Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Aplica-se a:✅ ponto de extremidade de análise SQL e Warehouse no Microsoft Fabric
A recuperação de dados do data lake é uma operação crucial de E/S (entrada/saída) com implicações substanciais para o desempenho da consulta. O Data Warehouse do Fabric emprega padrões de acesso refinados para aprimorar as leituras de dados do armazenamento e elevar a velocidade de execução da consulta. Além disso, ele minimiza de forma inteligente a necessidade de leituras de armazenamento remoto aproveitando os caches locais.
O cache é uma técnica que melhora o desempenho de aplicativos de processamento de dados reduzindo as operações de E/S. O cache armazena dados e metadados acessados com frequência em uma camada de armazenamento mais rápida, como a memória ou o disco SSD local, para que as solicitações seguintes possam ser atendidas com mais rapidez, diretamente do cache. Se um determinado conjunto de dados tiver sido acessado anteriormente por uma consulta, todas as consultas subsequentes recuperarão esses dados diretamente do cache na memória. Essa abordagem diminui significativamente a latência de E/S, pois as operações de memória local são notavelmente mais rápidas em comparação com a busca de dados do armazenamento remoto.
O cache em memória e disco no Fabric Data Warehouse é totalmente transparente para o usuário. Independentemente da origem, seja uma tabela de warehouse, um atalho do OneLake ou até um atalho do OneLake que referencie serviços que não são do Azure, a consulta armazena em cache todos os dados acessados.
Há dois tipos de caches descritos posteriormente neste artigo, cache na memória e cache de disco. O cache do conjunto de resultados é abordado em outro artigo.
Cache na memória
À medida que a consulta acessa e recupera dados do armazenamento, ela executa um processo de transformação que transcodifica os dados de seu formato original baseado em arquivo em estruturas altamente otimizadas no cache na memória.

Os dados no cache são organizados em um formato colunar compactado e otimizado para consultas analíticas. Cada coluna de dados é armazenada em conjunto, separada das outras, permitindo uma melhor compactação, uma vez que valores de dados semelhantes são armazenados juntos, levando à redução do volume de memória. Quando as consultas precisam executar operações em uma coluna específica, como agregações ou filtragem, o mecanismo pode funcionar com mais eficiência, pois não precisa processar dados desnecessários de outras colunas.
Além disso, esse armazenamento colunar também é propício para o processamento paralelo, o que pode acelerar significativamente a execução da consulta para grandes conjuntos de dados. O mecanismo pode executar operações em várias colunas simultaneamente, aproveitando os processadores multi-núcleo modernos.
Essa abordagem é especialmente benéfica para cargas de trabalho analíticas em que as consultas envolvem a verificação de grandes quantidades de dados para executar agregações, filtragem e outras manipulações de dados.
Cache de disco
Determinados conjuntos de dados são muito grandes para serem acomodados em um cache na memória. Para sustentar o desempenho rápido de consulta para esses conjuntos de dados, o Warehouse utiliza o espaço em disco como uma extensão complementar do cache na memória. Todas as informações carregadas no cache na memória também são serializadas para o cache SSD.
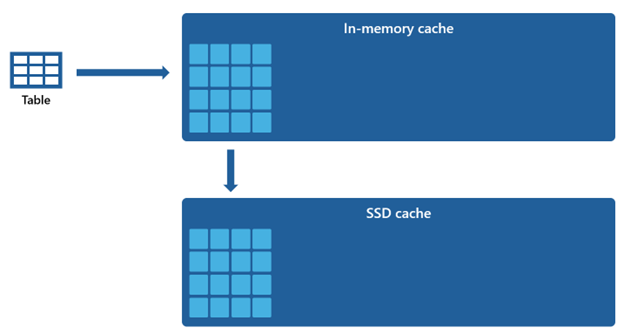
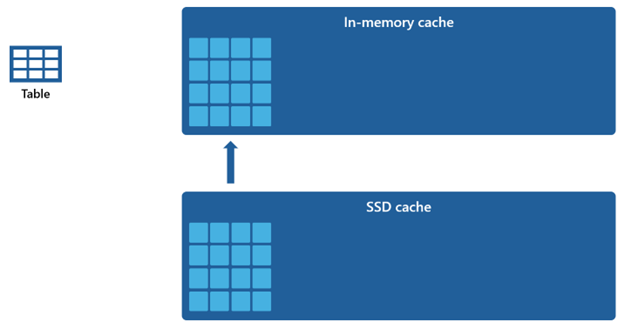
Dado que o cache na memória tem uma capacidade menor em comparação com o cache SSD, os dados removidos do cache na memória permanecem dentro do cache SSD por um período estendido. Quando a consulta subsequente solicita esses dados, eles são recuperados do cache SSD para o cache na memória significativamente mais rápido do que se buscados do armazenamento remoto, fornecendo a você um desempenho de consulta mais consistente.
Gerenciamento de cache
O cache permanece consistentemente ativo e opera perfeitamente em segundo plano, não exigindo nenhuma intervenção de sua parte. Não é necessário desabilitar o cache, pois isso inevitavelmente levaria a uma deterioração perceptível no desempenho da consulta.
O mecanismo de cache é orquestrado e confirmado pelo próprio Microsoft Fabric e não oferece aos usuários a capacidade de limpar manualmente o cache.
A consistência transacional de cache total garante que quaisquer modificações nos dados no armazenamento, como por meio de operações de DML (Linguagem de Manipulação de Dados), depois de serem inicialmente carregadas no cache na memória, resultarão em dados consistentes.
Quando o cache atingir seu limite de capacidade e novos dados estiverem sendo lidos pela primeira vez, os objetos que permaneceram não utilizados por mais tempo serão removidos do cache. Esse processo é decretado para criar espaço para o fluxo de novos dados e manter uma estratégia de utilização de cache ideal.