Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Dica
Esse conteúdo é um trecho do eBook, Architecting Cloud Native .NET Applications for Azure, disponível no .NET Docs ou como um PDF para download gratuito que pode ser lido offline.

Pare o que você está fazendo e peça aos seus colegas que definam o termo "Nativo de Nuvem". Há uma boa chance de você ter várias respostas diferentes.
Vamos começar com uma definição simples:
A arquitetura e as tecnologias nativas de nuvem são uma abordagem para projetar, construir e operar cargas de trabalho que são criadas na nuvem e aproveitam ao máximo o modelo de computação em nuvem.
O Cloud Native Computing Foundation fornece a definição oficial:
As tecnologias nativas de nuvem capacitam as organizações a criar e executar aplicativos escalonáveis em ambientes modernos e dinâmicos, como nuvens públicas, privadas e híbridas. Contêineres, malhas de serviço, microsserviços, infraestrutura imutável e APIs declarativas exemplificam essa abordagem.
Essas técnicas permitem sistemas flexívelmente acoplados que são resilientes, gerenciáveis e observáveis. Combinados com uma automação robusta, eles permitem que os engenheiros façam alterações de alto impacto com frequência e previsibilidade com trabalho mínimo.
A nuvem nativa é sobre velocidade e agilidade. Os sistemas de negócios estão evoluindo da habilitação de recursos de negócios para armas de transformação estratégica que aceleram a velocidade e o crescimento dos negócios. É imperativo colocar novas ideias no mercado imediatamente.
Ao mesmo tempo, os sistemas de negócios também se tornaram cada vez mais complexos, com os usuários exigindo mais. Eles esperam capacidade de resposta rápida, recursos inovadores e tempo de inatividade zero. Problemas de desempenho, erros recorrentes e a incapacidade de se mover rapidamente não são mais aceitáveis. Seus usuários visitarão seu concorrente. Os sistemas nativos de nuvem foram projetados para adotar mudanças rápidas, grandes escalas e resiliência.
Aqui estão algumas empresas que implementaram técnicas nativas de nuvem. Pense na velocidade, agilidade e escalabilidade que eles alcançaram.
| Empresa | Experiência |
|---|---|
| Netflix | Tem mais de 600 serviços em produção. Implanta 100 vezes por dia. |
| Uber | Tem mais de mil serviços em produção. Implanta milhares de vezes por semana. |
| Tem mais de 3.000 serviços em produção. Realiza 1.000 implantações por dia. |
Como você pode ver, Netflix, Uber e WeChat expõem sistemas nativos de nuvem que consistem em muitos serviços independentes. Esse estilo arquitetônico permite que eles respondam rapidamente às condições do mercado. Eles atualizam instantaneamente pequenas áreas de um aplicativo dinâmico e complexo, sem uma reimplantação completa. Eles dimensionam individualmente os serviços conforme necessário.
Os pilares da nuvem nativa
A velocidade e a agilidade da nuvem nativa derivam de muitos fatores. O principal é a infraestrutura de nuvem. Mas há mais: cinco outros pilares fundamentais mostrados na Figura 1-3 também fornecem a base para sistemas nativos de nuvem.
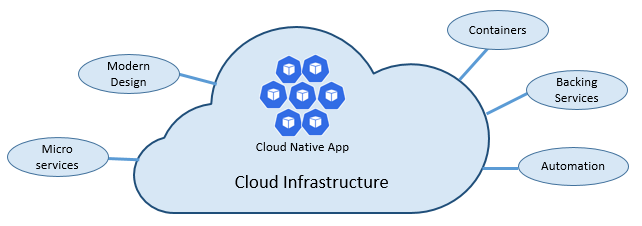
Figura 1-3. Pilares fundamentais nativos da nuvem
Vamos levar algum tempo para entender melhor o significado de cada pilar.
A nuvem
Os sistemas nativos de nuvem aproveitam ao máximo o modelo de serviço de nuvem.
Projetados para prosperar em um ambiente de nuvem dinâmico e virtualizado, esses sistemas fazem uso extensivo da infraestrutura de computação de PaaS (Plataforma como Serviço) e dos serviços gerenciados. Eles tratam a infraestrutura subjacente como descartável, provisionada em minutos e redimensionada, escalada ou destruída sob demanda, por meio de automatização.
Considere a diferença entre como tratamos animais de estimação e mercadorias. Em um data center tradicional, os servidores são tratados como animais de estimação: uma máquina física, dado um nome significativo e cuidado. Você dimensiona adicionando mais recursos ao mesmo computador (escala vertical). Se o servidor ficar doente, você cuidará dele de volta à saúde. Se o servidor ficar indisponível, todos percebem.
O modelo de serviço de mercadorias é diferente. Você provisiona cada instância como uma máquina virtual ou contêiner. Eles são idênticos e recebem um identificador do sistema, como o Service-01, o Service-02 e assim por diante. Você dimensiona criando mais instâncias (escalar horizontalmente). Ninguém percebe quando uma instância fica indisponível.
O modelo de commodities abraça a infraestrutura imutável. Os servidores não são reparados ou modificados. Se um falhar ou exigir atualização, ele será destruído e um novo será provisionado – tudo feito por meio da automação.
Os sistemas nativos de nuvem adotam o modelo de serviço de commodities. Eles continuam a ser executados à medida que a infraestrutura é dimensionada ou reduzida horizontalmente, sem levar em conta os computadores nos quais eles estão em execução.
A plataforma de nuvem do Azure dá suporte a esse tipo de infraestrutura altamente elástica com recursos automáticos de dimensionamento, autorrecuperação e monitoramento.
Design moderno
Como você projetaria um aplicativo nativo de nuvem? Como seria sua arquitetura? A quais princípios, padrões e práticas recomendadas você seguiria? Qual infraestrutura e preocupações operacionais seriam importantes?
O aplicativo Twelve-Factor
Uma metodologia amplamente aceita para construir aplicativos baseados em nuvem é o aplicativoTwelve-Factor. Ele descreve um conjunto de princípios e práticas que os desenvolvedores seguem para construir aplicativos otimizados para ambientes de nuvem modernos. Atenção especial é dada à portabilidade entre ambientes e automação declarativa.
Embora aplicável a qualquer aplicativo baseado na Web, muitos profissionais consideram Twelve-Factor uma base sólida para a criação de aplicativos nativos de nuvem. Os sistemas baseados nesses princípios podem implantar e dimensionar rapidamente e adicionar recursos para reagir rapidamente às mudanças de mercado.
A tabela a seguir destaca a metodologia Twelve-Factor:
| Fator | Explicação |
|---|---|
| 1 – Base de código | Uma única base de código para cada microsserviço, armazenada em seu próprio repositório. Acompanhado com controle de versão, ele pode ser implantado em vários ambientes (QA, Preparo, Produção). |
| 2 – Dependências | Cada microsserviço isola e empacota suas próprias dependências, adotando alterações sem afetar todo o sistema. |
| 3 – Configurações | As informações de configuração são movidas para fora do microsserviço e externalizadas por meio de uma ferramenta de gerenciamento de configuração fora do código. A mesma implantação pode se propagar entre ambientes com a configuração correta aplicada. |
| 4 – Serviços de Backup | Os recursos auxiliares (armazenamentos de dados, caches, agentes de mensagens) devem ser expostos por meio de uma URL endereçável. Isso desassocia o recurso do aplicativo, permitindo que ele seja intercambiável. |
| 5 – Compilar, liberar, executar | Cada versão deve impor uma separação estrita entre os estágios de build, versão e execução. Cada uma deve ser marcada com uma ID exclusiva e dar suporte à capacidade de reversão. Os sistemas modernos de CI/CD ajudam a atender a esse princípio. |
| 6 – Processos | Cada microsserviço deve ser executado em seu próprio processo, isolado de outros serviços em execução. Externalize o estado necessário para um serviço de backup, como um cache distribuído ou armazenamento de dados. |
| 7 – Associação de porta | Cada microsserviço deve ser independente com suas interfaces e funcionalidades expostas em sua própria porta. Isso fornece isolamento de outros microsserviços. |
| 8 – Concorrência | Quando a capacidade precisar aumentar, escale os serviços horizontalmente em vários processos idênticos (cópias) em vez de escalar verticalmente uma única instância grande no computador mais poderoso disponível. Desenvolva o aplicativo para ser simultâneo, fazendo o dimensionamento contínuo em ambientes de nuvem. |
| 9 – Descartabilidade | As instâncias de serviço devem ser descartáveis. Favoreça a inicialização rápida para aumentar as oportunidades de escalabilidade e desligamentos normalizados para deixar o sistema em um estado correto. Os contêineres do Docker, juntamente com um orquestrador, satisfazem inerentemente esse requisito. |
| 10 – Paridade Desenvolvimento/Produção | Mantenha os ambientes em todo o ciclo de vida do aplicativo da maneira mais semelhante possível, evitando atalhos caros. Aqui, a adoção de contêineres pode contribuir muito promovendo o mesmo ambiente de execução. |
| 11 – Registro em log | Trate os logs gerados por microsserviços como fluxos de eventos. Processe-os com um agregador de eventos. Propague dados de log para ferramentas de gerenciamento de log/mineração de dados, como o Azure Monitor ou o Splunk, e, eventualmente, para arquivamento de longo prazo. |
| 12 – Processos de administração | Execute tarefas administrativas/de gerenciamento, como limpeza de dados ou análise de computação, como processos pontuais. Use ferramentas independentes para invocar essas tarefas do ambiente de produção, mas separadamente do aplicativo. |
No livro Beyond the Twelve-Factor App, o autor Kevin Hoffman detalha cada um dos 12 fatores originais (escritos em 2011). Além disso, ele discute três fatores extras que refletem o design de aplicativo de nuvem moderno de hoje.
| Novo Fator | Explicação |
|---|---|
| 13 – API Primeiro | Torne tudo um serviço. Suponha que seu código será consumido por um cliente front-end, gateway ou outro serviço. |
| 14 – Telemetria | Em uma estação de trabalho, você tem uma visibilidade profunda do seu aplicativo e seu comportamento. Na nuvem, você não precisa se preocupar. Verifique se seu design inclui a coleta de dados de monitoramento, específicos do domínio e de saúde/sistema. |
| 15 – Autenticação/Autorização | Implemente a identidade desde o início. Considere os recursos RBAC (controle de acesso baseado em função) disponíveis em nuvens públicas. |
Vamos nos referir a muitos dos mais de 12 fatores neste capítulo e ao longo do livro.
Azure Well-Architected Framework
Projetar e implantar cargas de trabalho baseadas em nuvem pode ser desafiador, especialmente ao implementar a arquitetura nativa de nuvem. A Microsoft fornece as melhores práticas padrão do setor para ajudar você e sua equipe a fornecer soluções de nuvem robustas.
O Microsoft Well-Architected Framework fornece um conjunto de princípios orientadores que podem ser usados para melhorar a qualidade de uma carga de trabalho nativa de nuvem. A estrutura consiste em cinco pilares de excelência de arquitetura:
| Princípios | Descrição |
|---|---|
| Gerenciamento de Custos | Concentre-se na geração de valor incremental antecipadamente. Aplique os princípios Build-Measure-Learn para acelerar o tempo de lançamento no mercado, evitando soluções com uso intensivo de capital. Usando uma estratégia de pagamento conforme o uso, invista à medida que escalar, em vez de fazer um grande investimento inicial. |
| Excelência operacional | Automatize o ambiente e as operações para aumentar a velocidade e reduzir o erro humano. Reverta ou propague atualizações de problemas rapidamente. Implemente o monitoramento e o diagnóstico desde o início. |
| Eficiência do desempenho | Atenda com eficiência às demandas colocadas em suas cargas de trabalho. Favoreça o escalonamento horizontal e incorpore-o ao projetar seus sistemas. Realize continuamente testes de carga e desempenho para identificar possíveis gargalos. |
| Confiabilidade | Crie cargas de trabalho resilientes e disponíveis. A resiliência permite que as cargas de trabalho se recuperem de falhas e continuem funcionando. A disponibilidade garante que os usuários acessem sua carga de trabalho o tempo todo. Crie aplicativos para esperar falhas e se recuperar deles. |
| Segurança | Implemente a segurança em todo o ciclo de vida de um aplicativo, desde design e implementação até implantação e operações. Preste muita atenção ao gerenciamento de identidades, ao acesso à infraestrutura, à segurança do aplicativo e à soberania de dados e à criptografia. |
Para começar, a Microsoft fornece um conjunto de avaliações online para ajudá-lo a avaliar suas cargas de trabalho de nuvem atuais em relação aos cinco pilares bem projetados.
Microsserviços
Os sistemas nativos de nuvem adotam microsserviços, um estilo de arquitetura popular para construir aplicativos modernos.
Criados como um conjunto distribuído de serviços pequenos e independentes que interagem por meio de uma malha compartilhada, os microsserviços compartilham as seguintes características:
Cada um implementa uma funcionalidade de negócios específica em um contexto de domínio maior.
Cada um é desenvolvido de forma autônoma e pode ser implantado de forma independente.
Cada um deles é autossuficiente e encapsula sua própria tecnologia de armazenamento de dados, dependências e plataforma de programação.
Cada um é executado em seu próprio processo e se comunica com outras pessoas usando protocolos de comunicação padrão, como HTTP/HTTPS, gRPC, WebSockets ou AMQP.
Eles compõem juntos para formar um aplicativo.
A Figura 1-4 contrasta uma abordagem de aplicativo monolítico com uma abordagem de microsserviços. Observe como o monólito é composto por uma arquitetura em camadas, que é executada em um único processo. Normalmente, ele consome um banco de dados relacional. No entanto, a abordagem de microsserviço segrega a funcionalidade em serviços independentes, cada um com sua própria lógica, estado e dados. Cada microsserviço hospeda seu próprio armazenamento de dados.
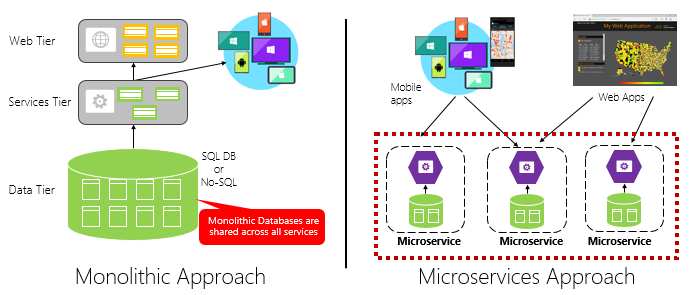
Figura 1-4. Arquitetura monolítica versus microsserviços
Observe como os microsserviços promovem o princípio processos do aplicativoTwelve-Factor, discutido anteriormente no capítulo.
O fator nº 6 especifica "Cada microsserviço deve ser executado em seu próprio processo, isolado de outros serviços em execução".
Por que microsserviços?
Os microsserviços oferecem agilidade.
No início do capítulo, comparamos um aplicativo eCommerce criado como um monolito com esse com microsserviços. No exemplo, vimos alguns benefícios claros:
Cada microsserviço tem um ciclo de vida autônomo e pode evoluir independentemente e implantar com frequência. Você não precisa aguardar uma versão trimestral para implantar um novo recurso ou atualização. Você pode atualizar uma pequena área de um aplicativo dinâmico com menos risco de interromper todo o sistema. A atualização pode ser feita sem uma reimplantação completa do aplicativo.
Cada microsserviço pode ser dimensionado de forma independente. Em vez de dimensionar todo o aplicativo como uma única unidade, você dimensiona apenas os serviços que exigem mais poder de processamento para atender aos níveis de desempenho desejados e aos contratos de nível de serviço. O dimensionamento refinado fornece maior controle do seu sistema e ajuda a reduzir os custos gerais à medida que você dimensiona partes do seu sistema, não tudo.
Um excelente guia de referência para entender os microsserviços é o .NET Microsserviços: arquitetura para aplicativos .NET em contêineres. O livro se aprofunda no design e na arquitetura dos microsserviços. É um complemento para uma arquitetura de referência completa de microsserviços, disponível para download gratuito na Microsoft.
Desenvolvendo microsserviços
Os microsserviços podem ser criados em qualquer plataforma de desenvolvimento moderna.
A plataforma Microsoft .NET é uma excelente opção. Gratuito e de software livre, ele tem muitos recursos internos que simplificam o desenvolvimento de microsserviços. O .NET é multiplataforma. Os aplicativos podem ser criados e executados no Windows, macOS e na maioria dos tipos do Linux.
O .NET tem um desempenho alto e tem pontuado bem em comparação com Node.js e outras plataformas concorrentes. Curiosamente, o TechEmpower conduziu um amplo conjunto de parâmetros de comparação de desempenho em várias plataformas e estruturas de aplicativos Web. O .NET marcou entre os 10 primeiros - bem acima de Node.js e outras plataformas concorrentes.
O .NET é mantido pela Microsoft e pela comunidade do .NET no GitHub.
Desafios de microsserviço
Embora os microsserviços nativos de nuvem distribuídos possam fornecer imensa agilidade e velocidade, eles apresentam muitos desafios:
Comunicação
Como os aplicativos cliente front-end se comunicarão com os microsserviços principais do back-end? Você permitirá a comunicação direta? Ou pode abstrair os microsserviços de back-end com uma fachada de gateway que fornece flexibilidade, controle e segurança?
Como os microsserviços principais de back-end se comunicarão entre si? Você permitirá chamadas HTTP diretas que podem aumentar o acoplamento e afetar o desempenho e a agilidade? Ou poderá considerar o sistema de mensagens desacoplado com tecnologias de fila e tópico?
A comunicação é abordada no capítulo padrões de comunicação nativos de nuvem .
Resiliência
Uma arquitetura de microsserviços transforma a comunicação do seu sistema de rede de dentro do processo para fora do processo. Em uma arquitetura distribuída, o que acontece quando o Serviço B não está respondendo a uma chamada de rede do Serviço A? Ou o que acontece quando o Serviço C fica temporariamente indisponível e outros serviços que o chamam ficam bloqueados?
A resiliência é abordada no capítulo de resiliência nativa da nuvem .
Dados Distribuídos
Por design, cada microsserviço encapsula seus próprios dados, expondo operações por meio de sua interface pública. Em caso afirmativo, como consultar dados ou implementar uma transação em vários serviços?
Os dados distribuídos são abordados no capítulo padrões de dados nativos da nuvem .
Segredos
Como seus microsserviços armazenarão e gerenciarão com segurança segredos e dados confidenciais de configuração?
Os segredos são abordados em detalhes sobre a segurança nativa da nuvem.
Gerenciar a complexidade com o Dapr
O Dapr é um runtime de aplicativo de software livre distribuído. Por meio de uma arquitetura de componentes conectáveis, ele simplifica drasticamente o encanamento por trás de aplicativos distribuídos. Ele fornece uma cola dinâmica que une seu aplicativo a recursos e componentes de infraestrutura predefinidos do runtime do Dapr. A Figura 1-5 mostra Dapr a partir de 20.000 pés.
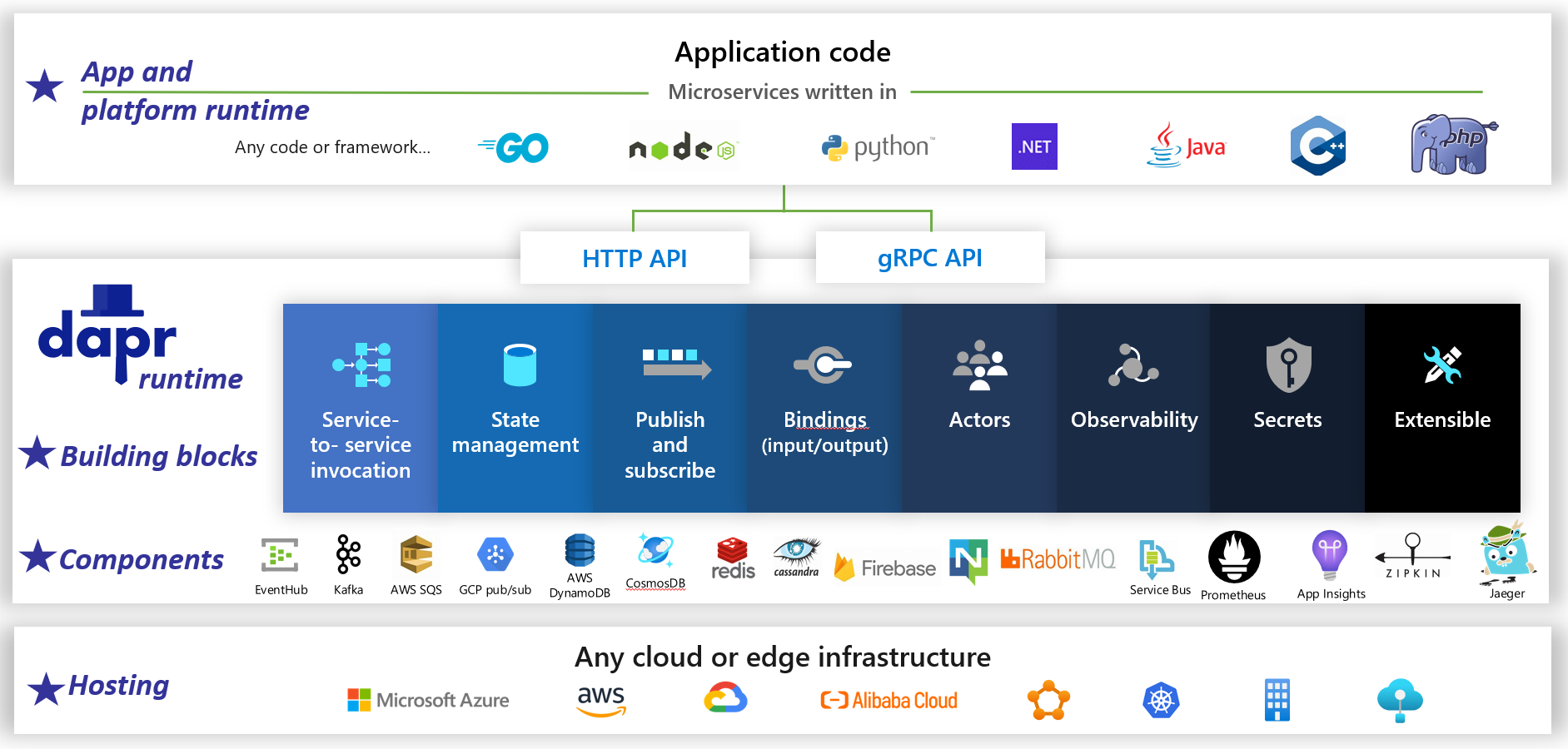 Figura 1-5. Dapr a 20 mil pés.
Figura 1-5. Dapr a 20 mil pés.
Na linha superior da figura, observe como o Dapr fornece SDKs específicos para linguagem para plataformas de desenvolvimento populares. O Dapr v1 inclui suporte para .NET, Go, Node.js, Python, PHP, Java e JavaScript.
Embora os SDKs específicos à linguagem aprimorem a experiência do desenvolvedor, o Dapr é independente da plataforma. Nos bastidores, o modelo de programação do Dapr expõe os recursos por meio de protocolos de comunicação HTTP/gRPC padrão. Qualquer plataforma de programação pode chamar o Dapr por meio de suas APIs HTTP e gRPC nativas.
As caixas azuis no centro da figura representam os blocos de construção Dapr. Cada um expõe o código de encanamento pré-criado a uma funcionalidade de aplicativo distribuído que seu aplicativo pode consumir.
A linha de componentes representa um grande conjunto de componentes de infraestrutura predefinidos que seu aplicativo pode consumir. Pense em componentes como código de infraestrutura que você não precisa escrever.
A linha inferior destaca a portabilidade do Dapr e os diversos ambientes nos quais ele pode ser executado.
Olhando para frente, o Dapr tem o potencial de ter um impacto profundo no desenvolvimento de aplicativos nativos de nuvem.
Contêineres
É natural ouvir o termo contêiner mencionado em qualquer conversa sobre nativo de nuvem. No livro, Cloud Native Patterns, a autora Cornelia Davis observa que, "Os contêineres são um grande habilitador de software nativo de nuvem". O Cloud Native Computing Foundation coloca a contêinerização de microsserviços como a primeira etapa em seus Cloud-Native Trail Map – diretrizes para empresas que iniciam sua jornada nativa de nuvem.
{kind=link}
A conteinerização de um microsserviço é simples e direta. O código, suas dependências e o tempo de execução são empacotados em um binário chamado imagem de contêiner. As imagens são armazenadas em um registro de contêiner, que atua como um repositório ou biblioteca para imagens. Um registro pode estar localizado em seu computador de desenvolvimento, em seu data center ou em uma nuvem pública. O próprio Docker mantém um registro público por meio do Hub do Docker. A nuvem do Azure apresenta um registro de contêiner privado para armazenar imagens de contêiner próximas aos aplicativos de nuvem que as executarão.
Quando um aplicativo é iniciado ou dimensionado, você transforma a imagem de contêiner em uma instância de contêiner em execução. A instância é executada em qualquer computador que tenha um mecanismo de runtime de contêiner instalado. Você pode ter quantas instâncias do serviço conteinerizado forem necessárias.
A Figura 1-6 mostra três microsserviços diferentes, cada um em seu próprio contêiner, todos em execução em um único host.
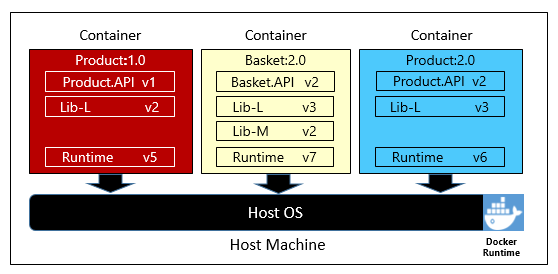
Figura 1-6. Vários contêineres em execução em um host de contêiner
Observe como cada contêiner mantém seu próprio conjunto de dependências e runtime, que podem ser diferentes um do outro. Aqui, vemos diferentes versões do microsserviço Produto em execução no mesmo host. Cada contêiner compartilha uma fatia do sistema operacional, memória e processador do host subjacente, mas é isolado um do outro.
Observe o quão bem o modelo de contêiner abraça o princípio dependências do aplicativoTwelve-Factor.
O fator nº 2 especifica que "Cada microsserviço isola e empacota suas próprias dependências, adotando alterações sem afetar todo o sistema".
Os contêineres dão suporte a cargas de trabalho do Linux e do Windows. A nuvem do Azure abraça abertamente ambos. Curiosamente, é o Linux, não o Windows Server, que se tornou o sistema operacional mais popular no Azure.
Embora existam vários fornecedores de contêineres, o Docker capturou a maior parte do mercado. A empresa tem liderado o movimento de contêineres de software. Tornou-se o padrão de fato para empacotar, implantar e executar aplicativos nativos de nuvem.
Por que contêineres?
Os contêineres fornecem portabilidade e garantem consistência entre ambientes. Encapsulando tudo em um único pacote, você isola o microsserviço e suas dependências da infraestrutura subjacente.
Você pode implantar o contêiner em qualquer ambiente que hospede o mecanismo de runtime do Docker. Cargas de trabalho em contêineres também eliminam a despesa de pré-configurar cada ambiente com estruturas, bibliotecas de software e mecanismos de runtime.
Ao compartilhar o sistema operacional subjacente e os recursos de host, um contêiner tem um volume muito menor do que uma máquina virtual completa. O tamanho menor aumenta a densidade ou o número de microsserviços que um determinado host pode executar ao mesmo tempo.
Orquestração de contêineres
Embora ferramentas como o Docker criem imagens e executem contêineres, você também precisa de ferramentas para gerenciá-las. O gerenciamento de contêineres é feito com um programa de software especial chamado orquestrador de contêineres. Na operação em escala com muitos contêineres em execução independentes, a orquestração é essencial.
A Figura 1-7 mostra as tarefas de gerenciamento que os orquestradores de contêiner automatizam.
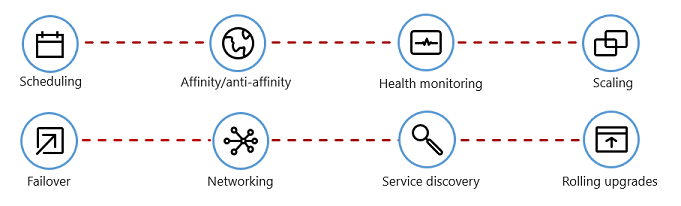
Figura 1-7. O que os orquestradores de contêineres fazem
A tabela a seguir descreve tarefas comuns de orquestração.
| Tarefas | Explicação |
|---|---|
| Agendamento | Provisionar automaticamente instâncias de contêiner. |
| Afinidade/antiafinidade | Provisione contêineres próximos ou distantes uns dos outros, ajudando a disponibilidade e o desempenho. |
| Monitoramento da integridade | Detectar e corrigir falhas automaticamente. |
| Failover | Reprovisionar automaticamente uma instância com falha em um computador íntegro. |
| Escalonamento | Adicione ou remova automaticamente uma instância de contêiner para atender à demanda. |
| Rede | Gerenciar uma camada de rede para comunicação de contêiner. |
| Descoberta de Serviços | Habilitar os contêineres a localizarem uns aos outros. |
| Atualizações sem interrupção | Coordenar atualizações incrementais com uma implantação sem tempo de inatividade. Reverter alterações problemáticas automaticamente. |
Observe como os orquestradores de contêineres adotam os princípios de Descartabilidade e Simultaneidade do Aplicativo Twelve-Factor.
O fator nº 9 especifica que "as instâncias de serviço devem ser descartáveis, favorecendo inicializações rápidas para aumentar as oportunidades de escalabilidade e desligamentos normalizados para deixar o sistema em um estado correto". Os contêineres do Docker, juntamente com um orquestrador, satisfazem inerentemente esse requisito."
O fator nº 8 especifica que os serviços se expandem por um grande número de pequenos processos idênticos (cópias), em oposição à expansão de uma única instância grande no computador mais potente disponível.
Embora existam vários orquestradores de contêineres, o Kubernetes tornou-se o padrão de fato para o mundo nativo da nuvem. É uma plataforma portátil, extensível e de software livre para gerenciar cargas de trabalho em contêineres.
Você poderia hospedar sua própria instância do Kubernetes, mas seria responsável por provisionar e gerenciar seus recursos , o que pode ser complexo. A nuvem do Azure apresenta o Kubernetes como um serviço gerenciado. O AKS (Serviço de Kubernetes do Azure) e o ARO (Red Hat OpenShift) do Azure permitem aproveitar totalmente os recursos e o poder do Kubernetes como um serviço gerenciado, sem precisar instalá-lo e mantê-lo.
A orquestração de contêineres é abordada em detalhes no Dimensionamento de aplicativos nativos de nuvem.
Serviços de backup
Os sistemas nativos de nuvem dependem de muitos recursos auxiliares diferentes, como armazenamentos de dados, agentes de mensagens, monitoramento e serviços de identidade. Esses serviços são conhecidos como serviços de backup.
A Figura 1-8 mostra muitos serviços de backup comuns que os sistemas nativos de nuvem consomem.
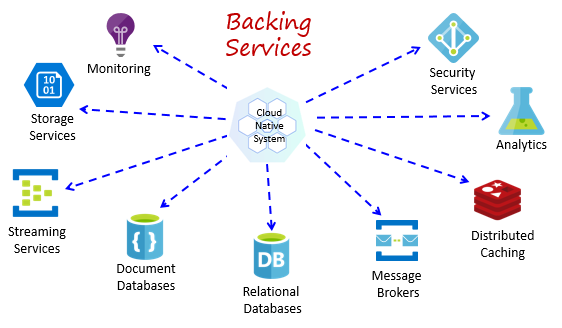
Figura 1-8. Serviços de backup comuns
Você poderia hospedar seus próprios serviços de backup, mas seria responsável pelo licenciamento, provisionamento e gerenciamento desses recursos.
Os provedores de nuvem oferecem uma variedade avançada de serviços de backup gerenciados. Em vez de possuir o serviço, basta consumi-lo. O provedor de nuvem opera o recurso em escala e tem a responsabilidade pelo desempenho, segurança e manutenção. O monitoramento, a redundância e a disponibilidade são integrados ao serviço. Os provedores garantem o desempenho no nível do serviço e dão suporte total aos seus serviços gerenciados – abra um ticket e eles resolvem o problema.
Os sistemas nativos de nuvem favorecem serviços de backup gerenciados de fornecedores de nuvem. A economia em tempo e mão-de-obra pode ser significativa. O risco operacional de operar seus próprios negócios e enfrentar problemas pode ficar caro rapidamente.
Uma prática recomendada é tratar um serviço de backup como um recurso anexado, dinamicamente associado a um microsserviço com informações de configuração (uma URL e credenciais) armazenadas em uma configuração externa. Essa orientação é explicitada no aplicativoTwelve-Factor, discutido anteriormente no capítulo.
O fator nº 4 especifica que os serviços de backup "devem ser expostos por meio de uma URL endereçável. Isso desassocia o recurso do aplicativo, permitindo que ele seja intercambiável."
O fator nº 3 especifica que "as informações de configuração são movidas para fora do microsserviço e externalizadas por meio de uma ferramenta de gerenciamento de configuração fora do código".
Com esse padrão, um serviço de backup pode ser anexado e desanexado sem alterações de código. Você pode promover um microsserviço de QA para um ambiente de preparo. Você atualiza a configuração de microsserviço para apontar para os serviços de backup no preparo e injetar as configurações em seu contêiner por meio de uma variável de ambiente.
Os fornecedores de nuvem fornecem APIs para que você se comunique com seus serviços de backup proprietários. Essas bibliotecas encapsulam a complexidade e o encanamento proprietários. No entanto, a comunicação diretamente com essas APIs associará firmemente seu código a esse serviço de backup específico. É uma prática amplamente aceita isolar os detalhes de implementação da API do fornecedor. Introduza uma camada de intermediação, ou API intermediária, expondo operações genéricas ao seu código de serviço e encapsule o código do fornecedor dentro dele. Esse acoplamento flexível permite que você troque um serviço de backup por outro ou mova seu código para um ambiente de nuvem diferente sem precisar fazer alterações no código do serviço de linha principal. Dapr, discutido anteriormente, segue esse modelo com seu conjunto de blocos de construção predefinidos.
Em uma ideia final, os serviços de backup também promovem o princípio Sem estado do Aplicativo Twelve-Factor discutido anteriormente no capítulo.
O fator nº 6 especifica que, "Cada microsserviço deve ser executado em seu próprio processo, isolado de outros serviços em execução. Externalize o estado necessário para um serviço de backup, como um cache distribuído ou um armazenamento de dados.
Os serviços de backup são discutidos em padrões de dados nativos de nuvem e padrões de comunicação nativos de nuvem.
Automação
Como você viu, os sistemas nativos de nuvem adotam microsserviços, contêineres e design de sistema moderno para obter velocidade e agilidade. Mas isso é apenas parte da história. Como você provisiona os ambientes de nuvem nos quais esses sistemas são executados? Como implantar rapidamente recursos e atualizações de aplicativos? Como você completa o panorama completo?
Insira a prática amplamente aceita de Infraestrutura como Código ou IaC.
Com a IaC, você automatiza o provisionamento de plataforma e a implantação de aplicativos. Você essencialmente aplica práticas de engenharia de software, como teste e controle de versão às práticas de DevOps. Sua infraestrutura e implantações são automatizadas, consistentes e repetíveis.
Automatizando a infraestrutura
Ferramentas como o Azure Resource Manager, o Azure Bicep, o Terraform da HashiCorp e a CLI do Azure permitem que você crie um script declarativo da infraestrutura de nuvem necessária. Nomes de recursos, locais, capacidades e segredos são parametrizados e dinâmicos. O script tem controle de versão e há check-in no controle do código-fonte como um artefato do seu projeto. Você invoca o script para garantir uma infraestrutura consistente e repetível em ambientes de sistema, como qualidade, homologação e produção.
Nos bastidores, a IaC é idempotente, o que significa que você pode executar o mesmo script repetidamente sem efeitos colaterais. Se a equipe precisar fazer uma alteração, ela editará e executará novamente o script. Somente os recursos atualizados são afetados.
No artigo, O que é infraestrutura como código, o autor Sam Guckenheimer descreve como"As equipes que implementam IaC podem fornecer ambientes estáveis rapidamente e em escala. Eles evitam a configuração manual de ambientes e impõem consistência, representando o estado desejado de seus ambientes por meio do código. As implantações de infraestrutura com IaC são repetíveis e evitam problemas de runtime causados por descompasso de configuração ou dependências ausentes. As equipes do DevOps podem trabalhar em conjunto com um conjunto unificado de práticas e ferramentas para fornecer aplicativos e sua infraestrutura de suporte rapidamente, de forma confiável e em escala.".
Automatizando implantações
O aplicativoTwelve-Factor, discutido anteriormente, exige etapas separadas ao transformar o código concluído em um aplicativo em execução.
O fator nº 5 especifica que "Cada versão deve impor uma separação estrita entre os estágios de build, versão e execução. Cada uma deve ser marcada com uma ID exclusiva e dar suporte à capacidade de reversão.
Os sistemas modernos de CI/CD ajudam a atender a esse princípio. Eles fornecem etapas de build e entrega separadas que ajudam a garantir um código consistente e de qualidade prontamente disponível para os usuários.
A Figura 1-9 mostra a separação em todo o processo de implantação.
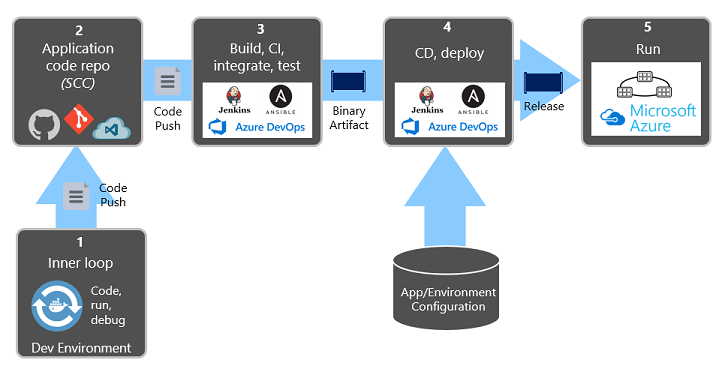
Figura 1-9. Etapas de implantação em um pipeline de CI/CD
Na figura anterior, preste atenção especial à separação de tarefas:
- O desenvolvedor constrói um recurso em seu ambiente de desenvolvimento, iterando por meio do que é chamado de "loop interno" de código, execução e depuração.
- Quando concluído, esse código é enviado por push para um repositório de código, como GitHub, Azure DevOps ou BitBucket.
- O push dispara um estágio de build que transforma o código em um artefato binário. O trabalho é implementado com um pipeline de CI (Integração Contínua ). Ele compila, testa e empacota automaticamente o aplicativo.
- A fase de liberação pega o artefato binário, aplica informações de configuração de ambiente e aplicativo externo e produz uma versão imutável. A versão é implantada em um ambiente especificado. O trabalho é implementado com um pipeline de CD (Entrega Contínua). Cada versão deve ser identificável. Você pode dizer: "Essa implantação está executando a Versão 2.1.1 do aplicativo".
- Por fim, o recurso lançado é executado no ambiente de execução de destino. As versões são imutáveis, o que significa que qualquer alteração deve criar uma nova versão.
Aplicando essas práticas, as organizações evoluíram radicalmente a forma como enviam software. Muitos mudaram de versões trimestrais para atualizações sob demanda. O objetivo é detectar problemas no início do ciclo de desenvolvimento quando eles são mais baratos de corrigir. Quanto maior for a duração entre as integrações, mais caro se torna resolver os problemas. Com a consistência no processo de integração, as equipes podem confirmar alterações de código com mais frequência, levando a uma melhor colaboração e qualidade de software.
A infraestrutura como automação de código e implantação, juntamente com o GitHub e o Azure DevOps são discutidas detalhadamente no DevOps.
Colaborar conosco no GitHub
A fonte deste conteúdo pode ser encontrada no GitHub, onde você também pode criar e revisar problemas e solicitações de pull. Para obter mais informações, confira o nosso guia para colaboradores.