Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Se o fluxo de dados que você está desenvolvendo estiver ficando maior e mais complexo, aqui estão algumas coisas que você pode fazer para melhorar seu design original.
Dividi-lo em vários fluxos de dados
Não faça tudo em um fluxo de dados. Além de um único fluxo de dados complexo tornar o processo de transformação de dados mais longo, também torna mais difícil entender e reutilizar o fluxo de dados. Dividir o fluxo de dados em vários fluxos de dados pode ser feito separando tabelas em fluxos de dados diferentes ou até mesmo uma tabela em vários fluxos de dados. Você pode usar o conceito de uma tabela computada ou tabela vinculada para criar parte da transformação em um fluxo de dados e reutilizá-la em outros fluxos de dados.
Dividir os fluxos de dados de transformação dos fluxos de dados de preparo/extração
Ter alguns fluxos de dados apenas para extrair dados (ou seja, fluxos de dados de estágio) e outros apenas para transformar dados é útil não só para criar uma arquitetura multicamadas, mas também para reduzir a complexidade dos fluxos de dados. Algumas etapas apenas extraem dados da fonte de dados, como obter dados, navegação e alterações de tipo de dados. Ao separar os fluxos de dados de preparo e os fluxos de dados de transformação, você torna seus fluxos de dados mais simples de desenvolver.
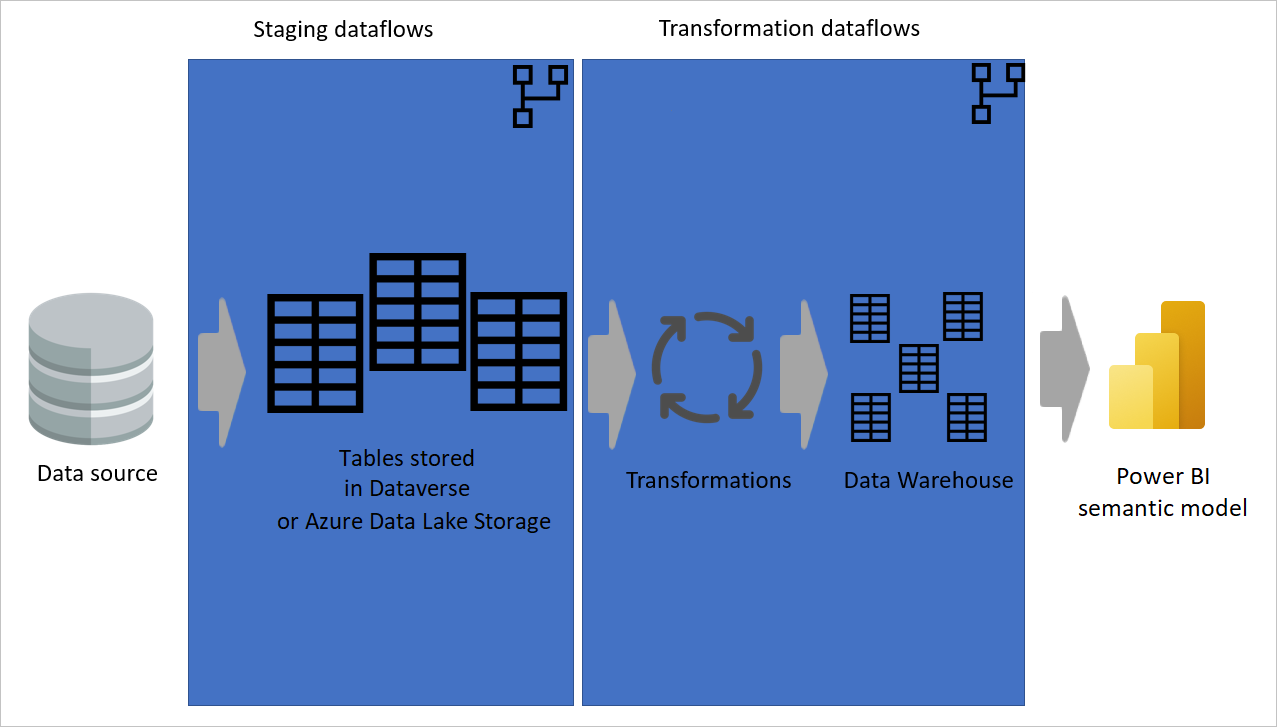
Imagem mostrando dados sendo extraídos de uma fonte de dados para fluxos de dados intermediários, onde as tabelas são armazenadas ou no Dataverse ou no Azure Data Lake Storage. Em seguida, os dados são movidos para fluxos de dados de transformação em que os dados são transformados e convertidos na estrutura do data warehouse. Em seguida, os dados são movidos para o modelo semântico.
Usar funções personalizadas
Funções personalizadas são úteis em cenários em que um determinado número de etapas precisa ser feito para várias consultas de diferentes fontes. As funções personalizadas podem ser desenvolvidas por meio da interface gráfica no Editor do Power Query ou usando um script M. As funções podem ser reutilizadas em um fluxo de dados em quantas tabelas forem necessárias.
Ter uma função personalizada ajuda tendo apenas uma única versão do código-fonte, para que você não precise duplicar o código. Como resultado, manter a lógica de transformação do Power Query e todo o fluxo de dados é muito mais fácil. Para obter mais informações, vá para a seguinte postagem no blog: Funções Personalizadas Facilitadas no Power BI Desktop.
Nota
Às vezes, você pode receber uma notificação informando que uma capacidade premium é necessária para atualizar um fluxo de dados com uma função personalizada. Você pode ignorar essa mensagem e reabrir o editor de fluxo de dados. Isso geralmente resolve seu problema, a menos que a função se refira a uma consulta com "carregamento habilitado".
Colocar consultas em pastas
Usar pastas para consultas ajuda a agrupar consultas relacionadas. Ao desenvolver o fluxo de dados, gaste um pouco mais de tempo para organizar consultas em pastas que fazem sentido. Usando essa abordagem, você pode encontrar consultas com mais facilidade no futuro e manter o código é muito mais fácil.
Usar tabelas computadas
As tabelas computadas não só tornam seu fluxo de dados mais compreensível, como também fornecem melhor desempenho. Quando você usa uma tabela computada, as outras tabelas referenciadas nela estão recebendo dados de uma tabela "já processada e armazenada". A transformação é muito mais simples e rápida.
Aproveitar o mecanismo de computação aprimorado
Para fluxos de dados desenvolvidos no portal de administração do Power BI, verifique se você usa o mecanismo de computação aprimorado executando junções e filtrando transformações primeiro em uma tabela computada antes de fazer outros tipos de transformações.
Dividir várias etapas em várias consultas
É difícil acompanhar um grande número de etapas em uma tabela. Em vez disso, você deve dividir um grande número de etapas em várias tabelas. Você pode usar Habilitar Carregamento para outras consultas e desabilitá-las se forem consultas intermediárias, carregando apenas a tabela final por meio do fluxo de dados. Quando você tem várias consultas com etapas menores em cada uma, é mais fácil usar o diagrama de dependência e acompanhar cada consulta para uma investigação mais aprofundada, em vez de pesquisar centenas de etapas em uma consulta.
Adicionar propriedades para consultas e etapas
A documentação é a chave para ter um código fácil de manter. No Power Query, você pode adicionar propriedades às tabelas e também às etapas. O texto que você adiciona nas propriedades aparece como uma dica de ferramenta quando você passa o mouse sobre essa consulta ou etapa. Esta documentação ajuda você a manter seu modelo no futuro. Com um olhar para uma tabela ou etapa, você pode entender o que está acontecendo lá, em vez de repensar e lembrar o que você fez nessa etapa.
Verifique se a capacidade está na mesma região
Atualmente, os fluxos de dados não dão suporte a vários países ou regiões. A capacidade Premium deve estar na mesma região que o tenant do Power BI.
Separar fontes locais de fontes de nuvem
Recomendamos que você crie um fluxo de dados separado para cada tipo de origem, como local, nuvem, SQL Server, Spark e Dynamics 365. A separação de fluxos de dados por tipo de origem facilita a solução de problemas rápida e evita limites internos ao atualizar seus fluxos de dados.
Separar fluxos de dados com base na atualização agendada necessária para tabelas
Se você tiver uma tabela de transações de vendas que seja atualizada no sistema de origem a cada hora e tiver uma tabela de mapeamento de produtos que seja atualizada a cada semana, divida essas duas tabelas em dois fluxos de dados com agendas de atualização de dados diferentes.
Evite agendar a atualização para tabelas vinculadas no mesmo espaço de trabalho
Se você estiver sendo bloqueado regularmente de seus fluxos de dados que contêm tabelas vinculadas, pode ser devido a um fluxo de dados correspondente e dependente no mesmo espaço de trabalho que fica bloqueado durante a atualização do fluxo de dados. Esse bloqueio fornece precisão transacional e garante que ambos os fluxos de dados sejam atualizados com êxito, mas pode impedi-lo de editar.
Se você configurar um agendamento separado para o fluxo de dados vinculado, os fluxos de dados poderão ser atualizados desnecessariamente e impedir que você edite o fluxo de dados. Há duas recomendações para evitar esse problema:
- Não defina um agendamento de atualização para um fluxo de dados vinculado no mesmo workspace que o fluxo de dados de origem.
- Se você quiser configurar um agendamento de atualização separadamente e quiser evitar o comportamento de bloqueio, mova o fluxo de dados para um workspace separado.