Migração do Time Series Insights (TSI) Gen2 para o Azure Data Explorer
Observação
O serviço TSI (Time Series Insights) não terá mais suporte após março de 2025. Considere migrar os ambientes existentes do TSI para soluções alternativas assim que possível. Para obter mais informações sobre a substituição e a migração, visite nossa documentação.
Visão geral
Recomendações de migração de alto nível.
| Recurso | Estado Gen2 | Migração recomendada |
|---|---|---|
| Ingerir o JSON do hub com mesclagem e saída | Ingestão de TSI | Assistente/ingestão do ADX-OneClick |
| Abrir armazenamento frio | ID do arm da conta de armazenamento do cliente | Exportação de dados contínua para tabela externa especificada pelo cliente em ADLS. |
| Conector PBI | Versão Prévia Privada | Use o conector ADX PBI. Reescreva TSQ para KQL manualmente. |
| Conector do Spark | Versão prévia privada. Dados de telemetria da consulta. Tarefa de Modelo de Consulta. | Migrar dados para o ADX. Use o conector do Spark ADX para dados de telemetria + exportar o modelo para JSON e carregar no Spark. Reescreva as consultas em KQL. |
| Carregamento em Massa | Versão Prévia Privada | Use Ingest e LightIngest do ADX OneClick. Opcionalmente, configure o particionamento no ADX. |
| Modelo do Time Series | Pode ser exportado como um arquivo JSON. Pode ser importado para ADX para executar junções em KQL. | |
| Explorer do TSI | Alternando quente e frio | Painéis de laboratório |
| Idioma de consulta | Consultas de série temporal (TSQ) | Reescreva as consultas em KQL. Use SDKs do Kusto em vez de TSI. |
Migrando telemetria
Use PT=Time a pasta na conta de armazenamento para recuperar a cópia de toda a telemetria no ambiente. Para saber mais, veja Armazenamento Premium.
Etapa de migração 1 – Obter estatísticas sobre dados de telemetria
Dados
- Visão geral do env
- Registre a ID do ambiente da primeira parte do FQDN de acesso a dados (por exemplo, d390b0b0-1445-4c0c-8365-68d6382c1c2a de. env.crystal-dev.windows-int.net)
- visão geral de Env- > configuração de Armazenamento- > Armazenamento conta
- Usar Gerenciador de Armazenamento para obter estatísticas de pasta
- Tamanho do registro e o número de BLOBs da
PT=Timepasta. Para clientes na visualização privada da importação em massa, também no tamanho do registroPT=Importe no número de BLOBs.
- Tamanho do registro e o número de BLOBs da
Etapa de migração 2 – migrar telemetria para ADX
Criar cluster ADX
Defina o tamanho do cluster com base no tamanho dos dados usando o avaliador de custo ADX.
- Das métricas de Hubs de Eventos (ou Hub IoT), recupere a taxa de quantidade de dados ingeridos por dia. Na conta de Armazenamento conectada ao ambiente de TSI, recupere a quantidade de dados no contêiner de blob usado pelo TSI. Essas informações serão usadas para calcular o tamanho ideal de um cluster ADX para seu ambiente.
- Abra o Avaliador de custo do Azure Data Explorer e preencha os campos existentes com as informações encontradas. Defina "tipo de carga de trabalho" como "otimizado para armazenamento" e "dados ativos" com a quantidade total de dados consultados ativamente.
- Depois de fornecer todas as informações, o avaliador de custo do Azure Data Explorer irá sugerir um tamanho de VM e um número de instâncias para o cluster. Analise se o tamanho dos dados consultados ativamente se ajustará ao cache ativo. Multiplique o número de instâncias sugeridas pelo tamanho do cache do tamanho da VM, por exemplo:
- Sugestão de avaliador de custo: 9x DS14 + 4 TB (cache)
- Cache ativo total sugerido: 36 TB = [9x (instâncias) x 4 TB (de cache ativo por nó)]
- Mais fatores a considerar:
- Crescimento do ambiente: ao planejar o tamanho do cluster ADX, considere o crescimento dos dados ao longo do tempo.
- Hidratação e particionamento: ao definir o número de instâncias no cluster ADX, considere nós extras (2-3x) para acelerar o hidratação e o particionamento.
- Para obter mais informações sobre a seleção de computação, consulte Selecionar a SKU de computação correta para seu cluster do Azure Data Explorer.
Para monitorar melhor o cluster e a ingestão de dados, você deve habilitar as Configurações de Diagnóstico e enviar os dados para um Workspace do Log Analytics.
No blade Azure Data Explorer, vá para "Monitoramento | Configurações de diagnóstico" e clique em "Adicionar configuração de diagnóstico"
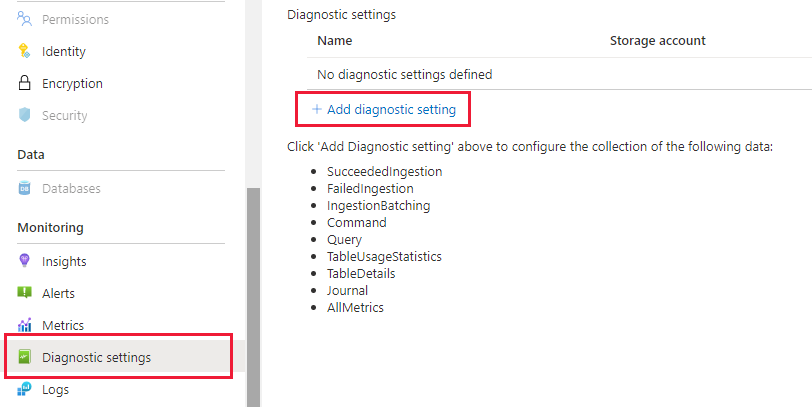
Preencha o seguinte
- Nome da configuração de diagnóstico: nome de exibição para esta configuração
- Logs: no mínimo, selecione SucceededIngestion, FailedIngestion, IngestionBatching
- Selecione o espaço de trabalho Log Analytics para o qual enviar os dados (se você não tiver um, você precisará provisionar um antes desta etapa)
Particionamento de dados.
- Para conjuntos de dados, o particionamento padrão do ADX é suficiente.
- O particionamento de dados é benéfico em um conjunto muito específico de cenários e não deve ser aplicado de outra forma:
- Para melhorar a latência de consulta em conjuntos de Big Data em que a maioria das consultas filtra em uma coluna de cadeia de caracteres de alta cardinalidade, por exemplo, uma ID de série temporal.
- Ao ingerir dados fora de ordem, por exemplo, quando eventos do passado puderem ser ingeridos em dias ou semanas após sua geração na origem.
- Para obter mais informações, verifique a política de particionamento de dados do ADX.


Formatos para ingestão de dados
Ir para https://dataexplorer.azure.com.
Vá para a guia dados e selecione “Ingerir do contêiner de BLOBs’
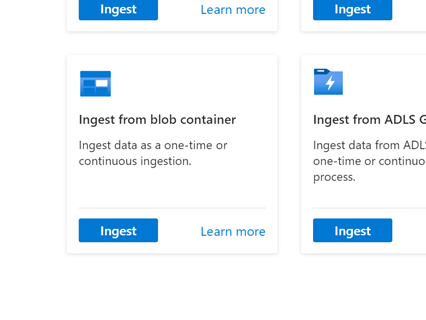
Selecione cluster, banco de dados e crie uma nova tabela com o nome escolhido para os dados TSI
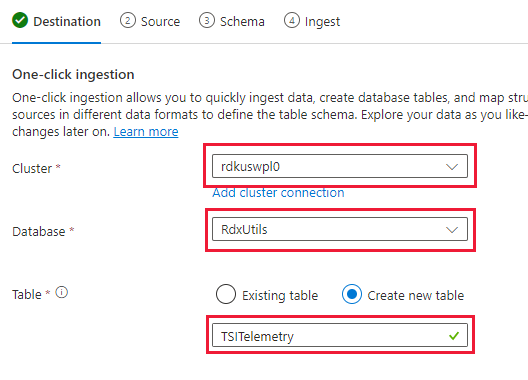
Selecione Avançar: origem
Na guia origem, selecione:
- Dados históricos
- “Selecionar contêiner”
- Escolha a assinatura e a conta de Armazenamento para seus dados de TSI
- Escolha o contêiner que se correlaciona com o ambiente TSI
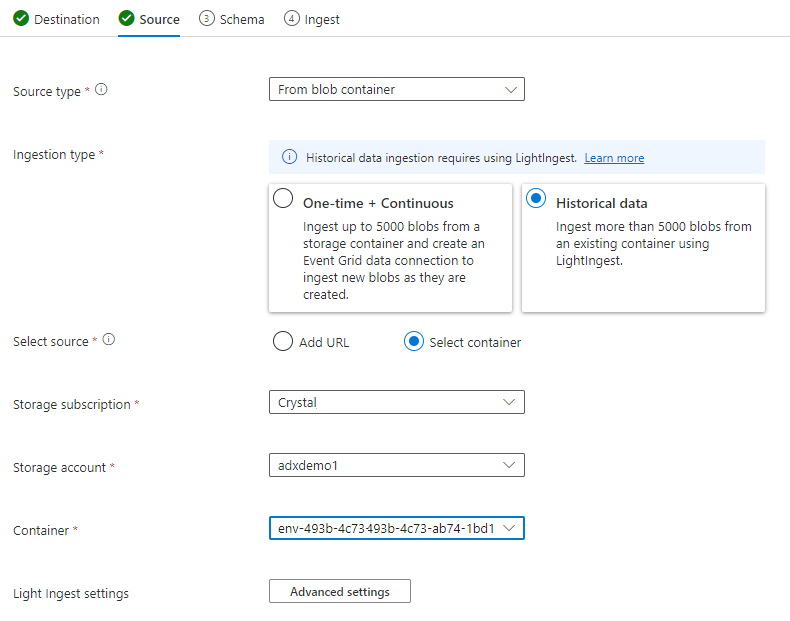
Selecione Configurações avançadas
- Creation time pattern: '/'yyyyMMddHHmmssfff'_'
- Padrão de nome de blob: *. parquet
- Selecione “Não aguardar a conclusão da ingestão”
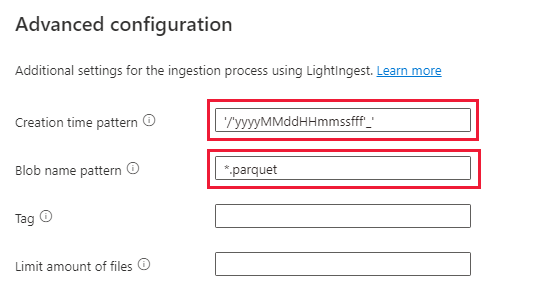
Em filtros de arquivo, adicione o caminho da pasta
V=1/PT=Time
Selecione Avançar: esquema
Observação
O TSI aplica um nivelamento e saída ao persistir colunas em arquivos parquet. Consulte estes links para obter mais detalhes: mesclagem e saída de regras, atualizações de regras de ingestão.






Se o esquema for desconhecido ou variável
Remova todas as colunas que são consultadas com frequência, deixando pelo menos carimbo de data/hora e coluna (s) TSID.
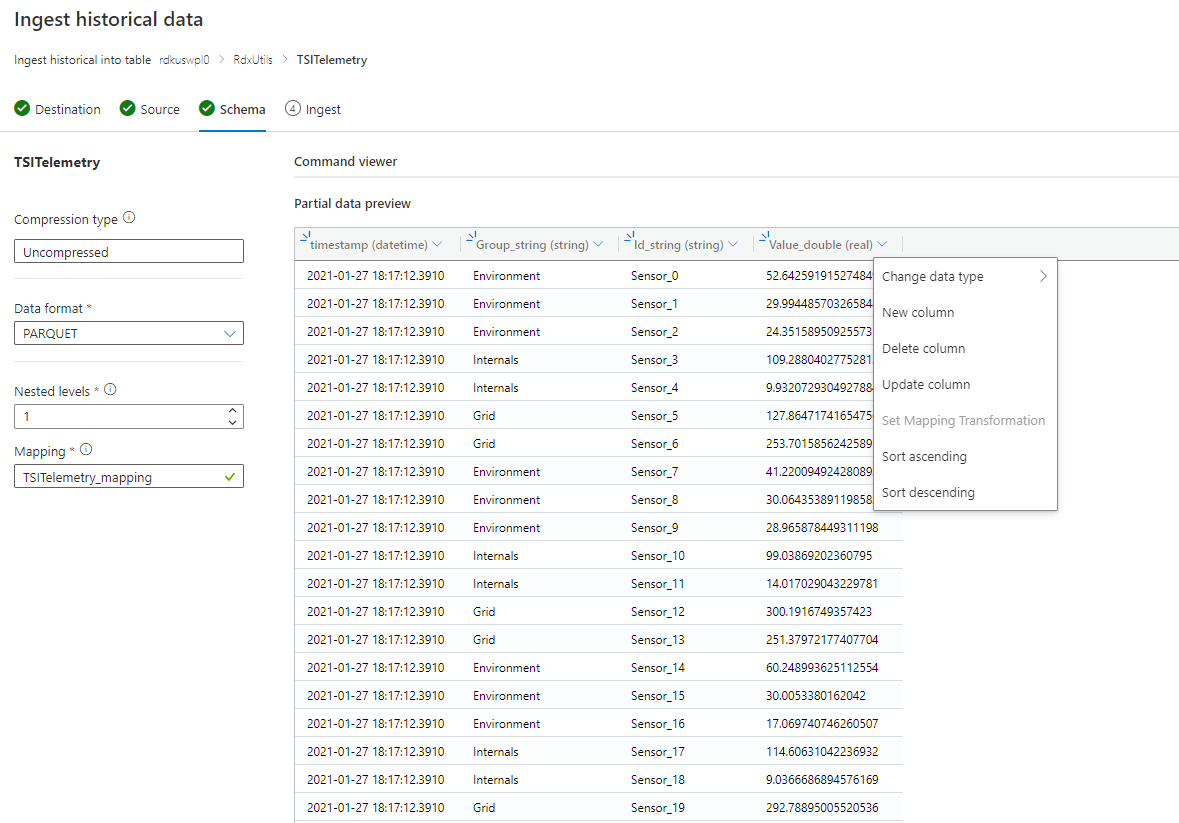
Adicione uma nova coluna de tipo dinâmico e mapeie-a para o registro inteiro usando $ Path.
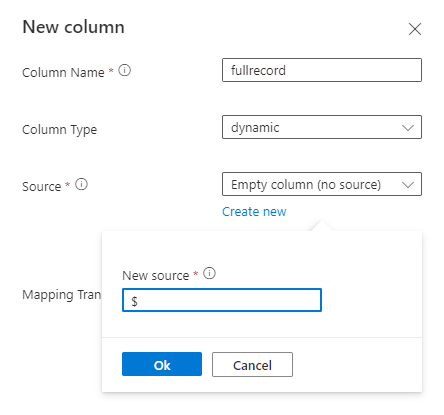
Exemplo:
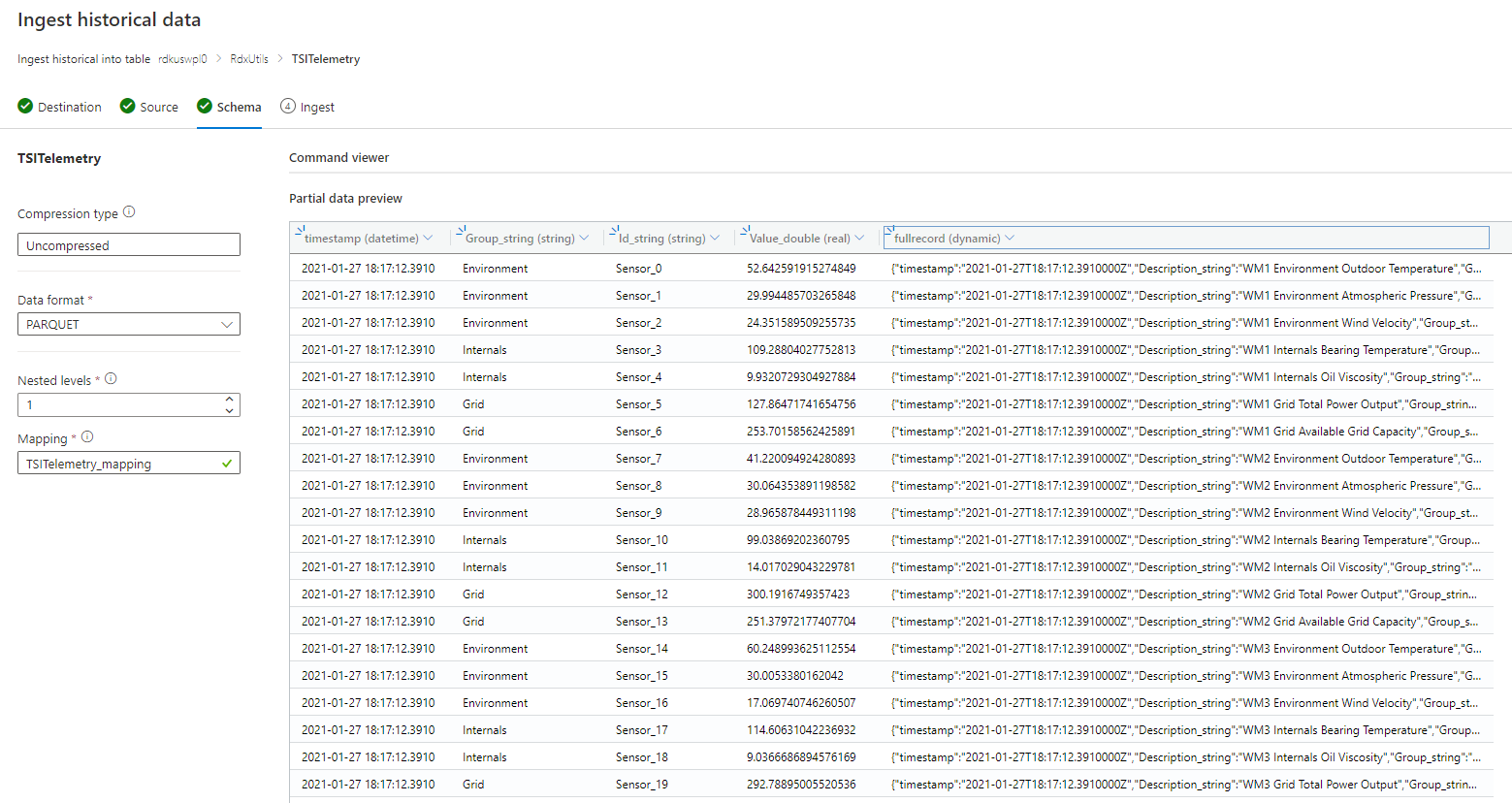
Se o esquema for conhecido ou fixo
- Confirme se os dados parecem corretos. Corrija todos os tipos, se necessário.
- Selecione Avançar: Resumo



Copie o comando de iluminação e armazene-o em algum lugar para que você possa usá-lo na próxima etapa.

Ingestão de dados
Antes de ingerir os dados, você precisa instalar a ferramenta mais iluminada. O comando gerado a partir de One-Click ferramenta inclui um token SAS. É melhor gerar um novo para que você tenha controle sobre o tempo de expiração. No portal, navegue até o contêiner de BLOB para o ambiente TSI e selecione ‘token de acesso compartilhado’

Observação
Também é recomendável escalar verticalmente o cluster antes de iniciar uma grande ingestão. Por exemplo, D14 ou D32 com mais de 8 instâncias.
Defina o seguinte
- Permissões: leitura e lista
- Expiração: definido como um período em que você se sente confortável de que a migração de dados será concluída
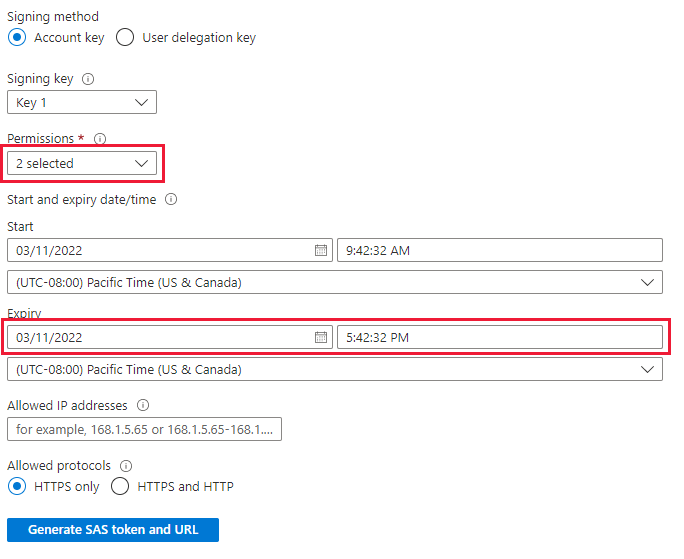
Clique em ‘Gerar o Token e a URL SAS’ e copie a ‘URL SAS do blob’

Vá para o comando de iluminação que você copiou anteriormente. Substitua o -source parameter no comando por esta ‘URL SAS do Blob’
Opção 1: ingerir todos os dados. Para ambientes menores, você pode ingerir todos os dados com um único comando.
- Abra um prompt de comando e altere para o diretório no qual a ferramenta de iluminação foi extraída. Uma vez lá, Cole o comando de iluminação e execute-o.

Opção 2: ingerir dados por ano ou por mês. Para ambientes maiores ou para testar em um conjunto de dados menor, você pode filtrar ainda mais o comando de iluminação.
Por ano: altere seu parâmetro-prefix
- Antes:
-prefix:"V=1/PT=Time" - Depois:
-prefix:"V=1/PT=Time/Y=<Year>" - Exemplo:
-prefix:"V=1/PT=Time/Y=2021"
- Antes:
Por mês: altere seu parâmetro-prefix
- Antes:
-prefix:"V=1/PT=Time" - Depois:
-prefix:"V=1/PT=Time/Y=<Year>/M=<month #>" - Exemplo:
-prefix:"V=1/PT=Time/Y=2021/M=03"
- Antes:



Depois de modificar o comando, execute-o como acima. Uma das ingestão está concluída (usando a opção de monitoramento abaixo) modifique o comando para o próximo ano e mês que você deseja ingerir.
Ingestão de monitoramento
O comando de iluminação incluía o sinalizador-dontWait para que o próprio comando não aguarde a conclusão da ingestão. A melhor maneira de monitorar o progresso é utilizar a guia "Insights" no portal. Abra a seção do cluster do Azure Data Explorer no portal e vá para 'Monitoramento | Insights'

Você pode usar a seção ' ingestão (visualização) ' com as configurações abaixo para monitorar a ingestão, pois ela está acontecendo
- Intervalo de tempo: últimos 30 minutos
- Examinar com êxito e por tabela
- Se você tiver alguma falha, examine falha e por tabela
Você saberá que a ingestão está concluída quando você vir as métricas ir para 0 para sua tabela. Se você quiser ver mais detalhes, poderá usar o Log Analytics. Na seção cluster de Data Explorer do Azure, selecione na guia ' log ':

Consultas úteis
Entender o esquema se o esquema dinâmico for usado
| project p=treepath(fullrecord)
| mv-expand p
| summarize by tostring(p)
Acessando valores na matriz
| where id_string == "a"
| summarize avg(todouble(fullrecord.['nestedArray_v_double'])) by bin(timestamp, 1s)
| render timechart
Migrando o modelo de série temporal (TSM) para o Azure Data Explorer
O modelo pode ser baixado no formato JSON do ambiente de TSI usando a API do lote do TSI Explorer UX ou do TSM. Em seguida, o modelo pode ser importado para outro sistema, como o Azure Data Explorer.
Baixe o TSM da UX do TSI.
Exclua as três primeiras linhas usando VSCode ou outro editor.
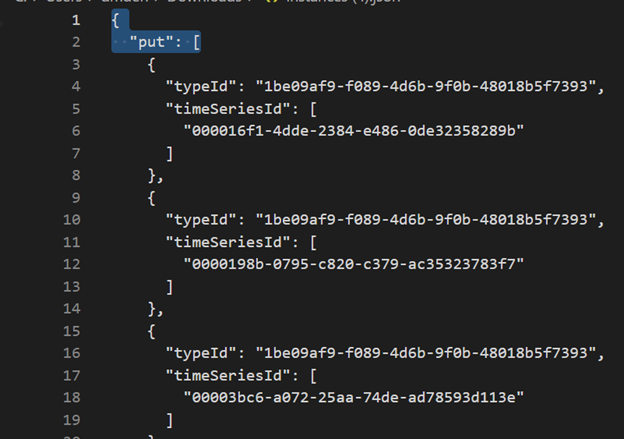
Usando o VSCode ou outro editor, pesquise e substitua como Regex
\},\n \{por}{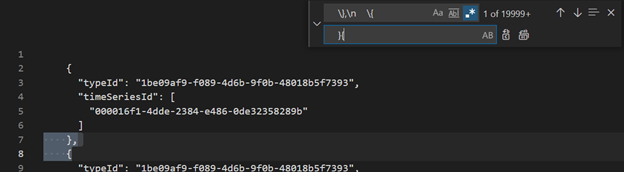
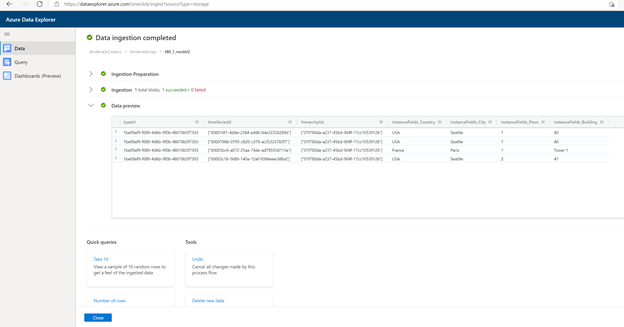
Ingerir como JSON em ADX como uma tabela separada usando Upload da funcionalidade de arquivo.



Traduzir consultas de série temporal (TSQ) para KQL
GetEvents
{
"getEvents": {
"timeSeriesId": [
"assest1",
"siteId1",
"dataId1"
],
"searchSpan": {
"from": "2021-11-01T00:00:0.0000000Z",
"to": "2021-11-05T00:00:00.000000Z"
},
"inlineVariables": {},
}
}
events
| where timestamp >= datetime(2021-11-01T00:00:0.0000000Z) and timestamp < datetime(2021-11-05T00:00:00.000000Z)
| where assetId_string == "assest1" and siteId_string == "siteId1" and dataid_string == "dataId1"
| take 10000
GetEvents com filtro
{
"getEvents": {
"timeSeriesId": [
"deviceId1",
"siteId1",
"dataId1"
],
"searchSpan": {
"from": "2021-11-01T00:00:0.0000000Z",
"to": "2021-11-05T00:00:00.000000Z"
},
"filter": {
"tsx": "$event.sensors.sensor.String = 'status' AND $event.sensors.unit.String = 'ONLINE"
}
}
}
events
| where timestamp >= datetime(2021-11-01T00:00:0.0000000Z) and timestamp < datetime(2021-11-05T00:00:00.000000Z)
| where deviceId_string== "deviceId1" and siteId_string == "siteId1" and dataId_string == "dataId1"
| where ['sensors.sensor_string'] == "status" and ['sensors.unit_string'] == "ONLINE"
| take 10000
GetEvents com variável projetada
{
"getEvents": {
"timeSeriesId": [
"deviceId1",
"siteId1",
"dataId1"
],
"searchSpan": {
"from": "2021-11-01T00:00:0.0000000Z",
"to": "2021-11-05T00:00:00.000000Z"
},
"inlineVariables": {},
"projectedVariables": [],
"projectedProperties": [
{
"name": "sensors.value",
"type": "String"
},
{
"name": "sensors.value",
"type": "bool"
},
{
"name": "sensors.value",
"type": "Double"
}
]
}
}
events
| where timestamp >= datetime(2021-11-01T00:00:0.0000000Z) and timestamp < datetime(2021-11-05T00:00:00.000000Z)
| where deviceId_string== "deviceId1" and siteId_string == "siteId1" and dataId_string == "dataId1"
| take 10000
| project timestamp, sensorStringValue= ['sensors.value_string'], sensorBoolValue= ['sensors.value_bool'], sensorDoublelValue= ['sensors.value_double']
AggregateSeries
{
"aggregateSeries": {
"timeSeriesId": [
"deviceId1"
],
"searchSpan": {
"from": "2021-11-01T00:00:00.0000000Z",
"to": "2021-11-05T00:00:00.0000000Z"
},
"interval": "PT1M",
"inlineVariables": {
"sensor": {
"kind": "numeric",
"value": {
"tsx": "coalesce($event.sensors.value.Double, todouble($event.sensors.value.Long))"
},
"aggregation": {
"tsx": "avg($value)"
}
}
},
"projectedVariables": [
"sensor"
]
}
events
| where timestamp >= datetime(2021-11-01T00:00:00.0000000Z) and timestamp < datetime(2021-11-05T00:00:00.0000000Z)
| where deviceId_string == "deviceId1"
| summarize avgSensorValue= avg(coalesce(['sensors.value_double'], todouble(['sensors.value_long']))) by bin(IntervalTs = timestamp, 1m)
| project IntervalTs, avgSensorValue
AggregateSeries com filtro
{
"aggregateSeries": {
"timeSeriesId": [
"deviceId1"
],
"searchSpan": {
"from": "2021-11-01T00:00:00.0000000Z",
"to": "2021-11-05T00:00:00.0000000Z"
},
"filter": {
"tsx": "$event.sensors.sensor.String = 'heater' AND $event.sensors.location.String = 'floor1room12'"
},
"interval": "PT1M",
"inlineVariables": {
"sensor": {
"kind": "numeric",
"value": {
"tsx": "coalesce($event.sensors.value.Double, todouble($event.sensors.value.Long))"
},
"aggregation": {
"tsx": "avg($value)"
}
}
},
"projectedVariables": [
"sensor"
]
}
}
events
| where timestamp >= datetime(2021-11-01T00:00:00.0000000Z) and timestamp < datetime(2021-11-05T00:00:00.0000000Z)
| where deviceId_string == "deviceId1"
| where ['sensors.sensor_string'] == "heater" and ['sensors.location_string'] == "floor1room12"
| summarize avgSensorValue= avg(coalesce(['sensors.value_double'], todouble(['sensors.value_long']))) by bin(IntervalTs = timestamp, 1m)
| project IntervalTs, avgSensorValue
Migração do conector de Power BI TSI para o conector de Power BI ADX
As etapas manuais envolvidas nesta migração são
- Converter a consulta Power BI em TSQ
- Converter TSQ em KQL Power BI consulta em TSQ: a consulta Power BI copiada do gerenciador de UX do TSI é semelhante à mostrada abaixo
Para dados brutos (API do GetEvents)
{"storeType":"ColdStore","isSearchSpanRelative":false,"clientDataType":"RDX_20200713_Q","environmentFqdn":"6988946f-2b5c-4f84-9921-530501fbab45.env.timeseries.azure.com", "queries":[{"getEvents":{"searchSpan":{"from":"2019-10-31T23:59:39.590Z","to":"2019-11-01T05:22:18.926Z"},"timeSeriesId":["Arctic Ocean",null],"take":250000}}]}
- Para convertê-lo em TSQ, crie um JSON a partir da carga acima. A documentação da API GetEvents também tem exemplos para entender melhor isso. Consulta-execute-API REST (Azure Time Series Insights) | Microsoft Docs
- O TSQ convertido é semelhante ao mostrado abaixo. É a carga JSON dentro de "consultas"
{
"getEvents": {
"timeSeriesId": [
"Arctic Ocean",
"null"
],
"searchSpan": {
"from": "2019-10-31T23:59:39.590Z",
"to": "2019-11-01T05:22:18.926Z"
},
"take": 250000
}
}
Para dados Aggradate (API da série de agregação)
- Para uma única variável embutida, a consulta do PowerBI do Gerenciador de UX do TSI é parecida com a mostrada abaixo:
{"storeType":"ColdStore","isSearchSpanRelative":false,"clientDataType":"RDX_20200713_Q","environmentFqdn":"6988946f-2b5c-4f84-9921-530501fbab45.env.timeseries.azure.com", "queries":[{"aggregateSeries":{"searchSpan":{"from":"2019-10-31T23:59:39.590Z","to":"2019-11-01T05:22:18.926Z"},"timeSeriesId":["Arctic Ocean",null],"interval":"PT1M", "inlineVariables":{"EventCount":{"kind":"aggregate","aggregation":{"tsx":"count()"}}},"projectedVariables":["EventCount"]}}]}
- Para convertê-lo em TSQ, crie um JSON a partir da carga acima. A documentação da API AggregateSeries tem exemplos que ajudam a entender melhor. Consulta-execute-API REST (Azure Time Series Insights) | Microsoft Docs
- O TSQ convertido é semelhante ao mostrado abaixo. É a carga JSON dentro de "consultas"
{
"aggregateSeries": {
"timeSeriesId": [
"Arctic Ocean",
"null"
],
"searchSpan": {
"from": "2019-10-31T23:59:39.590Z",
"to": "2019-11-01T05:22:18.926Z"
},
"interval": "PT1M",
"inlineVariables": {
"EventCount": {
"kind": "aggregate",
"aggregation": {
"tsx": "count()"
}
}
},
"projectedVariables": [
"EventCount",
]
}
}
- Para mais de uma variável embutida, acrescente o JSON em "inlineVariables", conforme mostrado no exemplo abaixo. A consulta de Power BI para mais de uma variável embutida é semelhante a:
{"storeType":"ColdStore","isSearchSpanRelative":false,"clientDataType":"RDX_20200713_Q","environmentFqdn":"6988946f-2b5c-4f84-9921-530501fbab45.env.timeseries.azure.com","queries":[{"aggregateSeries":{"searchSpan":{"from":"2019-10-31T23:59:39.590Z","to":"2019-11-01T05:22:18.926Z"},"timeSeriesId":["Arctic Ocean",null],"interval":"PT1M", "inlineVariables":{"EventCount":{"kind":"aggregate","aggregation":{"tsx":"count()"}}},"projectedVariables":["EventCount"]}}, {"aggregateSeries":{"searchSpan":{"from":"2019-10-31T23:59:39.590Z","to":"2019-11-01T05:22:18.926Z"},"timeSeriesId":["Arctic Ocean",null],"interval":"PT1M", "inlineVariables":{"Magnitude":{"kind":"numeric","value":{"tsx":"$event['mag'].Double"},"aggregation":{"tsx":"max($value)"}}},"projectedVariables":["Magnitude"]}}]}
{
"aggregateSeries": {
"timeSeriesId": [
"Arctic Ocean",
"null"
],
"searchSpan": {
"from": "2019-10-31T23:59:39.590Z",
"to": "2019-11-01T05:22:18.926Z"
},
"interval": "PT1M",
"inlineVariables": {
"EventCount": {
"kind": "aggregate",
"aggregation": {
"tsx": "count()"
}
},
"Magnitude": {
"kind": "numeric",
"value": {
"tsx": "$event['mag'].Double"
},
"aggregation": {
"tsx": "max($value)"
}
}
},
"projectedVariables": [
"EventCount",
"Magnitude",
]
}
}
- Se você quiser consultar os dados mais recentes ("isSearchSpanRelative": true), calcule manualmente o searchSpan conforme mencionado abaixo,
- localize a diferença entre "from" e "to" da carga de Power BI. Vamos chamar essa diferença como "D", onde "D" = "from"-"to"
- Pegue o carimbo de data/hora atual ("T") e subtraia a diferença obtida na primeira etapa. Será novo "from" (F) de searchSpan, em que "F" = "T"-"D"
- Agora, o novo "from" é "F" obtido na etapa 2 e New "to" é "T" (carimbo de data/hora atual)