Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Observação
O Azure Active Directory agora é o Microsoft Entra ID. Saiba mais
Ingerir dados no Dynamics 365 Customer Insights - Data usando a conta do Azure Data Lake Storage com tabelas do Common Data Model. A ingestão de dados pode ser completa ou incremental.
Pré-requisitos
A conta do Azure Data Lake Storage deve ter o recurso namespace hierárquico habilitado. Os dados devem ser armazenados em um formato de pasta hierárquico que defina a pasta raiz e possua subpastas para cada tabela. As subpastas podem ter dados completos ou pastas de dados incrementais.
Para autenticar com uma entidade de serviço do Microsoft Entra, ele deve estar configurada em seu locatário. Para obter mais informações, consulte Conectar-se a uma conta do Azure Data Lake Storage usando uma entidade de serviço do Microsoft Entra.
Para se conectar ao armazenamento protegido por firewalls, Configurar links privados do Azure.
Se o data lake tiver conexões de link privado atualmente, o Customer Insights - Data também deverá se conectar usando um link privado, independentemente da configuração de acesso à rede.
O Azure Data Lake Storage ao qual você deseja se conectar e do qual pretende ingerir os dados deve estar na mesma região do Azure que o ambiente do Dynamics 365 Customer Insights. Não há suporte para conexões com uma pasta do Common Data Model de um data lake em uma região diferente do Azure. Para conhecer a região do Azure do ambiente, vá para Configurações>Sistema>Sobre no Customer Insights - Data.
Os dados armazenados em serviços online podem ser armazenados em um local diferente daquele onde os dados são processados ou armazenados. Ao importar ou se conectar a dados armazenados em serviços online, você concorda que os dados podem ser transferidos. Saiba mais no Microsoft Trust Center.
A entidade de serviço do Customer Insights - Data deve estar em uma das seguintes funções para acessar a conta de armazenamento. Para obter mais informações, consulte Conceder permissões à entidade de serviço para acessar a conta de armazenamento.
- Leitor de Dados do Storage Blob
- Proprietário de Dados do Storage Blob
- Colaborador de Dados do Storage Blob
Ao se conectar ao armazenamento do Azure usando a opção de assinatura do Azure, o usuário que configura a conexão da fonte de dados precisa de pelo menos as permissões Colaborador de dados do Storage Blob na conta de armazenamento.
Ao se conectar ao armazenamento do Azure usando a opção de recurso do Azure, o usuário que configura a conexão da fonte de dados precisa de pelo menos a permissão da ação Microsoft.Storage/storageAccounts/read na conta de armazenamento. Uma função interna do Azure que inclui essa ação é a função Leitor. Para só limitar acesso à ação necessária, crie uma função personalizada do Azure que só inclua essa ação.
Para obter um desempenho ideal, o tamanho de uma partição deve ser 1 GB ou menos, e o número dos arquivos de partição em uma pasta não deve exceder 1.000.
Os dados no Data Lake Storage devem seguir o padrão do Common Data Model padrão para armazenamento dos dados e ter o manifesto do Common Data Model para representar o esquema dos arquivos de dados (*.csv ou *.parquet). O manifesto deve fornecer os detalhes das tabelas, como colunas de tabela e tipos de dados, e o local do arquivo de dados e o tipo de arquivo. Para obter mais informações, consulte O manifesto do Common Data Model. Se o manifesto não estiver presente, os usuários Administradores com acesso de Proprietário de Dados de Blob de Armazenamento ou Colaborador de Dados de Blob de Armazenamento poderão definir o esquema ao ingerir os dados.
Observação
Se algum dos campos nos arquivos .parquet tiver o tipo de dados Int96, talvez os dados não sejam exibidos na página Tabelas. Recomendamos o uso de tipos de dados padrão, como o formato do carimbo de data/hora Unix (que representa o tempo como o número de segundos a partir de 1º de janeiro de 1970, à meia-noite UTC).
Limitações
- O Customer Insights - Data não dá suporte a colunas do tipo decimal com precisão superior a 16.
Conectar ao Azure Data Lake Storage
Nomes de conexão de dados, caminhos de dados, como pastas dentro de um contêiner, e nomes de tabela devem usar nomes que comecem com uma letra. Os nomes só podem conter letras, números e sublinhados (_). Os caracteres especiais não são compatíveis.
Acesse Dados>Origens de dados.
Selecione Adicionar uma fonte de dados.
Selecione Tabelas de Common Data Model do Azure Data Lake.

Insira um Nome da fonte de dados e uma Descrição opcional. O nome é referenciado em processos downstream e não será possível alterá-lo após a criação da fonte de dados.
Escolha uma das opções a seguir para Conectar seu armazenamento usando. Para obter mais informações, consulte Conectar-se a uma conta do Azure Data Lake Storage usando uma entidade de serviço do Microsoft Entra.
- Recurso do Azure: insira o ID do Recurso.
- Assinatura do Azure: selecione Assinatura e, em seguida, Grupo de recursos e Conta de armazenamento.
Observação
Você precisa de uma das seguintes funções para o contêiner a fim de criar a fonte de dados:
- O Leitor de Dados do Blob de Armazenamento é suficiente para ler de uma conta de armazenamento e ingerir os dados para o Customer Insights - Data.
- O Proprietário ou Colaborador de Dados do Blob de Armazenamento é necessário se você quiser editar os arquivos de manifesto diretamente no Customer Insights - Data.
Ter a função na conta de armazenamento fornece a mesma função em todos os contêineres.
Escolha o nome do Contêiner que contém os dados e o esquema (arquivo model.json ou manifest.json) de onde importar dados.
Observação
Qualquer arquivo model.json ou manifest.json associado a outra fonte de dados no ambiente não será mostrado na lista. Contudo, o mesmo arquivo model.json file ou manifest.json pode ser usado para fontes de dados em vários ambientes.
Opcionalmente, se você quiser ingerir dados de uma conta de armazenamento por meio de um Link Privado do Azure, selecione Habilitar Link Privado. Para obter mais informações, vá até Links Privados.
Para criar um novo esquema, vá para Criar um novo arquivo de esquema.
Para usar um esquema existente, navegue até a pasta que contém o arquivo model.json ou manifest.cdm.json. Você pode pesquisar em um diretório para localizar o arquivo.
Selecione o arquivo json e selecione Avançar. Uma lista de tabelas disponíveis é exibida.
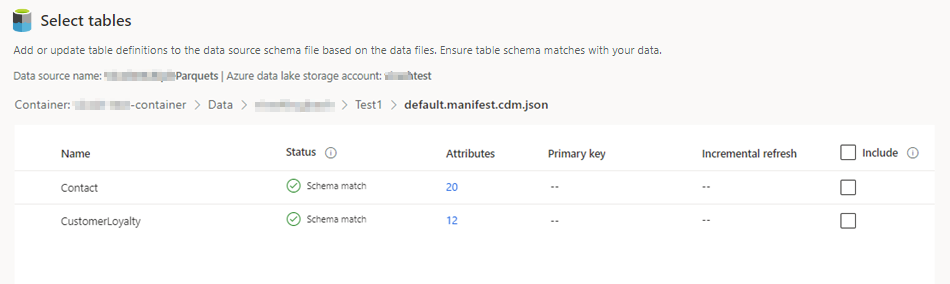
Selecione as tabelas que deseja incluir.
Dica
Para editar uma tabela em uma interface de edição do JSON, selecione a tabela e, depois, Editar arquivo de esquema. Faça as alterações e selecione Salvar.
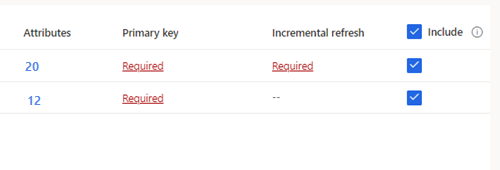
Para tabelas selecionadas que exigem ingestão incremental, Obrigatório é exibido sob Atualização incremental. Para cada uma dessas tabelas, consulte Configurar uma atualização incremental para fontes de dados do Azure Data Lake.
Para tabelas selecionadas nas quais uma chave primária não esteja definida, Obrigatório é exibido em Chave primária. Para cada uma destas tabelas:
- Selecione Obrigatória. O painel Editar tabela é exibido.
- Escolha a Chave primária. A chave primária é um atributo exclusivo da tabela. Para um atributo ser uma chave primária válida, ele não deve ter valores duplicados, valores ausentes ou valores nulos. Os atributos de tipo de dados de cadeia de caracteres, inteiro e GUID são compatíveis como chaves primárias.
- Opcionalmente, altere o padrão de partição.
- Selecione Fechar para salvar e fechar o painel.
Selecione o número de Colunas para cada tabela incluída. A página Gerenciar atributos é exibida.
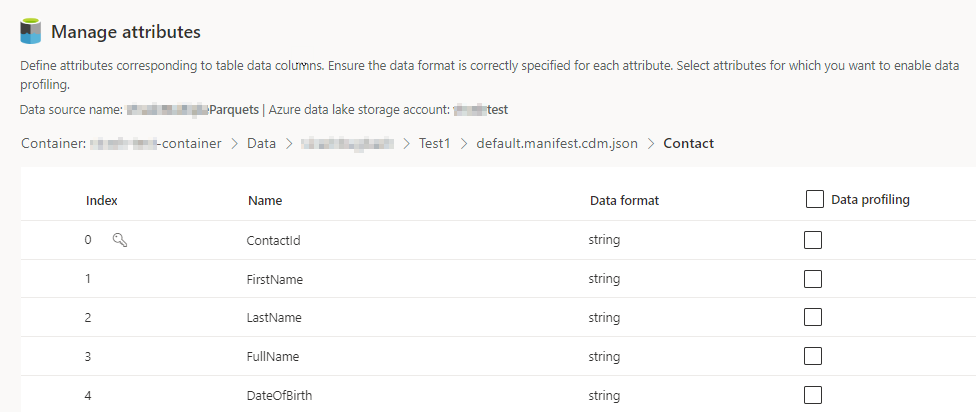
- Crie colunas, edite ou exclua colunas existentes. Você pode alterar o nome, o formato de dados ou adicionar um tipo semântico.
- Para habilitar análises e outros recursos, selecione Criação de perfil de dados para toda a tabela ou para colunas específicas. Por padrão, nenhuma tabela está habilitada para criação de perfil de dados.
- Selecione Concluído.
Selecione Salvar. A página Fontes de dados abre mostrando a nova fonte de dados no status Atualizando.
Dica
Existem status para tarefas e processos. A maioria dos processos depende de outros processos upstream, como atualizações de fontes de dados e perfis de dados.
Selecione o status para abrir o painel Detalhes de progresso e exibir o progresso das tarefas. Para cancelar o trabalho, selecione Cancelar trabalho na parte inferior do painel.
Em cada tarefa, você pode selecionar Ver detalhes para obter mais informações sobre o andamento, como tempo de processamento, a data do último processamento e possíveis erros e avisos aplicáveis associados à tarefa ou ao processo. Selecione Exibir status do sistema na parte inferior do painel para ver outros processos no sistema.

O carregamento de dados pode levar algum tempo. Após uma atualização bem-sucedida, os dados ingeridos podem ser revisados na página Tabelas.
Criar um arquivo de esquema
Selecione Criar arquivo de esquema.
Insira um nome para o arquivo e selecione Salvar.
Selecione Nova tabela. O painel Nova Tabela é exibido.
Insira o nome da tabela e escolha a Localização de arquivos de dados.
- Vários arquivos .csv ou .parquet: navegue até a pasta raiz, selecione o tipo de padrão e insira a expressão.
- Arquivos .csv ou .parquet únicos: navegue até o arquivo .csv ou .parquet e selecione-o.
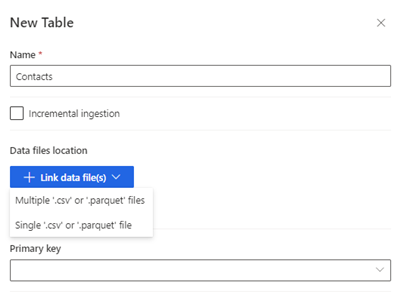
Selecione Salvar.
Selecione definir os atributos para adicionar manualmente os atributos ou selecione gerá-los automaticamente. Para definir os atributos, insira um nome, selecione o formato de dados e o tipo semântico opcional. Para atributos gerados automaticamente:
Depois que os atributos forem gerados automaticamente, selecione Revisar atributos. A página Gerenciar atributos é exibida.
Garanta que o formato de dados esteja correto para cada atributo.
Para habilitar análises e outros recursos, selecione Criação de perfil de dados para toda a tabela ou para colunas específicas. Por padrão, nenhuma tabela está habilitada para criação de perfil de dados.
Selecione Concluído. A página Selecionar tabelas é exibida.
Continue adicionando tabelas e colunas, se aplicável.
Depois que todas as tabelas tiverem sido adicionadas, selecione Incluir para incluir as tabelas na ingestão de fonte de dados.
Para tabelas selecionadas que exigem ingestão incremental, Obrigatório é exibido sob Atualização incremental. Para cada uma dessas tabelas, consulte Configurar uma atualização incremental para fontes de dados do Azure Data Lake.
Para tabelas selecionadas nas quais uma chave primária não esteja definida, Obrigatório é exibido em Chave primária. Para cada uma destas tabelas:
- Selecione Obrigatória. O painel Editar tabela é exibido.
- Escolha a Chave primária. A chave primária é um atributo exclusivo da tabela. Para um atributo ser uma chave primária válida, ele não deve ter valores duplicados, valores ausentes ou valores nulos. Os atributos de tipo de dados de cadeia de caracteres, inteiro e GUID são compatíveis como chaves primárias.
- Opcionalmente, altere o padrão de partição.
- Selecione Fechar para salvar e fechar o painel.
Selecione Salvar. A página Fontes de dados abre mostrando a nova fonte de dados no status Atualizando.
Dica
Existem status para tarefas e processos. A maioria dos processos depende de outros processos upstream, como atualizações de fontes de dados e perfis de dados.
Selecione o status para abrir o painel Detalhes de progresso e exibir o progresso das tarefas. Para cancelar o trabalho, selecione Cancelar trabalho na parte inferior do painel.
Em cada tarefa, você pode selecionar Ver detalhes para obter mais informações sobre o andamento, como tempo de processamento, a data do último processamento e possíveis erros e avisos aplicáveis associados à tarefa ou ao processo. Selecione Exibir status do sistema na parte inferior do painel para ver outros processos no sistema.
O carregamento de dados pode levar algum tempo. Após uma atualização bem-sucedida, os dados ingeridos podem ser revisados na página Tabelas>de Dados.
Editar uma fonte de dados do Azure Data Lake Storage
Você pode atualizar a opção Conecte-se à conta de armazenamento usando. Para obter mais informações, consulte Conectar-se a uma conta do Azure Data Lake Storage usando uma entidade de serviço do Microsoft Entra. Para conectar-se a um contêiner diferente na sua conta de armazenamento ou alterar o nome da conta, crie uma nova conexão da fonte de dados.
Acesse Dados>Origens de dados. Ao lado da fonte de dados que você deseja atualizar, selecione Editar
Altere qualquer uma das seguintes informações:
Descrição
Conecte seu armazenamento usando e informações de conexão. Você não pode alterar informações de Contêiner ao atualizar a conexão.
Nota
Uma das funções a seguir deve ser atribuída à conta de armazenamento ou contêiner:
- Leitor de Dados do Storage Blob
- Proprietário de Dados do Storage Blob
- Colaborador de Dados do Storage Blob
Habilite o Link Privado se quiser ingerir dados de uma conta de armazenamento por meio de um Link Privado do Azure. Para obter mais informações, vá até Links Privados.
Selecione Avançar.
Altere qualquer uma das seguintes informações:
Navegue até um arquivo model.json ou manifest.json diferente com um conjunto diferente de tabelas do contêiner.
Para adicionar mais tabelas para ingestão, selecione Nova tabela.
Para remover quaisquer tabelas já selecionadas se não houver dependências, selecione a tabela e escolha Excluir.
Importante
Se houver dependências no arquivo model.json ou manifest.json existente e no conjunto de tabelas, você verá uma mensagem de erro e não será possível selecionar outro arquivo model.json ou manifest.json. Remova essas dependências antes de alterar o arquivo model.json ou manifest.json ou criar uma fonte de dados com o arquivo model.json ou manifest.json que deseja usar para evitar a remoção das dependências.
Para alterar a localização do arquivo de dados ou a chave primária, selecione Editar.
Para alterar os dados de ingestão incremental, consulte Configurar uma atualização incremental para fontes de dados do Azure Data Lake.
Altere apenas o nome da tabela para corresponder ao nome da tabela no arquivo .json.
Observação
Sempre mantenha o nome da tabela igual ao nome da tabela no arquivo model.json ou manifest.json após a ingestão. O Customer Insights - Data valida todos os nomes de tabela com model.json ou manifest.json durante cada atualização do sistema. Se o nome de uma tabela for alterado, ocorrerá um erro porque o Customer Insights - Data não consegue encontrar o novo nome da tabela no arquivo .json. Se o nome de uma tabela ingerida tiver sido alterado acidentalmente, edite o nome da tabela de acordo com o nome no arquivo .json.
Selecione Colunas para adicioná-las ou alterá-las ou para habilitar a criação de perfil de dados. Em seguida, selecione Concluído.
Selecione Salvar para aplicar as alterações e voltar à página Fontes de dados.
Dica
Existem status para tarefas e processos. A maioria dos processos depende de outros processos upstream, como atualizações de fontes de dados e perfis de dados.
Selecione o status para abrir o painel Detalhes de progresso e exibir o progresso das tarefas. Para cancelar o trabalho, selecione Cancelar trabalho na parte inferior do painel.
Em cada tarefa, você pode selecionar Ver detalhes para obter mais informações sobre o andamento, como tempo de processamento, a data do último processamento e possíveis erros e avisos aplicáveis associados à tarefa ou ao processo. Selecione Exibir status do sistema na parte inferior do painel para ver outros processos no sistema.
Atualizar uma fonte de dados quando o esquema for alterado
Se o esquema dos dados de origem for alterado após a criação da conexão da fonte de dados, um erro de incompatibilidade de esquema ou incompatibilidade de dados aparecerá solicitando que você atualize a conexão da fonte de dados. O erro "As colunas nos dados de origem foram alteradas" é mostrado nos detalhes da tarefa. As alterações de esquema incluem atualizações em colunas, nomes de colunas e tipos de dados de coluna.
Acesse Dados>Origens de dados. Selecione Editar ao lado da fonte de dados com os erros. Em seguida, selecione Próximo.
Selecione a tabela que tem erros.
Selecione Gerar automaticamente os atributos e confirme.
Depois que a geração do atributo for concluída, selecione Concluído.
Selecione Incluir na tabela e, em seguida, selecione Salvar para aplicar suas alterações e retornar à página Fontes de dados.
Evitar a formação de fragmentos de partição durante a ingestão no Data Lake
É possível que sua estratégia de particionamento do data lake possa criar centenas de milhares de pequenas partições, como uma nova partição para cada entidade a cada hora. Para evitar a fragmentação de partição, siga estas práticas recomendadas:
- Evite o particionamento excessivo: o particionamento deve ser baseado em colunas de baixa cardinalidade, como data ou região, em vez de campos de alta cardinalidade, como ID de entidade ou hora.
- Tamanhos de arquivo ideais de destino: para reduzir a sobrecarga de abrir e fechar muitos arquivos pequenos e melhorar o desempenho de leitura, procure arquivos de partição entre 16 MB e 1 GB.
- Use o Delta Lake, que fornece recursos de otimização automática: o Delta Lake dá suporte à preenchimento automático e otimiza recursos de gravação que gerenciam automaticamente tamanhos de arquivo e layout de partição. No Databricks Runtime 11.3 e posteriores, o Delta Lake ajusta automaticamente os tamanhos de arquivo e as partições em segundo plano.
- Reavaliar a estratégia de particionamento periodicamente: à medida que os padrões de volume de dados e acesso evoluem, sua estratégia de particionamento deve ser reavaliada. Use ferramentas como estatísticas de salto de dados e perfilamento de consultas para orientar ajustes.
Centenas de milhares de pequenas partições podem causar os seguintes sintomas:
- Degradação de desempenho durante a ingestão de dados e a execução da consulta.
- Aumento da sobrecarga e latência dos metadados.
- Custos operacionais mais altos devido ao armazenamento ineficiente e ao uso de computação.
- Erros quando o número de partições excede as limitações de um serviço.
- Erros de falta de memória quando o sistema tenta criar um grafo para cada partição.