Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Tip
Microsoft Fabric Data Warehouse é um armazém relacional de escala empresarial com base de data lake, arquitetura pronta para o futuro, IA integrada e novos recursos. Se você não estiver familiarizado com o data warehouse, comece com Fabric Data Warehouse. As cargas de trabalho existentes de pools de SQL dedicados podem ser atualizadas para Fabric para acessar novos recursos em ciência de dados, análise em tempo real e relatórios.
Neste artigo, você aprenderá a escrever uma consulta usando o pool de SQL do Synapse sem servidor para ler arquivos Delta Lake. O Delta Lake é uma camada de armazenamento open-source que traz transações ACID (atomicidade, consistência, isolamento e durabilidade) para o Apache Spark e cargas de trabalho de Big Data. Saiba mais no vídeo sobre como consultar tabelas de Delta Lake.
Importante
Os pools de SQL sem servidor podem consultar o Delta Lake versão 1.0. As alterações que foram introduzidas desde a versão do Delta Lake 1.2, como renomeação de colunas, não são compatíveis com o modo sem servidor. Se você estiver usando as versões mais avançadas do Delta com vetores de exclusão, pontos de verificação v2 e outros, considere usar outro mecanismo de consulta, como o endpoint SQL do Microsoft Fabric para Lakehouses.
O pool de SQL sem servidor no espaço de trabalho do Synapse permite ler os dados armazenados em formato Delta Lake e distribuí-los às ferramentas de relatório. Um pool de SQL sem servidor pode ler arquivos Delta Lake criados com o uso do Apache Spark, Azure Databricks ou qualquer outro produtor do formato Delta Lake.
Os pools do Apache Spark no Azure Synapse permitem que os engenheiros de dados modifiquem arquivos Delta Lake usando Scala, PySpark e .NET. Os pools de SQL sem servidor ajudam os analistas de dados a gerar relatórios sobre arquivos Delta Lake criados por engenheiros de dados.
Importante
A consulta do formato Delta Lake com o pool de SQL sem servidor é uma funcionalidade em disponibilidade geral. No entanto, a consulta de tabelas Delta do Spark ainda está em versão prévia pública e não está pronta para produção. Há problemas conhecidos que poderão ocorrer se você consultar tabelas Delta criadas por meio dos Pools do Spark. Confira os problemas conhecidos em autoajuda do pool de SQL sem servidor.
Pré-requisitos
Importante
As fontes de dados só podem ser criadas em bancos de dados personalizados (não no banco de dados mestre ou nos bancos de dados replicados dos pools do Apache Spark).
Para usar os exemplos neste artigo, você precisará concluir as seguintes etapas:
- Crie um banco de dados com uma fonte de dados que faça referência à conta de armazenamento NYC Yellow Taxi.
- Inicialize os objetos executando o script de instalação no banco de dados criado na etapa 1. Esse script de instalação criará as fontes de dados, as credenciais no escopo do banco de dados e os formatos de arquivo externos que são usados nessas amostras.
Se você tiver criado o seu banco de dados e alternado seu contexto (usando instrução USE database_name ou a lista de menus suspensos para selecionar o banco de dados em um editor de consultas), poderá criar sua fonte de dados externa que contenha o URI raiz para esse conjunto de dados e usá-la para consultar arquivos do Delta Lake. Por exemplo:
CREATE EXTERNAL DATA SOURCE DeltaLakeStorage
WITH ( LOCATION = 'https://<yourstorageaccount>.blob.core.windows.net/delta-lake/' );
GO
SELECT TOP 10 *
FROM OPENROWSET(
BULK 'covid',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT = 'delta'
) as rows;
Se uma fonte de dados estiver protegida com uma chave SAS ou identidade personalizada, você poderá configurar a fonte de dados com credenciais no escopo do banco de dados.
É possível criar uma fonte de dados externa cuja localização aponte para a pasta raiz do armazenamento. Após criar a fonte de dados externa, use a fonte de dados e o caminho relativo para o arquivo na função OPENROWSET. Assim, você não precisa usar o URI absoluto completo para seus arquivos. Também é possível definir credenciais personalizadas para acessar o local de armazenamento.
Ler a pasta Delta Lake
Importante
Use o script de instalação nos pré-requisitos para configurar as fontes de dados e tabelas de exemplo.
A função OPENROWSET permite ler o conteúdo de arquivos Delta Lake fornecendo a URL à sua pasta raiz.
A maneira mais fácil de ver o conteúdo do arquivo DELTA é fornecer a URL do arquivo à função OPENROWSET e especificar o formato DELTA. Se o arquivo estiver disponível publicamente ou se sua identidade do Microsoft Entra puder acessar esse arquivo, você poderá ver o conteúdo do arquivo usando uma consulta como a mostrada no exemplo a seguir:
SELECT TOP 10 *
FROM OPENROWSET(
BULK '/covid/',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT = 'delta') as rows;
Os nomes de coluna e tipos de dados são lidos automaticamente nos arquivos Delta Lake. A função OPENROWSET usa os melhores tipos de estimativa, como VARCHAR(1000), para as colunas de cadeia de caracteres.
O URI na função OPENROWSET deve fazer referência à pasta Delta Lake raiz que contém uma subpasta chamada _delta_log.
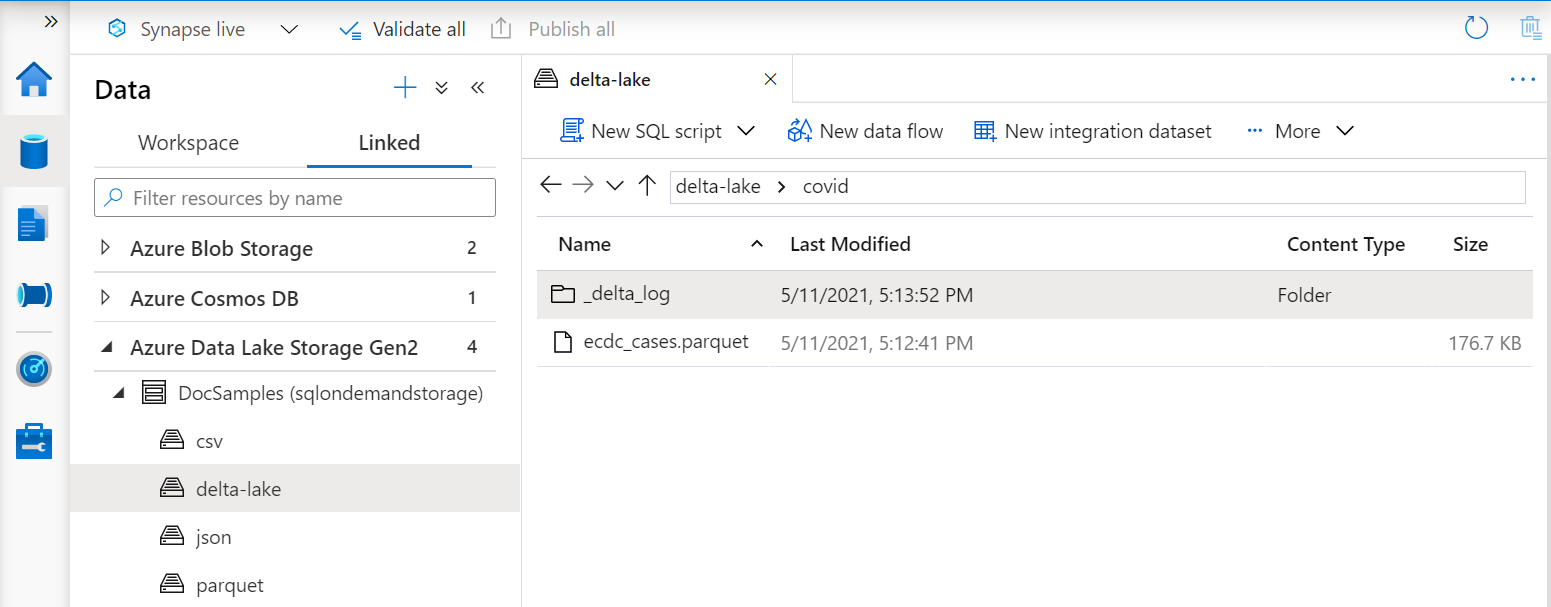
Se você não tiver essa subpasta, significa que não está usando o formato Delta Lake. Você pode converter seus arquivos Parquet simples na pasta para o formato Delta Lake usando um script como o seguinte exemplo de script Python do Apache Spark:
%%pyspark
from delta.tables import DeltaTable
deltaTable = DeltaTable.convertToDelta(spark, "parquet.`abfss://delta-lake@sqlondemandstorage.dfs.core.windows.net/covid`")
Para melhorar o desempenho das suas consultas, considere especificar tipos explícitos na WITH cláusula.
Observação
O pool de SQL do Synapse sem servidor usa a inferência de esquema para determinar automaticamente as colunas e seus tipos. As regras de inferência de esquema são as mesmas usadas para arquivos Parquet. Para mapeamento de tipo Delta Lake para o tipo nativo do SQL, confira mapeamento de tipo para Parquet.
Verifique se você consegue acessar o arquivo. Se o arquivo estiver protegido por uma chave SAS ou identidade personalizada do Azure, você deverá configurar uma credencial no nível do servidor para logon do SQL.
Importante
Verifique se você está usando um agrupamento do banco de dados UTF-8 (por exemplo, Latin1_General_100_BIN2_UTF8), porque os valores de cadeia de caracteres em arquivos Delta Lake são codificados usando o modelo UTF-8.
A incompatibilidade entre a codificação de texto no arquivo Delta Lake e o agrupamento pode causar erros de conversão inesperados.
Você pode alterar facilmente o agrupamento padrão do banco de dados atual usando a seguinte instrução T-SQL:
ALTER DATABASE CURRENT COLLATE Latin1_General_100_BIN2_UTF8; Para obter mais informações sobre agrupamentos, consulte Tipos de agrupamentos com suporte para o SQL do Synapse.
Especificar explicitamente o esquema
OPENROWSET permite especificar explicitamente quais colunas você deseja ler no arquivo usando a cláusula WITH:
SELECT TOP 10 *
FROM OPENROWSET(
BULK 'covid',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT = 'delta'
)
WITH ( date_rep date,
cases int,
geo_id varchar(6)
) as rows;
Com a especificação explícita do esquema do conjunto de resultados, você pode minimizar os tamanhos de tipo e usar os tipos mais precisos VARCHAR(6) para colunas de cadeia de caracteres em vez da opção pessimista VARCHAR(1000). A minimização de tipos pode melhorar significativamente o desempenho das suas consultas.
Importante
Verifique se você está especificando explicitamente um agrupamento UTF-8 (por exemplo,Latin1_General_100_BIN2_UTF8) para todas as colunas de cadeia de caracteres na cláusula WITH, ou defina um agrupamento UTF-8 no nível do banco de dados.
Uma incompatibilidade entre a codificação de texto no arquivo e o agrupamento da coluna de cadeia de caracteres pode causar erros inesperados de conversão.
É possível alterar facilmente o agrupamento padrão do banco de dados atual usando a seguinte instrução T-SQL:
alter database current collate Latin1_General_100_BIN2_UTF8 Você pode definir facilmente a ordenação nos tipos de coluna usando a seguinte definição: geo_id varchar(6) collate Latin1_General_100_BIN2_UTF8
Conjunto de dados
Neste exemplo, é usado o conjunto de dados de Táxi Amarelo de NYC. O conjunto de PARQUET dados original é convertido em DELTA formato e a DELTA versão é usada nos exemplos.
Consultar dados particionados
O conjunto de dados fornecido neste exemplo foi dividido (particionado) em subpastas separadas.
Ao contrário da opção Parquet, você não precisa direcionar partições específicas usando a função FILEPATH. A função OPENROWSET identificará colunas de particionamento na sua estrutura de pastas do Delta Lake e permitirá a consulta direta de dados com o uso dessas colunas. Este exemplo mostra os valores das tarifas por ano, mês e tipo de pagamento nos três primeiros meses de 2017.
SELECT
YEAR(pickup_datetime) AS year,
passenger_count,
COUNT(*) AS cnt
FROM
OPENROWSET(
BULK 'yellow',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT='DELTA'
) nyc
WHERE
nyc.year = 2017
AND nyc.month IN (1, 2, 3)
AND pickup_datetime BETWEEN CAST('1/1/2017' AS datetime) AND CAST('3/31/2017' AS datetime)
GROUP BY
passenger_count,
YEAR(pickup_datetime)
ORDER BY
YEAR(pickup_datetime),
passenger_count;
A função OPENROWSET eliminará as partições não correspondentes a year e month na cláusula where. Essa técnica de remoção de arquivo/partição reduz significativamente o conjunto de dados, melhora o desempenho e reduz o custo da consulta.
O nome da pasta na função OPENROWSET (yellow neste exemplo) é concatenado usando o LOCATION na fonte de dados DeltaLakeStorage, e deve referenciar a pasta raiz do Delta Lake que contém uma subpasta denominada _delta_log.
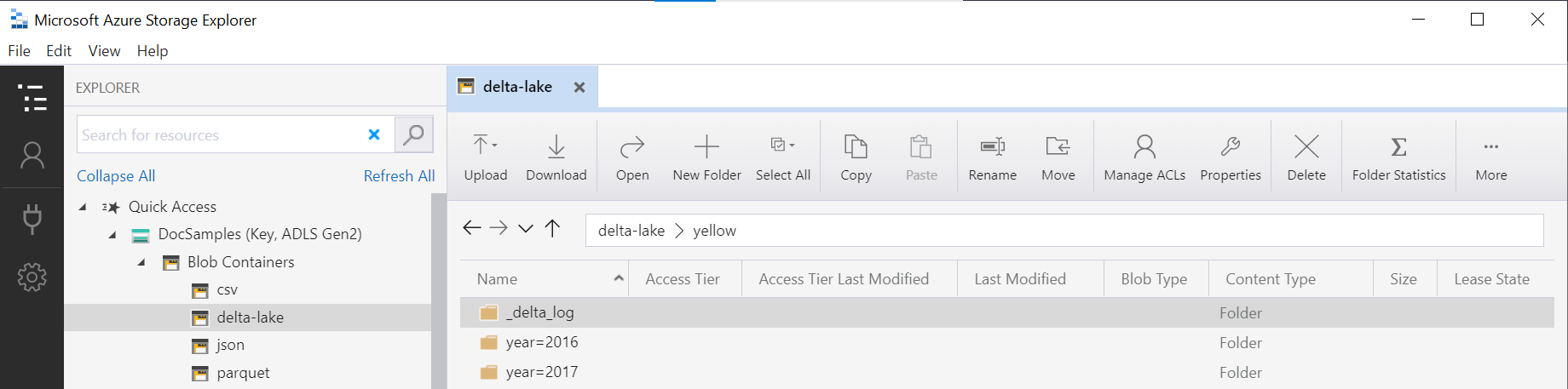
Se você não tiver essa subpasta, significa que não está usando o formato Delta Lake. Você pode converter seus arquivos Parquet simples na pasta ao formato Delta Lake usando o seguinte script do Python no Apache Spark:
%%pyspark
from delta.tables import DeltaTable
deltaTable = DeltaTable.convertToDelta(spark, "parquet.`abfss://delta-lake@sqlondemandstorage.dfs.core.windows.net/yellow`", "year INT, month INT")
O segundo argumento da função DeltaTable.convertToDeltaLake representa as colunas de particionamento (ano e mês) que integram o padrão de pasta (neste exemplo, year=*/month=*) e seus tipos.
Limitações
- Analise as limitações e os problemas conhecidos na página de autoajuda do pool de SQL sem servidor do Synapse.
Conteúdo relacionado
Acesse o próximo artigo para saber como Consultar tipos aninhados de Parquet. Se você quiser continuar criando soluções Delta Lake, saiba como criar exibições ou tabelas externas na pasta Delta Lake.