Saiba mais sobre classificadores treináveis
Categorizar e rotular conteúdo para que ele possa ser protegido e manipulado corretamente é o local de partida para a disciplina de proteção de informações. O Microsoft Purview tem três maneiras de classificar o conteúdo.
Dica
Se você não for um cliente E5, use a avaliação de soluções do Microsoft Purview de 90 dias para explorar como recursos adicionais do Purview podem ajudar sua organização a gerenciar as necessidades de segurança e conformidade de dados. Comece agora no hub de avaliações portal de conformidade do Microsoft Purview. Saiba mais sobre os termos de inscrição e avaliação.
Manualmente
A categorização manual requer julgamento e ação humanas. Usuários e administradores categorizam o conteúdo à medida que o encontram. Você pode usar os rótulos pré-existentes e tipos de informações confidenciais ou usar os criados personalizados. Em seguida, você pode proteger o conteúdo e gerenciar sua disposição.
Correspondência automatizada de padrões
Esses mecanismos de categorização incluem a localização de conteúdo por:
- Palavras-chave ou valores de metadados (palavra-chave linguagem de consulta).
- Usando padrões identificados anteriormente de informações confidenciais como segurança social, cartão de crédito ou números de conta bancária (definições de entidade de tipo de informação confidencial).
- Reconhecer um item porque é uma variação em um modelo (impressão de dedo do documento).
- Usando a presença de cadeias de caracteres exatas, os dados exatos correspondem.
Os rótulos de confidencialidade e retenção podem ser aplicados automaticamente para disponibilizar o conteúdo para uso no Learn about Prevenção Contra Perda de Dados do Microsoft Purview e aplicar automaticamente as polícias para rótulos de retenção.
Classificadores
Esse método de categorização é adequado para conteúdo que não é facilmente identificado pelos métodos manuais ou automatizados de correspondência de padrões. Esse método de categorização é mais sobre como usar um classificador para identificar um item com base no que é o item, não por elementos que estão no item (correspondência de padrões). Um classificador aprende a identificar um tipo de conteúdo examinando centenas de exemplos do conteúdo que você está interessado em identificar.
Observação
Em Visualização – você pode exibir os classificadores treináveis no gerenciador de conteúdo expandindo Classificadores Treináveis no painel de filtros. Os classificadores treináveis exibirão automaticamente o número de incidentes encontrados no SharePoint, Teams e OneDrive, sem exigir nenhuma rotulagem. Se você não quiser usar esse recurso, deverá registrar uma solicitação com Suporte da Microsoft. Isso desabilitará a exibição de seus dados confidenciais que não são usados em políticas de rotulagem no Content Explorer. Você também pode desabilitar a verificação de seus dados. Se a verificação for desativada, a rotulagem de confidencialidade e as políticas DLP com esses classificadores não funcionarão
Onde você pode usar classificadores
Os classificadores estão disponíveis para uso como condição para:
- Rotulagem automática do Office com rótulos de confidencialidade
- Aplicar automaticamente a política de rótulo de retenção com base em uma condição
- Conformidade em comunicações
- Os rótulos de confidencialidade podem usar classificadores como condições, consulte Aplicar um rótulo de confidencialidade ao conteúdo automaticamente.
- Prevenção contra perda de dados
Importante
Os classificadores funcionam apenas com itens que não são criptografados.
Tipos de classificadores
- Classificadores pré-treinados – a Microsoft criou e pré-treinou vários classificadores que você pode começar a usar sem treiná-los. Esses classificadores serão exibidos com o status de
Ready to use. - Classificadores treináveis personalizados – se você tiver necessidades de identificação e categorização de conteúdo que vão além do que os classificadores pré-treinados cobrem, você pode criar e treinar seus próprios classificadores.
Consulte Definições de classificadores treináveis para uma lista completa de todos os classificadores pré-treinados.
Classificadores personalizados
Quando os classificadores pré-treinados não atendem às suas necessidades, você pode criar e treinar seus próprios classificadores. Há mais trabalho envolvido na criação de seus próprios, mas eles serão muito melhor adaptados às suas necessidades de organizações.
Você começa a criar um classificador treinável personalizado alimentando-o com exemplos que estão definitivamente na categoria. Depois que ele processa esses exemplos, você o testa dando uma combinação de exemplos correspondentes e não correspondentes. Em seguida, o classificador faz previsões sobre se um determinado item se enquadra na categoria que você está criando. Em seguida, você confirma seus resultados, classificando os verdadeiros positivos, verdadeiros negativos, falsos positivos e falsos negativos para ajudar a aumentar a precisão de suas previsões.
Quando você publica o classificador, ele classifica por meio de itens em locais como SharePoint Online, Exchange e OneDrive e classifica o conteúdo. Depois de publicar o classificador, você pode continuar a treiná-lo usando um processo de comentários semelhante ao processo de treinamento inicial.
Por exemplo, você pode criar classificadores treináveis para:
- Documentos legais - como privilégio do cliente advogado, conjuntos de fechamento, instrução de trabalho
- Documentos estratégicos de negócios - como comunicados de imprensa, fusão e aquisição, negócios, planos de negócios ou marketing, propriedade intelectual, patentes, documentos de design
- Informações sobre preços - como faturas, cotações de preço, ordens de trabalho, documentos de licitação
- Informações financeiras - como investimentos organizacionais, resultados trimestrais ou anuais
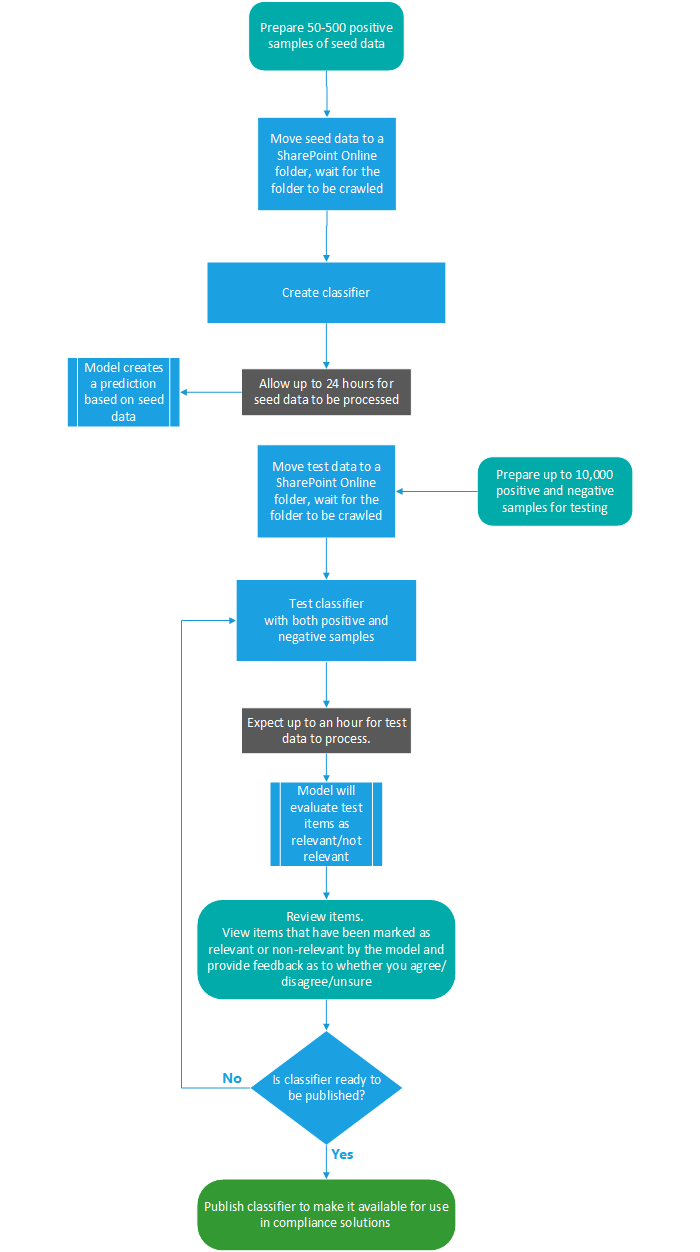
Fluxo de processo para criar classificadores personalizados
Criar e publicar um classificador para uso em soluções de conformidade, como políticas de retenção e supervisão de comunicação, segue esse fluxo. Para obter mais detalhes sobre como criar um classificador treinável personalizado, consulte Criando um classificador personalizado.
Classificadores de retreinamento
Você pode ajudar a melhorar a precisão de todos os classificadores treináveis personalizados e fornecendo comentários sobre a precisão da classificação que eles executam. Isso é chamado de retreinamento e segue esse fluxo de trabalho.
Observação
Classificadores pré-treinados não podem ser treinados novamente.

Fornecer comentários de correspondência/não de precisão de correspondência em classificadores treináveis
Você pode exibir o número de correspondências que um classificador treinável tem no Gerenciador de Conteúdo e classificadores treináveis. Você também pode fornecer comentários sobre se um item é realmente uma correspondência ou não usando o mecanismo de comentários Match, Not a Match e usar esse comentário para ajustar seus classificadores. Consulte Aumentar a precisão do classificador para obter mais informações.
Confira também
Comentários
Em breve: Ao longo de 2024, eliminaremos os problemas do GitHub como o mecanismo de comentários para conteúdo e o substituiremos por um novo sistema de comentários. Para obter mais informações, consulte https://aka.ms/ContentUserFeedback.
Enviar e exibir comentários de