Tamanhos de máquina virtual da série HBv2
Aplica-se a: ✔️ VMs do Linux ✔️ VMs do Windows ✔️ Conjuntos de dimensionamento flexíveis ✔️ Conjuntos de dimensionamento uniformes
Vários testes de desempenho foram executados em VMs de tamanho da série HBv2. A seguir estão alguns dos resultados desse teste de desempenho.
| Carga de trabalho | HBv2 |
|---|---|
| Tríade de STREAM | 350 GB/s (21-23 GB/s por CCX) |
| Linpack de Alto Desempenho (HPL) | 4 TeraFLOPS (Rpeak, FP64), 8 TeraFLOPS (RMAX, FP32) |
| Largura de banda e latência de RDMA | 1,2 microssegundos, 190 GB/s |
| FIO no SSD NVMe local | 2,7 GB/s leituras, 1,1 GB/s gravações; leituras de IOPS de 102 mil, 115 gravações de IOPS |
| IOR em 8 * SSD Premium do Azure (P40 Managed Disks, RAID0) * * | 1,3 GB/s de leituras, 2,5 GB/gravações; leituras de IOPS de 101 mil, gravações de IOPS de 105 mil |
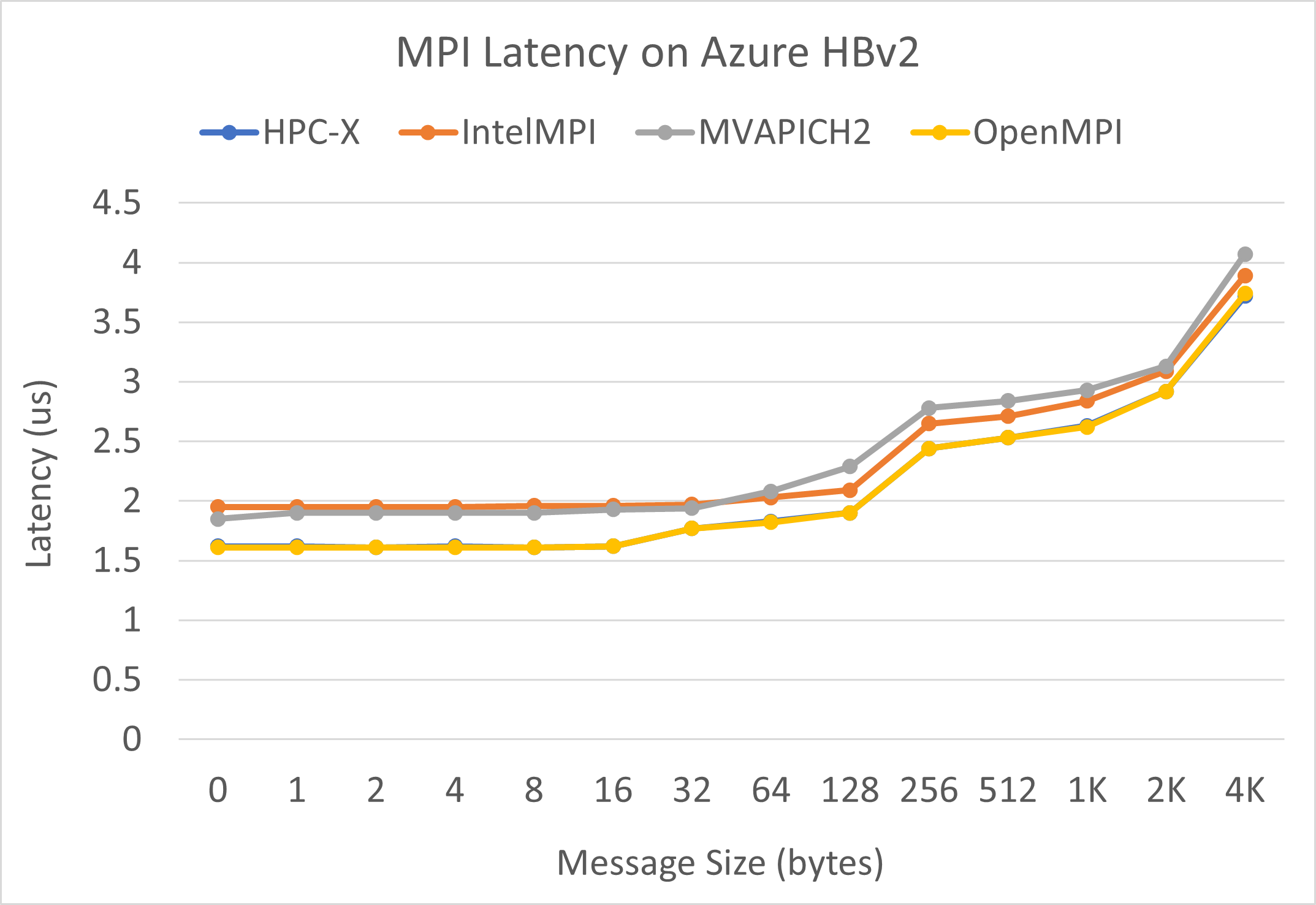
Latência de MPI
O teste de latência de MPI do conjunto de microbenchmarks da OSU é executado. Os scripts de exemplo estão no GitHub.
./bin/mpirun_rsh -np 2 -hostfile ~/hostfile MV2_CPU_MAPPING=[INSERT CORE #] ./osu_latency
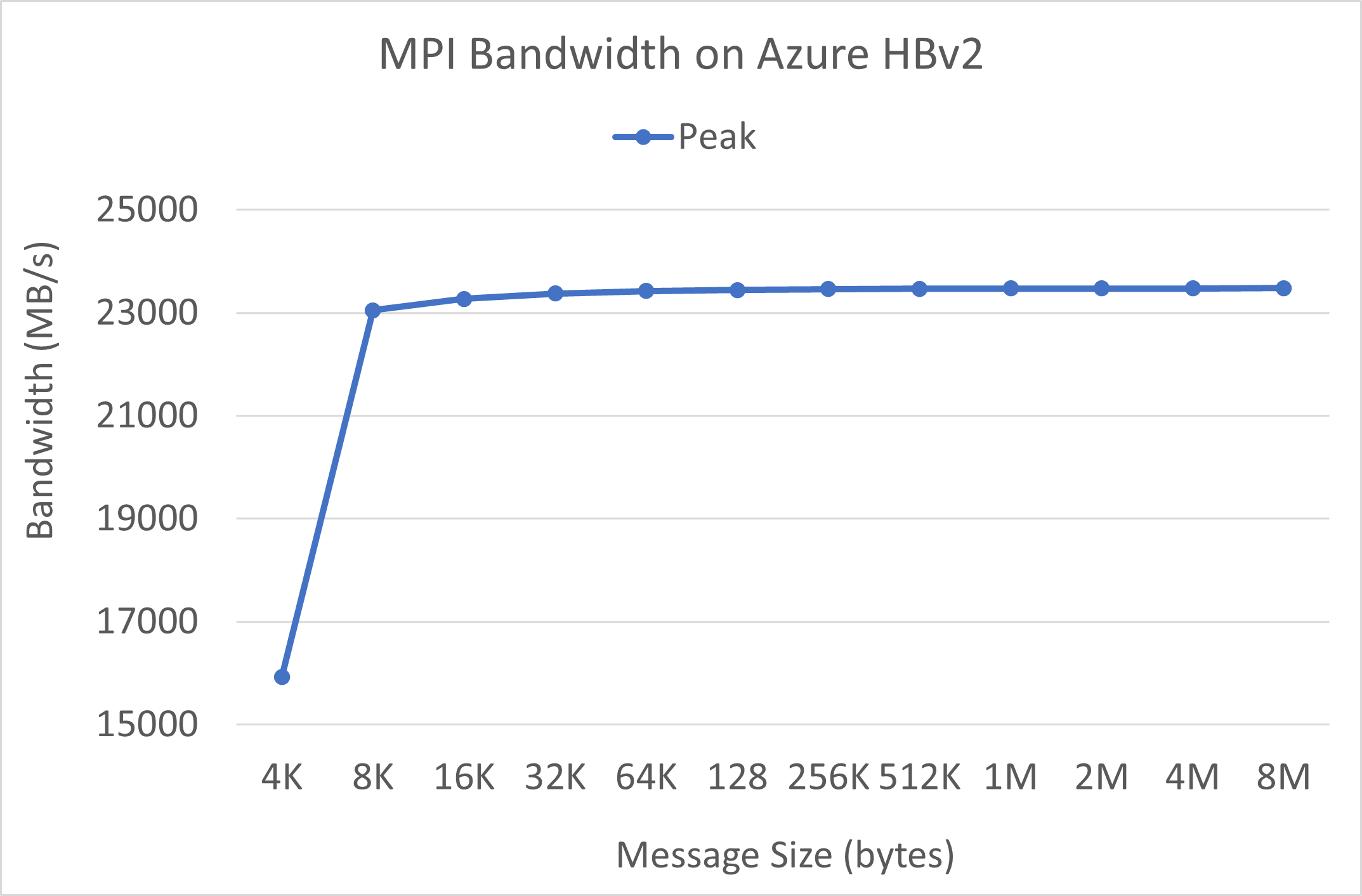
Largura de banda de MPI
O teste de largura de banda de MPI do conjunto de microbenchmarks da OSU é executado. Os scripts de exemplo estão no GitHub.
./mvapich2-2.3.install/bin/mpirun_rsh -np 2 -hostfile ~/hostfile MV2_CPU_MAPPING=[INSERT CORE #] ./mvapich2-2.3/osu_benchmarks/mpi/pt2pt/osu_bw
Mellanox Perftest
O pacote Mellanox Perftest tem muitos testes de InfiniBand, como latência (ib_send_lat) e largura de banda (ib_send_bw). Um comando de exemplo é mostrado abaixo.
numactl --physcpubind=[INSERT CORE #] ib_send_lat -a
Próximas etapas
- Leia informações sobre comunicados mais recentes, exemplos de cargas de trabalho de HPC e resultados de desempenho nos Blogs do programa Tech Groups da Computação do Azure.
- Para obter uma visão de nível superior da arquitetura de execução de cargas de trabalho de HPC, confira HPC (computação de alto desempenho) no Azure.
Comentários
Em breve: Ao longo de 2024, eliminaremos os problemas do GitHub como o mecanismo de comentários para conteúdo e o substituiremos por um novo sistema de comentários. Para obter mais informações, consulte https://aka.ms/ContentUserFeedback.
Enviar e exibir comentários de