Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Antes de usar o recurso de mineração de processos do Power Automate de maneira eficaz, você precisa compreender:
- Requisitos de dados.
- Onde obter dados de registro de seu aplicativo.
- Como conectar a uma fonte de dados.
Assista a um vídeo curto sobre como carregar dados para usar com o recurso de mineração de processos:
Requisitos de dados
Logs de eventos e logs de atividades são tabelas armazenadas no sistema de registro que documentam quando ocorre um evento ou uma atividade. Por exemplo, as atividades realizadas no aplicativo CRM (gerenciamento de relacionamento com o cliente) são salvas como um log de eventos no aplicativo CRM. Para que a mineração de processos analise o log de eventos, os seguintes campos são necessários:
ID do Caso
A ID do caso deve representar uma instância do seu processo e geralmente é o objeto sobre o qual o processo atua. Pode ser uma "ID do paciente" para um processo de check-in de paciente internado, uma "ID do pedido" para um processo de envio de pedido ou uma "ID do pedido" para um processo de aprovação. Esta ID deve estar presente para todas as atividades no log.
Nome da Atividade
As atividades são as etapas do seu processo e os nomes das atividades descrevem cada etapa. Em um processo de aprovação comum, os nomes das atividades podem ser "enviar solicitação", "solicitação aprovada", "solicitação rejeitada" e "revisar solicitação".
Carimbo de data/hora de Início e Carimbo de data/hora de Término
Os carimbos de data/hora indicam a hora exata em que um evento ou atividade ocorreu. Os logs de eventos têm apenas um carimbo de data/hora. Isso indica a hora em que um evento ou atividade ocorreu no sistema. Os registros de atividades têm dois carimbos de data/hora: um carimbo de data/hora de início e um carimbo de data/hora de término. Eles indicam o início e o fim de cada evento ou atividade.
Você também pode estender sua análise ingerindo tipos de atributo opcionais:
Recurso
Um recurso humano ou técnico executando um evento específico.
Atributo de Nível de Evento
Atributo analítico adicional, que tem valor diferente por evento, por exemplo, Departamento executando a atividade.
Atributo de Nível de Caso (primeiro evento)
O Atributo de Nível de Caso é um atributo adicional que, do ponto de vista analítico, é considerado como tendo um único valor por caso (por exemplo, Valor da Fatura em USD). No entanto, o log de eventos a ser ingerido não precisa necessariamente estar em conformidade com a consistência, tendo o mesmo valor para o atributo específico para todos os eventos no log de eventos. Talvez não seja possível garantir isso, por exemplo, quando a atualização incremental de dados é usada. O Power Automate Process Mining ingere os dados como estão, armazenando todos os valores fornecidos no log de eventos, mas usa o chamado mecanismo de interpretação de atributos no nível do caso para trabalhar com os atributos no nível do caso.
Em outras palavras, sempre que o atributo é usado para uma função específica, que requer valores de nível de evento (por exemplo, filtragem de nível de evento), o produto usa os valores de nível de evento. Sempre que um valor de nível de caso é necessário (por exemplo, filtro de nível de caso, análise de causa raiz), ele usa o valor interpretado, que é obtido do primeiro evento cronologicamente no caso.
Atributo de Nível de Caso (último evento)
O mesmo que Atributo de Nível de Caso (primeiro evento), mas quando interpretado no nível do caso, o valor é obtido do último evento cronologicamente no caso.
Finanças por Evento
Custo/receita/valor numérico fixo que muda de acordo com a atividade realizada, por exemplo, custos de serviço de entrega. O valor financeiro é calculado como a soma (média, mínimo, máximo) dos valores financeiros por cada evento.
Atributos Financeiros por Caso (primeiro evento)
Os Atributos Financeiros por Caso é um atributo numérico adicional que, do ponto de vista analítico, é considerado como tendo um único valor por caso (por exemplo, Valor da Fatura em USD). No entanto, o log de eventos a ser ingerido não precisa necessariamente estar em conformidade com a consistência, tendo o mesmo valor para o atributo específico para todos os eventos no log de eventos. Talvez não seja possível garantir isso, por exemplo, quando a atualização incremental de dados é usada. O Power Automate Process Mining ingere os dados como estão, armazenando todos os valores fornecidos no log de eventos. No entanto, ele usa o chamado mecanismo de interpretação de atributos no nível do caso para trabalhar com os atributos no nível do caso.
Em outras palavras, sempre que o atributo é usado para uma função específica, que requer valores de nível de evento (por exemplo, filtragem de nível de evento), o produto usa os valores de nível de evento. Sempre que um valor de nível de caso é necessário (por exemplo, filtro de nível de caso, análise de causa raiz), ele usa o valor interpretado, que é obtido do primeiro evento cronologicamente no caso.
Atributos Financeiros por Caso (último evento)
O mesmo que Atributos Financeiros por Caso (primeiro evento), mas quando interpretado no nível do caso, o valor é obtido do último evento cronologicamente no caso.
Onde obter dados de registro de seu aplicativo
O recurso de mineração de processos precisa de dados de log de eventos para executar a mineração de processos. Embora muitas tabelas existentes no banco de dados do seu aplicativo contenham o estado atual dos dados, elas podem não conter um registro histórico dos eventos que aconteceram, que é o formato de log de eventos necessário. Felizmente, em muitos aplicativos maiores, esse log ou registro histórico costuma ser armazenado em uma tabela específica. Por exemplo, muitos aplicativos Dynamics mantêm esse registro na tabela Atividades. Outros aplicativos, como SAP ou Salesforce, têm conceitos semelhantes, mas o nome pode ser diferente.
Nessas tabelas que registram registros históricos, a estrutura de dados pode ser complexa. Pode ser necessário unir a tabela de log a outras tabelas no banco de dados do aplicativo para obter IDs ou nomes específicos. Além disso, nem todos os eventos em que você está interessado são registrados. Pode ser necessário determinar quais eventos devem ser mantidos ou filtrados. Se precisar de ajuda, entre em contato com a equipe de TI que gerencia este aplicativo para entender mais.
Conectar-se a uma fonte de dados
O benefício de se conectar a um banco de dados diretamente é manter o relatório de processos atualizado com os dados mais recentes da origem de dados.
O Power Query dá suporte a uma grande variedade de conectores que fornecem uma maneira para o recurso de mineração de processos se conectar e importar dados da fonte de dados correspondente. Os conectores comuns incluem Texto/CSV, Microsoft Dataverse e banco de dados do SQL Server. Se estiver usando um aplicativo como SAP ou Salesforce, você poderá se conectar a essas fontes de dados diretamente por meio de seus conectores. Para obter informações sobre os conectores compatíveis e como usá-los, acesse Conectores no Power Query.
Experimentar o recurso de mineração de processos com o conector de Texto/CSV
Uma maneira fácil de experimentar o recurso de mineração de processos, independentemente de onde sua fonte de dados está localizada, é usar o conector de Texto/CSV. Pode ser necessário trabalhar com o administrador do banco de dados para exportar uma pequena amostra do log de eventos como um arquivo CSV. Quando você tiver o arquivo CSV, poderá importá-lo para o recurso de mineração de processos usando as etapas a seguir na tela de seleção da fonte de dados.
Observação
É necessário ter o OneDrive for Business para usar o conector Texto/CSV. Se você não tiver o OneDrive for Business, use a Tabela em branco em vez de Texto/CSV, como na etapa 3. Você não poderá importar tantos registros em Tabela em branco.
Na home page de mineração de processos, crie um processo selecionando Começar aqui.
Insira um nome de processo e selecione Criar.
Na tela Escolher fonte de dados, selecione Todas as categorias>Texto/CSV.
Selecione Procurar OneDrive. Talvez seja necessária uma autenticação.
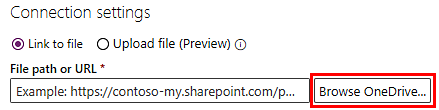
Carregue seu log de eventos selecionando o ícone Carregar no canto superior direito e, depois, selecione Arquivos.
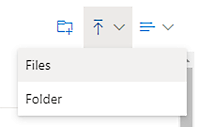
Carregue o log de eventos, selecione o arquivo na lista e, depois, Abrir para usar esse arquivo.
Usar o conector do Fluxo de Dados
O conector do Fluxo de Dados não tem suporte no Microsoft Power Platform. O fluxo de dados existente não pode ser usado como uma fonte de dados para o Power Automate Process Mining.
Usar o conector do Dataverse
O conector Dataverse não é compatível com a Microsoft Power Platform. Você precisa se conectar a ele usando o conector OData, o que exige mais algumas etapas.
Certifique-se de ter acesso ao ambiente do Dataverse.
Você precisa da URL do ambiente do ambiente do Dataverse ao qual está tentando se conectar. Ela costuma ter a seguinte aparência:
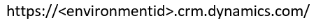
Para saber como encontrar sua URL, consulte Encontrar a URL do seu ambiente do Dataverse.
Na tela Power Query - Escolha fontes de dados, selecione OData.
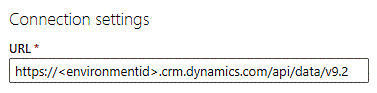
Na caixa de texto da URL, digite api/data/v9.2 no final da URL para que tenha a seguinte aparência:
Em Credenciais de conexão, selecione Conta organizacional no campo Tipo de autenticação.
Selecione Entrar e insira suas credenciais.
Selecione Avançar.
Expanda a pasta OData. Você deve ver todas as tabelas do Dataverse nesse ambiente. Por exemplo, a tabela Atividades é chamada de activitypointers.
Marque a caixa de seleção ao lado da tabela que deseja importar e selecione Próximo.