Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Tip
Microsoft Fabric Data Warehouse é um armazém relacional de escala empresarial com base de data lake, arquitetura pronta para o futuro, IA integrada e novos recursos. Se você não estiver familiarizado com o data warehouse, comece com Fabric Data Warehouse. As cargas de trabalho existentes de pools de SQL dedicados podem ser atualizadas para Fabric para acessar novos recursos em ciência de dados, análise em tempo real e relatórios.
Neste tutorial, você aprenderá a executar a análise de dados exploratórios usando conjuntos de dados abertos existentes, sem a necessidade de configuração de armazenamento. Você combina diferentes Azure Open Datasets usando um pool de SQL sem servidor. Depois, você visualizará os resultados no Synapse Studio para o Azure Synapse Analytics.
Neste tutorial, você:
- Acessar o pool de SQL sem servidor interno
- Acessar conjuntos de dados abertos do Azure para usar dados do tutorial
- Executar a análise básica de dados usando o SQL
Acessar o pool de SQL sem servidor
Cada espaço de trabalho vem com um pool SQL sem servidor pré-configurado para você usar chamado Built-in. Para acessá-lo:
- Abra o workspace e selecione o hub Desenvolver.
- Selecione o botão +Adicionar novo recurso.
- Selecione Script SQL.
Você pode usar esse script para explorar seus dados sem precisar reservar a capacidade do SQL.
Se você não tiver uma assinatura do Azure, crie uma conta gratuita antes de começar.
Acessar os dados do tutorial
Todos os dados que usamos neste tutorial estão hospedados na conta de armazenamento azureopendatastorage, que contém conjuntos de dados abertos do Azure para uso aberto em tutoriais como este. Você pode executar todos os scripts como estão diretamente do seu workspace, desde que seu workspace possa acessar uma rede pública.
Este tutorial usa um conjunto de dados sobre o Táxi de Nova Iorque (NYC):
- Datas e horas da retirada e entrega
- Localizações da retirada e entrega
- Distâncias das viagens
- Tarifas discriminadas
- Tipos de taxa
- Tipos de pagamento
- Contagens de passageiro relatadas pelos motoristas
A função OPENROWSET(BULK...) permite que você acesse arquivos no Armazenamento do Azure.
[OPENROWSET](develop-openrowset.md) lê o conteúdo de uma fonte de dados remota, como um arquivo, e retorna o conteúdo como um conjunto de linhas.
Para familiarizar-se com os dados de táxis de NYC, execute a seguinte consulta:
SELECT TOP 100 * FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/puYear=*/puMonth=*/*.parquet',
FORMAT='PARQUET'
) AS [nyc]
Outros conjuntos de dados acessíveis
Da mesma forma, podemos consultar o conjunto de dados de feriados públicos usando a seguinte consulta:
SELECT TOP 100 * FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/holidaydatacontainer/Processed/*.parquet',
FORMAT='PARQUET'
) AS [holidays]
Você também pode consultar o conjunto de dados meteorológicos usando a seguinte consulta:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/isdweatherdatacontainer/ISDWeather/year=*/month=*/*.parquet',
FORMAT='PARQUET'
) AS [weather]
Você pode saber mais sobre o significado das colunas individuais nas descrições dos conjuntos de dados:
Inferência de esquema automática
Como os dados são armazenados no formato de arquivo Parquet, a inferência automática de esquema está disponível. Você pode consultar os dados sem a necessidade de listar os tipos de dados de todas as colunas nos arquivos. Você também pode utilizar o mecanismo de coluna virtual e a função filepath para filtrar um determinado subconjunto de arquivos.
Observação
O agrupamento padrão é SQL_Latin1_General_CP1_CI_ASIf. Para uma ordenação não padrão, leve em conta a diferenciação de maiúsculas e minúsculas.
Se você criar um banco de dados com uma ordenação com diferenciação de maiúsculas e minúsculas, use o nome correto da coluna ao especificar as colunas.
Um nome de coluna tpepPickupDateTime estaria correto enquanto tpeppickupdatetime não funcionasse em um agrupamento não padrão.
Análise de série temporal, sazonalidade e exceções
Você pode resumir o número anual de corridas de táxi usando a seguinte consulta:
SELECT
YEAR(tpepPickupDateTime) AS current_year,
COUNT(*) AS rides_per_year
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/puYear=*/puMonth=*/*.parquet',
FORMAT='PARQUET'
) AS [nyc]
WHERE nyc.filepath(1) >= '2009' AND nyc.filepath(1) <= '2019'
GROUP BY YEAR(tpepPickupDateTime)
ORDER BY 1 ASC
O seguinte snippet mostra o resultado do número anual de corridas de táxi:
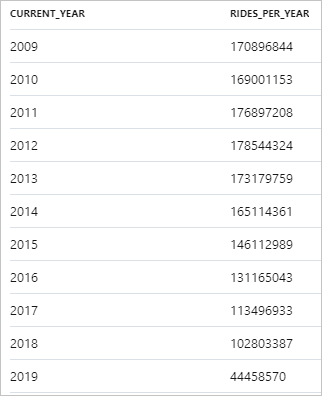
Os dados podem ser visualizados no Synapse Studio, alternando da exibição de Tabela para a exibição de gráfico. Você pode escolher entre diferentes tipos de gráfico, tais como: área, barras, colunas, linha, pizza e dispersão. Neste caso, plote o gráfico de colunas com a coluna Categoria definida com o valor current_year:
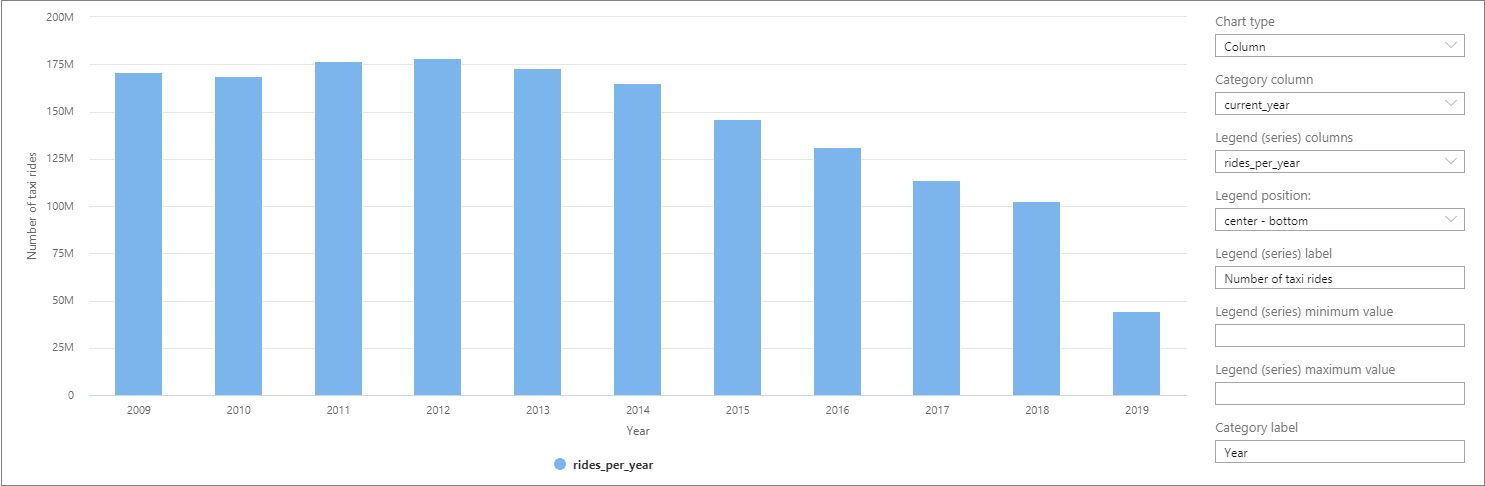
Nessa visualização, veja uma tendência de diminuição dos números de corridas ao longo dos anos. Supostamente, essa queda se deve ao recente aumento da popularidade das empresas de compartilhamento de caronas.
Observação
No momento da elaboração deste tutorial, os dados de 2019 ainda estavam incompletos. Como resultado, há uma enorme queda no número de corridas desse ano.
Você pode concentrar a análise em um ano específico, por exemplo: 2016. A seguinte consulta retorna o número diário de corridas durante aquele ano:
SELECT
CAST([tpepPickupDateTime] AS DATE) AS [current_day],
COUNT(*) as rides_per_day
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/puYear=*/puMonth=*/*.parquet',
FORMAT='PARQUET'
) AS [nyc]
WHERE nyc.filepath(1) = '2016'
GROUP BY CAST([tpepPickupDateTime] AS DATE)
ORDER BY 1 ASC
O seguinte snippet mostra o resultado dessa consulta:
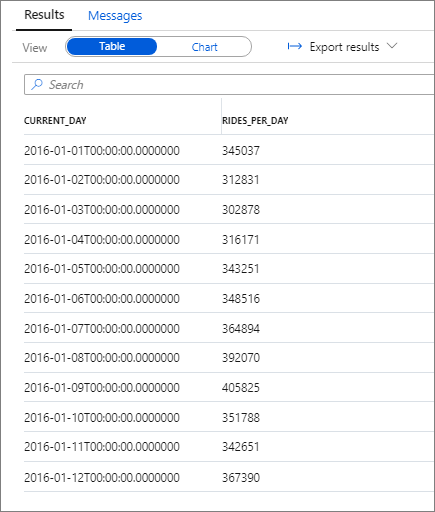
Novamente, você pode visualizar os dados plotando o gráfico de colunas com a coluna Categoria definida com o valor current_day e a coluna Legend (series) definida com o valor rides_per_day.
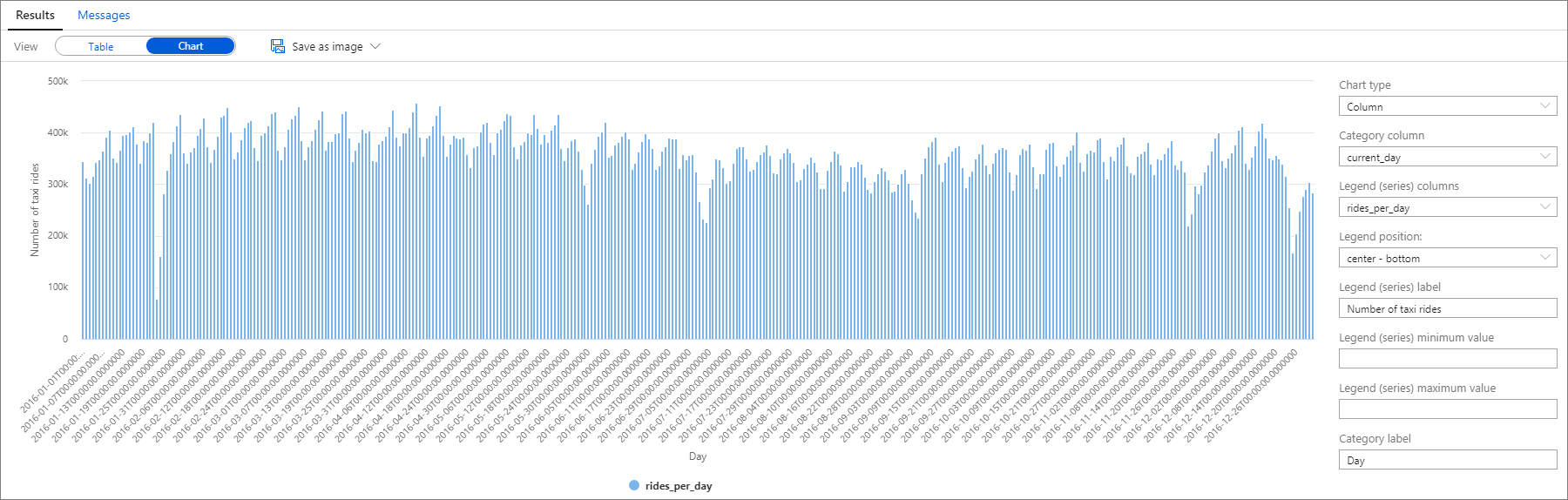
No gráfico, você pode ver que há um padrão semanal, com os sábados sendo o dia de pico. Durante os meses de verão, há menos corridas de táxi devido ao período de férias. Há também algumas quedas significativas no número de corridas de táxi sem um padrão claro de quando e por que elas ocorrem.
Em seguida, veja a queda nas corridas se correlaciona com feriados públicos. Verifique se há uma correlação unindo o conjunto de dados de corridas de Táxi de NYC com o conjunto de dados de feriados públicos:
WITH taxi_rides AS (
SELECT
CAST([tpepPickupDateTime] AS DATE) AS [current_day],
COUNT(*) as rides_per_day
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/puYear=*/puMonth=*/*.parquet',
FORMAT='PARQUET'
) AS [nyc]
WHERE nyc.filepath(1) = '2016'
GROUP BY CAST([tpepPickupDateTime] AS DATE)
),
public_holidays AS (
SELECT
holidayname as holiday,
date
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/holidaydatacontainer/Processed/*.parquet',
FORMAT='PARQUET'
) AS [holidays]
WHERE countryorregion = 'United States' AND YEAR(date) = 2016
),
joined_data AS (
SELECT
*
FROM taxi_rides t
LEFT OUTER JOIN public_holidays p on t.current_day = p.date
)
SELECT
*,
holiday_rides =
CASE
WHEN holiday is null THEN 0
WHEN holiday is not null THEN rides_per_day
END
FROM joined_data
ORDER BY current_day ASC
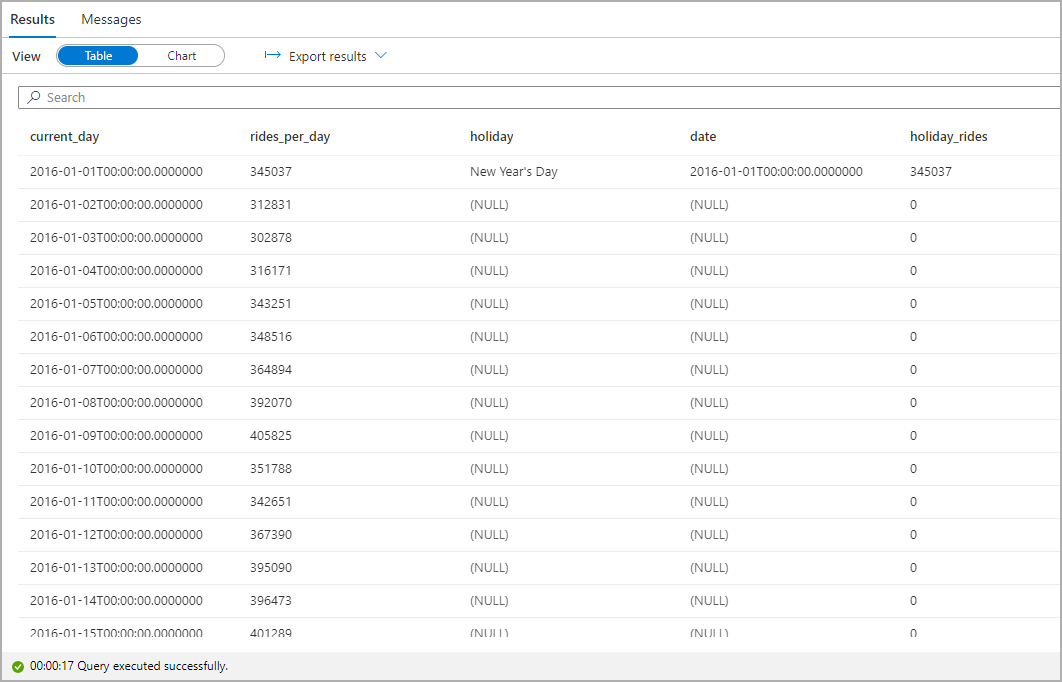
Destaque o número de corridas de táxi durante os feriados públicos. Para isso, escolha current_day para a coluna Categoria e rides_per_day e holiday_rides como as colunas Legend (series).
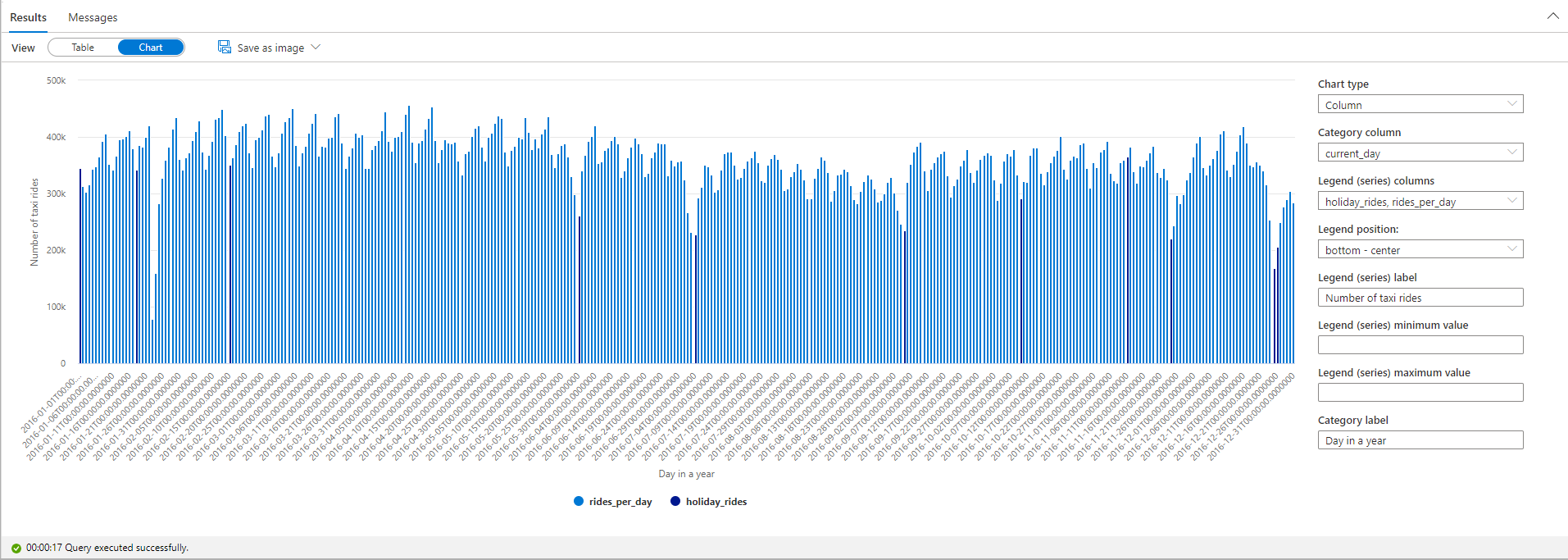
No gráfico de plotagem, é possível ver que, durante os feriados públicos, o número de corridas de táxi é menor. No entanto, ainda há uma grande queda não explicada no dia 23 de janeiro. Vamos examinar o clima em NYC naquele dia consultando o conjunto de dados meteorológicos:
SELECT
AVG(windspeed) AS avg_windspeed,
MIN(windspeed) AS min_windspeed,
MAX(windspeed) AS max_windspeed,
AVG(temperature) AS avg_temperature,
MIN(temperature) AS min_temperature,
MAX(temperature) AS max_temperature,
AVG(sealvlpressure) AS avg_sealvlpressure,
MIN(sealvlpressure) AS min_sealvlpressure,
MAX(sealvlpressure) AS max_sealvlpressure,
AVG(precipdepth) AS avg_precipdepth,
MIN(precipdepth) AS min_precipdepth,
MAX(precipdepth) AS max_precipdepth,
AVG(snowdepth) AS avg_snowdepth,
MIN(snowdepth) AS min_snowdepth,
MAX(snowdepth) AS max_snowdepth
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/isdweatherdatacontainer/ISDWeather/year=*/month=*/*.parquet',
FORMAT='PARQUET'
) AS [weather]
WHERE countryorregion = 'US' AND CAST([datetime] AS DATE) = '2016-01-23' AND stationname = 'JOHN F KENNEDY INTERNATIONAL AIRPORT'

Os resultados da consulta indicam que a queda no número de corridas de táxis ocorreu porque:
- houve uma nevasca de alta intensidade (aprox. 30 cm de espessura) naquele dia em NYC.
- Fez muito frio (a temperatura ficou abaixo de zero graus Celsius).
- Vento muito (aproximadamente 10 m/s).
Este tutorial mostrou como um analista de dados pode executar rapidamente uma análise exploratória de dados. Você pode combinar conjuntos de dados diferentes usando o pool de SQL sem servidor e visualizar os resultados usando o Azure Synapse Studio.
Conteúdo relacionado
Para aprender como conectar o pool de SQL sem servidor ao Power BI Desktop e criar relatórios, confira o artigo Conectar o pool de SQL sem servidor ao Power BI Desktop e criar relatórios.
Para saber como usar tabelas externas no pool de SQL sem servidor, confira Usar tabelas externas com o SQL do Synapse