Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
APLICA-SE A: Machine Learning Studio (clássico)
Machine Learning Studio (clássico)  Azure Machine Learning
Azure Machine Learning
Importante
O suporte para o Machine Learning Studio (clássico) terminará em 31 de agosto de 2024. Recomendamos que você faça a transição para o Azure Machine Learning até essa data.
A partir de 1º de dezembro de 2021, você não poderá criar recursos do Machine Learning Studio (clássico). Até 31 de agosto de 2024, você pode continuar usando os recursos existentes do Machine Learning Studio (clássico).
- Consulte informações sobre como mover projetos de machine learning do ML Studio (clássico) para o Azure Machine Learning.
- Saiba mais sobre o Azure Machine Learning
A documentação do ML Studio (clássico) está sendo desativada e pode não ser atualizada no futuro.
Este tópico descreve como escolher o hiperparâmetro correto definido por um algoritmo no Machine Learning Studio (clássico). A maioria dos algoritmos de Machine Learning tem parâmetros para serem definidos. Ao treinar um modelo, você precisa fornecer valores para esses parâmetros. A eficácia do modelo treinado depende dos parâmetros do modelo que você escolhe. O processo de localizar o conjunto ideal de parâmetros é conhecido como seleção de modelo.
Há várias maneiras de realizar a seleção de modelo. No machine learning, a validação cruzada é um dos métodos mais amplamente usados para seleção de modelos e é o mecanismo de seleção de modelo padrão no Machine Learning Studio (clássico). Como o Machine Learning Studio (clássico) dá suporte a R e Python, você sempre pode implementar seus mecanismos de seleção de modelo usando R ou Python.
Há quatro etapas no processo de localizar o melhor conjunto de parâmetros:
- Defina o espaço de parâmetro: para o algoritmo, primeiro decida os valores de parâmetro exatos que você deseja considerar.
- Defina as configurações de validação cruzada: decida como escolher dobras de validação cruzada para o conjunto de dados.
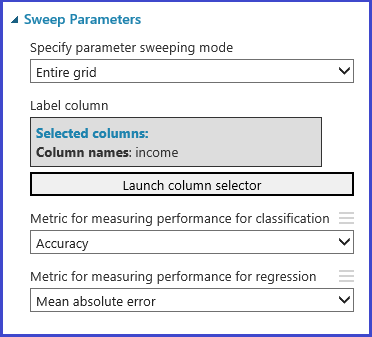
- Defina a métrica: decida qual métrica usar para determinar o melhor conjunto de parâmetros, como precisão, raiz do erro quadrático médio, precisão, recall ou pontuação f.
- Treinar, avaliar e comparar: para cada combinação exclusiva dos valores de parâmetro, a validação cruzada é realizada e com base na métrica de erro que você define. Após a avaliação e a comparação, você pode escolher o modelo com melhor desempenho.
A imagem a seguir ilustra como fazer isso no Machine Learning Studio (clássico).
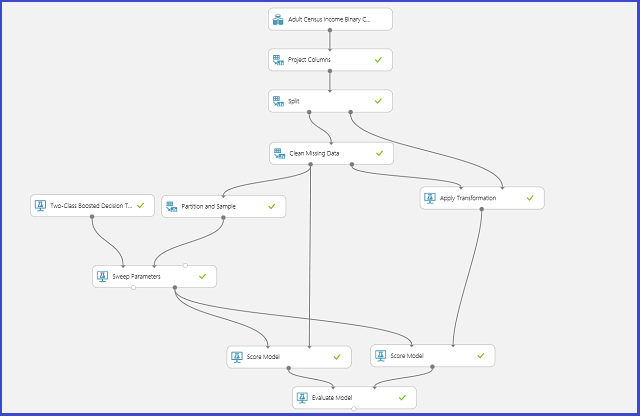
Definir o espaço de parâmetro
Você pode configurar o parâmetro definido na etapa de inicialização de modelo. O painel de parâmetros de todos os algoritmos de aprendizado de máquina tem dois modos de treinador: parâmetro único e intervalo de parâmetros. Escolha o modo de Intervalo de Parâmetros. No modo de intervalo de parâmetros, você pode inserir vários valores para cada parâmetro. Você pode inserir valores separados por vírgula na caixa de texto.
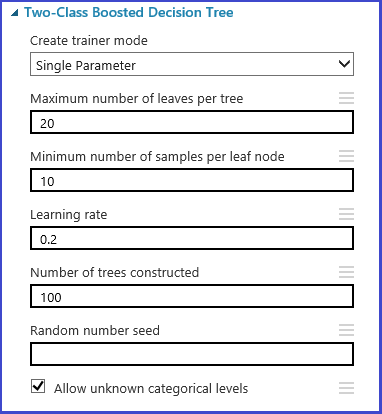
Como alternativa, você pode definir os pontos máximos e mínimos da grade e o número total de pontos a serem gerados com o Construtor de Intervalos de Uso. Por padrão, os valores de parâmetro são gerados em uma escala linear. Mas se a Escala de Logs for verificada, os valores serão gerados na escala de log (ou seja, a proporção dos pontos adjacentes é constante em vez de sua diferença). Para parâmetros de inteiros, você pode definir um intervalo usando um hífen. Por exemplo, "1-10" significa que todos os números inteiros entre 1 e 10 (ambos incluídos) formam o conjunto de parâmetros. Um modo misto também tem suporte. Por exemplo, o conjunto de parâmetros "1-10, 20, 50" incluiria os inteiros 1-10, 20 e 50.
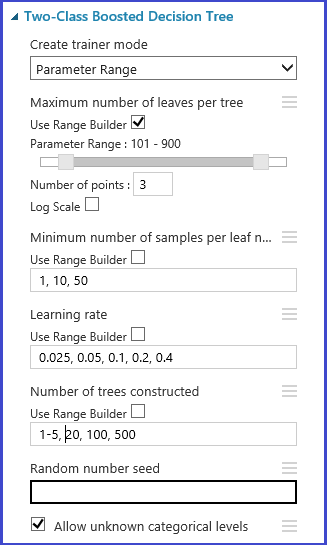
Definir partições de validação cruzada
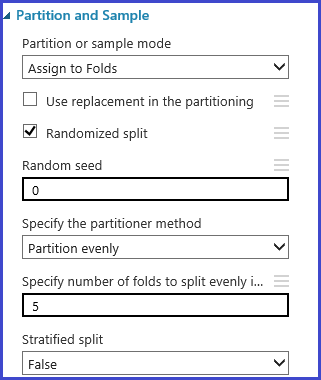
O módulo Partição e Exemplo pode ser usado para atribuir dobras aleatoriamente aos dados. No exemplo de configuração a seguir para o módulo, definimos cinco dobras e atribuímos aleatoriamente um número de dobras para as instâncias de amostra.
Definir a métrica
O módulo Ajustar Hiperparâmetros de Modelo fornece suporte para escolher empiricamente o melhor conjunto de parâmetros para um determinado algoritmo e conjunto de dados. Além de outras informações sobre o treinamento do modelo, o painel Propriedades deste módulo inclui a métrica para determinar o melhor conjunto de parâmetros. Possui duas caixas suspensas de seleção diferentes para algoritmos de classificação e regressão, respectivamente. Se o algoritmo em questão for de classificação, a métrica de regressão será ignorada e vice-versa. Neste exemplo específico, a métrica é Precisão.
Treinar, avaliar e comparar
O mesmo módulo Ajustar Hiperparâmetros de Modelo treina todos os modelos que correspondem ao conjunto de parâmetros, avalia várias métricas e cria o modelo mais bem treinado com base na métrica escolhida. Este módulo tem duas entradas obrigatórias:
- O aprendiz não treinado
- O conjunto de dados
O módulo também tem uma entrada de conjunto de dados opcional. Conecte o conjunto de dados com informações de particionamento ao input obrigatório de dados. Se o conjunto de dados não tiver informações de divisão, uma validação cruzada de 10 folds será executada automaticamente. Se a atribuição de dobra não for feita e um conjunto de dados de validação for indicado na porta opcional de conjunto de dados, então um modo de treinamento de teste é escolhido e o primeiro conjunto de dados é usado para treinar o modelo para cada combinação de parâmetros.
Então, o modelo é avaliado no conjunto de dados de validação. A porta de saída à esquerda do módulo mostra métricas diferentes como funções de valores de parâmetro. A porta de saída direita fornece o modelo treinado que corresponde ao modelo de melhor desempenho de acordo com a métrica escolhida (Precisão neste caso).
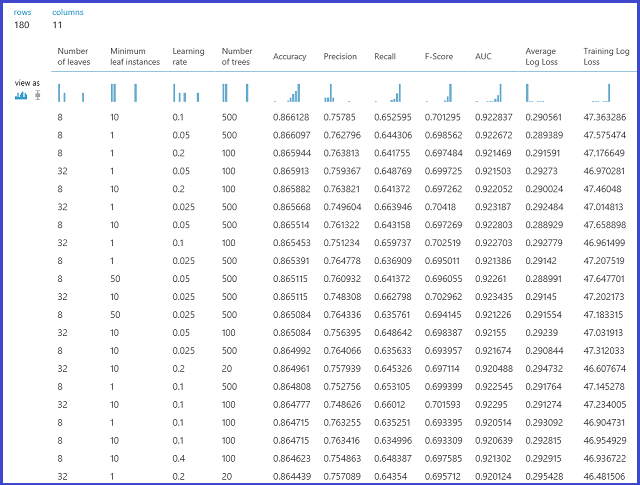
Você pode ver os parâmetros exatos escolhidos visualizando a porta de saída à direita. Esse modelo pode ser usado na pontuação de um conjunto de teste ou em um serviço Web operacionalizado depois de salvá-lo como um modelo treinado.