TripPin parte 5 - Paginação
Este tutorial de várias partes aborda a criação de uma nova extensão de fonte de dados para o Power Query. O tutorial deve ser seguido sequencialmente; cada lição se baseia no conector criado nas lições anteriores, adicionando incrementalmente novos recursos a ele.
Nesta lição, você vai:
- Adicionar suporte de paginação ao conector
Muitas APIs Rest retornam dados em "páginas", exigindo que os clientes façam várias solicitações para costurar os resultados juntos. Embora haja algumas convenções comuns para paginação (como RFC 5988), ela geralmente varia de API para API. Felizmente, TripPin é um serviço OData e o padrão OData define uma maneira de fazer paginação usando valores odata.nextLink retornados no corpo da resposta.
Para simplificar iterações anteriores do conector, a TripPin.Feed função não estava ciente da página. Ele simplesmente analisou qualquer JSON retornado da solicitação e formatou-o como uma tabela. Aqueles familiarizados com o protocolo OData podem ter notado que várias suposições incorretas foram feitas no formato da resposta (por exemplo, supondo que haja um value campo contendo uma matriz de registros).
Nesta lição, você melhorará sua lógica de tratamento de resposta, tornando-a ciente da página. Tutoriais futuros tornam a lógica de tratamento de página mais robusta e capaz de lidar com vários formatos de resposta (incluindo erros do serviço).
Observação
Você não precisa implementar sua própria lógica de paginação com conectores baseados em OData.Feed, pois ele manipula tudo para você automaticamente.
Checklist de paginação
Ao implementar o suporte à paginação, você precisará saber as seguintes coisas sobre sua API:
- Como você solicita a próxima página de dados?
- O mecanismo de paginação envolve o cálculo de valores ou você extrai a URL para a próxima página da resposta?
- Como você sabe quando parar a paginação?
- Há parâmetros relacionados à paginação que você deve estar ciente? (como "tamanho da página")
A resposta para essas perguntas afeta a maneira como você implementa sua lógica de paginação. Embora haja alguma quantidade de reutilização de código em implementações de paginação (como o uso de Table.GenerateByPage, a maioria dos conectores acabará exigindo lógica personalizada.
Observação
Esta lição contém lógica de paginação para um serviço OData, que segue um formato específico. Verifique a documentação da API para determinar as alterações que você precisará fazer no conector para dar suporte ao formato de paginação.
Visão geral da paginação OData
A paginação OData é controlada por anotações nextLink contidas na carga de resposta. O valor nextLink contém a URL para a próxima página de dados. Você saberá se há outra página de dados procurando um campo odata.nextLink no objeto mais externo na resposta. Se não houver campo odata.nextLink, você leu todos os seus dados.
{
"odata.context": "...",
"odata.count": 37,
"value": [
{ },
{ },
{ }
],
"odata.nextLink": "...?$skiptoken=342r89"
}
Alguns serviços OData permitem que os clientes forneçam uma preferência máxima de tamanho de página, mas cabe ao serviço honre-a ou não. O Power Query deve ser capaz de lidar com respostas de qualquer tamanho, portanto, você não precisa se preocupar em especificar uma preferência de tamanho de página, você pode dar suporte a qualquer coisa que o serviço jogue em você.
Mais informações sobre paginação controlada por servidor podem ser encontradas na especificação OData.
Testando o TripPin
Antes de corrigir a implementação de paginação, confirme o comportamento atual da extensão do tutorial anterior. A consulta de teste a seguir recupera a tabela Pessoas e adicionará uma coluna de índice para mostrar a contagem de linhas atual.
let
source = TripPin.Contents(),
data = source{[Name="People"]}[Data],
withRowCount = Table.AddIndexColumn(data, "Index")
in
withRowCount
Ative o Fiddler e execute a consulta no SDK do Power Query. Observe que a consulta retorna uma tabela com 8 linhas (índice 0 a 7).
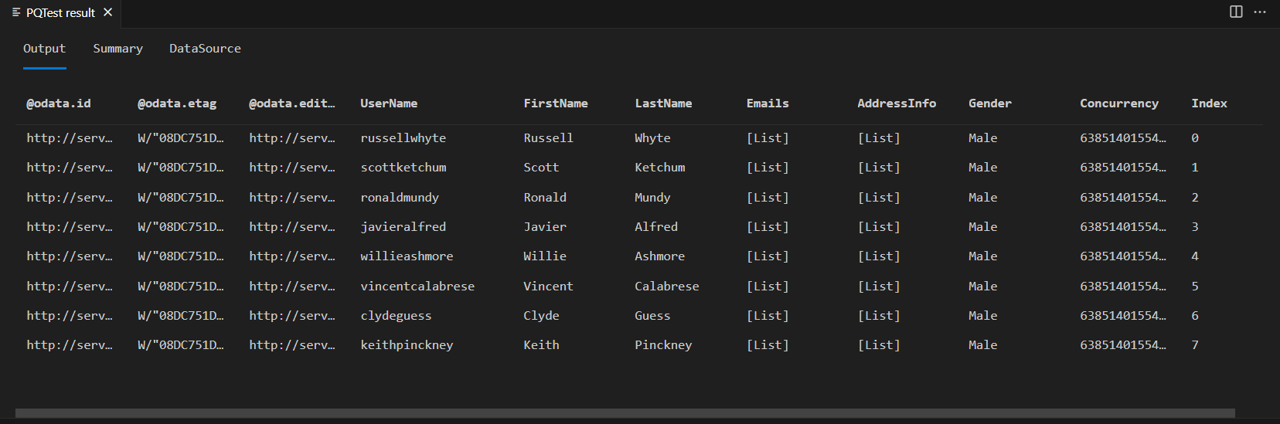
Se você examinar o corpo da resposta do fiddler, verá que ele contém de fato um @odata.nextLink campo, indicando que há mais páginas de dados disponíveis.
{
"@odata.context": "https://services.odata.org/V4/TripPinService/$metadata#People",
"@odata.nextLink": "https://services.odata.org/v4/TripPinService/People?%24skiptoken=8",
"value": [
{ },
{ },
{ }
]
}
Implementando a paginação para o TripPin
Agora você fará as seguintes alterações em sua extensão:
- Importar a função comum
Table.GenerateByPage - Adicionar uma função
GetAllPagesByNextLinkque usaTable.GenerateByPagepara associar todas as páginas - Adicionar uma função
GetPageque pode ler uma única página de dados - Adicionar uma função
GetNextLinkpara extrair a próxima URL da resposta - Atualizar
TripPin.Feedpara usar as novas funções de leitor de página
Observação
Conforme indicado anteriormente neste tutorial, a lógica de paginação variará entre fontes de dados. A implementação aqui tenta dividir a lógica em funções que devem ser reutilizáveis para fontes que usam os próximos links retornados na resposta.
Table.GenerateByPage
Para combinar as múltiplas páginas (potencialmente) retornadas pela fonte em uma única tabela, usaremos Table.GenerateByPage. Esta função recebe como argumento uma getNextPage função que deve fazer exatamente o que o nome sugere: buscar a próxima página de dados. Table.GenerateByPage irá chamar repetidamente a função, getNextPage passando-lhe os resultados produzidos na última vez que foi chamada, até que ela retorne null para sinalizar que não há mais páginas disponíveis.
Como essa função não faz parte da biblioteca padrão do Power Query, você precisará copiar o código-fonte dela para o seu arquivo .pq.
Implementando GetAllPagesByNextLink
O corpo da função GetAllPagesByNextLink implementa o argumento de getNextPage para Table.GenerateByPage. Ele chamará a função GetPage e recuperará a URL para a próxima página de dados do campo NextLink do registro meta da chamada anterior.
// Read all pages of data.
// After every page, we check the "NextLink" record on the metadata of the previous request.
// Table.GenerateByPage will keep asking for more pages until we return null.
GetAllPagesByNextLink = (url as text) as table =>
Table.GenerateByPage((previous) =>
let
// if previous is null, then this is our first page of data
nextLink = if (previous = null) then url else Value.Metadata(previous)[NextLink]?,
// if NextLink was set to null by the previous call, we know we have no more data
page = if (nextLink <> null) then GetPage(nextLink) else null
in
page
);
Implementando GetPage
Sua função GetPage usará Web.Contents para recuperar uma única página de dados do serviço TripPin e converter a resposta em uma tabela. Ele passa a resposta de Web.Contents para a GetNextLink para extrair a URL da próxima página e a define no meta da tabela retornada (página de dados).
Essa implementação é uma versão ligeiramente modificada da TripPin.Feed chamada dos tutoriais anteriores.
GetPage = (url as text) as table =>
let
response = Web.Contents(url, [ Headers = DefaultRequestHeaders ]),
body = Json.Document(response),
nextLink = GetNextLink(body),
data = Table.FromRecords(body[value])
in
data meta [NextLink = nextLink];
Implementando GetNextLink
Sua função GetNextLink simplesmente verifica o corpo da resposta para um campo @odata.nextLink e retorna seu valor.
// In this implementation, 'response' will be the parsed body of the response after the call to Json.Document.
// Look for the '@odata.nextLink' field and simply return null if it doesn't exist.
GetNextLink = (response) as nullable text => Record.FieldOrDefault(response, "@odata.nextLink");
Juntando as peças
A etapa final para implementar sua lógica de paginação é atualizar TripPin.Feed para usar as novas funções. Por enquanto, você está simplesmente chamando GetAllPagesByNextLink, mas em tutoriais subsequentes, você adicionará novos recursos (como impor um esquema e lógica de parâmetro de consulta).
TripPin.Feed = (url as text) as table => GetAllPagesByNextLink(url);
Se você executar novamente a mesma consulta de teste anteriormente no tutorial, agora deverá ver o leitor de página em ação. Você também deve ver que tem 24 linhas na resposta em vez de oito.
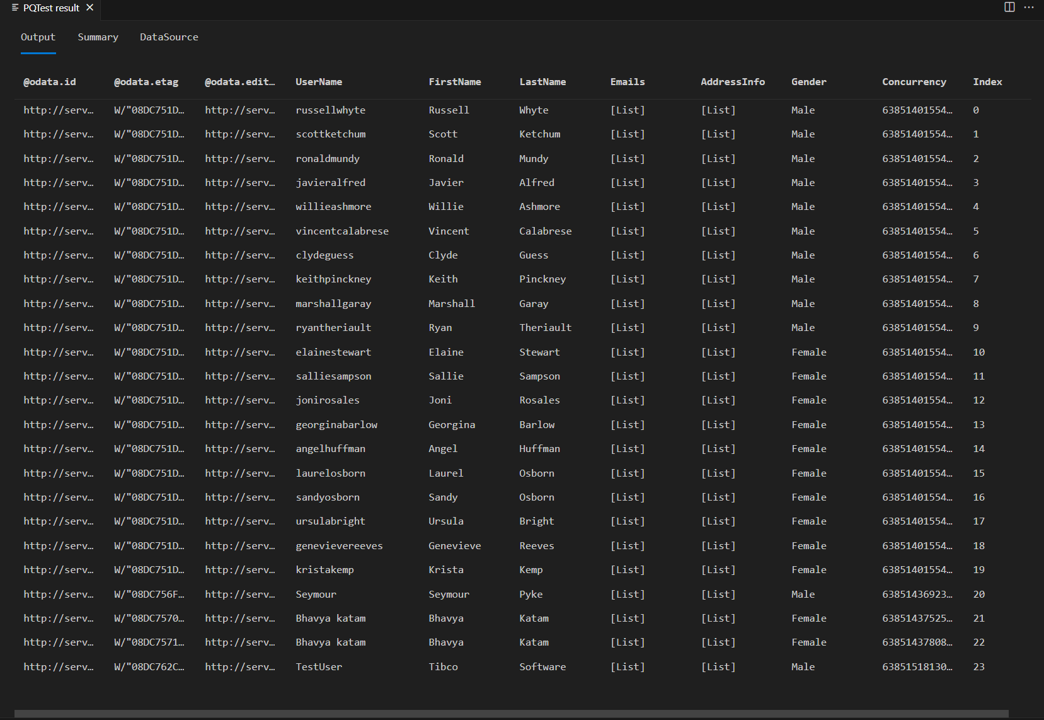
Se você examinar as solicitações no fiddler, agora verá solicitações separadas para cada página de dados.
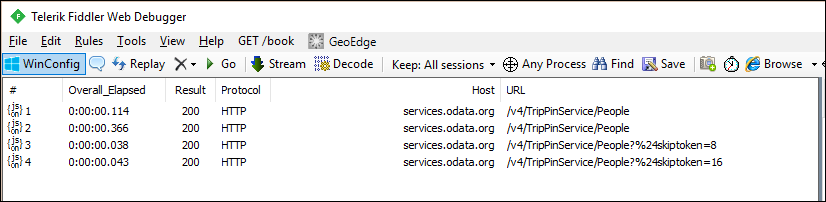
Observação
Você observará solicitações duplicadas para a primeira página de dados do serviço, o que não é ideal. A solicitação extra é resultado do comportamento de verificação de esquema do mecanismo M. Ignore este problema por enquanto e resolva-o no próximo tutorial, onde aplicará um esquema explícito.
Conclusão
Esta lição mostrou como implementar o suporte à paginação para uma API Rest. Embora a lógica provavelmente varie entre APIs, o padrão estabelecido aqui deve ser reutilizável com pequenas modificações.
Na próxima lição, você examinará como aplicar um esquema explícito aos seus dados, indo além dos tipos simples text e number de dados dos quais você obtém Json.Document.