Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Introdução
Os parceiros da Microsoft, incluindo ISVs (fornecedores independentes de software) como você, podem criar soluções de IA generativa por meio de muitas abordagens diferentes de código profissional e de baixo código. Para dar suporte a você nesse processo, a Microsoft está criando diretrizes para ISVs para permitir que você crie melhor essas soluções.
Como os ISVs visam gerenciar consultas e tarefas especializadas, a complexidade de suas soluções de IA generativa aumenta. Essas soluções complexas de IA generativa exigem precauções exclusivas durante o desenvolvimento e monitoramento e observação consistentes durante toda a produção. Ao observar o comportamento e os resultados do seu produto, você pode identificar rapidamente áreas de crescimento, abordar prontamente os riscos e problemas e aumentar ainda mais o desempenho da sua aplicação.
Construindo e operacionalizando aplicativos de copiloto
Para entender como a observabilidade afeta seu aplicativo desde o início do ciclo de vida da solução, é fundamental pensar no ciclo de vida em três estágios principais: idealizar seu caso de uso, criar sua solução e operacionalizá-la para uso após a implantação.
Imagem intitulada LLM Lifecycle no mundo real. É composto por três círculos, conectados com setas e cercados por uma seta maior rotulada como "gerenciamento". O primeiro círculo é rotulado como "Idealizando/Explorando" e inclui "prompts de tentativa", "Hipótese" e "Encontrar LLMs". Ele decorre da seta de necessidade de negócios e está conectado ao segundo círculo com uma seta rotulada como "projeto avançado". O segundo círculo é rotulado como "Construção/aumento" e é composto por "geração aumentada de recuperação", "tratamento de exceções", "engenharia imediata ou ajuste fino" e "avaliação". O segundo círculo se conecta ao último círculo com "preparar para implantação do aplicativo". O último círculo é o maior, é rotulado como "operacionalização" e é composto por "implantar aplicativo/interface do usuário LLM", "gerenciamento de cotas e custos", "filtragem de conteúdo", "implantação/preparação segura" e "monitoramento". O último círculo está conectado ao segundo círculo com "enviar feedback", enquanto o segundo está conectado ao primeiro com 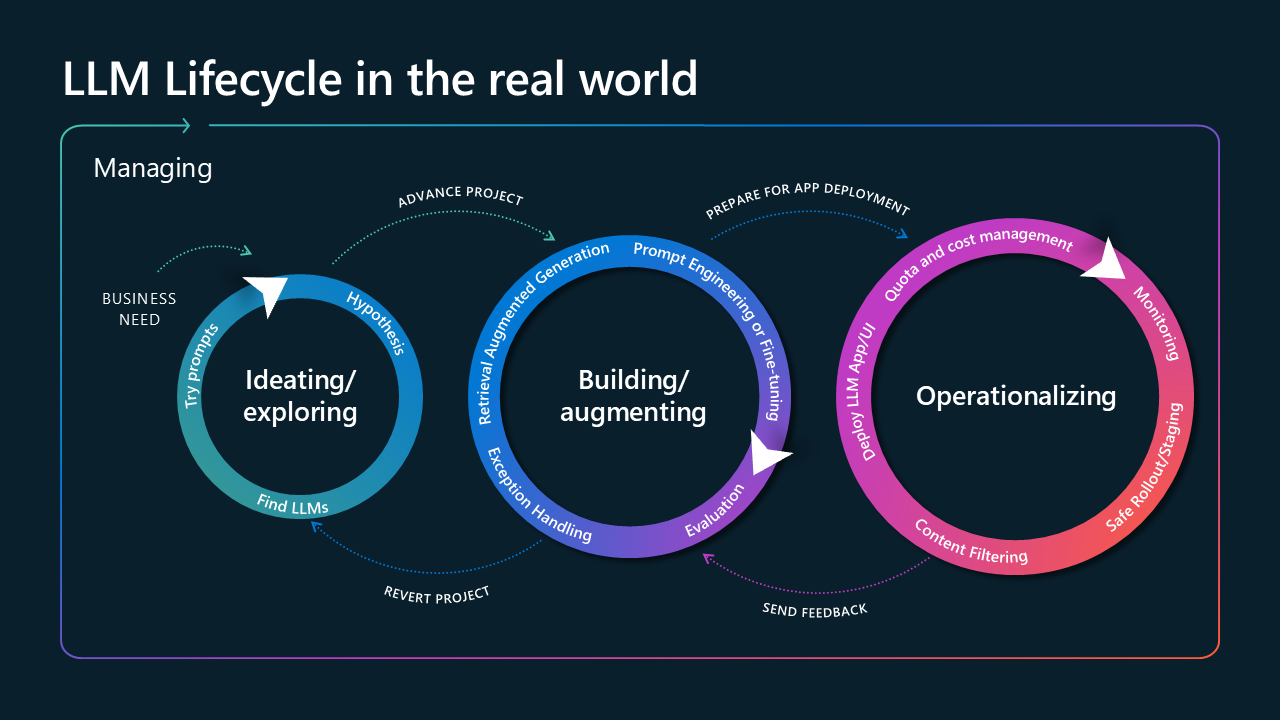
A primeira fase é composta por identificar seu caso de uso e idealizar abordagens tecnológicas para construí-lo. Depois de identificar um caminho para criar seu aplicativo, você entra na segunda fase, que consiste em desenvolver e avaliar o aplicativo. Depois que o aplicativo é implantado na produção, ele entra na última fase, onde pode ser observado e atualizado.
Os insights de observabilidade obtidos na segunda e terceira fases tornam-se críticos ao retornar às fases anteriores para realizar atualizações e implantações. Ao realizar testes contínuos e recuperar métricas para informar processos anteriores, você pode continuar ajustando seu aplicativo.
É importante entender quais ações você pode tomar para praticar a observabilidade em diferentes pontos do processo. Em um alto nível, as seguintes ações de observabilidade ocorrem durante o ciclo de vida do aplicativo:
Primeira fase
- Personas não técnicas, como gerentes de produto, praticam a observabilidade ao identificar as principais qualidades de seu aplicativo.
- As partes interessadas podem definir quais métricas são mais importantes para medir o desempenho de seu aplicativo, como métricas de risco e segurança, métricas de qualidade ou métricas de execução.
- As equipes podem definir metas para métricas como engajamento do usuário e gerenciamento de custos.
- As personas técnicas se concentram na identificação de plataformas, ferramentas e métodos que podem permitir com mais sucesso a criação do aplicativo.
- Essa etapa pode incluir a escolha de um padrão a ser usado, a escolha de um modelo de linguagem grande (LLM) e a identificação das principais fontes de dados a serem extraídas.
Segunda fase
- Durante esse estágio, desenvolvedores e cientistas de dados podem configurar sua solução para ser facilmente monitorada e iterada. Para promover a observabilidade posteriormente, os ISVs podem:
- Crie conjuntos de dados dourados e conjuntos de dados automatizados de conversas de vários turnos para avaliação do copiloto.
- Depure, execute e avalie o fluxo com um subconjunto de dados.
- Crie variações para avaliação de modelo com prompts diferentes.
- Execute a otimização de preços e recursos adequada para a redução de custos do LLM para iterar e construir.
- Os desenvolvedores se concentram em realizar experimentos durante o desenvolvimento e avaliar a qualidade de seus aplicativos antes de implantá-los em produção. Durante esse estágio, é fundamental:
- Avalie o desempenho geral do aplicativo com conjuntos de dados de teste usando métricas predefinidas, incluindo a eficácia do modelo e do prompt.
- Compare os resultados desses testes, estabeleça uma linha de base e implante o código na produção.
Terceira fase
- Muitos experimentos são conduzidos enquanto o aplicativo está sendo usado ativamente na produção. É importante monitorar sua solução para garantir que ela esteja funcionando adequadamente. Durante esta fase:
- A instrumentação de telemetria incorporada no aplicativo emite os rastreamentos, métricas e logs relevantes.
- Os serviços de nuvem emitem a integridade do Azure OpenAI e outras métricas relevantes.
- O armazenamento de telemetria personalizado contém dados sobre rastreamentos, métricas, logs, uso, consentimento e outras métricas relevantes.
- As experiências de painel pré-configuradas permitem que desenvolvedores, cientistas de dados e administradores monitorem o desempenho da API LLM e a integridade do sistema no ambiente de produção.
- O feedback dos usuários finais é enviado de volta aos desenvolvedores e cientistas de dados para avaliação para ajudar a melhorar a solução.
A coleta de dados e a telemetria fornecem informações sobre as áreas a serem abordadas e melhoradas no futuro. Ao tomar medidas preventivas durante a fase de ideação, como identificar métricas apropriadas e realizar avaliações rigorosas de sua solução durante a criação de seu aplicativo, você pode preparar sua solução para o sucesso mais tarde.
Desafios de observabilidade em IA generativa
Embora a observabilidade em geral possa exigir que os ISVs superem muitos obstáculos, as soluções de IA generativa introduzem considerações e desafios específicos.
Avaliação qualitativa
Como as respostas imediatas de IA generativa são fornecidas em formato de linguagem natural, elas precisam ser avaliadas exclusivamente. Por exemplo, eles podem ser verificados quanto a qualidades como fundamentação e relevância.
Os ISVs precisam considerar o melhor caminho para medir essas qualidades, seja para avaliação manual ou métricas assistidas por IA com um humano no loop para validação final.
Não importa como você o avalie, você provavelmente também precisará de conjuntos de dados preexistentes para comparar suas respostas imediatas. Essas preparações podem significar mais trabalho durante o desenvolvimento do aplicativo, pois você identifica uma resposta ideal para tópicos comuns de prompt.
IA responsável
Novas considerações e expectativas para a IA ética introduzem a necessidade de monitorar privacidade, segurança, inclusão e muito mais. Os ISVs precisam monitorar esses atributos para promover a segurança do usuário final, reduzir o risco e minimizar as experiências negativas do usuário.
Os seis princípios de IA responsável da Microsoft ajudam a promover sistemas de IA seguros, éticos e confiáveis. Para promover esses valores em sua solução, avaliar seu aplicativo em relação a esses padrões é fundamental.
Métricas de monitoramento de uso e custo
Os tokens são a principal unidade de medida para aplicativos generativos de IA, e todos os prompts e respostas são tokenizados para que possam ser medidos. Acompanhar o número de tokens usados é essencial, pois afeta o custo para executar seu aplicativo.
Métricas de serviços públicos
Monitorar a satisfação do usuário e o impacto nos negócios do seu aplicativo são tão críticos quanto as métricas de desempenho ou qualidade. Como a IA interage com os clientes de maneiras diferentes, há novas considerações para monitorar o envolvimento e a retenção do cliente.
Medir a utilidade das respostas de sua IA pode ser feito de muitas maneiras diferentes. Por exemplo, os funis de prompt e resposta rastreiam quanto tempo leva para a interação resultar em uma resposta utilizável ou útil. Também é importante considerar o rastreamento do tempo que seu usuário interage com a IA, a duração da conversa e o número de vezes que seu usuário aceita a resposta fornecida. Em cenários em que o usuário pode editar a resposta, é essencial medir a distância de edição ou até que ponto ele edita a resposta.
Métricas de desempenho
A IA requer sistemas cada vez mais complexos e de alto desempenho que devem ser mantidos adequadamente para garantir que sua solução possa processar prompts e dados de forma rápida e eficiente. Como a IA generativa cria conteúdo qualitativo com um grande grau de variedade, é importante ter sistemas para avaliar e testar sua IA em diferentes cenários.
Como as interações do LLM são mais complexas do que um aplicativo típico, elas precisam ser medidas em várias camadas para identificar problemas de latência. Por exemplo, os tempos para tokenizar o prompt do usuário, gerar uma resposta e retornar a resposta a um usuário podem ser medidos separadamente ou como um todo. Cada componente individual do fluxo de trabalho deve ser avaliado para identificar áreas para possíveis problemas.
Sua capacidade de observar sua solução também depende do método de implantação. Os ISVs geralmente adotam um dos dois padrões de implantação para seus aplicativos copiloto. Você pode implantar e gerenciar seus aplicativos em um ambiente que você possui ou implantar aplicativos em um ambiente que pertence a seus clientes.
Para saber mais sobre como a implantação afeta a observabilidade entre os tipos de solução, acesse o guia de observabilidade pró-código.
Métricas para monitorar e avaliar
No domínio ISV de aplicativos de IA generativa e modelos de aprendizado de máquina, é importante avaliar continuamente sua solução e intervir prontamente para conter comportamentos indesejáveis. Monitorar métricas relacionadas à experiência ou feedback do usuário, proteções e IA responsável, consistência de saída, latência e custo são essenciais para otimizar o desempenho de seus aplicativos copilot.
Avaliação qualitativa usando métricas assistidas por IA
Para medir informações qualitativas, os ISVs podem usar métricas assistidas por IA para monitorar suas soluções. As métricas assistidas por IA utilizam LLMs como GPT-4 para avaliar métricas de forma semelhante ao julgamento humano, o que fornece informações mais sutis sobre os recursos de sua solução.
Essas métricas geralmente exigem parâmetros como pergunta, resposta e qualquer contexto circundante da conversa. Eles se enquadram em duas categorias:
- As métricas de risco e segurança monitoram conteúdo de alto risco, como violência, automutilação, conteúdo sexual e conteúdo de ódio
- As métricas de qualidade de geração rastreiam medições qualitativas, como:
- Aterramento - quão bem a resposta do modelo se alinha com as informações do prompt ou da fonte de entrada.
- Relevância: quão bem a resposta do modelo se relaciona com o prompt original.
- Coerência - até que ponto a resposta do modelo é compreensível e semelhante à humana.
- Fluência - a linguística, gramática e sintaxe da resposta do modelo.
Métricas como essas permitem que os ISVs avaliem mais facilmente a qualidade das respostas de seus aplicativos. Eles fornecem uma avaliação rápida e mensurável de muitos valores diferentes que podem ser difíceis de interpretar.
Padrões de IA responsáveis
A Microsoft está comprometida em manter os padrões de IA responsável. Para apoiar isso, estabelecemos um conjunto de padrões de IA responsável que podem ajudá-lo a mitigar os riscos associados à IA generativa:
- Responsabilidade
- Transparência
- Imparcialidade
- Inclusão
- Confiabilidade e segurança
- Privacidade e segurança
Os ISVs podem monitorar métricas que os notificam quando surge um problema. Essas notificações podem incluir métricas qualitativas assistidas por IA que filtram respostas ou solicitações de conteúdo prejudicial ou alertam os ISVs sobre determinados erros ou mensagens sinalizadas.
Por exemplo, o Azure OpenAI oferece soluções que podem medir a porcentagem de prompts e respostas filtrados que não retornaram conteúdo devido à filtragem de conteúdo. Os ISVs devem monitorar os prompts que retornam esses erros e visam reduzir a quantidade que eles ocorrem.
Uso e satisfação do cliente
Alguns recursos da IA podem ser monitorados de forma semelhante a outros tipos de aplicativos, como monitorar a retenção de clientes e o tempo gasto no uso do aplicativo. No entanto, existem muitas diferenças no monitoramento da satisfação do cliente que se aplicam especificamente à IA:
- Reação do usuário à resposta. Isso pode ser medido por meio de métricas tão simples quanto se um usuário reage a uma resposta com o polegar para cima ou para baixo.
- Alterações do usuário na resposta. Em cenários em que o usuário pode modificar a resposta da IA para atender às necessidades dele, o insight pode ser obtido monitorando o quanto o usuário modifica a resposta. Por exemplo, um e-mail redigido que o usuário alterou drasticamente provavelmente não foi tão útil quanto um e-mail redigido que o usuário enviou no estado em que se encontra.
- Utilização da resposta pelo usuário. Considere monitorar se o usuário executa uma ação por meio do aplicativo em resposta à IA. Se uma IA sugerir uma ação por meio de seu aplicativo, meça a taxa de usuários que aceitam a sugestão.
O objetivo de muitos aplicativos de IA é criar uma resposta que seu usuário considere útil. Usar um funil de prompt e resposta é uma maneira comum de medir a rapidez com que sua solução pode gerar uma resposta útil. Esse funil mede a quantidade de tempo e interações que leva para sua solução criar uma resposta que o usuário mantém ou encerra a conversa.
Nesse conceito, o funil começa quando um usuário envia um prompt. À medida que a IA gera respostas com as quais o usuário pode interagir, o funil se estreita à medida que as respostas se aproximam do que o usuário deseja. Por exemplo, o usuário pode editar a resposta da IA ou pedir uma resposta ligeiramente diferente. Quando o usuário estiver satisfeito com a interação, ele terá as informações específicas que procurava e o funil termina. Medir quantas interações são necessárias para que seu prompt passe de amplo para útil e específico é útil para determinar a eficácia do seu aplicativo para o cliente.
Ao observar como seus usuários interagem com sua solução, você pode fazer inferências sobre a utilidade de seu aplicativo. Se seus usuários utilizarem consistentemente as saídas do seu LLM sem realizar mais ações, é provável que a resposta tenha sido útil para eles.
Monitoramento de custos
Como os recursos necessários para executar um aplicativo de IA generativa podem aumentar rapidamente, é essencial observá-los de forma consistente.
Algumas áreas que podem afetar a otimização de custos do seu aplicativo incluem:
- Utilização da GPU
- Custos e considerações de armazenamento
- Considerações de dimensionamento
Garantir a visibilidade dessas métricas pode ajudá-lo a manter os custos sob controle, enquanto a configuração de sistemas de alerta ou processos automáticos relacionados a essas métricas também pode ser útil para solicitar uma ação imediata.
Por exemplo, o número de tokens de prompt e conclusão que seu aplicativo usa afeta diretamente a utilização da GPU e o custo para operar sua solução. Monitorar de perto o uso do token e configurar alertas se ele ultrapassar determinados limites pode ajudá-lo a ficar ciente do comportamento do aplicativo.
Disponibilidade e desempenho da solução
Como acontece com todas as soluções, o monitoramento consistente de aplicativos de IA pode ajudar a impulsionar um alto nível de desempenho. Uma grande diferença entre aplicativos de IA generativa e outros é o conceito de tokenização, que precisa ser considerado ao medir o desempenho.
Os ISVs que criam soluções de IA generativa podem medir:
- O tempo para renderizar o primeiro token
- Os tokens renderizados por segundo
- As solicitações por segundo que seu aplicativo pode gerenciar
Embora todas essas métricas possam ser medidas como um grupo, também é importante observar que os LLMs têm várias camadas. Por exemplo, o tempo que leva para sua IA gerar uma resposta é composto pelo tempo que leva para:
- Receber o prompt do usuário
- Processar o prompt por meio de tokenização
- Inferir qualquer informação relevante ausente
- Gerar uma resposta
- Compile essas informações em uma resposta por meio da destokenização
- Envie esta resposta de volta para o usuário
A medição em cada uma dessas etapas pode ajudá-lo a identificar atrasos e onde eles estão ocorrendo, permitindo que você resolva o problema em sua origem.
Outras técnicas de avaliação de IA generativa
Conjuntos de dados dourados
Um conjunto de dados dourado é uma coleção de respostas de especialistas para perguntas realistas do usuário que são usadas para fornecer garantia de qualidade do copiloto. Essas respostas não são usadas para treinar seu modelo, mas podem ser comparadas às respostas que seu modelo fornece à mesma pergunta do usuário.
Embora não seja uma métrica que você possa medir, ter uma resposta padronizada de alta qualidade com a qual você pode comparar as respostas do seu LLM ajuda nos resultados da sua solução. Dessa forma, criar seus próprios conjuntos de dados dourados para avaliar o desempenho do copiloto ajuda a acelerar o processo de avaliação do copiloto.
Simulação de conversação em vários turnos
A curadoria manual de conjuntos de dados de avaliação pode ser limitada principalmente a conversas de turno único devido à dificuldade de criar bate-papos de vários turnos com som natural. Em vez de escrever interações com script para comparar as respostas do seu modelo, os ISVs podem desenvolver conversas simuladas para testar as habilidades de conversação de vários turnos do copiloto.
Essa simulação pode gerar diálogo, permitindo que sua IA interaja com um usuário virtual simples. Esse usuário interagiria com sua IA por meio de um script pré-gerado de prompts ou os geraria por meio de IA, permitindo que você criasse um grande número de conversas de teste para avaliar. Você também pode empregar avaliadores humanos para interagir com o aplicativo e gerar conversas mais longas para revisar.
Ao avaliar as interações do seu aplicativo em uma conversa mais longa, você pode avaliar a eficácia com que ele identifica a intenção do usuário e usa o contexto em toda a conversa. Como muitas soluções de IA generativa se destinam a se basear em várias interações do usuário, é essencial avaliar como seu aplicativo lida com conversas de vários turnos.
Ferramentas de desenvolvedor para começar
Os desenvolvedores de ISV e cientistas de dados precisam usar ferramentas e métricas para avaliar suas soluções de LLM. A Microsoft tem muitas opções disponíveis para você explorar.
Estúdio de IA do Azure
O Azure AI Studio fornece recursos de observabilidade para gerenciamento de modelos, benchmarks de modelos, rastreamento, avaliação e ajuste fino de sua solução LLM.
Ele oferece suporte a dois tipos de métricas automatizadas para avaliar aplicativos generativos de IA: métricas tradicionais de ML e métricas assistidas por IA. Você também pode usar o playground de bate-papo e recursos relacionados para testar facilmente seu modelo.
Prompt flow
O fluxo imediato é um conjunto de ferramentas de desenvolvimento projetadas para simplificar o ciclo de desenvolvimento de ponta a ponta de aplicativos de IA baseados em LLM, desde a prototipagem e teste até a implantação e monitoramento. O SDK do fluxo de prompt fornece:
- Avaliadores integrados que oferecem suporte a avaliadores personalizados baseados em código ou prompt por meio do Prompty para atender às necessidades de avaliação específicas da tarefa.
- Rastreamento de prompt que rastreia as entradas, saídas e contexto dos prompts e permite que os desenvolvedores identifiquem as causas e origens dos problemas do modelo
- Painéis de monitoramento, incluindo métricas personalizadas do sistema (por exemplo, uso de token, latência) e personalizadas da avaliação para dar suporte à observabilidade pré e pós-implantação no Azure AI Studio e no Application Insights.
Outras ferramentas
Prompty é uma classe de ativos independente de linguagem para criar e gerenciar prompts de LLM. Ele permite que você acelere o processo de desenvolvimento, fornecendo opções para projetar, testar e aprimorar suas soluções.
PyRIT (Python Risk Identification Tool for Generative AI) é a estrutura de automação aberta da Microsoft para sistemas de IA generativa de red-teaming. Ele permite que você avalie a robustez de seus copilotos em relação a diferentes categorias de danos.
Próximas etapas
Ao projetar seu aplicativo de IA generativa com observabilidade e monitoramento em mente, você pode avaliar sua qualidade desde o desenvolvimento até a produção. Comece com as ferramentas disponíveis para começar a desenvolver seu aplicativo ou explore opções para monitorar uma solução que já está em produção.
Recursos adicionais
Como avaliar LLMs: uma estrutura métrica completa - Microsoft Research
Mais orientações sobre como avaliar sua inscrição no LLM
Introdução ao fluxo de prompt - Azure Machine Learning | Microsoft Learn
Informações sobre como configurar e começar a trabalhar com o fluxo imediato