Opções de configuração para minimizar a latência de rede com aplicativos SAP
Importante
Em novembro de 2021, fizemos alterações significativas na forma como os grupos de posicionamento de proximidade devem ser usados com a carga de trabalho do SAP em implantações de zona.
Os aplicativos SAP baseados na arquitetura SAP NetWeaver ou SAP S/4HANA são sensíveis à latência de rede entre a camada de aplicativo SAP e a camada de banco de dados SAP. Essa sensibilidade ocorre porque a maior parte da lógica de negócios é executada na camada de aplicativo. Como a camada de aplicativo SAP executa a lógica de negócios, ela emite consultas para a camada de banco de dados em uma alta frequência, a uma taxa de milhares ou dezenas de milhares por segundo. Na maioria dos casos, a natureza dessas consultas é simples. Geralmente, elas podem ser executadas na camada de banco de dados em 500 microssegundos ou menos.
O tempo gasto na rede para enviar tal consulta da camada de aplicativo para a camada de banco de dados e receber o resultado retornado tem um grande impacto no tempo necessário para executar processos de negócios. Essa sensibilidade à latência de rede é o motivo pelo qual você talvez queira atingir determinada latência mínima de rede nos projetos de implantação do SAP. Confira a Nota SAP n.º 1100926 – Perguntas frequentes: desempenho de rede para obter diretrizes sobre como classificar a latência de rede.
Em muitas regiões do Azure, o número de data centers cresceu. Ao mesmo tempo, os clientes, especialmente para sistemas SAP de ponta, estão usando famílias de VMs mais especiais, como a família Mv2 ou Mv3 e mais recentes. Esses tipos de máquina virtual do Azure nem sempre estão disponíveis em cada um dos data centers que são coletados em uma região do Azure. Esses fatos podem criar oportunidades para otimizar a latência de rede entre a camada do aplicativo SAP e a camada de DBMS SAP.
O Azure oferece diferentes opções de implantação para cargas de trabalho SAP. Para o tipo de implantação escolhido você tem opções para otimizar a latência da rede, se necessário. Informações detalhadas sobre cada opção são descritas detalhadamente nas seguintes seções desse artigo:
- Grupos de posicionamento de proximidade
- Conjunto de Dimensionamento de Máquinas Virtuais com Orquestração Flexível
Grupos de posicionamento de proximidade
Grupos de posicionamento de proximidade permitem o agrupamento de diferentes tipos de VM em uma única coluna de rede, garantindo baixa latência de rede ideal entre eles. Quando a primeira VM é implantada no grupo de posicionamento por proximidade, essa VM é associada a uma coluna de rede específica. Como todas as outras VMs que serão implantadas no mesmo grupo de posicionamento de proximidade, essas VMs são agrupadas na mesma lombada de rede. Por ser atrativa que essa perspectiva seja, o uso do constructo também apresenta algumas restrições e armadilhas:
- Você não pode pressupor que todos os tipos de VM do Azure estejam disponíveis em todos os datacenters do Azure ou em cada espinha de rede. Como resultado, a combinação de diferentes tipos de VM dentro de um grupo de posicionamento de proximidade pode ser severamente restrita. Essas restrições ocorrem porque o hardware do host necessário para executar determinado tipo de VM pode não estar presente no datacenter ou na lombada de rede no qual o grupo de posicionamento foi atribuído
- Ao redimensionar as partes das VMs que estão dentro de um grupo de posicionamento por proximidade, você não pode presumir automaticamente que, em todos os casos, o novo tipo de VM esteja disponível no mesmo datacenter ou na espinha de rede em que o grupo de posicionamento por proximidade foi atribuído
- Como o Azure encerra o hardware, ele pode forçar determinadas VMs de um grupo de posicionamento por proximidade em outro datacenter do Azure ou em outra lombada de rede. Para obter detalhes sobre esse caso, leia o documento grupos de posicionamento de proximidade
Importante
.Como resultado das possíveis restrições, os grupos de posicionamento por proximidade devem ser usados somente:
- Quando necessário em determinados cenários (consulte mais adiante)
- Quando a latência de rede entre a camada do aplicativo e a camada do DBMS é muito alta e afeta a carga de trabalho
- Apenas na granularidade de um único sistema SAP e não em um cenário de sistema inteiro ou em uma estrutura SAP completa
- Como uma forma de manter os diferentes tipos e número de VMs em um grupo de posicionamento de proximidade em um mínimo
Os cenários em que os grupos de posicionamento de proximidade podem ser usados para otimizar a latência da rede:
- Você deseja implantar os recursos críticos da sua carga de trabalho SAP em diferentes zonas de disponibilidade e, por outro lado, precisa que as VMs da camada de aplicativo sejam espalhadas por diferentes domínios de falha usando conjuntos de disponibilidade em cada uma das zonas. Nesse caso, conforme descrito posteriormente no documento, os grupos de posicionamento de proximidade são a cola necessária.
- Você implanta a carga de trabalho SAP com conjuntos de disponibilidade. Onde a camada de banco de dados SAP, a camada de aplicativo SAP e as VMs ASCS/SCS são agrupadas em três conjuntos de disponibilidade diferentes. Nesse caso, pretende certificar-se de que os conjuntos de disponibilidade não estão espalhados por toda a região de Azure, uma vez que isto poderia, dependendo da região de Azure, resultar em latência de rede que poderia impactar negativamente a carga de trabalho SAP.
- Você usa grupos de posicionamento de proximidade para agrupar VMs e obter a menor latência de rede possível entre os serviços hospedados nas VMs. Por exemplo, a latência dentro de uma zona de disponibilidade por si só não atende aos requisitos do aplicativo.
Quanto ao cenário de implantação #2, em muitas regiões, especialmente regiões sem zonas de disponibilidade e na maioria das regiões com zonas de disponibilidade, a latência da rede independente de onde as VMs chegam é aceitável. No entanto, existem algumas regiões do Azure que não oferecem uma experiência boa o suficiente sem colocar três conjuntos de disponibilidade diferentes no mesmo local sem usar grupos de posicionamento por proximidade.
O que são grupos de posicionamento por proximidade?
Um grupo de posicionamento por proximidade do Azure é um constructo lógico. Quando um grupo de posicionamento de proximidade é definido, ele é associado a uma região e a um grupo de recursos do Azure. Quando as VMs são implantadas, um grupo de posicionamento por proximidade é referenciado pelo seguinte:
- A primeira VM do Azure implantada em uma lombada de rede com muitas unidades de computação do Azure e baixa latência de rede. Essa lombada de rede geralmente corresponde a um único datacenter do Azure. Você pode considerar a primeira máquina virtual como uma "VM de escopo" implantada em uma unidade de escala de computação baseada em algoritmos de alocação do Azure que são eventualmente combinados com parâmetros de implantação.
- Todas as VMs subsequentes implantadas que fazem referência ao grupo de posicionamento de proximidade serão implantadas na mesma linhagem de rede que a primeira máquina virtual.
Observação
Se não houver nenhum hardware de host implantado que possa executar um tipo de VM específico na espinha da rede em que a primeira VM foi colocada, a implantação do tipo de VM solicitada não terá êxito. Você obterá uma mensagem de falha de alocação que indica que a VM não tem suporte no perímetro do grupo de posicionamento de proximidade.
Para reduzir o risco mencionado, é recomendável usar a opção de intenção ao criar o grupo de posicionamento por proximidade. A opção de intenção permite listar os tipos de VM que você pretende incluir no grupo de posicionamento por proximidade. Essa lista de tipos de VM será usada para encontrar o melhor datacenter que hospede esses tipos de VM. Se esse datacenter for encontrado, o PPG será criado e terá como escopo o datacenter que atende aos requisitos de SKU da VM. Se esse datacenter não for encontrado, a criação do grupo de posicionamento por proximidade falhará. Você pode encontrar mais informações na documentação PPG – Usar a intenção para especificar tamanhos de VM. Lembre-se de que as situações de capacidade reais não são consideradas nas verificações disparadas pela opção de intenção. Como resultado, ainda poderá haver erros de alocação causados pela capacidade insuficiente disponível.
Um único Grupo de recursos do Azure pode ter vários grupos de posicionamento por proximidade atribuídos a ele. Mas um grupo de posicionamento por proximidade pode ser atribuído a apenas um grupo de recursos do Azure.
Para obter mais informações e exemplos de implantação de grupos de posicionamento de proximidade, veja a documentação disponível.
Grupos de posicionamento de proximidade com implantações zonais
É importante fornecer uma latência de rede razoavelmente baixa entre a camada de aplicação SAP e a camada DBMS. Na maioria das situações, apenas uma implantação zonal atende a esse requisito. Para um conjunto limitado de cenários, apenas uma implantação zonal pode não atender aos requisitos de latência do aplicativo. Essas situações exigem o posicionamento da VM o mais próximo possível e permitem latência de rede razoavelmente baixa. Um grupo de posicionamento por proximidade do Azure pode ser definido para esse sistema SAP.
Evite agrupar vários sistemas de produção ou não produção SAP em um único grupo de posicionamento por proximidade. Evite grupos de sistemas SAP, pois quanto mais sistemas você reunir em um grupo de posicionamento por proximidade, maior será a probabilidade:
- Você precisa de um tipo de VM que não esteja disponível na coluna de rede à qual o grupo de posicionamento de proximidade foi atribuído.
- Esses recursos de VMs não convencionais, como as VMs da Série M, podem, eventualmente. não ser atendidos quando você precisar expandir o número de VMs em um grupo de posicionamento de proximidade ao longo do tempo.
Com base em muitas melhorias implementadas pela Microsoft nas regiões do Azure para reduzir a latência da rede dentro de uma zona de disponibilidade do Azure, a orientação de implantação ao utilizar grupos de colocação de proximidade para implementações zonais é semelhante a:
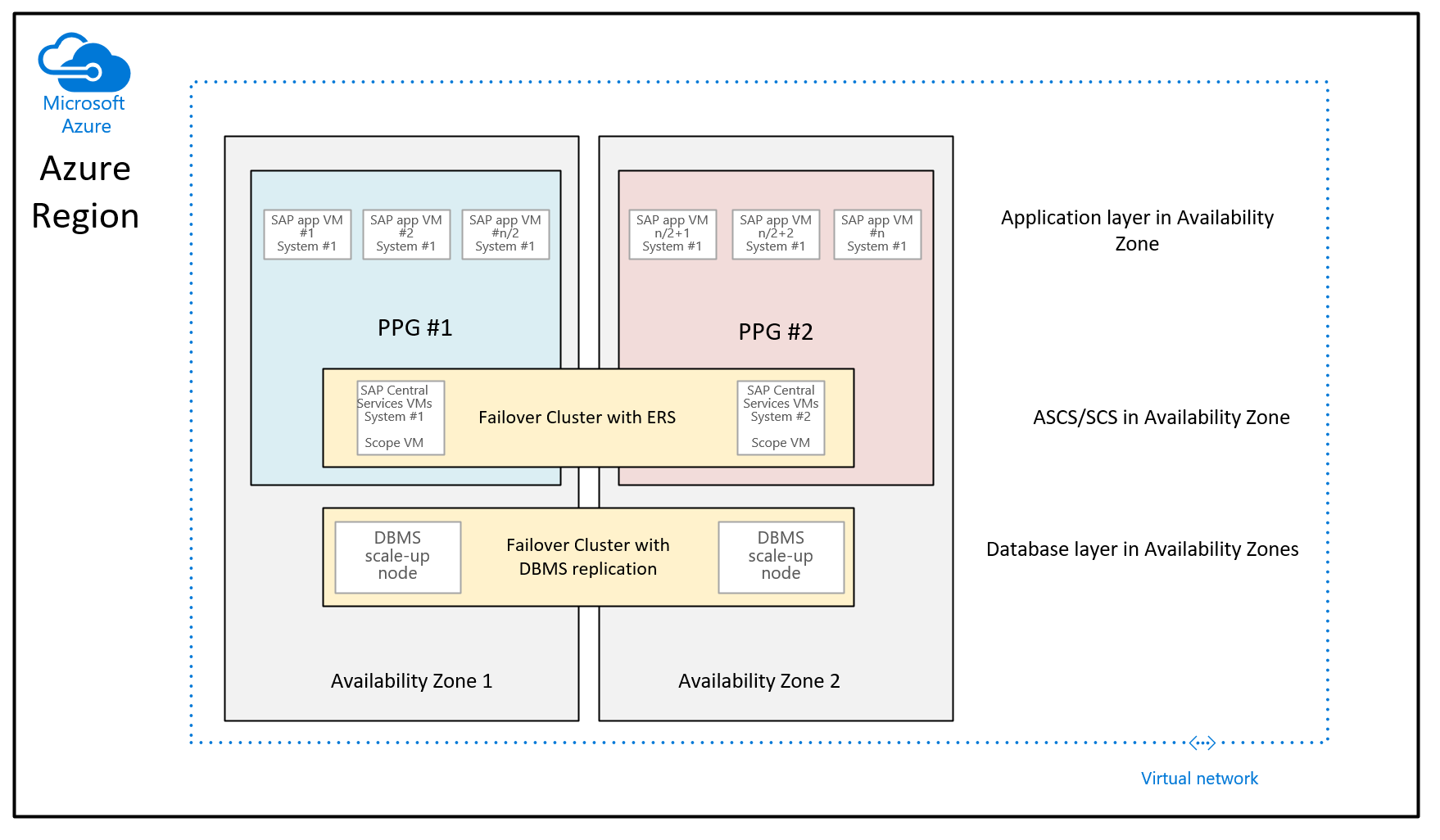
A diferença à recomendação fornecida até agora é que as VMs de banco de dados nas duas zonas não são mais uma parte dos grupos de posicionamento de proximidade. Os grupos de posicionamento de proximidade por zona agora estão no escopo da implantação da VM que executa as instâncias do SAP ASCS/SCS. Isso também significa que, para as regiões onde as zonas de disponibilidade são coletadas por vários datacenters, a instância ASCS/SCS e a camada de aplicativo podem ser executadas em uma coluna de rede e as VMs do banco de dados podem ser executadas em outra coluna de rede. Embora com as melhorias de rede feitas, a latência de rede entre a camada de aplicativo SAP e a camada DBMS ainda deve ser suficiente para obter um desempenho e uma taxa de transferência suficientemente bons. A vantagem dessa nova configuração é que você tem mais flexibilidade no redimensionamento de VMs ou na mudança para novos tipos de VM com a camada DBMS ou/e a camada de aplicativo do sistema SAP.
Para o caso especial de uso do Azure NetApp Files para o ambiente DBMS e a funcionalidade relacionada ao Azure NetApp Files de grupo de volumes de aplicativos do Azure NetApp Files para o SAP HANA e sua necessidade de grupos de posicionamento por proximidade, verifique o documento volumes NFS v4.1 no Azure NetApp Files para SAP HANA.
Grupos de posicionamento por proximidade com implantações de conjunto de disponibilidade
Nesse caso, a finalidade é usar grupos de posicionamento de proximidade para colocar as VMs que são implantadas por meio de diferentes conjuntos de disponibilidade. Nesse cenário de utilização, não está a utilizar uma implantação controlada em diferentes zonas de disponibilidade numa região. Em vez disso, você deseja implantar o sistema SAP usando conjuntos de disponibilidade. Como resultado, você tem pelo menos um conjunto de disponibilidade para as VMs do DBMS, as VMs ASCS/SCS e as VMs da camada de aplicativo. Como não é possível especificar no momento da implantação de uma VM um conjunto de disponibilidade AND uma zona de disponibilidade, você não pode controlar onde as VMs nos diferentes conjuntos de disponibilidade serão alocadas. Isso pode resultar em algumas regiões do Azure que a latência de rede entre diferentes VMs ainda pode ser muito alta para proporcionar uma experiência de desempenho suficientemente boa. Portanto, a arquitetura resultante ficaria assim:
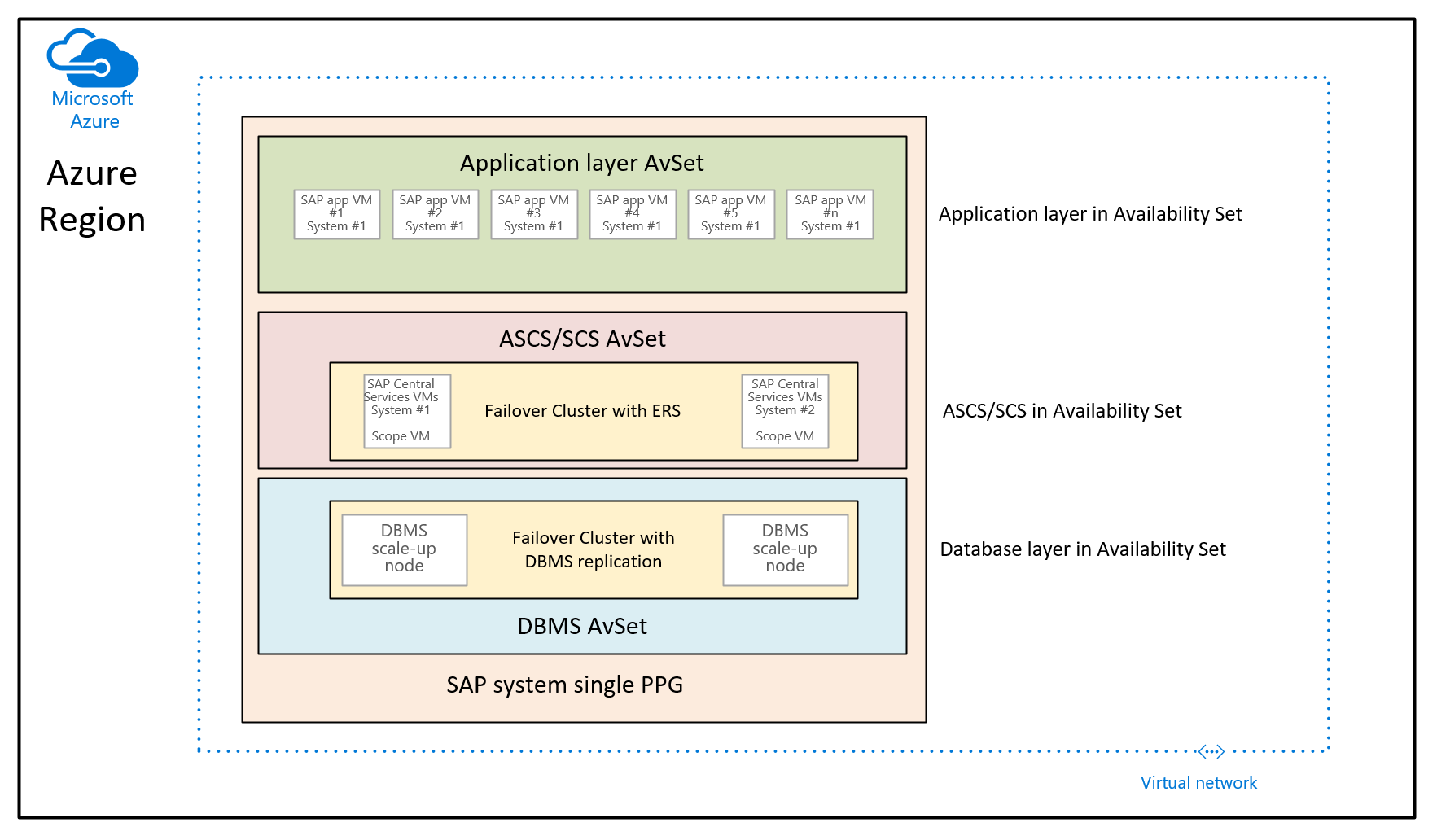
Neste gráfico, um único grupo de posicionamento de proximidade seria atribuído a um único sistema SAP. Este PPG é atribuído aos três conjuntos de disponibilidade. O grupo de posicionamento de proximidade é então definido pela implantação das primeiras VMs da camada de banco de dados no conjunto de disponibilidade do DBMS. Essa recomendação de arquitetura agrupa todas as VMs na mesma coluna de rede. Ela está apresentando as restrições mencionadas neste artigo. Portanto, a arquitetura do grupo de posicionamento de proximidade deve ser usada de forma grosseira.
Combine conjuntos de disponibilidade e zonas de disponibilidade com grupos de posicionamento de proximidade
Um dos problemas de usar zonas de disponibilidade para implantações de sistema SAP é que você não pode implantar a camada de aplicativo SAP usando conjuntos de disponibilidade dentro da zona de disponibilidade específica. Convém que a camada de aplicativo SAP seja implantada nas mesmas zonas que as VMs do SAP ACSC/SCS. Até o momento, não é possível fazer referência a uma zona de disponibilidade e a um conjunto de disponibilidade ao implantar uma única VM. Mas apenas implantando uma VM instruindo uma zona de disponibilidade, você perde a capacidade de garantir que as VMs da camada de aplicativo estejam espalhadas por diferentes domínios de atualização e falha.
Ao usar grupos de posicionamento por proximidade, você pode ignorar essa restrição. Esta é a sequência de implantação:
- Crie um grupo de posicionamento por proximidade.
- Implante sua VM âncora, recomendada como VM ASCS/SCS, referenciando uma zona de disponibilidade.
- Crie um conjunto de disponibilidade que faça referência ao grupo de posicionamento de proximidade do Azure. (Confira o comando mais adiante neste artigo.)
- Implante as VMs da camada de aplicativo referenciando o conjunto de disponibilidade e o grupo de posicionamento por proximidade.
Importante
É importante compreender que não é garantido que os discos das VMs da camada de aplicação sejam alocados na mesma zona de disponibilidade que as VMs são direcionadas para usar o grupo de posicionamento de proximidade. O resultado da implantação mostrada nas próximas etapas pode ser que as VMs sejam alocadas na mesma coluna da rede e, com isso, na mesma zona de disponibilidade da VM âncora. Mas é possível que os discos respectivos (VHD de base e discos de armazenamento do bloco do Azure montados) não estejam alocados na mesma espinha dorsal da rede ou mesmo na mesma zona de disponibilidade. Em vez disso, é possível que os discos dessas VMs sejam alocados em qualquer um dos datacenters da região específica. Embora os discos da VM âncora que foram implantados pela definição de uma zona sejam implantados na mesma zona em que a VM foi implantada.
Em vez de implantar a primeira VM conforme demonstrado na seção anterior, você faz referência a uma zona de disponibilidade e ao grupo de posicionamento de proximidade ao implantar a VM:
New-AzVm -ResourceGroupName "ppgexercise" -Name "centralserviceszone1" -Location "westus2" -OpenPorts 80,3389 -Zone "1" -ProximityPlacementGroup "collocate" -Size "Standard_E8s_v4"
Uma implantação bem-sucedida desta máquina virtual hospedaria a instância ASCS/SCS do sistema SAP em uma zona de disponibilidade. Nesse caso, o VM e o VHD base do VM e os discos de armazenamento de blocos do Azure potencialmente montados são atribuídos dentro da mesma zona de disponibilidade. O escopo do grupo de posicionamento de proximidade é fixado em um dos espinhos da rede na zona de disponibilidade definida.
Na próxima etapa, você precisa criar os conjuntos de disponibilidade que deseja usar para a camada de aplicativo do seu sistema SAP.
Defina e crie o grupo de posicionamento de proximidade. O comando para criar o conjunto de disponibilidade requer uma referência adicional à ID do grupo de posicionamento por proximidade (não o nome). Você pode obter a ID do grupo de posicionamento por proximidade usando este comando:
Get-AzProximityPlacementGroup -ResourceGroupName "ppgexercise" -Name "collocate"
Ao criar o conjunto de disponibilidade, você precisará considerar parâmetros adicionais quando estiver usando discos gerenciados (padrão, a menos que especificado de outra forma) e grupos de posicionamento por proximidade:
New-AzAvailabilitySet -ResourceGroupName "ppgexercise" -Name "ppgavset" -Location "westus2" -ProximityPlacementGroupId "/subscriptions/my very long ppg id string" -sku "aligned" -PlatformUpdateDomainCount 3 -PlatformFaultDomainCount 2
O ideal é que você use três domínios de falha. Mas o número de domínios de falha com suporte pode variar de região para região. Nesse caso, o número máximo de domínios de falha possíveis para as regiões específicas é dois. Para implantar suas VMs de camada de aplicativo, você precisa adicionar uma referência ao nome do conjunto de disponibilidade e ao nome do grupo de posicionamento por proximidade, conforme mostrado aqui:
New-AzVm -ResourceGroupName "ppgexercise" -Name "appinstance1" -Location "westus2" -OpenPorts 80,3389 -AvailabilitySetName "myppgavset" -ProximityPlacementGroup "collocate" -Size "Standard_E16s_v4"
Observação
Os discos das VMs implantados no conjunto de disponibilidade acima não são forçados a serem alocados na mesma zona de disponibilidade que a VM. Embora você tenha conseguido que as VMs da camada de aplicativo estejam espalhadas por diferentes domínios de falha sob a mesma coluna de rede em que a VM âncora está alocada, os discos, embora também alocados em diferentes domínios de falha, podem ser alocados em locais diferentes em um escopo de toda a região.
Essa implantação resulta em:
- Um serviço central para seu sistema SAP localizado em zonas de disponibilidade específicas.
- Uma camada de aplicativo SAP que está localizada por meio de conjuntos de disponibilidade na mesma lombada de rede que a VM ou VMs dos serviços centrais do SAP (ASCS/SCS).
Observação
Como você implanta uma VM do DBMS e ASCS/SCS em uma zona e a segunda VM do DBMS e ASCS/SCS em outra zona para criar uma configuração de alta disponibilidade, você precisará de um grupo de posicionamento por proximidade diferente para cada uma das zonas. O mesmo vale para qualquer conjunto de disponibilidade que você usar.
Alterar as configurações de grupo de posicionamento de proximidade de um sistema existente
Se você implementou grupos de posicionamento de proximidade a partir das recomendações fornecidas até o momento e deseja ajustar para a nova configuração, você pode fazer isso com os métodos descritos nestes artigos:
- Implantar VMs nos grupos de posicionamento por proximidade usando a CLI do Azure
- Implantar VMs nos grupos de posicionamento por proximidade usando o PowerShell
Você também pode usar esses comandos para casos em que está obtendo erros de alocação quando onde não é possível mudar para um novo tipo de VM com uma VM existente no grupo de posicionamento por proximidade.
Conjunto de Dimensionamento de Máquinas Virtuais com Orquestração flexível
Para evitar as limitações associadas ao grupo de posicionamento por proximidade, é recomendável implantar a carga de trabalho SAP nas zonas de disponibilidade usando um conjunto de dimensionamento flexível com FD=1. Essa estratégia de implantação garante que as VMs implantadas em cada zona não sejam restritas a um único datacenter ou coluna de rede, e todos os componentes do sistema SAP, como bancos de dados, ASCS/ERS e camada de aplicativo, estejam no escopo de uma zona. Com todos os componentes do sistema SAP sendo definidos no nível zonal, a latência de rede entre diferentes componentes de um único sistema SAP deve ser suficiente para garantir o desempenho e taxa de transferência satisfatórios. O principal benefício dessa nova opção de implantação com um conjunto de dimensionamento flexível com FD=1 é que ela fornece maior flexibilidade no redimensionamento das VMs ou na mudança para novos tipos de VM para todas as camadas do sistema SAP. Além disso, o conjunto de dimensionamento alocaria as VMs em vários domínios de falha em uma única zona, o que é ideal para executar várias VMs da camada de aplicativo em cada zona. Para obter mais informações, consulte o documento conjunto de dimensionamento de máquinas virtuais para a carga de trabalho SAP.

Em um ambiente de não produção ou não HA, é possível implantar todos os componentes do sistema SAP, incluindo o banco de dados, ASCS e camada de aplicativo, em uma única zona usando um conjunto de dimensionamento flexível com FD=1.
Opções de implantação recomendadas anteriormente
Essa seção inclui detalhes sobre as opções de implantação recomendadas anteriormente para otimizar a latência da rede para SAP. Com os novos recursos e o crescimento do Azure ao longo do tempo, os detalhes desta seção só devem ser aplicados em casos raros.
Grupos de posicionamento de proximidade para todo o sistema SAP com implantações zonais
O uso do grupo de posicionamento de proximidade que recomendamos até agora é mostrado nesse gráfico.

Você cria um grupo de posicionamento de proximidade (PPG) em cada uma das duas zonas de disponibilidade nas quais você implantou seu sistema SAP. Todas as VMs de uma zona específica fazem parte do grupo de posicionamento por proximidade individual dessa zona. Você começa em cada zona com a implantação da VM DBMS para definir o escopo do PPG e, em seguida, implanta a VM ASCS na mesma zona e PPG. Em uma terceira etapa, cria-se um conjunto de disponibilidade do Azure, atribui-se o conjunto de disponibilidade ao PPG com âmbito e implementa-se nele a camada de aplicação SAP. A vantagem dessa configuração é que todos os componentes estão perfeitamente alinhados sob a mesma coluna de rede. A grande desvantagem é que sua flexibilidade no redimensionamento de máquinas virtuais pode ser limitada.
Com base em muitas melhorias implantadas pela Microsoft nas regiões do Azure para reduzir a latência da rede dentro de uma zona de disponibilidade do Azure, existe a atual orientação de implantação para implantações zonais nesse artigo.
Grupos de posicionamento por proximidade e Grandes instâncias HANA
Se alguns dos seus sistemas SAP dependem de HANA Large Instances para a camada de banco de dados, você poderá experimentar melhorias significativas na latência da rede entre a unidade HANA Large Instances e as VMs do Azure quando estiver usando unidades HANA Large Instances que são implantadas em Revisão 4 linhas ou carimbos.. Uma melhoria é que as unidades de Grandes instâncias HANA são implementadas com um grupo de posicionamento por proximidade. Você pode usar esse grupo de posicionamento por proximidade para implantar suas VMs de camada de aplicativo. Como resultado, essas VMs serão implantadas no mesmo datacenter que hospeda sua unidade de Grandes instâncias HANA.
Para determinar se a unidade de Grandes instâncias HANA está implantada em uma linha ou selo da Revisão 4, confira o artigo Controle de Grandes instâncias HANA do Azure por meio do portal do Azure. Na visão geral dos atributos de sua unidade de Grandes instâncias HANA, você também pode determinar o nome do grupo de posicionamento por proximidade porque ele foi criado quando a unidade de Grandes instâncias HANA foi implantada. O nome que aparece na visão geral dos atributos é o nome do grupo de posicionamento por proximidade no qual você deve implantar suas VMs de camada de aplicativo.
Em comparação com os sistemas SAP que usam apenas máquinas virtuais do Azure, quando você usa Grandes instâncias HANA, tem menos flexibilidade para decidir quantos Grupos de recursos do Azure devem ser usados. Todas as unidades de Grandes instâncias HANA de um Locatário de Grandes instâncias HANA são agrupadas em um único grupo de recursos, conforme descrito neste artigo. A menos que você implante em locatários diferentes para separar, por exemplo, sistemas de produção e de não produção ou outros sistemas, todas as suas unidades de Grandes instâncias HANA serão implantadas em um locatário de Grandes instâncias HANA. Esse locatário tem uma relação um-para-um com um grupo de recursos. Mas um grupo de posicionamento por proximidade separado será definido para cada uma das unidades individuais.
Como resultado, as relações entre grupos de recursos do Azure e grupos de posicionamento por proximidade para um único locatário serão mostradas aqui:

Próximas etapas
Confira a documentação de referência:
- Carga de trabalho SAP no Azure: lista de verificação de planejamento e implantação
- Implantar VMs em grupos de posicionamento por proximidade usando a CLI do Azure
- Implantar VMs em grupos de posicionamento por proximidade usando o PowerShell
- Considerações para Implantação do DBMS de Máquinas Virtuais do Azure para cargas de trabalho do SAP
Comentários
Em breve: Ao longo de 2024, eliminaremos os problemas do GitHub como o mecanismo de comentários para conteúdo e o substituiremos por um novo sistema de comentários. Para obter mais informações, consulte https://aka.ms/ContentUserFeedback.
Enviar e exibir comentários de