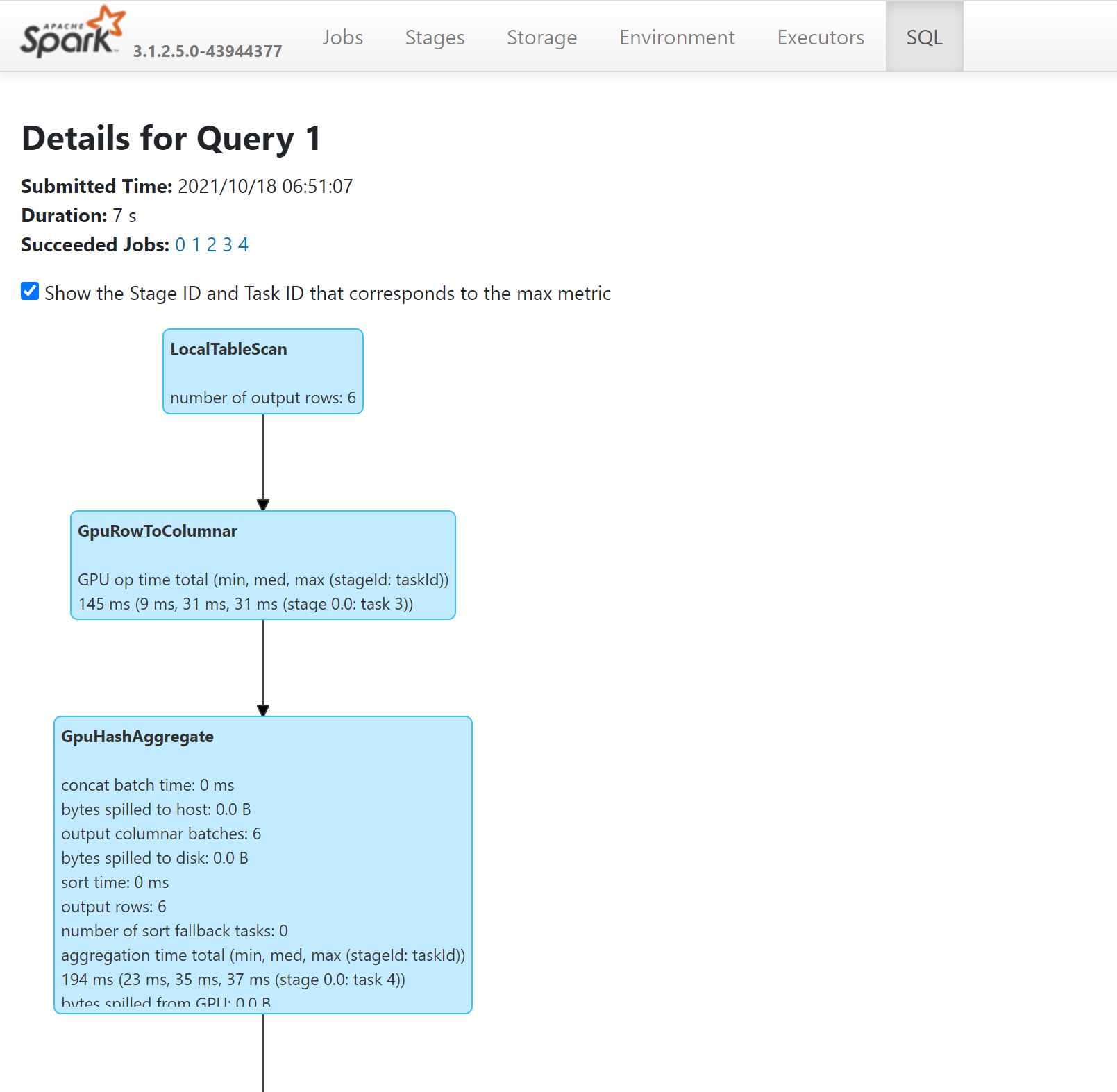
- Você poderá ver as operações na sua consulta que foram realizadas em GPUs observando o plano do SQL por meio do Servidor de Histórico do Spark:
Como ajustar seu aplicativo para GPUs
A maioria dos trabalhos do Spark poderá ver um desempenho aprimorado por meio do ajuste das definições de configuração dos padrões e o mesmo é verdadeiro para trabalhos que estão usando o plug-in RAPIDS Accelerator para Apache Spark.
Cotas e restrições de recursos nos pools do Azure Synapse habilitados para GPU
Nível do workspace
Cada workspace do Azure Synapse vem com uma cota padrão de 50 vCores de GPU. Para aumentar sua cota de núcleos de GPU, envie uma solicitação de suporte no portal do Azure.
Próximas etapas
Comentários
Em breve: Ao longo de 2024, eliminaremos os problemas do GitHub como o mecanismo de comentários para conteúdo e o substituiremos por um novo sistema de comentários. Para obter mais informações, consulte https://aka.ms/ContentUserFeedback.
Enviar e exibir comentários de