Práticas recomendadas de unificação de dados
Ao configurar regras para unificar seus dados em um perfil de cliente, considere estas práticas recomendadas:
Equilibre o tempo para unificar versus completar a correspondência. A tentativa de capturar todas as correspondências possíveis leva a muitas regras e a unificação demora muito tempo.
Adicione regras progressivamente e acompanhe os resultados. Remova regras que não melhorem o resultado da partida.
Desduplicar cada tabela para que cada cliente seja representado em uma única linha.
Use normalização para padronizar variações na forma como os dados foram inseridos, como Rua x Rua x Rua x Rua.
Use correspondência difusa estrategicamente para corrigir erros de digitação e como bob@contoso.com e bob@contoso.cm. As correspondências difusas demoram mais para serem executadas do que as correspondências exatas. Sempre teste para ver se o tempo extra gasto na correspondência difusa vale a taxa de correspondência adicional.
Restrinja o escopo das correspondências com correspondência exata. Certifique-se de que cada regra com condições difusas tenha pelo menos uma condição de correspondência exata.
Não corresponda colunas que contenham dados muito repetidos. Certifique-se de que as colunas de correspondência difusa não tenham valores repetidos com frequência, como o valor padrão de um formulário "Nome".
Desempenho de unificação
Cada regra leva tempo para ser executada. Padrões como comparar todas as tabelas com todas as outras tabelas ou tentar capturar todas as correspondências de registros possíveis podem levar a longos tempos de processamento de unificação. Ele também retorna poucas ou mais correspondências em um plano que compara cada tabela a uma tabela base.
A melhor abordagem é começar com um conjunto básico de regras que você sabe que são necessárias, como comparar cada tabela com sua tabela principal. Sua tabela principal deve ser aquela com os dados mais completos e precisos. Esta tabela deve ser ordenada no topo da unificação de regras de correspondência etapa.
Adicione progressivamente várias regras e veja quanto tempo as alterações levam para serem executadas e se seus resultados melhoram. Vá para Configurações>Sistema>Status e Select Correspondência para ver quanto tempo levou a desduplicação e a correspondência para cada execução de unificação.
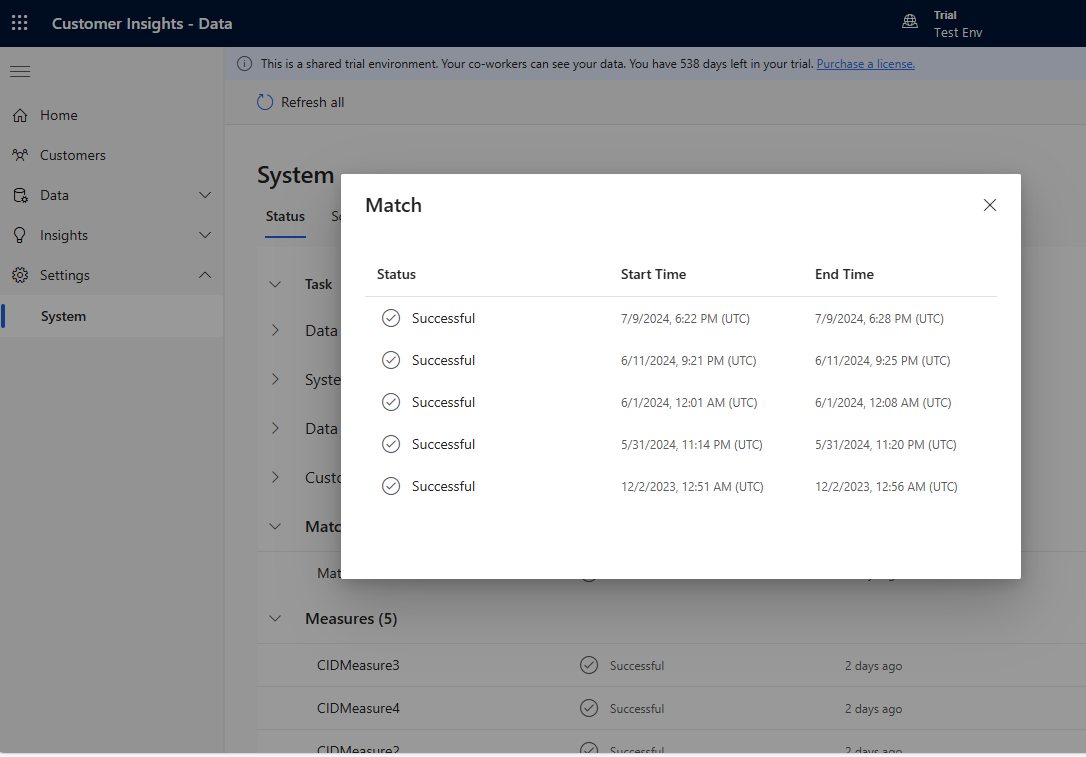
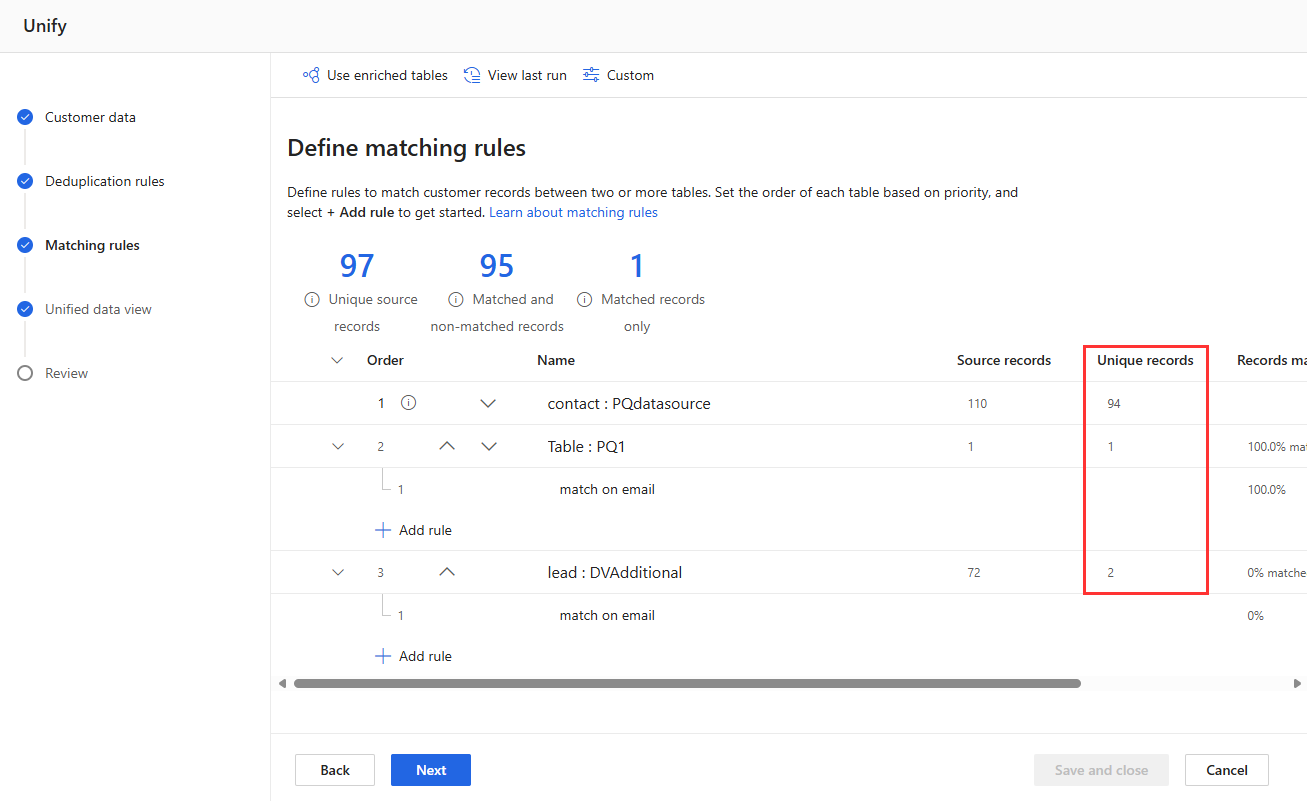
Visualize as estatísticas da regra nas páginas Regras de desduplicação e Regras de correspondência para ver se o número de Alterações de registros exclusivos. Se uma nova regra corresponder a alguns registros e a contagem exclusiva de registros não mudar, então uma regra anterior identificou essas correspondências.
Desduplicação
Use regras de desduplicação para remover registros duplicados de clientes em uma tabela para que uma única linha em cada tabela represente cada cliente. Uma boa regra identifica um cliente exclusivo.
Neste exemplo simples, os registros 1, 2 e 3 compartilham um email ou um telefone e representam a mesma pessoa.
| ID | Nome | o Telefone | |
|---|---|---|---|
| 0 | Pessoa 1 | (425) 555-1111 | AAA@A.com |
| 2 | Pessoa 1 | (425) 555-1111 | BBB@B.com |
| 3 | Pessoa 1 | (425) 555-2222 | BBB@B.com |
| 4 | Pessoa 2 | (206) 555-9999 | Person2@contoso.com |
Não queremos comparar apenas o nome, pois isso corresponderia a pessoas diferentes com o mesmo nome.
Crie a Regra 1 usando Nome e Telefone, que corresponde aos registros 1 e 2.
Crie a Regra 2 usando Nome e Email, que corresponde aos registros 2 e 3.
A combinação da Regra 1 e da Regra 2 cria um único grupo de correspondência porque elas compartilham o registro 2.
Você decide o número de regras e as condições que identificam os clientes com exclusividade. As regras exatas dependem dos dados disponíveis para comparação, da qualidade dos dados e da demora que você deseja para o processo de eliminação de duplicação.
Registros vencedores e alternativos
Depois que as regras são executadas e os registros duplicados são identificados, o processo de desduplicação seleciona uma "linha vencedora". As linhas não vencedoras são chamadas de "Linhas alternativas". Linhas alternativas são usadas na unificação de regras de correspondência etapa para combinar registros de outras tabelas com a linha vencedora. As linhas são comparadas com os dados nas linhas alternativas, além da linha vencedora.
Depois de adicionar uma regra a uma tabela, você pode configurar qual linha Select será a linha vencedora por meio de Mesclar preferências. As preferências de mesclagem são definidas por tabela. Independentemente da política de mesclagem selecionada, se houver empate por uma linha vencedora, a primeira linha na ordem dos dados será usada como desempate.
Normalização
Use a normalização para padronizar os dados para uma melhor correspondência. A normalização funciona bem em grandes conjuntos de dados.
Os dados normalizados só são usados para fins de comparação a fim de comparar registros do cliente de maneira mais eficaz. Ela não altera os dados na saída do perfil unificado de cliente final.
| Normalização | Exemplos |
|---|---|
| Numerais | Converte muitos símbolos Unicode que representam números em números simples. Exemplos: ❽ e Ⅷ são ambos normalizados para o número 8. Observação: os símbolos devem ser codificados no formato Unicode Point. |
| Símbolos | Remove símbolos e caracteres especiais. Exemplos: !?"#$%&'( )+,.-/:;<=>@^~{}`[ ] |
| Texto em letras minúsculas | Converte caracteres maiúsculos em minúsculos. Exemplo: "ESTE É UM EXEMPLO" é convertido em "este é um exemplo" |
| Tipo – Telefone | Converte telefones em formatos variados em dígitos e leva em conta variações na maneira como extensões e códigos de país/região são apresentados. Exemplo: +01 425.555.1212 = 1 (425) 555-1212 |
| Tipo – Nome | Converte mais de 500 variações de nomes e títulos em comum. Exemplos: "debby" -> "deborah" "prof" e "professor" -> "Prof." |
| Tipo – Endereço | Converte partes comuns de endereços Exemplos: "street" -> "st" e "northwest" -> "nw" |
| Tipo – Organização | Remove cerca de 50 "palavras barulhentas" de nomes de empresas, como "co", "corp", "corporação" e "ltd". |
| Unicode para ASCII | Converte caracteres Unicode no equivalente de lertra ASCII Exemplo: os caracteres 'à,' 'á,' 'â,' 'À,' 'Á,' 'Â,' 'Ã,' 'Ä,' 'Ⓐ,' e 'A' são todos convertidos para 'a.' |
| Espaço em branco | Remove todos os espaços em branco |
| Mapeamento de alias | Permite carregar uma lista personalizada de pares de cadeias de caracteres que podem ser usados para indicar cadeias de caracteres que devem sempre ser consideradas uma correspondência exata. Use o mapeamento de alias quando tiver exemplos de dados específicos que você acha que deveriam ter ou não correspondência usando um dos outros padrões de normalização. Exemplo: Scott e Scooter, ou MSFT e Microsoft. |
| Bypass personalizado | Permite carregar uma lista personalizada de cadeias de caracteres que podem ser usadas para indicar cadeias de caracteres que jamais devem ter uma correspondência. O bypass personalizado é útil quando você tem dados com valores comuns que devem ser ignorados, como um número de telefone ou um email fictício. Exemplo: nunca combine o telefone 555-1212 ou test@contoso.com |
Correspondência exata
Use a precisão para determinar o quão próximas duas strings devem estar para serem consideradas uma correspondência. A configuração de precisão padrão requer uma correspondência exata. Qualquer outro valor permite a correspondência difusa para essa condição.
A precisão pode ser definida como baixa (30% de correspondência), média (60% de correspondência) e alta (80% de correspondência). Ou você pode personalizar e definir a precisão em incrementos de 1%.
Condições de correspondência exata
As condições de correspondência exata são executadas primeiro para obter um conjunto Smaller de valores para correspondência difusa. Para serem eficazes, as condições de correspondência exata devem ter um grau razoável de exclusividade. Por exemplo, se todos os seus clientes moram no mesmo país/região, ter uma correspondência exata por país/região não ajudaria a restringir o escopo.
Colunas como campos de nome completo, e-mail, telefone ou endereço têm boa exclusividade e são ótimas colunas para usar como correspondência exata.
Certifique-se de que a coluna usada para uma condição de correspondência exata não tenha valores repetidos com frequência, como um valor padrão de "Nome" capturado por um formulário. Os insights do cliente podem criar perfis de colunas de dados para fornecer insights sobre os principais valores repetidos. Você pode habilitar o perfil de dados em conexões do Azure Data Lake (usando Modelo de Dados Comum ou formato Delta) e Synapse. O perfil de dados é executado na próxima atualização do fonte de dados. Para mais informações, acesse Perfil de dados.
Correspondência difusa
Use correspondência difusa para combinar strings próximas, mas não exatas devido a erros de digitação ou outras pequenas variações. Use a correspondência difusa estrategicamente, pois é mais lenta que as correspondências exatas. Certifique-se de pelo menos uma condição de correspondência exata em qualquer regra que tenha condições difusas.
A correspondência difusa não se destina a capturar variações de nomes como Suzzie e Suzanne. Essas variações são melhor capturadas com o padrão de normalização Tipo: Nome ou a correspondência de alias personalizada , onde os clientes podem inserir seus própria lista de variações de nomes que desejam considerar como correspondências.
Você pode adicionar condições a uma regra, como comparar Nome e Telefone. As condições dentro de uma determinada regra são condições "AND"; todas as condições devem coincidir para que as linhas correspondam. Porém, regras à parte são condições "OR". Se a Regra 1 não corresponder às linhas, as linhas serão comparadas à Regra 2.
Observação
Somente colunas do tipo de dados da cadeia de caracteres podem usar correspondência difusa. Para colunas com outros tipos de dados, como inteiro, duplo ou datetime, o campo de precisão é definido como correspondência exata e é somente leitura.
Cálculos de correspondência difusa
As correspondências difusas são feitas calculando-se a pontuação da distância de edição para duas cadeias de caracteres. Se a pontuação atingir ou exceder o limite de precisão, as cadeias de caracteres serão consideradas correspondentes.
A distância de edição é o número de edições necessárias para transformar uma cadeia de caracteres em outra, adicionando, excluindo ou alterando um caractere.
Por exemplo, as strings "Jacqueline" e "Jaclyne" têm uma distância de edição de cinco quando removemos os caracteres q, u, e, i e e e inserimos o caractere y.
O cálculo básico para determinar a pontuação da distância de edição é: (Comprimento da string base – Editar distância) / Comprimento da string base.
| Cadeia de caracteres base | Cadeia de caracteres de comparação | Pontuação |
|---|---|---|
| Jacqueline | Jaclyne | (10-4)/10=0,6 |
| fred@contoso.com | fred@contso.cm | (14-2)/14 = 0,857 |
| franklin | frank | (8-3)/8 = 0,625 |