Estender o Smart Store Analytics
Os usuários avançados do Smart Store Analytics podem acessar dados e análises relevantes de dentro de seu próprio armazenamento de data lake. O acesso pode ocorrer por meio de quaisquer outros serviços ou aplicativos que sejam compatíveis com o Microsoft Azure Data Lake Storage e a definição do Common Data Model; por exemplo, Microsoft Azure Synapse Analytics, Microsoft Azure Data Factory ou Microsoft Power BI.
Importante
Você deve usar o Microsoft Azure Data Lake Storage Gen2, já que o Microsoft Azure Data Lake Storage Gen1 será incompatível.
O modelo de dados do Smart Store Analytics está em conformidade com os modelos de banco de dados do Azure Synapse para varejo, é aprimorado com especificações do Smart Store Analytics e simplifica a conexão de outros aplicativos para o data lake.
Estrutura do data lake do Smart Store Analytics
O data lake do Smart Store Analytics segue a definição do Common Data Model (metadados do Common Data Model).
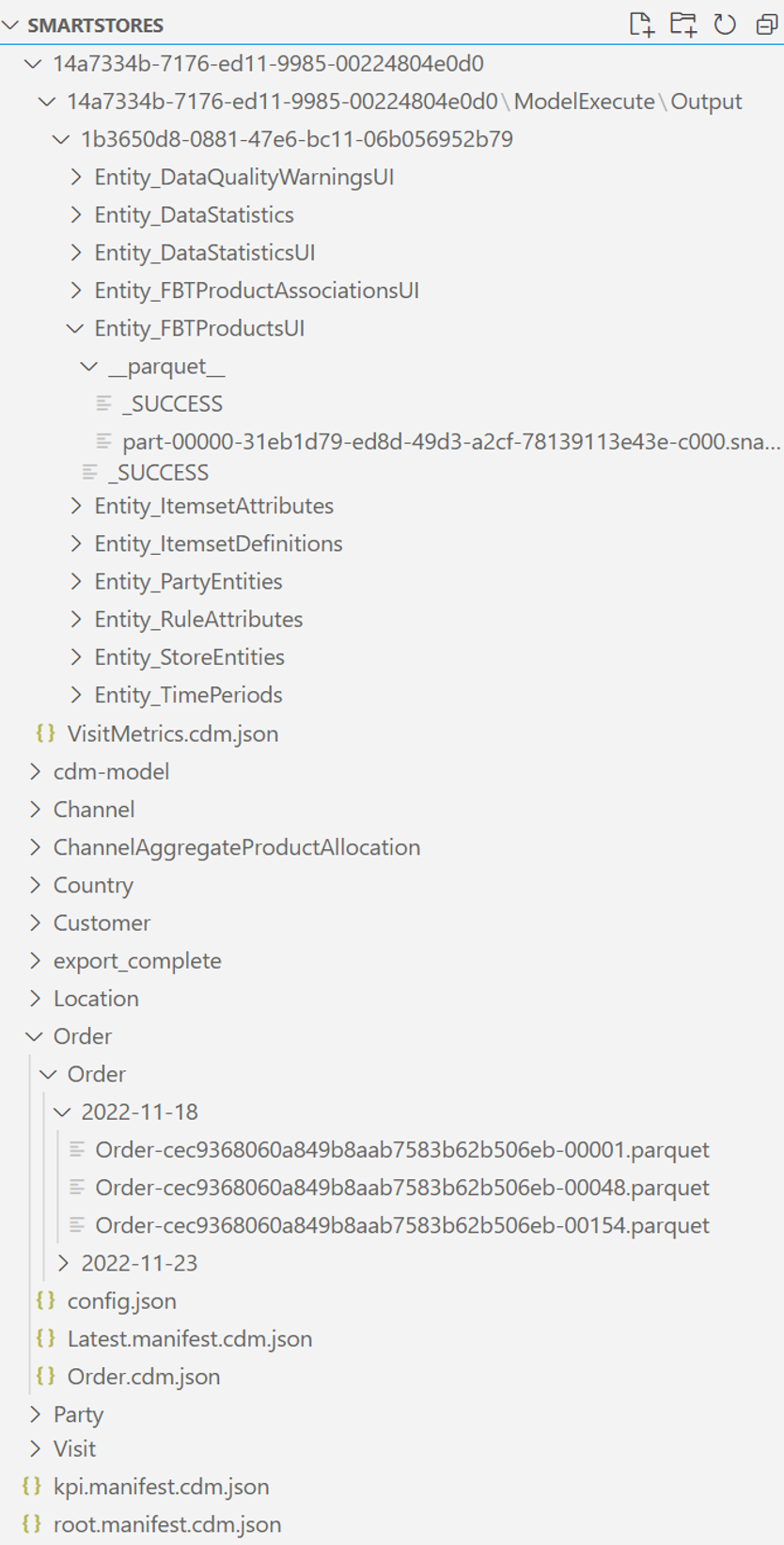
A pasta raiz é denominada smartstores/. Na pasta raiz, há dois instantâneos de dados:
Dados transformados do provedor da loja inteligente (dados brutos da loja inteligente)
O manifesto do Common Data Model raiz para os dados brutos é root.manifest.cdm.json. O arquivo de manifesto refere-se aos arquivos de esquema e arquivos de dados reais localizados nas subpastas (nomeados após as tabelas); por exemplo, smartstores/Order/.
A subpasta de cada tabela contém:
arquivo de esquema, que define os metadados, colunas e tipos da tabela, no formato table-name.cdm.json; por exemplo, Order.cdm.json
arquivos de dados, também conhecidos como partições de dados ou registros de tabela, no formato parquet; por exemplo, Order-cec9368060a849b8aab7583b62b506eb-00001.parquet
Dados gerados pelos módulos Retail Analytical e AI a partir dos dados brutos da loja inteligente
Todos os dados gerados estão em uma pasta com nome GUID; por exemplo, smartstores/14a7334b-7176-ed11-9985-00224804e0d0/. O manifesto do Common Data Model raiz para esses dados é kpi.manifest.cdm.json. O arquivo de manifesto refere-se aos arquivos de esquema e aos arquivos de dados reais localizados na pasta com nome GUID.
A pasta com nome GUID contém:
Arquivo de esquema para cada tabela, que define metadados, colunas e tipos de tabela, no formato table-name.cdm.json; por exemplo, OrderMetrics.cdm.json
Arquivos de dados, também conhecidos como partições de dados ou registros de tabela, em formato parquet; por exemplo, part-00000-1e110bf0-6474-400b-b40a-086fce9f8e2a-c000.snappy.parquet
Importante
De acordo com o contrato de metadados do Common Data Model, os usuários precisam de dados apenas dos arquivos manifest.cdm.json. Eles não precisam interpretar a estrutura de pastas ou outros arquivos internos presentes no data lake.
Uso do data lake do Smart Store Analytics
Veja alguns exemplos de dados sincronizados em insights analíticos/de IA gerados pelo Microsoft Cloud for Retail.
Pipeline de dados com o Microsoft Azure Data Factory
Para criar um pipeline de dados:
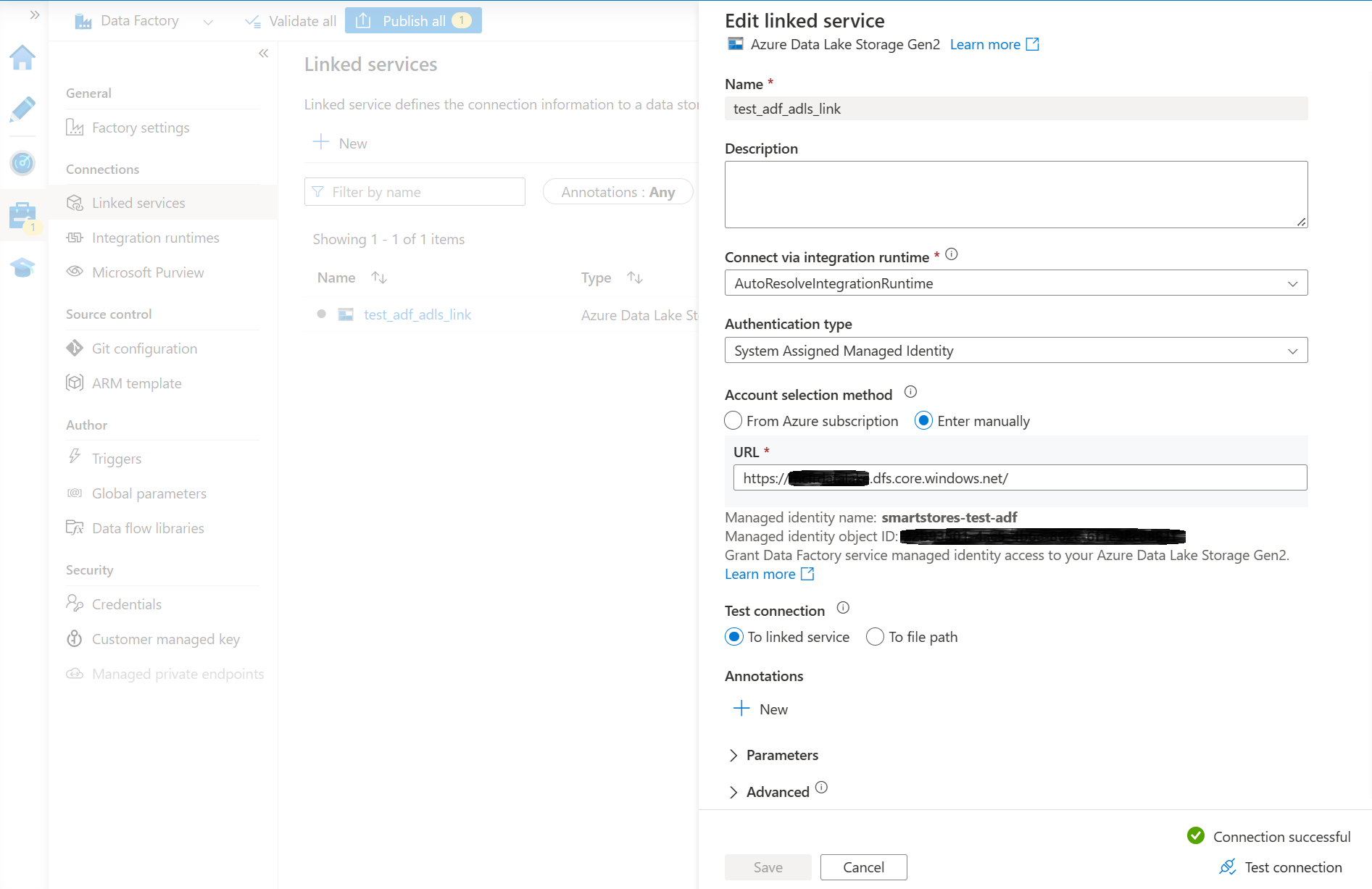
- Crie uma instância do Azure Data Factory e vincule-a ao armazenamento do data lake do Smart Store Analytics. Você deve ter um serviço vinculado com um teste de conexão bem-sucedido.
Observação
A maneira mais fácil de conectar uma instância do Azure Data Factory ao Azure Data Lake Storage é atribuir uma função de colaborador a uma identidade gerenciada do Azure Data Factory na conta do Azure Data Lake Storage. Consulte a documentação do Azure Data Factory para saber mais.
- Selecione Publicar tudo para publicar o novo link.
Criar um pipeline de dados com o Microsoft Azure Data Factory
Para criar um pipeline de cópia para a pasta smartstores/ como origem, execute as seguintes etapas:
- Na seção Autor, selecione Novo fluxo de dados para criar um fluxo de dados.
- Inicie a depuração para uma verificação mais rápida da configuração do pipeline.
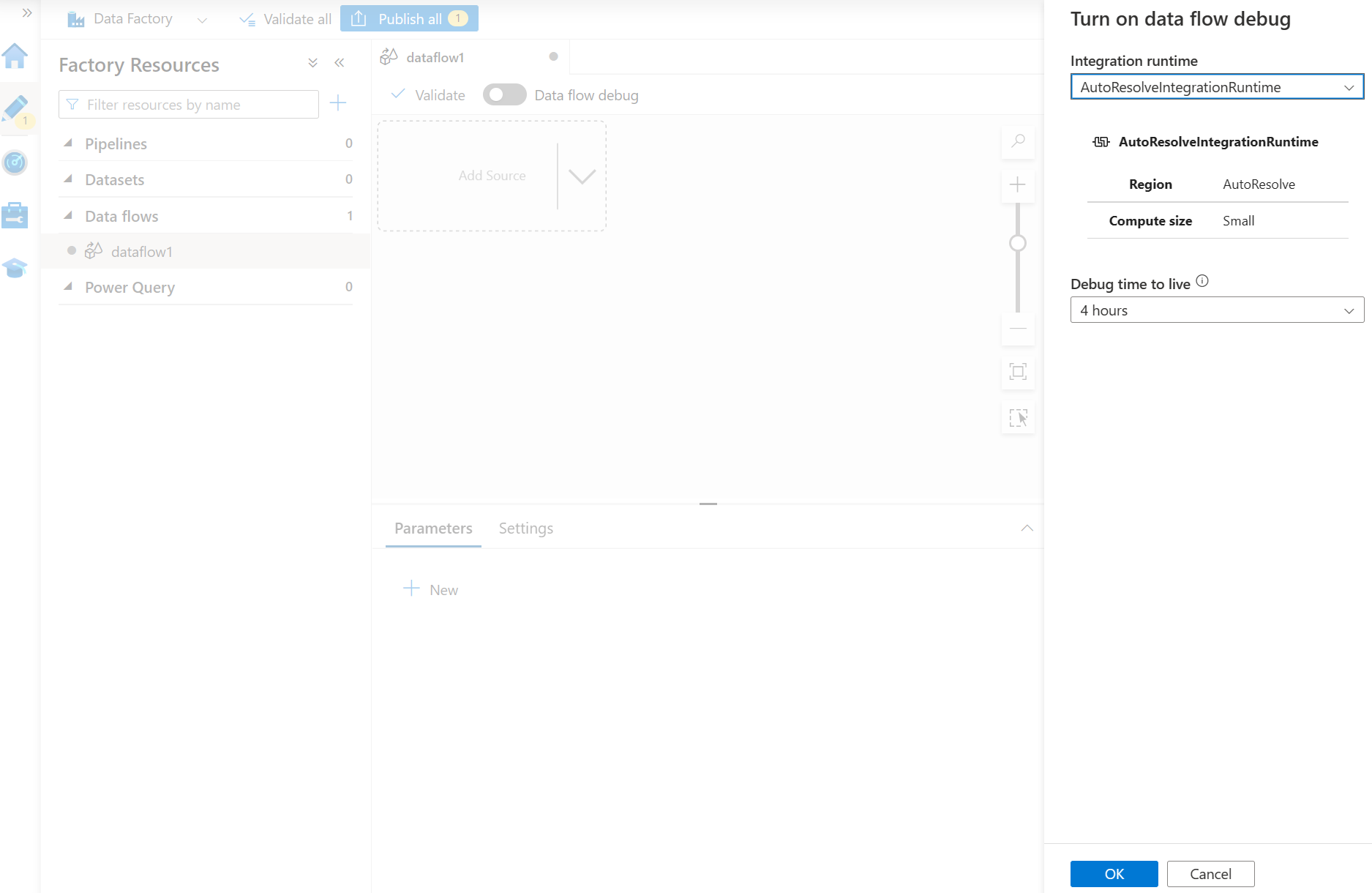
- Defina as configurações de origem da seguinte forma:
- Para o tipo de fonte, selecione Em linha
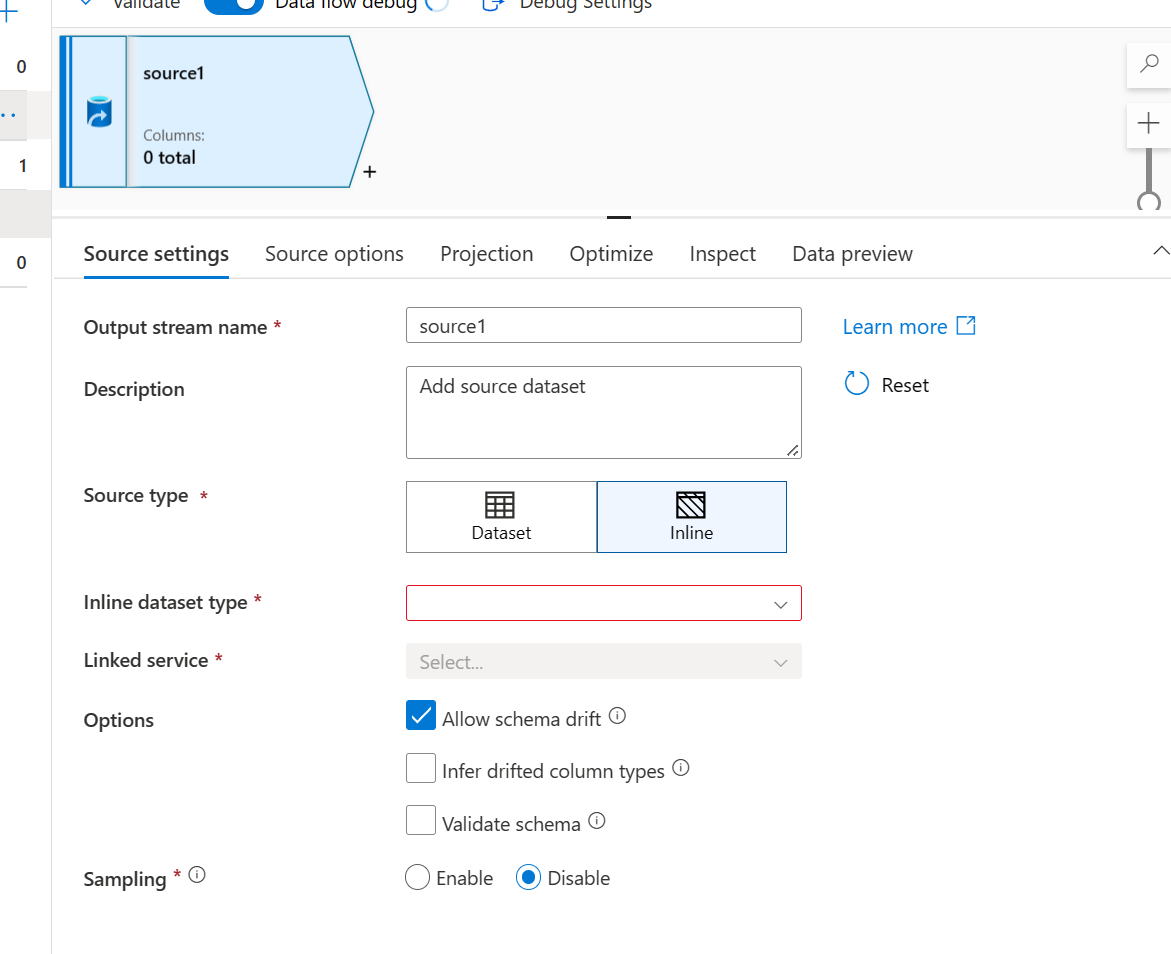
- Para o tipo de conjunto de dados em linha, selecione Common Data Model
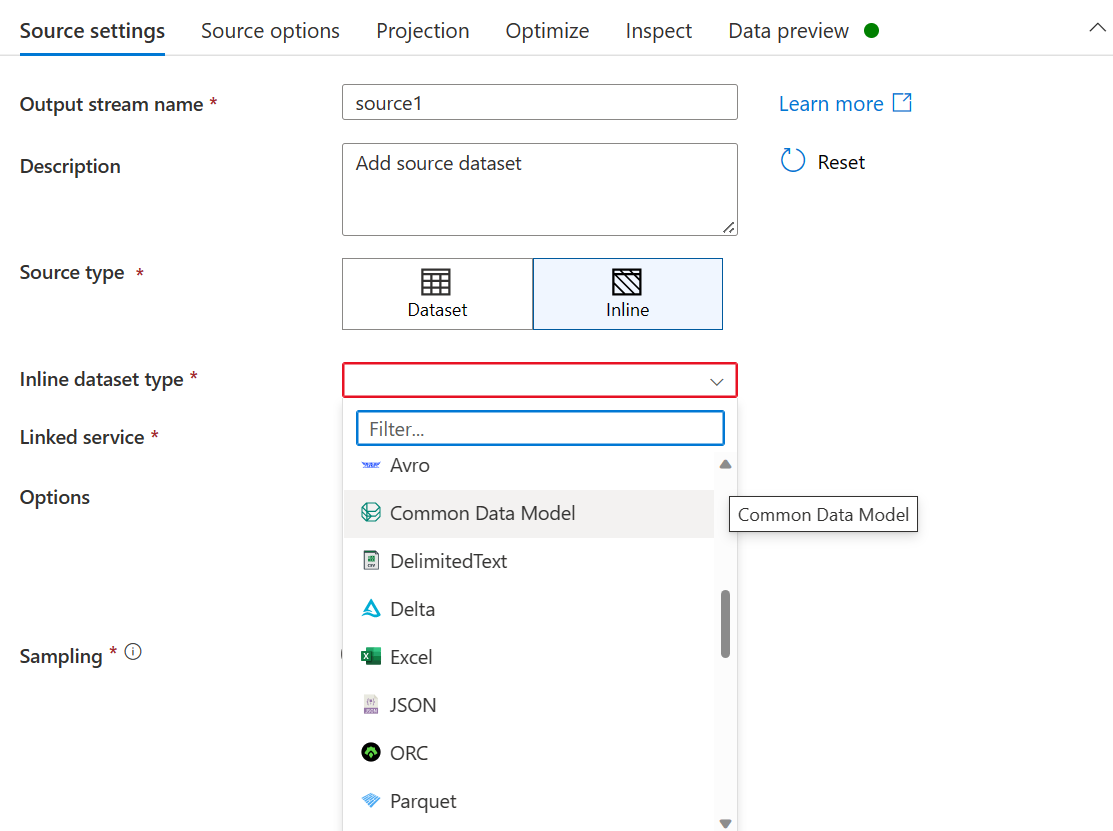
- Use o link do Azure Data Lake Storage criado para o data lake para o Smart Store Analytics.
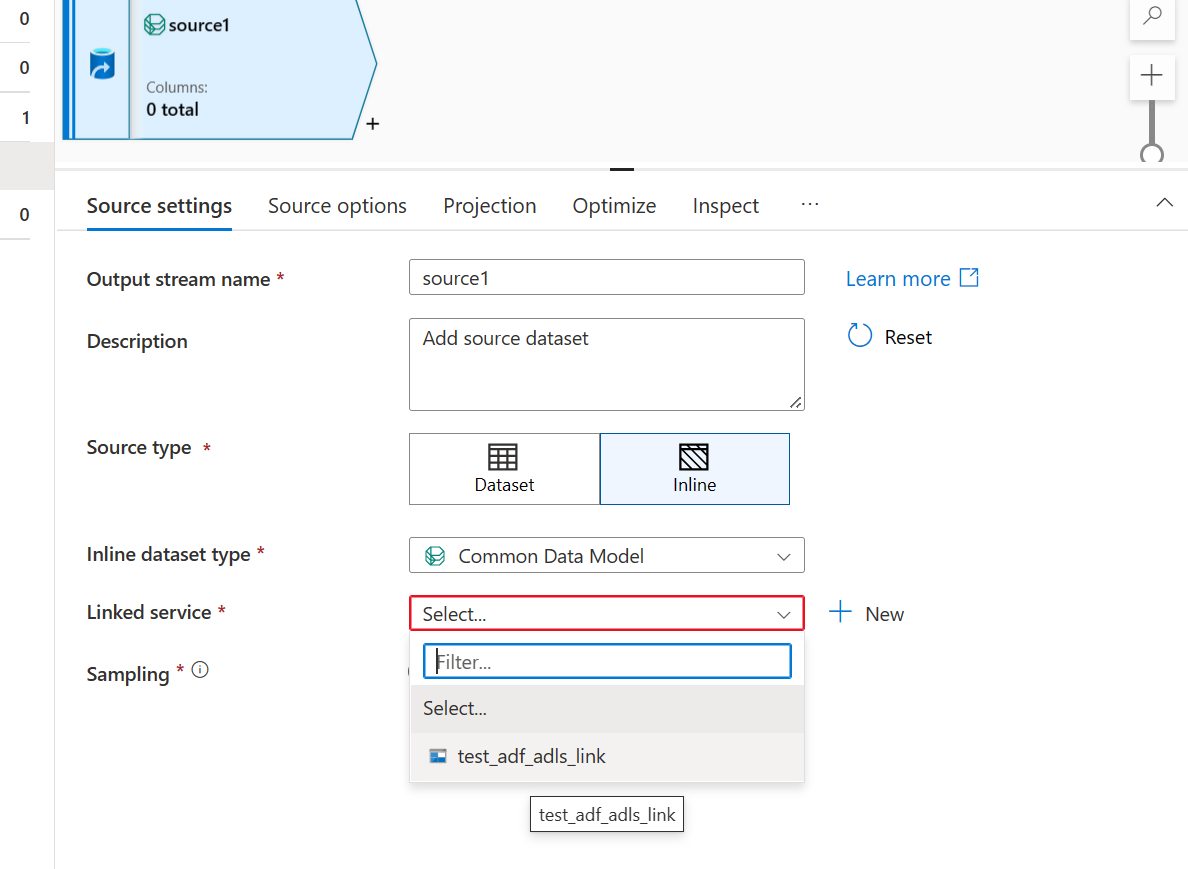
- Na seção Opções de origem, configure a origem do esquema do Common Data Model da seguinte maneira:
- Selecione Manifesto como formato de metadados.
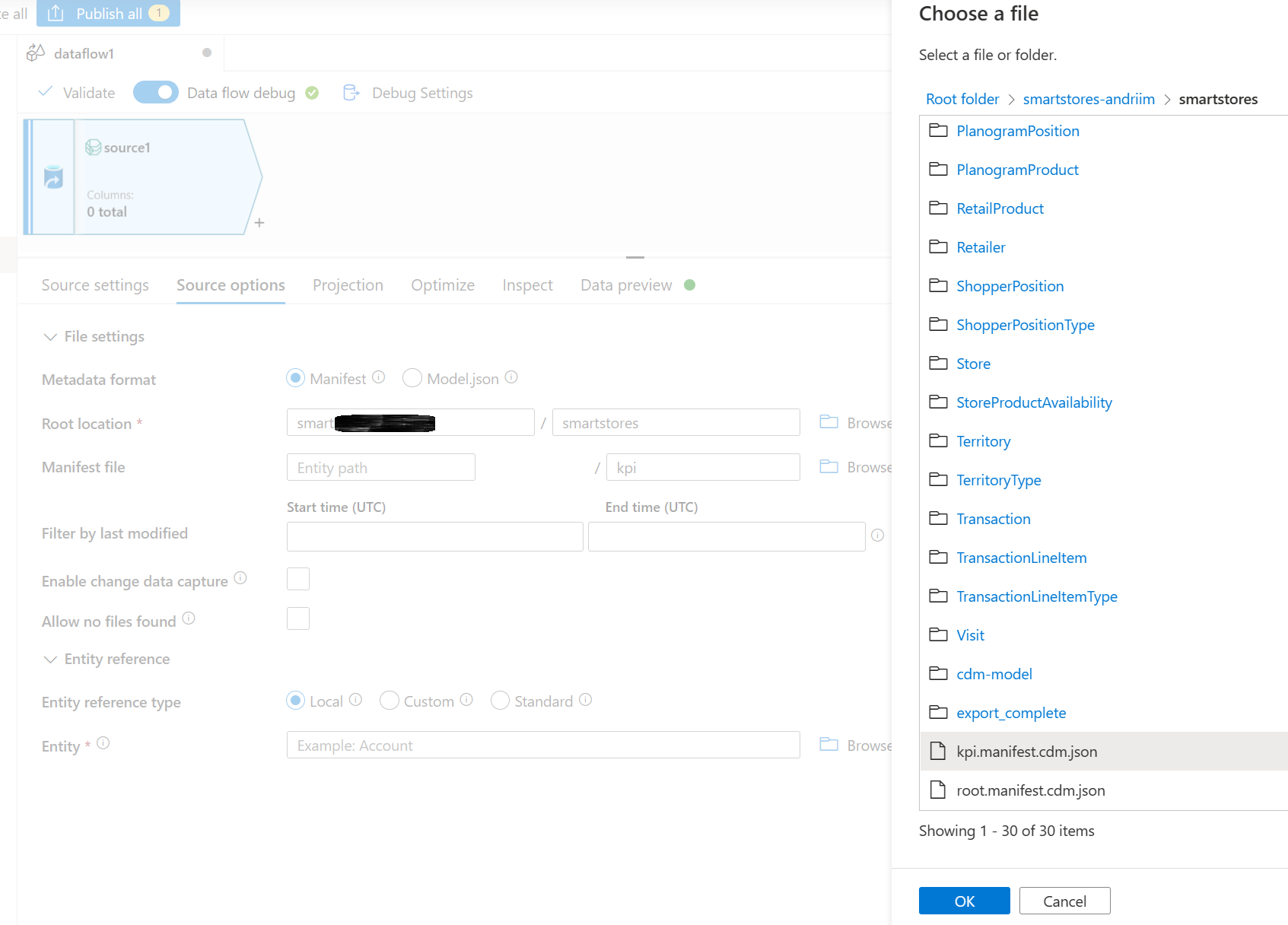
No local raiz, procure e selecione a pasta smartstores.
Na seção Arquivo de manifesto, navegue para selecionar o manifesto raiz necessário. Selecione o arquivo raiz para os dados analíticos e de insights de IA, kpi.manifest.cdm.json.
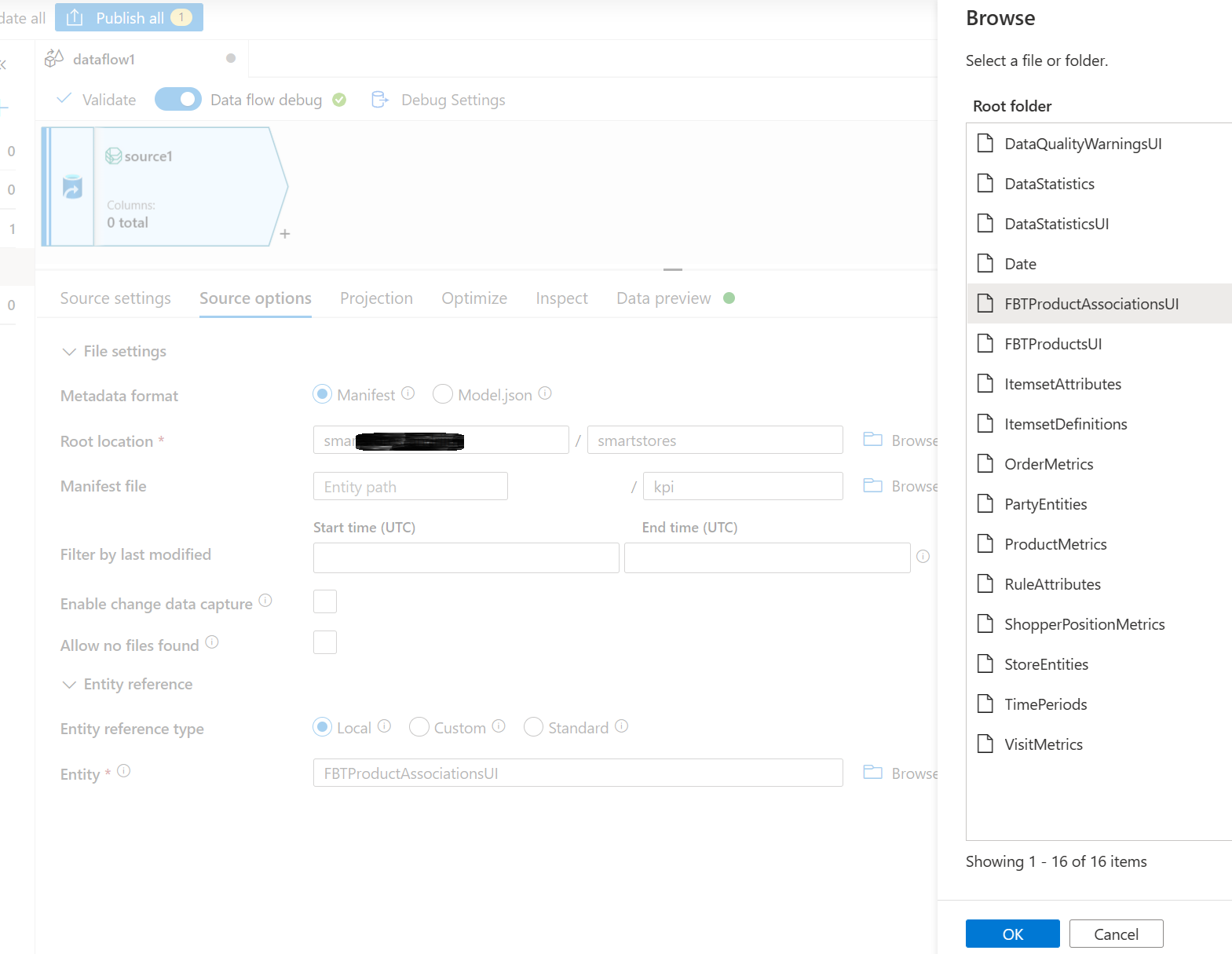
Na seção Entidade, selecione a entidade (tabela) que deseja copiar/transformar; por exemplo, FBTProductAssociationsUI do pacote Frequentemente comprados juntos.
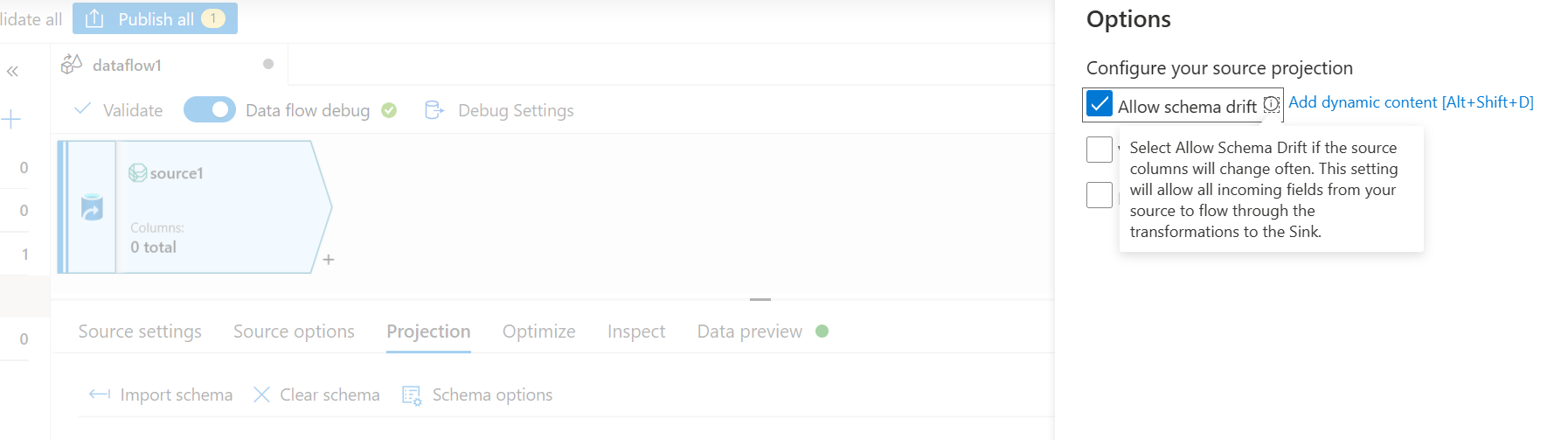
- Na guia Projeção, selecione Permitir descompasso de esquema. Essa seleção garantirá que o esquema não seja validado na origem, mas se desvie para outras etapas de transformação/coletor.
- Na guia Versão preliminar dos dados, selecione Recarregar para validar a configuração da fonte de dados.
Adicionar uma etapa de coletor: defina os parâmetros e o mapeamento de dados conforme necessário para seu cenário.
Selecione Publicar para publicar as alterações.