Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Use pools personalizados do Spark para adaptar a computação para suas cargas de trabalho no Fabric. Você pode escolher o tamanho do nó, configurar o comportamento de dimensionamento automático e habilitar a alocação de executor dinâmico.
Os pools personalizados ajudam a equilibrar o desempenho e o custo, permitindo definir limites de dimensionamento que correspondem à demanda de carga de trabalho.
Observação
Os pools personalizados do Spark podem obter inícios de sessão de aproximadamente 5 segundos quando configurados como um pool dinâmico personalizado com um ambiente que usa o modo Completo para publicação de biblioteca. Sem uma configuração de pool ao vivo, os pools personalizados do Spark levam cerca de três minutos para serem iniciados.
Se você já usar pools de inicialização, os pools personalizados serão uma opção complementar quando você precisar de mais controle sobre o dimensionamento e o comportamento de dimensionamento para cargas de trabalho específicas. Use pools de inicialização para inicialização rápida e configurações padrão, e migre para pools personalizados quando precisar de ajustes de computação específicos para a carga de trabalho. Para saber mais sobre pools de inicialização, consulte Configurar pools de inicialização no Fabric.
Pré-requisitos
Para criar um pool personalizado do Spark:
- Você precisa da função de Administrador no workspace.
- Um administrador de capacidade deve habilitar pools de workspace personalizados nas configurações de Computação do Spark para a capacidade.
Para obter mais informações, consulte Configurar e gerenciar configurações de engenharia de dados e ciência de dados para capacidades do Fabric.
Criar pools personalizados do Spark
Para criar ou gerenciar o pool do Spark associado ao seu workspace:
Vá para o workspace e selecione as configurações do Workspace.
Selecione a opção Engenharia de Dados/Ciência para expandir o menu e selecione configurações do Spark.
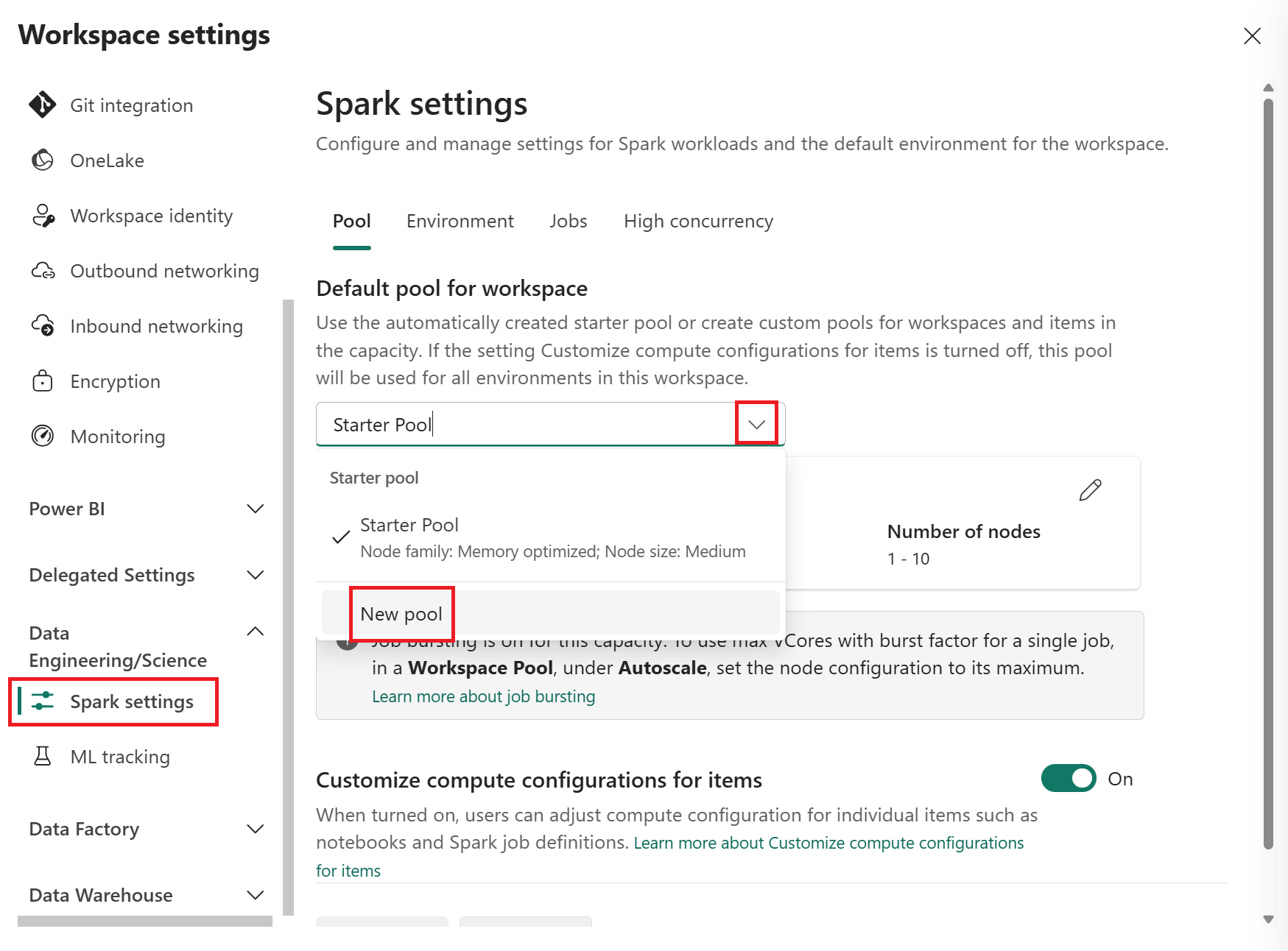
Selecione Novo Pool na lista suspensa pool padrão para o workspace para criar um novo pool personalizado do Spark. Você pode criar vários pools personalizados e selecionar qualquer um deles como o pool padrão para seu workspace.
Na página Criar novo pool , insira um nome de pool. Selecione uma família de nós (como otimizada para memória) e o tamanho do nó com base nos requisitos de carga de trabalho. Para obter mais informações sobre tamanhos de nó, consulte a seção Opções de Tamanho de Nó abaixo.
Dica
O tamanho do nó é determinado por (Unidades de Capacidade), que representam a capacidade de computação atribuída a cada nó.
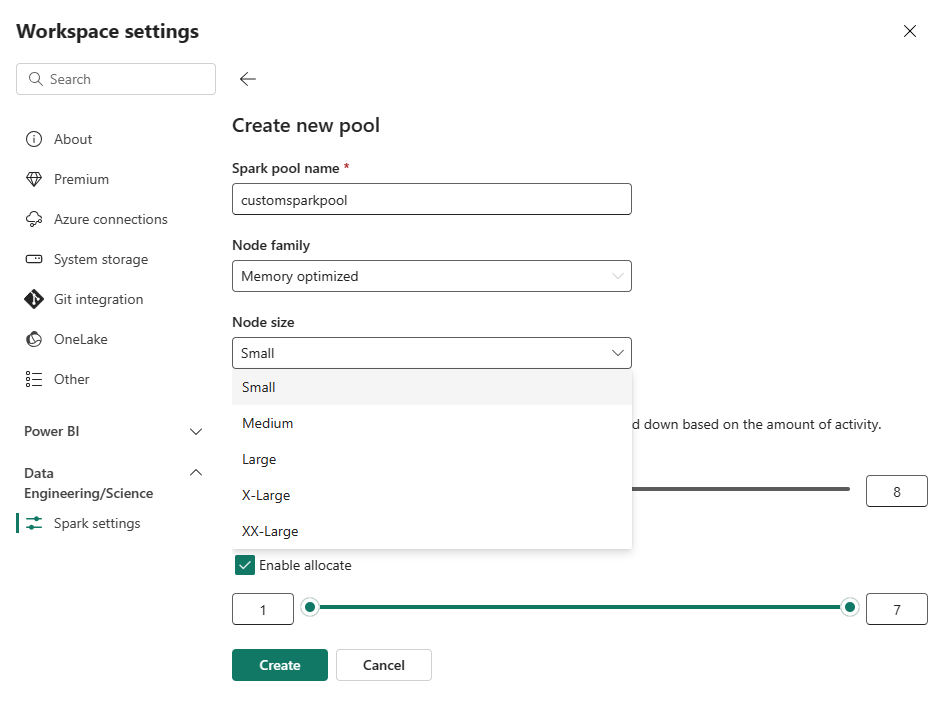
No modo de exibição de edição, configure o Dimensionamento Automático e aloque dinamicamente executores.
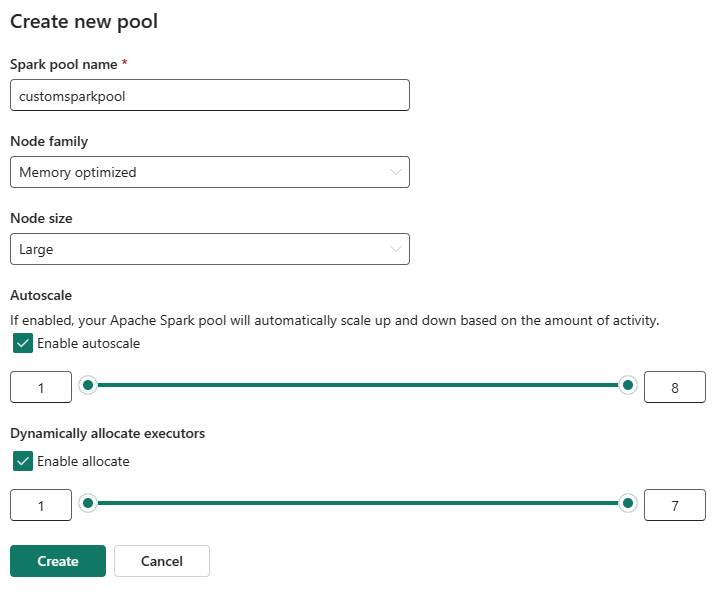
Use os controles deslizantes para aumentar ou diminuir cada configuração com base nas suas necessidades de carga de trabalho.
Se o Dimensionamento Automático estiver habilitado, o pool será dimensionado entre os valores de nó mínimo e máximo configurados com base na atividade.
Se os executores de alocação dinâmica estiverem habilitados, o Fabric ajustará a alocação do executor com base na demanda de carga de trabalho dentro dos limites configurados.
Selecione Criar.




Dica
Depois de criar um pool do Spark personalizado, o tempo de implantação da biblioteca depende do modo de publicação no ambiente anexado. O modo rápido é publicado em cerca de 5 segundos e instala bibliotecas no início da sessão. O modo completo leva de 3 a 6 minutos para publicar e implantar bibliotecas como parte da inicialização da sessão (de 1 a 3 minutos). Para obter a experiência mais rápida, configure o pool como um pool ao vivo personalizado com o modo Completo para obter inícios de sessão de aproximadamente 5 segundos.
Os pools personalizados têm uma duração padrão de autopausa de 2 minutos após a inatividade. Quando a autopausa é alcançada, a sessão expira e o cluster é desalocado. A cobrança se aplica somente enquanto a computação é usada ativamente. Atualmente, os pools personalizados do Spark no Microsoft Fabric dão suporte a um limite máximo de 200 nós, assim sendo, verifique se os valores mínimos e máximos de autoescala permanecem dentro desse limite.
Opções de tamanho do nó
Ao configurar um pool personalizado do Spark, você escolhe entre os seguintes tamanhos de nós:
| Tamanho de nó | vCores | Memória (GB) | Descrição |
|---|---|---|---|
| Pequeno | 4 | 32 | Para trabalhos leves de desenvolvimento e teste. |
| Médio | oito | 64 | Para cargas de trabalho gerais e operações típicas. |
| Grande | 16 | 128 | Para tarefas com uso intensivo de memória ou trabalhos de processamento de dados grandes. |
| Extragrande | 32 | 256 | Para as cargas de trabalho do Spark mais exigentes que necessitam de recursos significativos. |
| XX-Grande | 64 | 512 | Para as maiores cargas de trabalho do Spark que exigem a maior capacidade computacional e a memória máxima por nó. |
Conteúdo relacionado
- Saiba mais na documentação pública do Apache Spark .
- Introdução às configurações de administração do workspace Spark no Microsoft Fabric.
- Gerenciar bibliotecas em ambientes do Fabric