Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Saiba como usar um modelo ONNX pré-treinado em ML.NET para detectar objetos em imagens.
Treinar um modelo de detecção de objetos do zero requer a definição de milhões de parâmetros, uma grande quantidade de dados de treinamento rotulados e uma grande quantidade de recursos de computação (centenas de horas de GPU). O uso de um modelo pré-treinado permite que você atalho o processo de treinamento.
Neste tutorial, você aprenderá como:
- Compreender o problema
- Saiba o que é o ONNX e como ele funciona com ML.NET
- Entender o modelo
- Reutilizar o modelo pré-treinado
- Detectar objetos com um modelo carregado
Pré-requisitos
- Visual Studio 2022 ou posterior.
- Microsoft.ML Pacote NuGet
- Pacote NuGet do Microsoft.ML.ImageAnalytics
- Pacote NuGet Microsoft.ML.OnnxTransformer
- Modelo pré-treinado TINY YOLOv2
- Netron (opcional)
Visão geral do exemplo de detecção de objetos ONNX
Este exemplo cria um aplicativo de console do .NET Core que detecta objetos em uma imagem usando um modelo ONNX de aprendizado profundo pré-treinado. O código deste exemplo pode ser encontrado no repositório dotnet/machinelearning-samples no GitHub.
O que é a detecção de objetos?
A detecção de objetos é um problema de visão computacional. Embora intimamente relacionada à classificação de imagem, a detecção de objetos executa a classificação de imagem em uma escala mais granular. A detecção de objetos localiza e categoriza entidades em imagens. Os modelos de detecção de objetos geralmente são treinados usando redes neurais e de aprendizado profundo. Consulte o aprendizado profundo versus aprendizado de máquina para obter mais informações.
Use a detecção de objetos quando as imagens contiverem vários objetos de diferentes tipos.

Alguns casos de uso para detecção de objetos incluem:
- Carros Autônomos
- Robótica
- Detecção Facial
- Segurança no local de trabalho
- Contagem de objetos
- Reconhecimento de atividades
Selecionar um modelo de aprendizado profundo
O aprendizado profundo é um subconjunto de aprendizado de máquina. Para treinar modelos de aprendizado profundo, grandes quantidades de dados são necessárias. Os padrões nos dados são representados por uma série de camadas. As relações nos dados são codificadas como conexões entre as camadas que contêm pesos. Quanto maior o peso, mais forte a relação. Coletivamente, essa série de camadas e conexões é conhecida como redes neurais artificiais. Quanto mais camadas em uma rede, mais "mais profunda" ela é, tornando-a uma rede neural profunda.
Há diferentes tipos de redes neurais, sendo mais comuns a MLP (Perceptron multicamadas), a CNN (Rede Neural Convolucional) e a Rede Neural Recorrente (RNN). O mais básico é o MLP, que mapeia um conjunto de entradas para um conjunto de saídas. Essa rede neural é boa quando os dados não têm um componente espacial ou de tempo. A CNN usa camadas convolucionais para processar informações espaciais contidas nos dados. Um bom caso de uso para CNNs é o processamento de imagem para detectar a presença de um recurso em uma região de uma imagem (por exemplo, há um nariz no centro de uma imagem?). Por fim, os RNNs permitem que a persistência de estado ou memória seja usada como entrada. RNNs são usados para análise de série temporal, em que a ordenação sequencial e o contexto de eventos são importantes.
Entender o modelo
A detecção de objetos é uma tarefa de processamento de imagem. Portanto, a maioria dos modelos de aprendizado profundo treinados para resolver esse problema são CNNs. O modelo usado neste tutorial é o modelo Tiny YOLOv2, uma versão mais compacta do modelo YOLOv2 descrita no artigo: "YOLO9000: Melhor, Mais Rápido, Mais Forte" por Redmon e Farhadi. Tiny YOLOv2 é treinado no conjunto de dados Pascal VOC e é composto por 15 camadas que podem prever 20 classes diferentes de objetos. Como Tiny YOLOv2 é uma versão condensada do modelo YOLOv2 original, uma compensação é feita entre velocidade e precisão. As diferentes camadas que compõem o modelo podem ser visualizadas usando ferramentas como o Netron. Inspecionar o modelo produziria um mapeamento das conexões entre todas as camadas que compõem a rede neural, em que cada camada conteria o nome da camada junto com as dimensões da respectiva entrada/saída. As estruturas de dados usadas para descrever as entradas e saídas do modelo são conhecidas como tensores. Tensores podem ser considerados contêineres que armazenam dados em dimensões N. No caso de Tiny YOLOv2, o nome da camada de entrada é image e espera um tensor de dimensões 3 x 416 x 416. O nome da camada de saída é grid e gera um tensor de saída de dimensões 125 x 13 x 13.
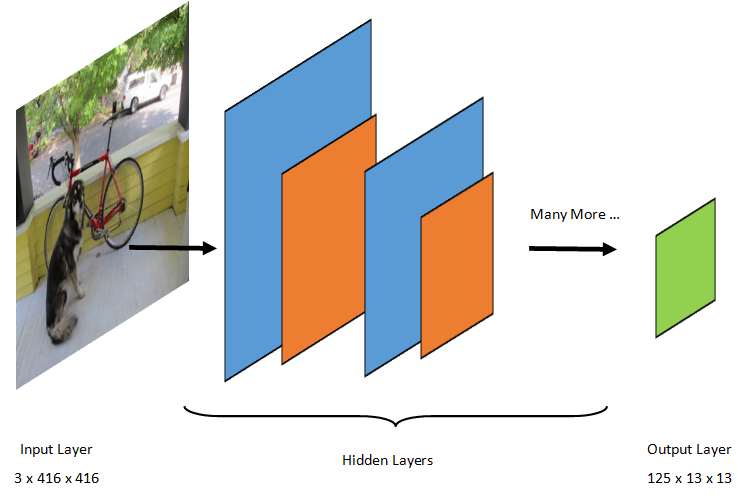
O modelo YOLO usa uma imagem 3(RGB) x 416px x 416px. O modelo usa essa entrada e passa pelas diferentes camadas para produzir uma saída. A saída divide a imagem de entrada em uma 13 x 13 grade, em que cada célula da grade consiste em 125 valores.
O que é um modelo ONNX?
O ONNX (Open Neural Network Exchange) é um formato de software livre para modelos de IA. O ONNX dá suporte à interoperabilidade entre estruturas. Isso significa que você pode treinar um modelo em uma das muitas estruturas populares de machine learning, como pyTorch, convertê-lo em formato ONNX e consumir o modelo ONNX em uma estrutura diferente, como ML.NET. Para saber mais, visite o site do ONNX.

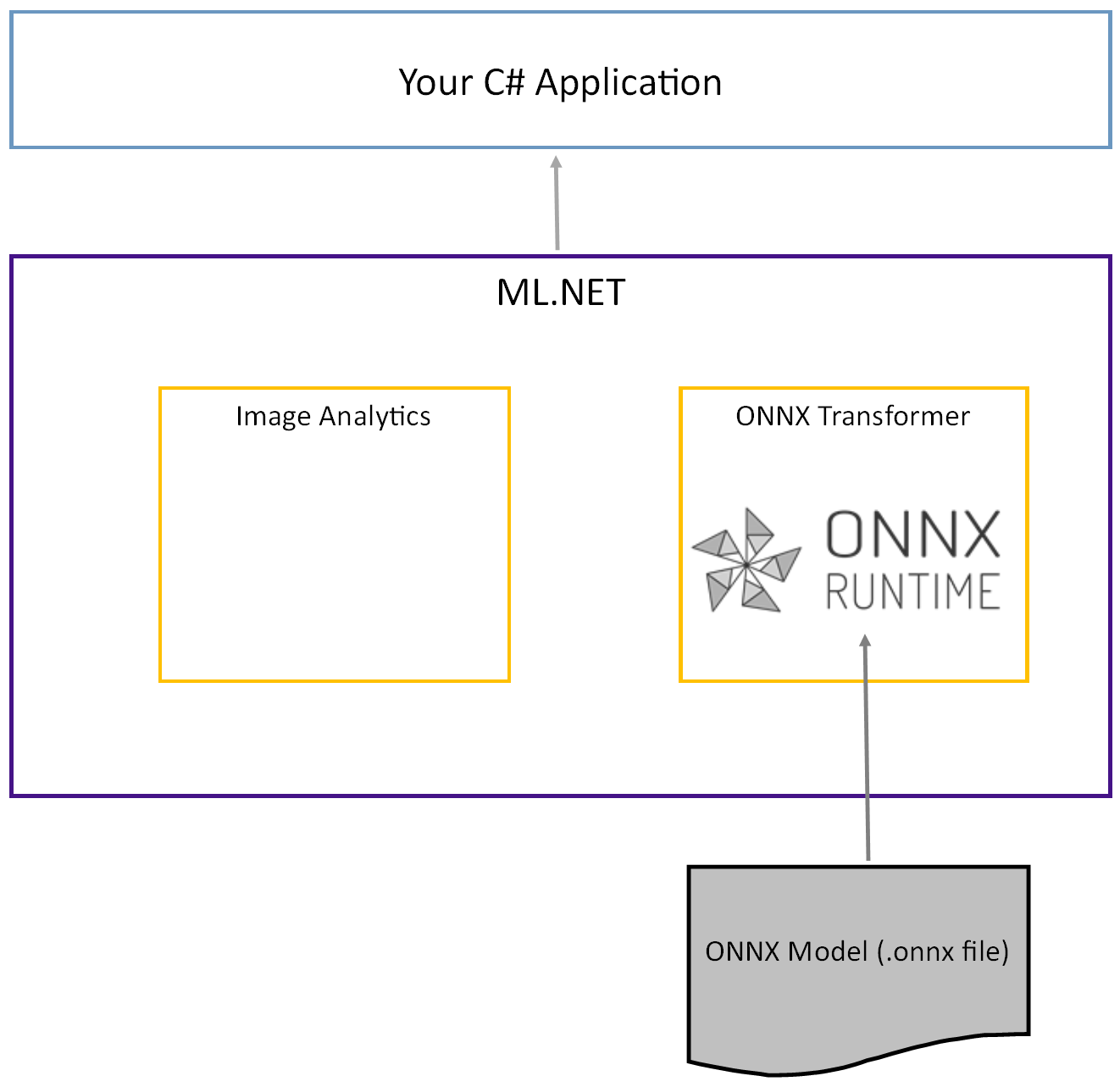
O modelo Tiny YOLOv2 pré-treinado é armazenado no formato ONNX, uma representação serializada das camadas e padrões aprendidos dessas camadas. Em ML.NET, a interoperabilidade com ONNX é obtida com os pacotes ImageAnalytics e OnnxTransformer NuGet. O ImageAnalytics pacote contém uma série de transformações que pegam uma imagem e a codificam em valores numéricos que podem ser usados como entrada em um pipeline de previsão ou treinamento. O OnnxTransformer pacote aproveita o ONNX Runtime para carregar um modelo ONNX e usá-lo para fazer previsões com base na entrada fornecida.
Configurar o projeto do Console do .NET
Agora que você tem uma compreensão geral do que é ONNX e como o Tiny YOLOv2 funciona, é hora de criar o aplicativo.
Criar um aplicativo de console
Crie um aplicativo de console C# chamado "ObjectDetection". Clique no botão Avançar.
Escolha .NET 8 como a estrutura a ser usada. Clique no botão Criar .
Instale o Microsoft.ML Pacote NuGet:
Observação
Este exemplo usa a versão estável mais recente dos pacotes NuGet mencionados, a menos que indicado de outra forma.
- No Gerenciador de Soluções, clique com o botão direito do mouse em seu projeto e selecione Gerenciar Pacotes NuGet.
- Escolha "nuget.org" como a origem do pacote, selecione a guia Procurar, pesquise Microsoft.ML.
- Selecione o botão Instalar.
- Selecione o botão OK na caixa de diálogo Alterações de Visualização e, em seguida, selecione o botão I Accept na caixa de diálogo Aceitação da Licença se você concordar com os termos de licença dos pacotes listados.
- Repita estas etapas para Microsoft.Windows.Compatibility, Microsoft.ML.ImageAnalytics, Microsoft.ML.OnnxTransformer e Microsoft.ML.OnnxRuntime.
Prepare seus dados e o modelo pré-treinado
Baixe o arquivo zip do diretório de ativos do projeto e descompacte .
Copie o diretório
assetspara o diretório do projeto ObjectDetection. Esse diretório e seus subdiretórios contêm os arquivos de imagem (exceto para o modelo Tiny YOLOv2, que você baixará e adicionará na próxima etapa) necessários para este tutorial.Baixe o modelo Tiny YOLOv2 do ONNX Model Zoo.
Copie o arquivo para o
model.onnxdiretório do projetoassets\Modele renomeie-o paraTinyYolo2_model.onnx. Este diretório contém o modelo necessário para este tutorial.No Gerenciador de Soluções, clique com o botão direito do mouse em cada um dos arquivos no diretório de ativos e subdiretórios e selecione Propriedades. Em Avançado, altere o valor de Copiar para Diretório de Saída para Copiar se for mais recente.
Criar classes e definir caminhos
Abra o arquivo Program.cs e adicione as seguintes diretivas adicionais using à parte superior do arquivo:
using System.Drawing;
using System.Drawing.Drawing2D;
using ObjectDetection.YoloParser;
using ObjectDetection.DataStructures;
using ObjectDetection;
using Microsoft.ML;
Em seguida, defina os caminhos dos vários ativos.
Primeiro, crie o
GetAbsolutePathmétodo na parte inferior do arquivo Program.cs .string GetAbsolutePath(string relativePath) { FileInfo _dataRoot = new FileInfo(typeof(Program).Assembly.Location); string assemblyFolderPath = _dataRoot.Directory.FullName; string fullPath = Path.Combine(assemblyFolderPath, relativePath); return fullPath; }Em seguida, abaixo das
usingdiretivas, crie campos para armazenar o local de seus ativos.var assetsRelativePath = @"../../../assets"; string assetsPath = GetAbsolutePath(assetsRelativePath); var modelFilePath = Path.Combine(assetsPath, "Model", "TinyYolo2_model.onnx"); var imagesFolder = Path.Combine(assetsPath, "images"); var outputFolder = Path.Combine(assetsPath, "images", "output");
Adicione um novo diretório ao seu projeto para armazenar seus dados de entrada e classes de previsão.
No Gerenciador de Soluções, clique com o botão direito do mouse no projeto e selecione Adicionar>Nova Pasta. Quando a nova pasta aparecer no Gerenciador de Soluções, nomeie-a como "DataStructures".
Crie sua classe de dados de entrada no diretório DataStructures recém-criado.
No Gerenciador de Soluções, clique com o botão direito do mouse no diretório DataStructures e selecione Adicionar>Novo Item.
Na caixa de diálogo Adicionar Novo Item , selecione Classe e altere o campo Nome para ImageNetData.cs. Em seguida, selecione Adicionar.
O arquivo ImageNetData.cs é aberto no editor de código. Adicione a seguinte
usingdiretiva à parte superior de ImageNetData.cs:using System.Collections.Generic; using System.IO; using System.Linq; using Microsoft.ML.Data;Remova a definição de classe existente e adicione o seguinte código para a
ImageNetDataclasse ao arquivo ImageNetData.cs :public class ImageNetData { [LoadColumn(0)] public string ImagePath; [LoadColumn(1)] public string Label; public static IEnumerable<ImageNetData> ReadFromFile(string imageFolder) { return Directory .GetFiles(imageFolder) .Where(filePath => Path.GetExtension(filePath) != ".md") .Select(filePath => new ImageNetData { ImagePath = filePath, Label = Path.GetFileName(filePath) }); } }ImageNetDataé a classe de dados de imagem de entrada e tem os seguintes String campos:-
ImagePathcontém o caminho em que a imagem é armazenada. -
Labelcontém o nome do arquivo.
Além disso,
ImageNetDatacontém um métodoReadFromFileque carrega vários arquivos de imagem armazenados noimageFoldercaminho especificado e os retorna como uma coleção deImageNetDataobjetos.-
Crie sua classe de previsão no diretório DataStructures .
No Gerenciador de Soluções, clique com o botão direito do mouse no diretório DataStructures e selecione Adicionar>Novo Item.
Na caixa de diálogo Adicionar Novo Item , selecione Classe e altere o campo Nome para ImageNetPrediction.cs. Em seguida, selecione Adicionar.
O arquivo ImageNetPrediction.cs é aberto no editor de código. Adicione a seguinte
usingdiretiva à parte superior de ImageNetPrediction.cs:using Microsoft.ML.Data;Remova a definição de classe existente e adicione o seguinte código para a
ImageNetPredictionclasse ao arquivo ImageNetPrediction.cs :public class ImageNetPrediction { [ColumnName("grid")] public float[] PredictedLabels; }ImageNetPredictioné a classe de dados de previsão e tem o seguintefloat[]campo:-
PredictedLabelscontém as dimensões, a pontuação de pertinência e as probabilidades de classe para cada uma das caixas delimitadoras detectadas em uma imagem.
-
Inicializar variáveis
A classe MLContext é um ponto de partida para todas as operações de ML.NET e a inicialização mlContext cria um novo ambiente ML.NET que pode ser compartilhado entre os objetos de fluxo de trabalho de criação de modelo. É semelhante, conceitualmente, ao DBContext Entity Framework.
Inicialize a mlContext variável com uma nova instância adicionando MLContext a seguinte linha abaixo do outputFolder campo.
MLContext mlContext = new MLContext();
Criar um analisador para saídas de modelo pós-processo
O modelo segmenta uma imagem em uma 13 x 13 grade, onde cada célula de grade é 32px x 32px. Cada célula de grade contém 5 caixas delimitadoras de objeto em potencial. Uma bounding box tem 25 elementos:
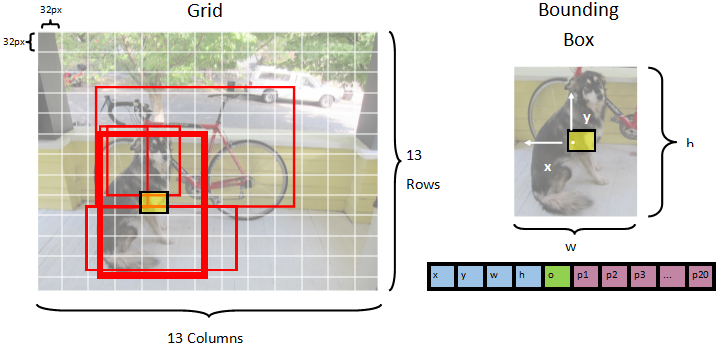
-
xa posição x do centro da caixa delimitadora em relação à célula de grade à qual está associada. -
ya posição y do centro da caixa delimitadora em relação à célula da grade com a qual está associada. -
wa largura da caixa delimitadora. -
ha altura da caixa delimitadora. -
oo valor de confiança de que um objeto existe dentro da caixa de delimitação, também conhecido como pontuação de objetividade. -
p1-p20probabilidades de classe para cada uma das 20 classes previstas pelo modelo.
No total, os 25 elementos que descrevem cada uma das cinco caixas limitadoras compõem os 125 elementos contidos em cada célula da grade.
A saída gerada pelo modelo ONNX pré-treinado é uma matriz flutuante de comprimento 21125, representando os elementos de um tensor com dimensões 125 x 13 x 13. Para transformar as previsões geradas pelo modelo em um tensor, alguns trabalhos pós-processamento são necessários. Para fazer isso, crie um conjunto de classes para ajudar a analisar a saída.
Adicione um novo diretório ao seu projeto para organizar o conjunto de classes de analisador.
- No Gerenciador de Soluções, clique com o botão direito do mouse no projeto e selecione Adicionar>Nova Pasta. Quando a nova pasta aparecer no Gerenciador de Soluções, nomeie-a como "YoloParser".
Criar caixas delimitadoras e dimensões
A saída de dados pelo modelo contém coordenadas e dimensões das caixas delimitadoras de objetos dentro da imagem. Crie uma classe base para dimensões.
No Gerenciador de Soluções, clique com o botão direito do mouse no diretório YoloParser e selecione Adicionar>Novo Item.
Na caixa de diálogo Adicionar Novo Item , selecione Classe e altere o campo Nome para DimensionsBase.cs. Em seguida, selecione Adicionar.
O arquivo DimensionsBase.cs é aberto no editor de código. Remova todas as
usingdiretivas e a definição de classe existente.Adicione o seguinte código para a
DimensionsBaseclasse ao arquivo DimensionsBase.cs :public class DimensionsBase { public float X { get; set; } public float Y { get; set; } public float Height { get; set; } public float Width { get; set; } }DimensionsBasetem as seguintesfloatpropriedades:-
Xcontém a posição do objeto ao longo do eixo x. -
Ycontém a posição do objeto ao longo do eixo y. -
Heightcontém a altura do objeto. -
Widthcontém a largura do objeto.
-
Em seguida, crie uma classe para suas caixas delimitadoras.
No Gerenciador de Soluções, clique com o botão direito do mouse no diretório YoloParser e selecione Adicionar>Novo Item.
Na caixa de diálogo Adicionar Novo Item , selecione Classe e altere o campo Nome para YoloBoundingBox.cs. Em seguida, selecione Adicionar.
O arquivo YoloBoundingBox.cs é aberto no editor de código. Adicione a seguinte
usingdiretiva à parte superior do YoloBoundingBox.cs:using System.Drawing;Logo acima da definição de classe existente, adicione uma nova definição de classe chamada
BoundingBoxDimensionsque herda daDimensionsBaseclasse para conter as dimensões da respectiva caixa delimitadora.public class BoundingBoxDimensions : DimensionsBase { }Remova a definição de classe existente
YoloBoundingBoxe adicione o seguinte código para aYoloBoundingBoxclasse ao arquivo YoloBoundingBox.cs :public class YoloBoundingBox { public BoundingBoxDimensions Dimensions { get; set; } public string Label { get; set; } public float Confidence { get; set; } public RectangleF Rect { get { return new RectangleF(Dimensions.X, Dimensions.Y, Dimensions.Width, Dimensions.Height); } } public Color BoxColor { get; set; } }YoloBoundingBoxtem as seguintes propriedades:-
Dimensionscontém dimensões da caixa delimitadora. -
Labelcontém a classe de objeto detectada dentro da caixa delimitadora. -
Confidencecontém o índice de confiança da classe. -
Rectcontém as dimensões da caixa delimitadora em forma de retângulo. -
BoxColorcontém a cor associada à respectiva classe usada para desenhar na imagem.
-
Criar o analisador
Agora que as classes para dimensões e caixas delimitadoras foram criadas, é hora de criar o analisador.
No Gerenciador de Soluções, clique com o botão direito do mouse no diretório YoloParser e selecione Adicionar>Novo Item.
Na caixa de diálogo Adicionar Novo Item , selecione Classe e altere o campo Nome para YoloOutputParser.cs. Em seguida, selecione Adicionar.
O arquivo YoloOutputParser.cs é aberto no editor de código. Adicione as seguintes
usingdiretivas à parte superior do YoloOutputParser.cs:using System; using System.Collections.Generic; using System.Drawing; using System.Linq;Dentro da definição de classe existente
YoloOutputParser, adicione uma classe aninhada que contenha as dimensões de cada uma das células na imagem. Adicione o seguinte código para a classeCellDimensions, que herda da classeDimensionsBase, na parte superior da definição da classeYoloOutputParser.class CellDimensions : DimensionsBase { }Dentro da definição de
YoloOutputParserclasse, adicione as seguintes constantes e campo.public const int ROW_COUNT = 13; public const int COL_COUNT = 13; public const int CHANNEL_COUNT = 125; public const int BOXES_PER_CELL = 5; public const int BOX_INFO_FEATURE_COUNT = 5; public const int CLASS_COUNT = 20; public const float CELL_WIDTH = 32; public const float CELL_HEIGHT = 32; private int channelStride = ROW_COUNT * COL_COUNT;-
ROW_COUNTé o número de linhas na grade em que a imagem é dividida. -
COL_COUNTé o número de colunas na grade em que a imagem é dividida. -
CHANNEL_COUNTé o número total de valores contidos em uma célula da grade. -
BOXES_PER_CELLé o número de caixas delimitadoras em uma célula, -
BOX_INFO_FEATURE_COUNTé o número de recursos contidos em uma caixa (x,y, altura, largura, confiança). -
CLASS_COUNTé o número de previsões de classe contidas em cada caixa delimitadora. -
CELL_WIDTHé a largura de uma célula na grade de imagem. -
CELL_HEIGHTé a altura de uma célula na grade de imagem. -
channelStrideé a posição inicial da célula atual na grade.
Quando o modelo faz uma previsão, também conhecida como pontuação, ele divide a
416px x 416pximagem de entrada em uma grade de células do tamanho de13 x 13. Cada célula que contém é32px x 32px. Dentro de cada célula, há cinco caixas delimitadoras cada uma contendo 5 características (x, y, largura, altura, confiança). Além disso, cada caixa delimitadora contém a probabilidade de cada uma das classes, que, neste caso, são 20 no total. Portanto, cada célula contém 125 informações (5 recursos + 20 probabilidades de classe).-
Crie uma lista de âncoras abaixo de channelStride para as cinco caixas delimitadoras:
private float[] anchors = new float[]
{
1.08F, 1.19F, 3.42F, 4.41F, 6.63F, 11.38F, 9.42F, 5.11F, 16.62F, 10.52F
};
As âncoras são proporções predefinidas de altura e largura de caixas de delimitação. A maioria dos objetos ou classes detectadas por um modelo tem proporções semelhantes. Isso é valioso quando se trata de criar caixas delimitadoras. Em vez de prever as caixas delimitadoras, calcula-se o deslocamento em relação às dimensões predefinidas, reduzindo assim a computação necessária para prever a caixa delimitadora. Normalmente, essas taxas de âncora são calculadas com base no conjunto de dados usado. Nesse caso, como o conjunto de dados é conhecido e os valores foram pré-compilados, as âncoras podem ser codificadas em código.
Em seguida, defina os rótulos ou classes que o modelo preverá. Esse modelo prevê 20 classes, que é um subconjunto do número total de classes previstas pelo modelo YOLOv2 original.
Adicione sua lista de rótulos abaixo do anchors.
private string[] labels = new string[]
{
"aeroplane", "bicycle", "bird", "boat", "bottle",
"bus", "car", "cat", "chair", "cow",
"diningtable", "dog", "horse", "motorbike", "person",
"pottedplant", "sheep", "sofa", "train", "tvmonitor"
};
Há cores associadas a cada uma das classes. Atribua as cores da classe abaixo de:labels
private static Color[] classColors = new Color[]
{
Color.Khaki,
Color.Fuchsia,
Color.Silver,
Color.RoyalBlue,
Color.Green,
Color.DarkOrange,
Color.Purple,
Color.Gold,
Color.Red,
Color.Aquamarine,
Color.Lime,
Color.AliceBlue,
Color.Sienna,
Color.Orchid,
Color.Tan,
Color.LightPink,
Color.Yellow,
Color.HotPink,
Color.OliveDrab,
Color.SandyBrown,
Color.DarkTurquoise
};
Criar funções auxiliares
Há uma série de etapas envolvidas na fase pós-processamento. Para ajudar com isso, vários métodos auxiliares podem ser empregados.
Os métodos auxiliares usados pelo analisador são:
-
Sigmoidaplica a função sigmoid que gera um número entre 0 e 1. -
Softmaxnormaliza um vetor de entrada em uma distribuição de probabilidade. -
GetOffsetmapeia os elementos da saída do modelo unidimensional para a posição correspondente em um tensor125 x 13 x 13. -
ExtractBoundingBoxesextrai as dimensões da caixa delimitadora usando o métodoGetOffsetda saída do modelo. -
GetConfidenceextrai o valor de confiança que indica a certeza de que o modelo detectou um objeto e usa aSigmoidfunção para transformá-lo em uma porcentagem. -
MapBoundingBoxToCellusa as dimensões da caixa delimitadora e mapeia-as para sua respectiva célula dentro da imagem. -
ExtractClassesextrai as previsões de classe para a caixa delimitadora da saída do modelo usando o métodoGetOffsete as converte em uma distribuição de probabilidade usando o métodoSoftmax. -
GetTopResultseleciona a classe na lista de classes previstas com a maior probabilidade. -
IntersectionOverUnionfiltra caixas delimitadoras sobrepostas com probabilidades menores.
Adicione o código para todos os métodos auxiliares abaixo de sua lista de classColors.
private float Sigmoid(float value)
{
var k = (float)Math.Exp(value);
return k / (1.0f + k);
}
private float[] Softmax(float[] values)
{
var maxVal = values.Max();
var exp = values.Select(v => Math.Exp(v - maxVal));
var sumExp = exp.Sum();
return exp.Select(v => (float)(v / sumExp)).ToArray();
}
private int GetOffset(int x, int y, int channel)
{
// YOLO outputs a tensor that has a shape of 125x13x13, which
// WinML flattens into a 1D array. To access a specific channel
// for a given (x,y) cell position, we need to calculate an offset
// into the array
return (channel * this.channelStride) + (y * COL_COUNT) + x;
}
private BoundingBoxDimensions ExtractBoundingBoxDimensions(float[] modelOutput, int x, int y, int channel)
{
return new BoundingBoxDimensions
{
X = modelOutput[GetOffset(x, y, channel)],
Y = modelOutput[GetOffset(x, y, channel + 1)],
Width = modelOutput[GetOffset(x, y, channel + 2)],
Height = modelOutput[GetOffset(x, y, channel + 3)]
};
}
private float GetConfidence(float[] modelOutput, int x, int y, int channel)
{
return Sigmoid(modelOutput[GetOffset(x, y, channel + 4)]);
}
private CellDimensions MapBoundingBoxToCell(int x, int y, int box, BoundingBoxDimensions boxDimensions)
{
return new CellDimensions
{
X = ((float)x + Sigmoid(boxDimensions.X)) * CELL_WIDTH,
Y = ((float)y + Sigmoid(boxDimensions.Y)) * CELL_HEIGHT,
Width = (float)Math.Exp(boxDimensions.Width) * CELL_WIDTH * anchors[box * 2],
Height = (float)Math.Exp(boxDimensions.Height) * CELL_HEIGHT * anchors[box * 2 + 1],
};
}
public float[] ExtractClasses(float[] modelOutput, int x, int y, int channel)
{
float[] predictedClasses = new float[CLASS_COUNT];
int predictedClassOffset = channel + BOX_INFO_FEATURE_COUNT;
for (int predictedClass = 0; predictedClass < CLASS_COUNT; predictedClass++)
{
predictedClasses[predictedClass] = modelOutput[GetOffset(x, y, predictedClass + predictedClassOffset)];
}
return Softmax(predictedClasses);
}
private ValueTuple<int, float> GetTopResult(float[] predictedClasses)
{
return predictedClasses
.Select((predictedClass, index) => (Index: index, Value: predictedClass))
.OrderByDescending(result => result.Value)
.First();
}
private float IntersectionOverUnion(RectangleF boundingBoxA, RectangleF boundingBoxB)
{
var areaA = boundingBoxA.Width * boundingBoxA.Height;
if (areaA <= 0)
return 0;
var areaB = boundingBoxB.Width * boundingBoxB.Height;
if (areaB <= 0)
return 0;
var minX = Math.Max(boundingBoxA.Left, boundingBoxB.Left);
var minY = Math.Max(boundingBoxA.Top, boundingBoxB.Top);
var maxX = Math.Min(boundingBoxA.Right, boundingBoxB.Right);
var maxY = Math.Min(boundingBoxA.Bottom, boundingBoxB.Bottom);
var intersectionArea = Math.Max(maxY - minY, 0) * Math.Max(maxX - minX, 0);
return intersectionArea / (areaA + areaB - intersectionArea);
}
Depois de definir todos os métodos auxiliares, é hora de usá-los para processar a saída do modelo.
Abaixo do IntersectionOverUnion método, crie o ParseOutputs método para processar a saída gerada pelo modelo.
public IList<YoloBoundingBox> ParseOutputs(float[] yoloModelOutputs, float threshold = .3F)
{
}
Crie uma lista para armazenar suas caixas delimitadoras e defina variáveis dentro do método ParseOutputs.
var boxes = new List<YoloBoundingBox>();
Cada imagem é dividida em uma grade de 13 x 13 células. Cada célula contém cinco caixas delimitadoras. Abaixo da boxes variável, adicione código para processar todas as caixas em cada uma das células.
for (int row = 0; row < ROW_COUNT; row++)
{
for (int column = 0; column < COL_COUNT; column++)
{
for (int box = 0; box < BOXES_PER_CELL; box++)
{
}
}
}
Dentro do loop mais interno, calcule a posição inicial da caixa atual dentro da saída do modelo unidimensional.
var channel = (box * (CLASS_COUNT + BOX_INFO_FEATURE_COUNT));
Diretamente abaixo disso, use o ExtractBoundingBoxDimensions método para obter as dimensões da caixa delimitadora atual.
BoundingBoxDimensions boundingBoxDimensions = ExtractBoundingBoxDimensions(yoloModelOutputs, row, column, channel);
Em seguida, use o GetConfidence método para obter a confiança da caixa delimitadora atual.
float confidence = GetConfidence(yoloModelOutputs, row, column, channel);
Depois disso, use o MapBoundingBoxToCell método para mapear a caixa delimitadora atual para a célula atual que está sendo processada.
CellDimensions mappedBoundingBox = MapBoundingBoxToCell(row, column, box, boundingBoxDimensions);
Antes de fazer qualquer processamento adicional, verifique se o valor de confiança é maior que o limite fornecido. Caso contrário, processe a próxima caixa delimitadora.
if (confidence < threshold)
continue;
Caso contrário, continue processando a saída. A próxima etapa é obter a distribuição de probabilidade das classes previstas para a caixa delimitadora atual usando o método ExtractClasses.
float[] predictedClasses = ExtractClasses(yoloModelOutputs, row, column, channel);
Em seguida, use o GetTopResult método para obter o valor e o índice da classe com a maior probabilidade para a caixa atual e computar sua pontuação.
var (topResultIndex, topResultScore) = GetTopResult(predictedClasses);
var topScore = topResultScore * confidence;
Use o topScore para manter apenas as caixas delimitadoras que estão acima do limite especificado.
if (topScore < threshold)
continue;
Por fim, se a caixa delimitadora atual exceder o limite, crie um novo BoundingBox objeto e adicione-o boxes à lista.
boxes.Add(new YoloBoundingBox()
{
Dimensions = new BoundingBoxDimensions
{
X = (mappedBoundingBox.X - mappedBoundingBox.Width / 2),
Y = (mappedBoundingBox.Y - mappedBoundingBox.Height / 2),
Width = mappedBoundingBox.Width,
Height = mappedBoundingBox.Height,
},
Confidence = topScore,
Label = labels[topResultIndex],
BoxColor = classColors[topResultIndex]
});
Depois que todas as células na imagem tiverem sido processadas, retorne a lista boxes. Adicione a seguinte instrução de retorno abaixo do loop for-most externo no ParseOutputs método.
return boxes;
Filtrar caixas sobrepostas
Agora que todas as caixas delimitadoras altamente confiantes foram extraídas da saída do modelo, a filtragem adicional precisa ser feita para remover imagens sobrepostas. Adicione um método chamado FilterBoundingBoxes abaixo do ParseOutputs método:
public IList<YoloBoundingBox> FilterBoundingBoxes(IList<YoloBoundingBox> boxes, int limit, float threshold)
{
}
Dentro do FilterBoundingBoxes método, comece criando uma matriz igual ao tamanho das caixas detectadas e marcando todos os slots como ativos ou prontos para processamento.
var activeCount = boxes.Count;
var isActiveBoxes = new bool[boxes.Count];
for (int i = 0; i < isActiveBoxes.Length; i++)
isActiveBoxes[i] = true;
Em seguida, classifique a lista com suas caixas delimitadoras em ordem decrescente com base no nível de confiança.
var sortedBoxes = boxes.Select((b, i) => new { Box = b, Index = i })
.OrderByDescending(b => b.Box.Confidence)
.ToList();
Depois disso, crie uma lista para manter os resultados filtrados.
var results = new List<YoloBoundingBox>();
Comece a processar cada caixa delimitadora iterando em cada uma das caixas delimitadoras.
for (int i = 0; i < boxes.Count; i++)
{
}
Dentro desse loop for, verifique se a caixa delimitadora atual pode ser processada.
if (isActiveBoxes[i])
{
}
Nesse caso, adicione a caixa delimitadora à lista de resultados. Se os resultados excederem o limite especificado de caixas a serem extraídas, interrompa o loop. Adicione o código a seguir dentro da instrução if.
var boxA = sortedBoxes[i].Box;
results.Add(boxA);
if (results.Count >= limit)
break;
Caso contrário, examine as caixas delimitadoras adjacentes. Adicione o seguinte código abaixo da verificação do limite da caixa.
for (var j = i + 1; j < boxes.Count; j++)
{
}
Assim como a primeira caixa, se a caixa adjacente estiver ativa ou pronta para ser processada, use o IntersectionOverUnion método para verificar se a primeira caixa e a segunda caixa excedem o limite especificado. Adicione o código a seguir ao loop for mais interno.
if (isActiveBoxes[j])
{
var boxB = sortedBoxes[j].Box;
if (IntersectionOverUnion(boxA.Rect, boxB.Rect) > threshold)
{
isActiveBoxes[j] = false;
activeCount--;
if (activeCount <= 0)
break;
}
}
Fora do loop for mais interno que verifica as caixas delimitadoras adjacentes, veja se há alguma caixa delimitadora restante para ser processada. Caso contrário, saia do loop externo.
if (activeCount <= 0)
break;
Por fim, retorne os resultados fora do loop inicial do método FilterBoundingBoxes:
return results;
Ótimo! Agora é hora de usar esse código junto com o modelo para pontuação.
Usar o modelo para pontuação
Assim como no pós-processamento, há algumas etapas na pontuação. Para ajudar com isso, adicione uma classe que conterá a lógica de pontuação ao seu projeto.
No Gerenciador de Soluções, clique com o botão direito do mouse no projeto e selecione Adicionar>Novo Item.
Na caixa de diálogo Adicionar Novo Item , selecione Classe e altere o campo Nome para OnnxModelScorer.cs. Em seguida, selecione Adicionar.
O arquivo OnnxModelScorer.cs é aberto no editor de código. Adicione as seguintes
usingdiretivas à parte superior do OnnxModelScorer.cs:using System; using System.Collections.Generic; using System.Linq; using Microsoft.ML; using Microsoft.ML.Data; using ObjectDetection.DataStructures; using ObjectDetection.YoloParser;Dentro da definição de
OnnxModelScorerclasse, adicione as variáveis a seguir.private readonly string imagesFolder; private readonly string modelLocation; private readonly MLContext mlContext; private IList<YoloBoundingBox> _boundingBoxes = new List<YoloBoundingBox>();Diretamente abaixo disso, crie um construtor para a
OnnxModelScorerclasse que inicializará as variáveis definidas anteriormente.public OnnxModelScorer(string imagesFolder, string modelLocation, MLContext mlContext) { this.imagesFolder = imagesFolder; this.modelLocation = modelLocation; this.mlContext = mlContext; }Depois de criar o construtor, defina alguns structs que contêm variáveis relacionadas às configurações de imagem e modelo. Crie um struct chamado
ImageNetSettingspara conter a altura e a largura esperadas como entrada para o modelo.public struct ImageNetSettings { public const int imageHeight = 416; public const int imageWidth = 416; }Depois disso, crie outro struct chamado
TinyYoloModelSettingsque contém os nomes das camadas de entrada e saída do modelo. Para visualizar o nome das camadas de entrada e saída do modelo, você pode usar uma ferramenta como o Netron.public struct TinyYoloModelSettings { // for checking Tiny yolo2 Model input and output parameter names, //you can use tools like Netron, // which is installed by Visual Studio AI Tools // input tensor name public const string ModelInput = "image"; // output tensor name public const string ModelOutput = "grid"; }Em seguida, crie o primeiro conjunto de métodos usados para pontuação. Crie o
LoadModelmétodo dentro de suaOnnxModelScorerclasse.private ITransformer LoadModel(string modelLocation) { }Dentro do
LoadModelmétodo, adicione o código a seguir para registro em log.Console.WriteLine("Read model"); Console.WriteLine($"Model location: {modelLocation}"); Console.WriteLine($"Default parameters: image size=({ImageNetSettings.imageWidth},{ImageNetSettings.imageHeight})");Pipelines do ML.NET precisam conhecer o esquema de dados para funcionar quando o método
Fité chamado. Nesse caso, um processo semelhante ao treinamento será usado. No entanto, como nenhum treinamento real está acontecendo, é aceitável usar um valor vazioIDataView. Crie um novoIDataViewpara o pipeline a partir de uma lista vazia.var data = mlContext.Data.LoadFromEnumerable(new List<ImageNetData>());Abaixo disso, defina o pipeline. O pipeline consistirá em quatro transformações.
-
LoadImagescarrega a imagem como um Bitmap. -
ResizeImagesredimensiona a imagem para o tamanho especificado (nesse caso,416 x 416). -
ExtractPixelsaltera a representação de pixel da imagem de um Bitmap para um vetor numérico. -
ApplyOnnxModelcarrega o modelo ONNX e o usa para pontuar nos dados fornecidos.
Defina o
LoadModelpipeline no método abaixo dadatavariável.var pipeline = mlContext.Transforms.LoadImages(outputColumnName: "image", imageFolder: "", inputColumnName: nameof(ImageNetData.ImagePath)) .Append(mlContext.Transforms.ResizeImages(outputColumnName: "image", imageWidth: ImageNetSettings.imageWidth, imageHeight: ImageNetSettings.imageHeight, inputColumnName: "image")) .Append(mlContext.Transforms.ExtractPixels(outputColumnName: "image")) .Append(mlContext.Transforms.ApplyOnnxModel(modelFile: modelLocation, outputColumnNames: new[] { TinyYoloModelSettings.ModelOutput }, inputColumnNames: new[] { TinyYoloModelSettings.ModelInput }));Agora é hora de instanciar o modelo para pontuação. Chame o
Fitmétodo no pipeline e retorne-o para processamento adicional.var model = pipeline.Fit(data); return model;-
Depois que o modelo é carregado, ele pode ser usado para fazer previsões. Para facilitar esse processo, crie um método chamado PredictDataUsingModel abaixo do LoadModel método.
private IEnumerable<float[]> PredictDataUsingModel(IDataView testData, ITransformer model)
{
}
Dentro do código a PredictDataUsingModelseguir, adicione o seguinte código para registro em log.
Console.WriteLine($"Images location: {imagesFolder}");
Console.WriteLine("");
Console.WriteLine("=====Identify the objects in the images=====");
Console.WriteLine("");
Em seguida, use o Transform método para pontuar os dados.
IDataView scoredData = model.Transform(testData);
Extraia as probabilidades previstas e retorne-as para processamento adicional.
IEnumerable<float[]> probabilities = scoredData.GetColumn<float[]>(TinyYoloModelSettings.ModelOutput);
return probabilities;
Agora que ambas as etapas estão configuradas, combine-as em um único método. Abaixo do PredictDataUsingModel método, adicione um novo método chamado Score.
public IEnumerable<float[]> Score(IDataView data)
{
var model = LoadModel(modelLocation);
return PredictDataUsingModel(data, model);
}
Quase lá! Agora é hora de colocar tudo em uso.
Detectar objetos
Agora que toda a configuração está concluída, é hora de detectar alguns objetos.
Pontuar e analisar saídas de modelo
Abaixo da criação da mlContext variável, adicione uma instrução try-catch.
try
{
}
catch (Exception ex)
{
Console.WriteLine(ex.ToString());
}
Dentro do try bloco, comece a implementar a lógica de detecção de objetos. Primeiro, carregue os dados em um IDataView.
IEnumerable<ImageNetData> images = ImageNetData.ReadFromFile(imagesFolder);
IDataView imageDataView = mlContext.Data.LoadFromEnumerable(images);
Em seguida, crie uma instância OnnxModelScorer e use-a para pontuar os dados carregados.
// Create instance of model scorer
var modelScorer = new OnnxModelScorer(imagesFolder, modelFilePath, mlContext);
// Use model to score data
IEnumerable<float[]> probabilities = modelScorer.Score(imageDataView);
Agora é hora da etapa pós-processamento. Crie uma instância YoloOutputParser e use-a para processar a saída do modelo.
YoloOutputParser parser = new YoloOutputParser();
var boundingBoxes =
probabilities
.Select(probability => parser.ParseOutputs(probability))
.Select(boxes => parser.FilterBoundingBoxes(boxes, 5, .5F));
Depois que a saída do modelo tiver sido processada, é hora de desenhar as caixas delimitadoras nas imagens.
Visualizar previsões
Depois que o modelo tiver avaliado as imagens e os resultados tiverem sido processados, as caixas delimitadoras deverão ser desenhadas na imagem. Para fazer isso, adicione um método chamado DrawBoundingBox abaixo do GetAbsolutePath método dentro de Program.cs.
void DrawBoundingBox(string inputImageLocation, string outputImageLocation, string imageName, IList<YoloBoundingBox> filteredBoundingBoxes)
{
}
Primeiro, carregue a imagem e obtenha as dimensões de altura e largura no DrawBoundingBox método.
Image image = Image.FromFile(Path.Combine(inputImageLocation, imageName));
var originalImageHeight = image.Height;
var originalImageWidth = image.Width;
Em seguida, crie um loop for-each para iterar em cada uma das caixas delimitadoras detectadas pelo modelo.
foreach (var box in filteredBoundingBoxes)
{
}
Dentro do loop for-each, obtenha as dimensões da caixa delimitadora.
var x = (uint)Math.Max(box.Dimensions.X, 0);
var y = (uint)Math.Max(box.Dimensions.Y, 0);
var width = (uint)Math.Min(originalImageWidth - x, box.Dimensions.Width);
var height = (uint)Math.Min(originalImageHeight - y, box.Dimensions.Height);
Como as dimensões da caixa delimitadora correspondem à entrada do modelo, 416 x 416dimensione as dimensões da caixa delimitadora para corresponder ao tamanho real da imagem.
x = (uint)originalImageWidth * x / OnnxModelScorer.ImageNetSettings.imageWidth;
y = (uint)originalImageHeight * y / OnnxModelScorer.ImageNetSettings.imageHeight;
width = (uint)originalImageWidth * width / OnnxModelScorer.ImageNetSettings.imageWidth;
height = (uint)originalImageHeight * height / OnnxModelScorer.ImageNetSettings.imageHeight;
Em seguida, defina um modelo para o texto que será exibido acima de cada caixa delimitadora. O texto conterá a classe do objeto dentro da respectiva caixa delimitadora, bem como a confiabilidade.
string text = $"{box.Label} ({(box.Confidence * 100).ToString("0")}%)";
Para desenhar na imagem, converta-a em um Graphics objeto.
using (Graphics thumbnailGraphic = Graphics.FromImage(image))
{
}
Dentro do using bloco de código, ajuste as configurações de objeto do Graphics gráfico.
thumbnailGraphic.CompositingQuality = CompositingQuality.HighQuality;
thumbnailGraphic.SmoothingMode = SmoothingMode.HighQuality;
thumbnailGraphic.InterpolationMode = InterpolationMode.HighQualityBicubic;
Abaixo disso, defina as opções de fonte e cor para o texto e a caixa delimitadora.
// Define Text Options
Font drawFont = new Font("Arial", 12, FontStyle.Bold);
SizeF size = thumbnailGraphic.MeasureString(text, drawFont);
SolidBrush fontBrush = new SolidBrush(Color.Black);
Point atPoint = new Point((int)x, (int)y - (int)size.Height - 1);
// Define BoundingBox options
Pen pen = new Pen(box.BoxColor, 3.2f);
SolidBrush colorBrush = new SolidBrush(box.BoxColor);
Crie e preencha um retângulo acima da caixa delimitadora para conter o texto usando o FillRectangle método. Isso ajudará a contrastar o texto e melhorar a legibilidade.
thumbnailGraphic.FillRectangle(colorBrush, (int)x, (int)(y - size.Height - 1), (int)size.Width, (int)size.Height);
Em seguida, desenhe o texto e a caixa delimitadora na imagem usando os métodos DrawString e DrawRectangle.
thumbnailGraphic.DrawString(text, drawFont, fontBrush, atPoint);
// Draw bounding box on image
thumbnailGraphic.DrawRectangle(pen, x, y, width, height);
Fora do loop for-each, adicione código para salvar as imagens no outputFolder.
if (!Directory.Exists(outputImageLocation))
{
Directory.CreateDirectory(outputImageLocation);
}
image.Save(Path.Combine(outputImageLocation, imageName));
Para obter comentários adicionais de que o aplicativo está fazendo previsões conforme o esperado em tempo de execução, adicione um método chamado LogDetectedObjects abaixo do DrawBoundingBox método no arquivo Program.cs para gerar os objetos detectados para o console.
void LogDetectedObjects(string imageName, IList<YoloBoundingBox> boundingBoxes)
{
Console.WriteLine($".....The objects in the image {imageName} are detected as below....");
foreach (var box in boundingBoxes)
{
Console.WriteLine($"{box.Label} and its Confidence score: {box.Confidence}");
}
Console.WriteLine("");
}
Agora que você tem métodos auxiliares para criar comentários visuais a partir das previsões, adicione um for-loop para iterar sobre cada uma das imagens pontuadas.
for (var i = 0; i < images.Count(); i++)
{
}
Dentro do loop for, obtenha o nome do arquivo de imagem e as caixas delimitadoras associadas a ele.
string imageFileName = images.ElementAt(i).Label;
IList<YoloBoundingBox> detectedObjects = boundingBoxes.ElementAt(i);
Abaixo disso, use o DrawBoundingBox método para desenhar as caixas delimitadoras na imagem.
DrawBoundingBox(imagesFolder, outputFolder, imageFileName, detectedObjects);
Por fim, use o LogDetectedObjects método para gerar previsões para o console.
LogDetectedObjects(imageFileName, detectedObjects);
Após a instrução try-catch, adicione lógica adicional para indicar que o processo foi concluído.
Console.WriteLine("========= End of Process..Hit any Key ========");
É isso!
Results
Depois de seguir as etapas anteriores, execute seu aplicativo de console (Ctrl + F5). Seus resultados devem ser semelhantes ao seguinte resultado. Você pode ver avisos ou mensagens de processamento, mas essas mensagens foram removidas dos seguintes resultados para maior clareza.
=====Identify the objects in the images=====
.....The objects in the image image1.jpg are detected as below....
car and its Confidence score: 0.9697262
car and its Confidence score: 0.6674225
person and its Confidence score: 0.5226039
car and its Confidence score: 0.5224892
car and its Confidence score: 0.4675332
.....The objects in the image image2.jpg are detected as below....
cat and its Confidence score: 0.6461141
cat and its Confidence score: 0.6400049
.....The objects in the image image3.jpg are detected as below....
chair and its Confidence score: 0.840578
chair and its Confidence score: 0.796363
diningtable and its Confidence score: 0.6056048
diningtable and its Confidence score: 0.3737402
.....The objects in the image image4.jpg are detected as below....
dog and its Confidence score: 0.7608147
person and its Confidence score: 0.6321323
dog and its Confidence score: 0.5967442
person and its Confidence score: 0.5730394
person and its Confidence score: 0.5551759
========= End of Process..Hit any Key ========
Para ver as imagens com caixas delimitadoras, navegue até o diretório assets/images/output/. Veja abaixo um exemplo de uma das imagens processadas.

Parabéns! Agora você criou com êxito um modelo de machine learning para detecção de objetos reutilizando um modelo pré-treinado ONNX em ML.NET.
Você pode encontrar o código-fonte deste tutorial no repositório dotnet/machinelearning-samples .
Neste tutorial, você aprendeu a:
- Compreender o problema
- Saiba o que é o ONNX e como ele funciona com ML.NET
- Entender o modelo
- Reutilizar o modelo pré-treinado
- Detectar objetos com um modelo carregado
Confira o repositório GitHub de exemplos do Machine Learning para explorar um exemplo de detecção de objetos expandido.
Colaborar conosco no GitHub
A fonte deste conteúdo pode ser encontrada no GitHub, onde você também pode criar e revisar problemas e solicitações de pull. Para obter mais informações, confira o nosso guia para colaboradores.