Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Microsoft Fabric permite operacionalizar machine learning modelos usando a função PREDICT escalonável. Essa função é compatível com a pontuação em lote em qualquer mecanismo de computação. Você pode gerar previsões em lote diretamente de um bloco de anotações Microsoft Fabric ou da página de item de um determinado modelo de ML.
Neste artigo, você aprenderá a aplicar PREDICT escrevendo código por conta própria ou por meio do uso de uma experiência de interface do usuário guiada que lida com a pontuação em lote para você.
Pré-requisitos
Obtenha uma assinatura Microsoft Fabric. Ou inscreva-se para uma avaliação gratuita Microsoft Fabric.
Faça login no Microsoft Fabric.
Alterne para o Fabric usando o alternador de experiência à esquerda inferior da sua página inicial.
Limitações
- Atualmente, a função PREDICT dá suporte apenas aos seguintes tipos de modelo de ML:
- CatBoost
- Keras
- LightGBM
- ONNX
- Profeta
- PyTorch
- Sklearn
- Spark
- Statsmodels
- TensorFlow
- XGBoost
- PREDICT requer que você salve modelos de ML no formato MLflow, com suas assinaturas preenchidas.
- PREDICT não dá suporte a modelos de ML com entradas ou saídas de vários tensores.
Como chamar PREDICT de um notebook
PREDICT dá suporte a modelos empacotados por MLflow no registro Microsoft Fabric. Se um modelo de ML já treinado e registrado existir em seu workspace, você poderá pular para a etapa 2. Caso contrário, a etapa 1 fornece código de exemplo para orientá-lo no treinamento de um modelo de regressão logística de exemplo. Use esse modelo para gerar previsões em lote no final do procedimento.
Treine um modelo de ML e registre-o no MLflow. O próximo exemplo de código usa a API do MLflow para criar um experimento de machine learning e, em seguida, inicia uma execução do MLflow para um modelo de regressão logística scikit-learn. Em seguida, a versão do modelo é armazenada e registrada no registro Microsoft Fabric. Para obter mais informações sobre modelos de treinamento e acompanhamento de seus próprios experimentos, confira como treinar modelos de ML com scikit-learn.
import mlflow import numpy as np from sklearn.linear_model import LogisticRegression from sklearn.datasets import load_diabetes from mlflow.models.signature import infer_signature mlflow.set_experiment("diabetes-demo") with mlflow.start_run() as run: lr = LogisticRegression() data = load_diabetes(as_frame=True) lr.fit(data.data, data.target) signature = infer_signature(data.data, data.target) mlflow.sklearn.log_model( lr, "diabetes-model", signature=signature, registered_model_name="diabetes-model" )Carregue dados de teste como um DataFrame do Spark. Para gerar previsões em lote com o modelo de ML treinado na etapa anterior, você precisa de dados de teste na forma de um DataFrame do Spark. No código a seguir, substitua o valor da variável
testpor seus próprios dados.# You can substitute "test" below with your own data test = spark.createDataFrame(data.frame.drop(['target'], axis=1))Crie um objeto
MLFlowTransformerpara carregar o modelo de ML para inferência. Para criar umMLFlowTransformerobjeto para gerar previsões em lotes, execute estas ações:- Especifique as
testcolunas DataFrame de que você precisa como entradas de modelo (nesse caso, todas elas). - Escolha um nome para a nova coluna de saída (nesse caso,
predictions). - Forneça o nome do modelo e a versão do modelo corretos para a geração dessas previsões.
Se você usar seu próprio modelo de ML, substitua os valores pelas colunas de entrada, nome da coluna de saída, nome do modelo e versão do modelo.
from synapse.ml.predict import MLFlowTransformer # You can substitute values below for your own input columns, # output column name, model name, and model version model = MLFlowTransformer( inputCols=test.columns, outputCol='predictions', modelName='diabetes-model', modelVersion=1 )- Especifique as
Gere previsões usando a função PREDICT. Para invocar a função PREDICT, use a API do Transformer, a API do Spark SQL ou uma UDF (função definida pelo usuário) do PySpark. As seções a seguir mostram como gerar previsões em lote com os dados de teste e o modelo de ML definidos nas etapas anteriores, usando os diferentes métodos para invocar a função PREDICT.
PREDICT com a API do Transformador
Esse código invoca a função PREDICT com a API do Transformer. Se você usar seu próprio modelo de ML, substitua os valores pelo modelo e pelos dados de teste.
# You can substitute "model" and "test" below with values
# for your own model and test data
model.transform(test).show()
PREDICT com a API do SPARK SQL
Esse código chama a função PREDICT usando a API sql do Spark. Se você usar seu próprio modelo de ML, substitua os valores por model_name, model_versione features por seu nome de modelo, versão do modelo e colunas de recursos.
Observação
Ao usar a API do Spark SQL para gerar previsões, você ainda precisará criar um MLFlowTransformer objeto, conforme mostrado na etapa 3.
from pyspark.ml.feature import SQLTransformer
# You can substitute "model_name," "model_version," and "features"
# with values for your own model name, model version, and feature columns
model_name = 'diabetes-model'
model_version = 1
features = test.columns
sqlt = SQLTransformer().setStatement(
f"SELECT PREDICT('{model_name}/{model_version}', {','.join(features)}) as predictions FROM __THIS__")
# You can substitute "test" below with your own test data
sqlt.transform(test).show()
PREDICT com uma função definida pelo usuário
Esse código chama a função PREDICT usando um UDF do PySpark. Se você estiver usando seu próprio modelo de ML, substitua os valores do modelo e das características.
from pyspark.sql.functions import col, pandas_udf, udf, lit
# You can substitute "model" and "features" below with your own values
my_udf = model.to_udf()
features = test.columns
test.withColumn("PREDICT", my_udf(*[col(f) for f in features])).show()
Gerar código PREDICT a partir da página de item de um modelo de ML
Na página de itens de qualquer modelo de ML, você pode escolher uma destas opções para iniciar a geração de previsão em lote para uma versão de modelo específica usando a função PREDICT:
- Copie um modelo de código em um notebook e personalize os parâmetros por conta própria.
- Use uma experiência de interface do usuário guiada para gerar o código PREDICT.
Usar uma experiência de interface do usuário guiada
A experiência de interface do usuário guiada orienta você por estas etapas:
- Selecione os dados de origem para pontuação.
- Mapeie os dados corretamente para as entradas do modelo de ML.
- Especifique o destino das saídas do modelo.
- Crie um notebook que use PREDICT para gerar e armazenar resultados de previsão.
Para usar a experiência guiada,
Navegue até a página de itens de uma versão específica do modelo de ML.
No menu suspenso Aplicar esta versão, selecione Aplicar este modelo usando o assistente.

Na etapa "Selecionar tabela de entrada", a janela "Aplicar previsões de modelo de ML" é aberta.
Selecione uma tabela de entrada de um lakehouse em seu espaço de trabalho atual.
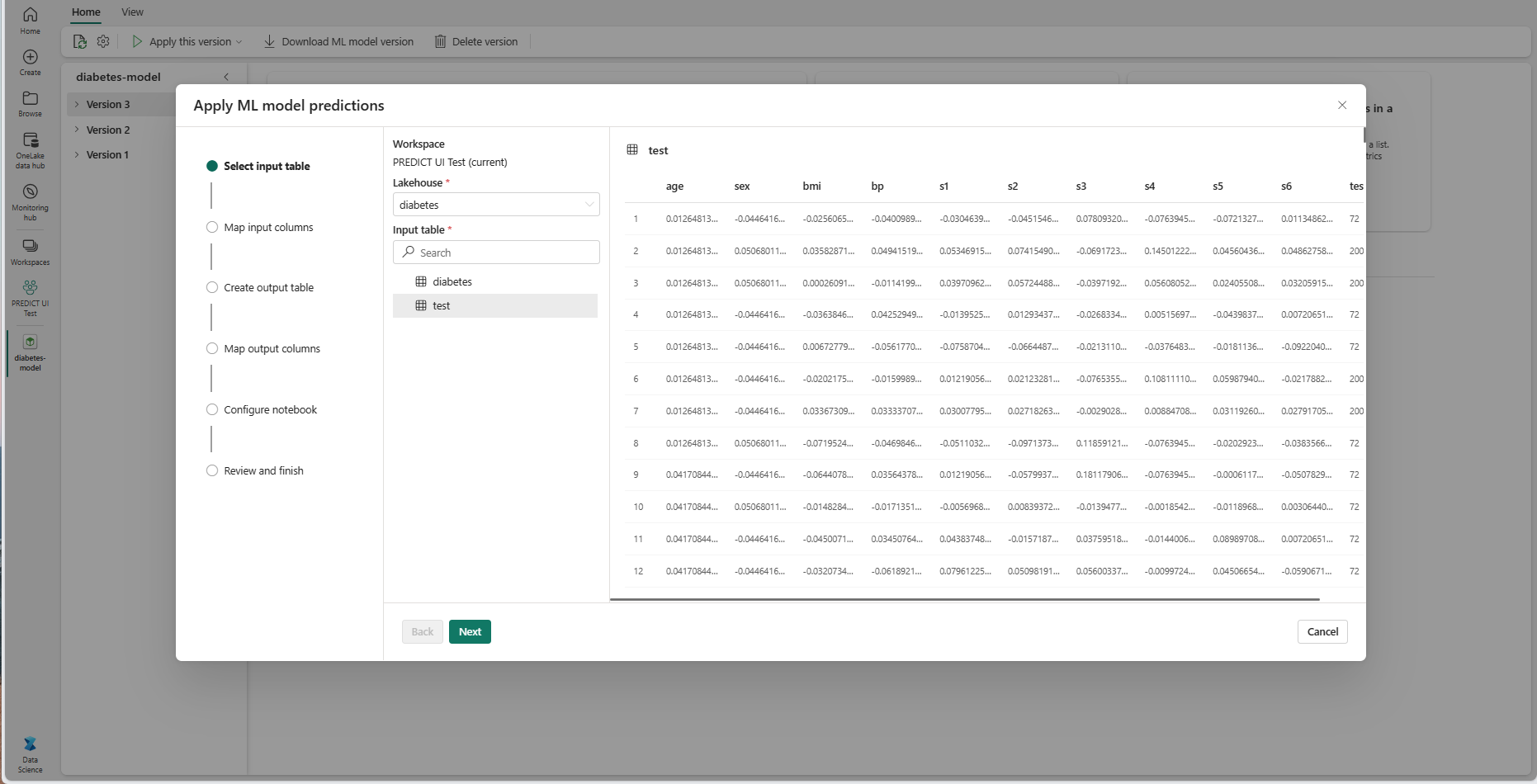
Selecione Avançar para ir para a etapa "Mapear colunas de entrada".
Mapeie os nomes das colunas da tabela de origem para os campos de entrada do modelo de aprendizado de máquina (ML), extraídos da assinatura do modelo. Você deve fornecer uma coluna de entrada para todos os campos obrigatórios do modelo. Além disso, os tipos de dados da coluna de origem devem corresponder aos tipos de dados esperados do modelo.
Dica
O assistente preenche previamente esse mapeamento se os nomes das colunas da tabela de entrada corresponderem aos nomes das colunas registrados na assinatura do modelo de ML.
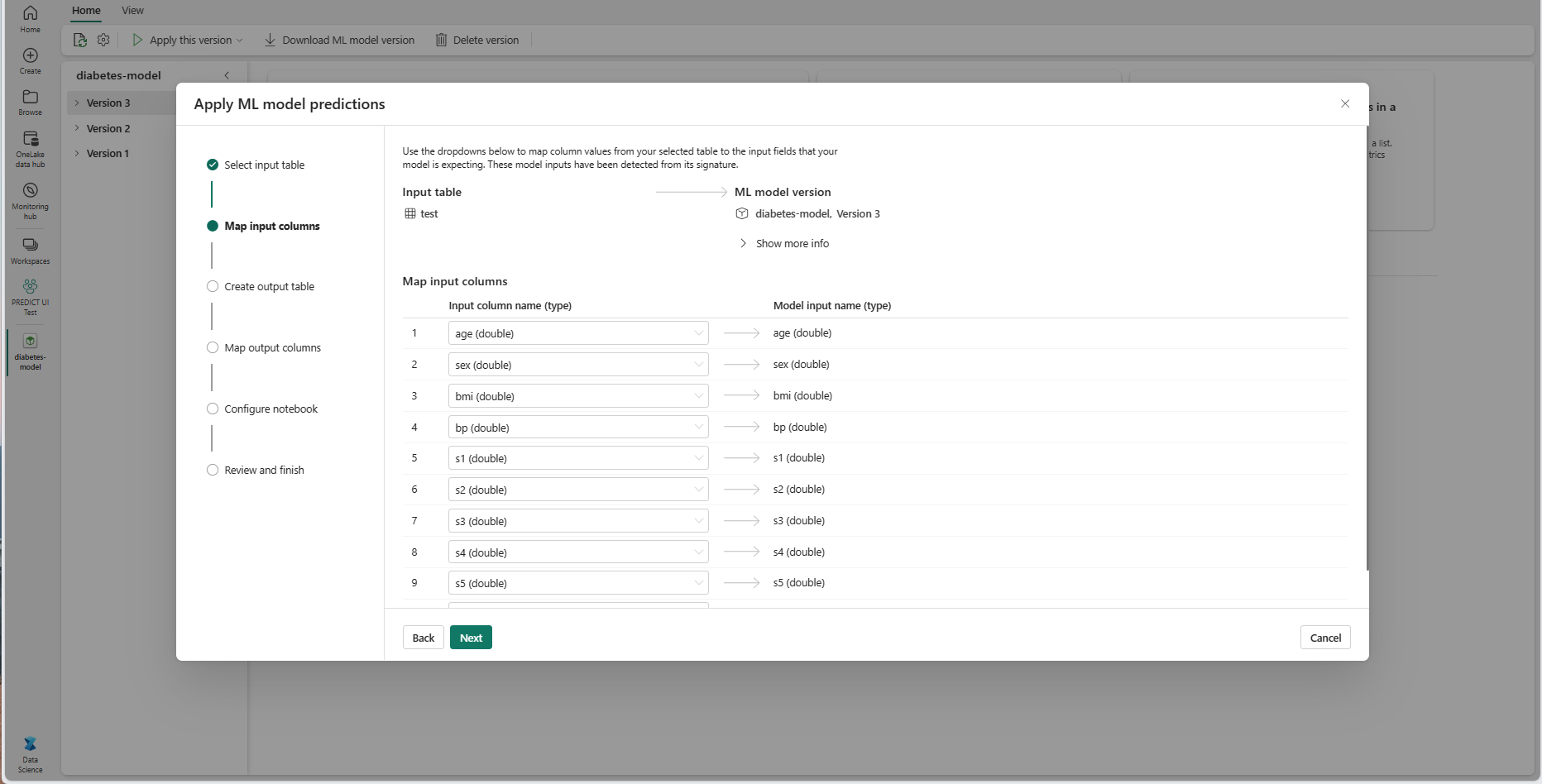
Selecione Avançar para ir para a etapa "Criar tabela de saída".
Forneça um nome para uma nova tabela no lakehouse do espaço de trabalho atual selecionado. Essa tabela de saída armazena os valores de entrada do modelo de ML e acrescenta os valores de previsão a essa tabela. Por padrão, a tabela de saída é criada no mesmo lakehouse que a tabela de entrada. Você pode alterar o lakehouse de destino.
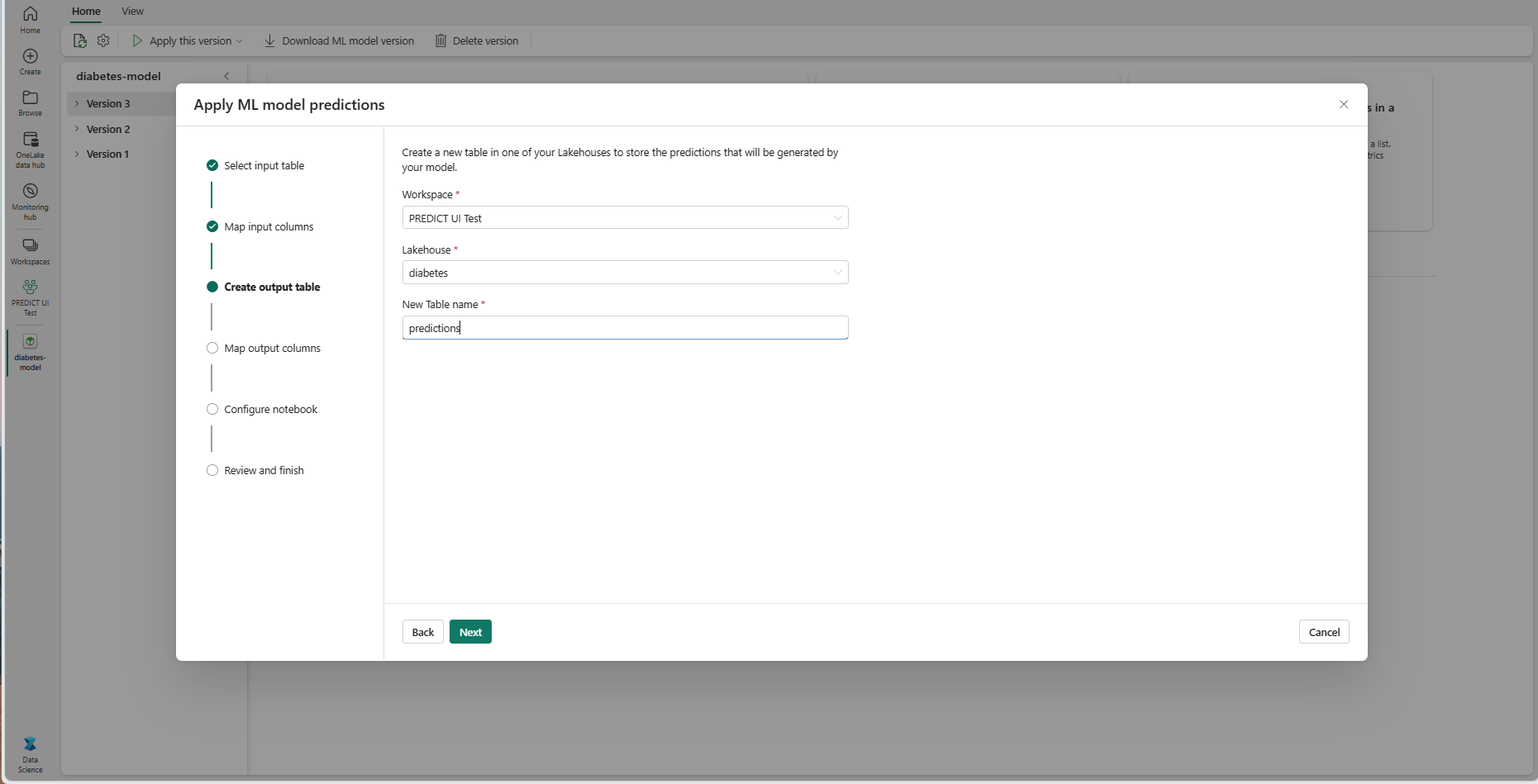
Selecione Avançar para ir para a etapa "Mapear colunas de entrada".
Use os campos de texto fornecidos para nomear as colunas da tabela de saída que armazena as previsões do modelo de ML.

Selecione Avançar para ir para a etapa "Configurar notebook".
Forneça um nome para um novo notebook que executa o código PREDICT gerado. O assistente exibe uma visualização do código gerado nesta etapa. Se você quiser, pode copiar o código para a área de transferência e colá-lo em um notebook existente.
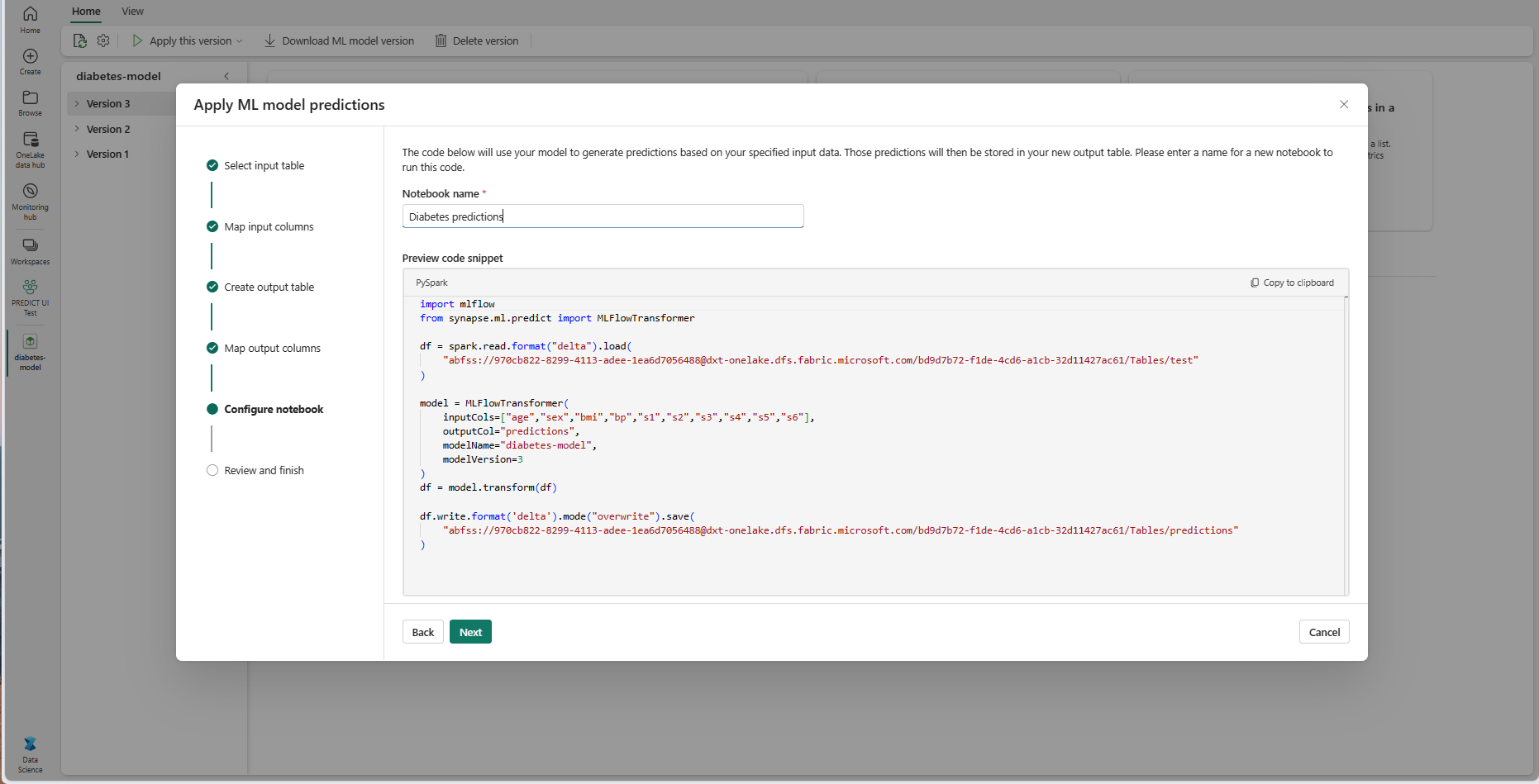
Selecione Avançar para ir para a etapa "Examinar e concluir".
Examine os detalhes na página de resumo e selecione Criar bloco de anotações para adicionar o novo bloco de anotações com seu código gerado ao seu espaço de trabalho. Você é levado diretamente para esse notebook, onde poderá executar o código para gerar e armazenar previsões.








Usar um modelo de código personalizável
Para usar um modelo de código para gerar previsões em lote:
- Vá para a página de item para uma determinada versão do modelo de ML.
- Selecione Copiar código para aplicar no menu suspenso Aplicar esta versão. A seleção copia um modelo de código personalizável.
Você pode colar esse modelo de código em um notebook para gerar previsões em lote com seu modelo de ML. Para executar o modelo de código com êxito, substitua manualmente os seguintes valores:
-
<INPUT_TABLE>: o caminho do arquivo para a tabela que fornece entradas para o modelo de ML. -
<INPUT_COLS>: uma matriz de nomes de coluna da tabela de entrada para alimentar o modelo de ML. -
<OUTPUT_COLS>: um nome para uma nova coluna na tabela de saída que armazena previsões. -
<MODEL_NAME>: o nome do modelo de ML a ser usado para gerar previsões. -
<MODEL_VERSION>: a versão do modelo de ML a ser usada para gerar previsões. -
<OUTPUT_TABLE>: o caminho do arquivo para a tabela que armazena as previsões.

import mlflow
from synapse.ml.predict import MLFlowTransformer
df = spark.read.format("delta").load(
<INPUT_TABLE> # Your input table filepath here
)
model = MLFlowTransformer(
inputCols=<INPUT_COLS>, # Your input columns here
outputCol=<OUTPUT_COLS>, # Your new column name here
modelName=<MODEL_NAME>, # Your ML model name here
modelVersion=<MODEL_VERSION> # Your ML model version here
)
df = model.transform(df)
df.write.format('delta').mode("overwrite").save(
<OUTPUT_TABLE> # Your output table filepath here
)