Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
O agente de dados do Fabric permite que as organizações criem sistemas de conversação usando IA generativa. Ao conectar modelos semânticos do Power BI como fontes de dados, as equipes podem fazer perguntas em linguagem natural e receber respostas precisas e ricas em contexto sem escrever consultas COMPLEXAs DEX ou SQL.
No entanto, a qualidade das respostas de IA depende muito de quão bem você prepara suas fontes de dados. Embora o agente de dados do Fabric dê suporte a vários tipos de fonte de dados, incluindo lakehouses, warehouses, casas de eventos e ontologias, este guia se concentra especificamente em modelos semânticos do Power BI e percorre as práticas recomendadas para configurá-los para maximizar a precisão e a relevância.
Como funciona o agente de dados do Fabric
O agente de dados usa uma arquitetura em camadas em que as perguntas do usuário fluem por meio de um Orchestrator. O Orchestrator determina a fonte de dados apropriada e invoca ferramentas especializadas, incluindo a ferramenta de geração DAX para modelos semânticos do Power BI para gerar, validar e executar consultas.
O fluxo de processamento de consulta
Análise de perguntas: O agente processa perguntas do usuário por meio do Azure OpenAI, garantindo a conformidade com protocolos e permissões de segurança e aderindo aos princípios de IA Responsável da Microsoft.
Seleção da Fonte de Dados: O sistema avalia a questão em relação às fontes disponíveis usando informações de esquema e instruções de IA que você fornece.
Geração de consulta: Para modelos semânticos, a ferramenta de geração DAX gera consultas DAX com base em esquema, metadados (sinônimos, valores mínimos e máximos de colunas numéricas, metadados visuais de relatório e muito mais), contexto configurado nos dados de preparação para IA e no histórico de conversas.
Formatação de resposta: O agente formata resultados em respostas legíveis por humanos com tabelas, resumos ou insights com base nas instruções do agente.

Preparação para IA: tornar o modelo semântico pronto para IA
O recurso Preparação para IA do Power BI fornece três componentes de configuração que afetam diretamente como o agente de dados do Fabric interpreta seu modelo semântico. Você pode acessar esses componentes no Power BI Desktop e no serviço do Power BI. O Power BI Copilot também usa as configurações do Prep para IA, portanto, investir tempo em configurar esses elementos beneficia tanto o Copilot quanto as respostas do agente de dados.
Importante
Ao consultar modelos semânticos, a ferramenta de geração DAX usada pelo agente de dados depende exclusivamente dos metadados do modelo semântico e das configurações do Prep for AI. A ferramenta de geração DAX ignora as instruções que você adicionar no nível do agente de dados para a geração de consulta DAX. A preparação adequada para a configuração de IA é essencial para resultados precisos.
Esquemas de dados de IA
Os esquemas de dados de IA permitem definir um subconjunto focado do modelo para priorização de IA. Embora o agente de dados também tenha sua própria seleção de tabela ao adicionar um modelo semântico como uma fonte de dados, configure seu esquema na Preparação para IA primeiro. A ferramenta de geração DAX usa esse esquema para criar consultas DAX.
Você pode configurar esse esquema no Power BI Desktop ou no serviço do Power BI selecionando dados de preparação para IA na faixa de opções Home. Em seguida, navegue até a guia Simplificar esquema de dados . A partir daí, selecione quais tabelas, colunas e medidas a IA deve usar ao gerar respostas. Para obter instruções detalhadas de instalação, consulte Definir um esquema de dados de IA.

Ao adicionar o modelo semântico ao agente de dados, selecione as mesmas tabelas definidas em Preparação para IA para garantir um comportamento consistente. Primeiro, defina o escopo do agente de dados (os tipos de perguntas que ele deve responder). Em seguida, selecione apenas os objetos relevantes. Essa abordagem reduz a ambiguidade, melhora a precisão e reduz a latência de resposta.
A ferramenta de geração DAX depende dos metadados do modelo para interpretar perguntas. Use nomes claros e amigáveis para tabelas, colunas e medidas que reflitam como os usuários se referem naturalmente aos dados. Por exemplo, use 'Receita Total' em vez de 'TR_AMT' ou 'Região de Vendas' em vez de 'DIM_GEO_01'. Essa orientação é especialmente importante para modelos grandes com campos sobrepostos ou similarmente nomeados, em que nomes ambíguos podem levar à geração de consulta incorreta.
Exemplo: Resolvendo a ambiguidade do campo
| Sem esquema de dados de IA | Com o esquema de dados de IA |
|---|---|
Um usuário pergunta: "What were our sales last quarter?" O modelo semântico contém várias medidas relacionadas a vendas: Receita Total, Vendas Brutas, Vendas Líquidas e Vendas Após Retornos. A IA retorna Vendas Brutas, mas sua equipe normalmente usa Vendas Líquidas para relatórios trimestrais. |
Depois de configurar o esquema de dados de IA para incluir apenas Vendas Líquidas e excluir as outras medidas que não são relevantes, a mesma pergunta agora retorna a métrica esperada. A IA não precisa mais adivinhar qual medida de "vendas" o usuário pretendia. |
Dicas para esquemas de dados de IA
Para obter resultados consistentes e precisos, certifique-se de selecionar as mesmas tabelas no agente de dados do Fabric que também são definidas por meio de Esquemas de Dados de IA na Preparação para IA.
Ao selecionar o esquema, inclua também objetos dependentes. Por exemplo, se uma medida de Receita Total fizer referência a duas outras medidas que dependem de colunas adicionais, inclua todos esses objetos dependentes em seu esquema. Para identificar dependências, use a função get_measure_dependencies da biblioteca Semantic Link Labs.
Se você tiver um modelo semântico grande, renomear todos os objetos manualmente poderá ser entediante. Use o servidor MCP de Modelagem do Power BI para que uma LLM gere nomes amigáveis aos negócios para suas tabelas, colunas e medidas. Examine e valide as alterações antes de salvar para garantir que elas não interrompa nenhuma expressão DAX, relações ou outros objetos dependentes.
Respostas verificadas
As respostas verificadas são respostas visuais aprovadas pelo usuário que são disparadas por perguntas específicas. Eles fornecem respostas consistentes e confiáveis a perguntas comuns ou complexas que, de outra forma, podem ser mal interpretadas. Como você armazena respostas verificadas no nível do modelo semântico (não no nível do relatório), elas funcionam em qualquer agente de dados que use o mesmo modelo. Para obter mais informações, consulte Preparar seus dados para IA – respostas verificadas.
Quando você usa respostas verificadas com o agente de dados, o sistema não retorna o visual do Power BI em si. Em vez disso, ele usa as perguntas do usuário e as propriedades do visual (colunas, medidas, filtros) para influenciar a geração de consulta DAX. Essa abordagem significa que as respostas verificadas melhoram a precisão da resposta orientando a ferramenta de geração DAX para a estrutura de consulta correta. Quando um usuário faz uma pergunta ao agente de dados, o sistema primeiro verifica se há uma correspondência exata ou semanticamente semelhante ao prompt definido na resposta verificada antes de gerar uma nova resposta.

Exemplo: Manipulando a terminologia regional
| Sem resposta verificada | Com resposta verificada |
|---|---|
Um usuário pergunta: "Show me performance by territory" a IA interpreta "território" como categoria de produto porque há uma coluna Territory na tabela Produtos. O usuário realmente quis dizer regiões de vendas. |
Você cria uma resposta verificada usando um visual de vendas regionais com perguntas de gatilho como "What is the sales performance by territory?"" Mostrar-me vendas divididas por território" e "Como as vendas são distribuídas entre regiões?" Agora, quando os usuários perguntam sobre o desempenho do território, eles obtêm respostas precisas consistentemente com base nos objetos usados no visual de vendas regionais. |
Dicas de configuração para respostas verificadas
- Use de cinco a sete perguntas de gatilho por resposta verificada para cobrir variações naturais.
- Incluir tanto formas formais quanto de conversa que os usuários podem tentar.
- Configure até três filtros para fatiamento flexível sem criar várias respostas verificadas.
- Se você renomear tabelas, colunas ou medidas referenciadas em uma resposta verificada, atualize a resposta verificada e salve-a novamente para que as alterações entrem em vigor.
Instruções de IA
As instruções de IA na Preparação para IA fornecem contexto, lógica de negócios e diretrizes diretamente sobre o modelo semântico. Eles ajudam a esclarecer a terminologia, orientar abordagens de análise e fornecem contexto comercial e semântico crítico que a IA não entenderia de outra forma.
Você pode configurar essas instruções no Power BI Desktop ou no serviço do Power BI selecionando os dados de preparação para IA na faixa de opções Home e navegando até a guia Adicionar instruções de IA . Para obter instruções detalhadas de instalação, consulte a documentação de Instruções de IA.

As instruções de IA são diretrizes não estruturadas que o LLM interpreta, mas não há garantia de que ela as siga exatamente. Instruções claras e específicas são mais eficazes do que as complexas ou conflitantes.
Conforme mencionado anteriormente, a ferramenta de geração DAX refere-se apenas às instruções de IA configuradas na Preparação para IA do modelo semântico. As instruções do agente de dados não são passadas para a ferramenta e são ignoradas ao consultar modelos semânticos. Por esse motivo, não adicione instruções específicas do modelo semântico no nível do agente de dados. Em vez disso, mantenha todas as instruções de modelo semântico na Preparação para IA em que a ferramenta de geração DAX possa usá-las. As instruções do agente de dados devem incluir apenas diretrizes que se apliquem a todas as fontes de dados configuradas no agente, como preferências gerais de formatação de resposta, regras de roteamento entre fontes, abreviações comuns, tom e assim por diante. Observe também que, ao contrário de outras fontes de dados, o agente de dados não dá suporte a instruções ou descrições de fonte de dados para modelos semânticos.
Exemplo: Definindo a terminologia de negócios
| Sem instruções de IA | Com instruções de IA |
|---|---|
| Um usuário pergunta: "Quem foram os melhores artistas no mês passado?" A IA não entende o que significa "melhor desempenho" em sua organização e retorna um erro ou pede esclarecimentos. | Você adiciona a instrução: "Um melhor vendedor é um representante de vendas que alcança 110% ou mais de sua cota mensal." Use a tabela Rep_Performance e filtre onde Quota_Attainment >= 1,1" Agora a IA interpreta corretamente a pergunta e retorna os resultados certos. |
Padrões de instrução eficazes
- Definições de período de tempo: "A temporada de pico vai de novembro a janeiro. Fora de temporada é de fevereiro a abril."
- Preferências de métrica: "Quando os usuários perguntarem sobre rentabilidade, use a medida Contribution_Margin, não Gross_Profit."
- Roteamento da Fonte de Dados: "Para perguntas de inventário, priorize a tabela Warehouse_Inventory em vez de Sales_Orders."
- Agrupamentos padrão: "A menos que especificado de outra forma, analise a receita por trimestre fiscal em vez de mês civil."
Além de Prep for AI, a ferramenta de geração de consulta DAX também usa metadados de visuais de relatório, como título do visual, colunas, medidas, filtros e assim por diante para melhorar a precisão da consulta.
Fluxo de trabalho de implementação recomendado
Otimizar o modelo semântico: Comece otimizando seu modelo semântico para desempenho. O baixo desempenho do agente de dados geralmente vem de um modelo semântico mal projetado, medidas DAX ineficientes ou uma combinação dos dois. Quando um usuário faz uma pergunta, o agente de dados gera uma consulta DAX e a executa em seu modelo. Um modelo bem otimizado usa menos recursos e obtém uma execução de consulta mais rápida. Em uma interface de conversa, os usuários esperam respostas rápidas, portanto, o desempenho lento afeta diretamente a experiência e a adoção do usuário.
Além disso, um modelo sobrecarregado com colunas, tabelas e medidas desnecessárias cria mais ruído para a ferramenta de geração DAX examinar, o que pode reduzir a precisão da resposta. Ao otimizar seu modelo antecipadamente, você também evita problemas de desempenho à medida que seus dados aumentam e o modelo se torna mais complexo. Saiba mais no curso Otimizar um modelo para desempenho no Power BI .
Use o Analisador de Práticas Recomendadas e o Analisador de Memória de Modelo Semântico em um notebook do Fabric para identificar problemas como tipos de dados incorretos, colunas desnecessárias, colunas de alta cardinalidade e padrões DAX ineficientes. Adicione descrições a tabelas, colunas e medidas para ajudar o LLM a entender a finalidade de cada objeto incluído no esquema de dados de IA.
Definir a preparação para IA > Esquema de dados de IA: com base no escopo do agente de dados, configure o esquema de dados de IA na Preparação para IA selecionando apenas as tabelas, colunas e medidas relevantes para as perguntas que seu agente deve responder.
Configurar o Prep para IA > Respostas verificadas: identifique suas perguntas mais comuns e configure respostas verificadas no Prep para IA usando visuais apropriados. Use perguntas completas e robustas como gatilhos (não frases parciais) para melhorar a precisão da correspondência.
Adicionar o Modelo Semântico ao agente de dados: Antes de adicionar instruções de IA na Preparação para IA, teste e valide as respostas do agente de dados. Esta etapa ajuda você a entender onde as instruções de IA são necessárias para melhorar a geração de consultas DAX.
Adicionar preparação para IA > Instruções de IA: com base em suas descobertas de validação, defina a terminologia de negócios, as preferências de análise e as prioridades da fonte de dados nas instruções de Preparação para IA (não nas instruções do agente de dados).
Preparar visuais de relatório: Examine os relatórios conectados ao modelo semântico, incluindo visuais e páginas ocultos, para garantir que os visuais tenham títulos descritivos. Visuais bem estruturados ajudam a IA a embasar as respostas usando os metadados visuais, como título visual, tabela, coluna, medidas usadas, filtros aplicados e muito mais.
Verifique e teste o DAX: A precisão da resposta depende da consulta DAX gerada. Ao testar seu agente de dados, examine a consulta DAX em cada resposta para verificar se ela é válida e responde corretamente à pergunta. Se os resultados estiverem incorretos, analise o DAX para identificar quais configurações (modelo semântico, esquema de dados de IA, respostas verificadas ou instruções de IA) precisam de ajuste.
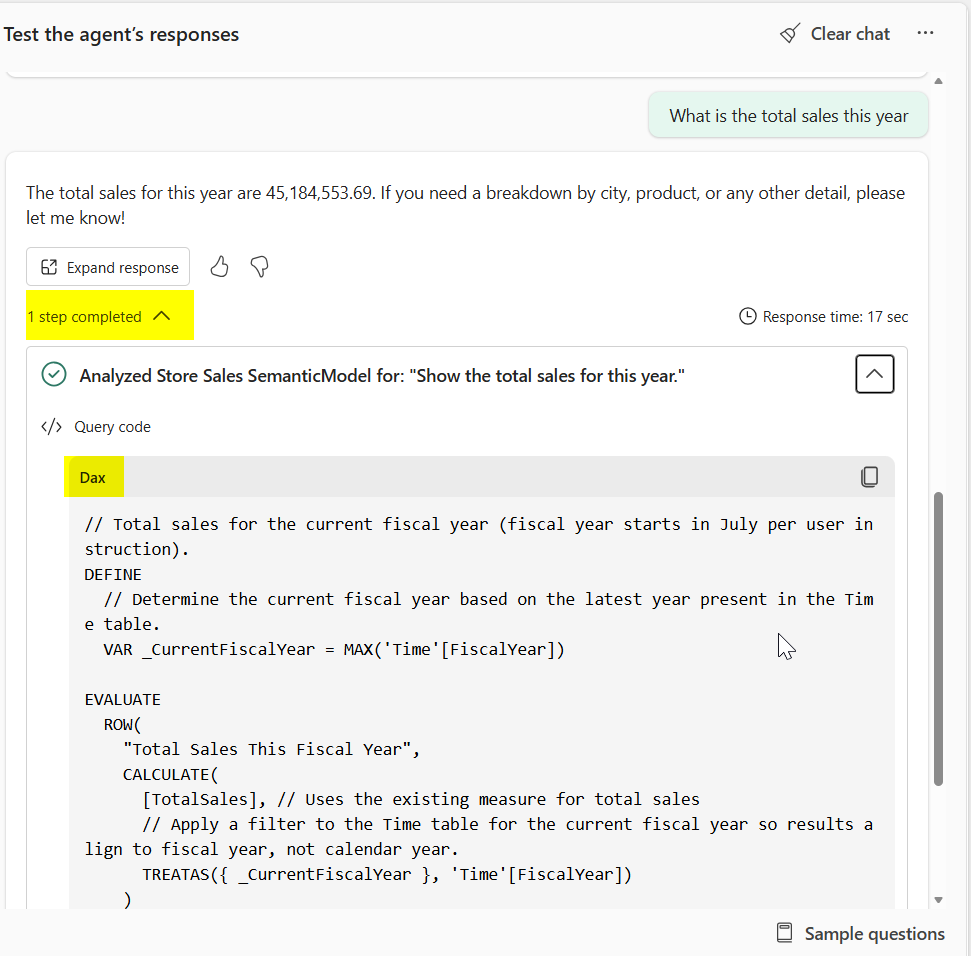
Configurar instruções do agente de dados: Adicione instruções no nível do agente de dados apenas para diretrizes que se apliquem a todas as fontes de dados configuradas no agente. Essa orientação inclui preferências gerais de formatação de resposta, regras de roteamento entre fontes, abreviações comuns e tom. Não adicione instruções específicas do modelo semântico aqui, pois elas não são passadas para a ferramenta de geração DAX. Para obter diretrizes sobre como configurar instruções do agente, consulte as diretrizes de configuração.
Validar &iterar: As LLMs podem produzir resultados incorretos sem o contexto adequado. Iterar continuamente na sua configuração e validar respostas para estabelecer confiança no seu agente de dados. Para avaliar as respostas programaticamente, você pode usar o SDK do Python do agente de dados do Fabric para executar avaliações automatizadas em pares de perguntas e respostas de verdade básica e analisar as métricas de precisão. Observe que o SDK é para avaliação somente nesse caso e não pode modificar a preparação do modelo semântico para configurações de IA. Para obter detalhes, consulte Avaliar seu agente de dados. Além disso, envolva stakeholders e usuários finais no processo de avaliação. Seus comentários garantem que as respostas se alinhem às expectativas e à usabilidade do mundo real, ajudando você a identificar lacunas que as verificações automatizadas podem perder.
Implementar Controle de Versão e Pipelines de Implantação: Use a integração com o Git e pipelines de implantação para gerenciar as configurações do agente de dados em workspaces de desenvolvimento, teste e produção. Essa prática garante que as alterações de configuração sejam testadas e validadas antes de serem promovidas à produção em que os usuários finais as acessam. Para obter detalhes, consulte Controle do Código-Fonte, CI/CD e ALM para agente de dados do Fabric.


Dica
Você pode usar recursos no fabric-toolbox repository como referência para guiar você nesse fluxo de trabalho. Este repositório contém:
- Lista de verificação para preparar e configurar o modelo semântico como fonte de dados
- bloco de anotações utilitários do agente de dados com snippets de código úteis e funções auxiliares
Armadilhas comuns a serem evitadas
Não utilizando o esquema de estrela: Modelos semânticos que usam tabelas planas, desnormalizadas, ou estruturas de dados pivotadas tornam o DAX menos eficiente e mais difícil de escrever corretamente. O DAX é otimizado para o esquema de estrela com tabelas de fatos e dimensões claras. Transforme tabelas amplas em estruturas normalizadas onde cada linha representa uma única observação.
Contando com campos ocultos: As respostas verificadas não funcionarão se fizerem referência a colunas ocultas no modelo.
Incluindo medidas desnecessárias: Os modelos semânticos geralmente contêm medidas auxiliares e objetos intermediários usados para aprimorar a interatividade do relatório. Ao configurar o esquema de dados de IA, inclua apenas as medidas que calculam as métricas de negócios reais. Excluir medidas auxiliares reduz o ruído e ajuda a ferramenta de geração DAX a gerar consultas mais precisas.
Medidas duplicadas ou sobrepostas: Várias medidas que calculam métricas semelhantes (por exemplo, Total de Vendas, Valor de Vendas, Receita) criam ambiguidade. Consolide ou diferencie claramente as medidas e exclua duplicatas do esquema de dados de IA.
Nomenclatura não descritiva: Nomes de objetos como TR_AMT, F_SLS ou DIM_GEO_01 não fornecem contexto para a ferramenta de geração DAX. Use nomes claros e amigáveis para os negócios, como Receita Total, Vendas ou Geografia do Cliente. Se você não puder renomear objetos, verifique se descrições e sinônimos fornecem o contexto necessário para que a IA entenda sua finalidade.
Dependendo de medidas implícitas: Medidas implícitas podem levar a resultados imprevisíveis. Crie medidas DAX explícitas para cálculos que você deseja que os usuários consultem e defina o resumo padrão correto (Soma, Média, Nenhum e assim por diante) em colunas numéricas para evitar agregações não intencionais.
Campos de data ambíguos: Várias colunas de data (Data do Pedido, Data do Envio, Data de Conclusão, Trimestre do Calendário/Trimestre FY e assim por diante) sem diretrizes claras confundem a IA. Use as instruções de IA e Respostas Verificadas na Preparação para IA para especificar qual campo de data usar por padrão ou para tipos de pergunta específicos.
Instruções conflitantes: As instruções de IA que contradizem as configurações de Resposta Verificada criam um comportamento imprevisível.
Ignorando o refinamento de esquema: Modelos grandes com muitos campos nomeados da mesma forma precisam de esquemas de dados de IA focados.
Instruções excessivamente complexas: Mantenha as instruções focadas e específicas. A IA interpreta as diretrizes complexas e conflitantes, mas não garante segui-las. Instruções complexas também podem adicionar à latência.
Tools
Para seguir estas diretrizes, você pode usar as ferramentas abaixo do repositório GitHub fabric-toolbox:
- Lista de verificação com recomendações. Essas são diretrizes e nem todos os itens na lista de verificação podem ser aplicáveis ao seu cenário.
- Notebook com coleção de utilidades em um só lugar.
- Servidor MCP do Power BI para acelerar o desenvolvimento e testes no VS Code
- Biblioteca de Semantic link labs para atualizar programaticamente o modelo semântico no Fabric notebook.
Recursos adicionais
- Documentação de conceitos do agente de dados do Fabric
- Caixa de ferramentas de malha com lista de verificação e blocos de anotações
- Adicionando o modelo semântico como uma fonte de dados ao agente de dados
- Preparar seus dados para IA no Power BI
- Otimizar seu modelo semântico para Copilot
- Otimizar um modelo para desempenho no Power BI – treinamento
- Perguntas frequentes sobre a preparação para IA