Tutorial: Visualize and analyze data using RevoScaleR
Important
This content is being retired and may not be updated in the future. The support for Machine Learning Server will end on July 1, 2022. For more information, see What's happening to Machine Learning Server?
Applies to: Microsoft R Client, Machine Learning Server
This tutorial builds on what you learned in the previous data import and exploration tutorial by adding more steps and functions that broaden your experience with RevoScaleR functions. As before, you'll work with airline sample data to complete the steps.
This tutorial focuses on analysis and predictions.
Note
R Client and Machine Learning Server are interchangeable in terms of RevoScaleR as long as data fits into memory and processing is single-threaded. If datasets exceed memory, we recommend pushing the compute context to Machine Learning Server.
What you will learn
- How to fit a linear model
- Compute crosstabs
- Fit a logistic regression model
- Compute predicted values
Prerequisites
To complete this tutorial as written, use an R console application.
- On Windows, go to \Program Files\Microsoft\R Client\R_SERVER\bin\x64 and double-click Rgui.exe.
- On Linux, at the command prompt, type Revo64.
You must also have data to work with. The previous tutorial, Data import and exploration, explains functions and usage scenarios.
Run the following script to reload data from the previous tutorial:
# create data source
mysource <- file.path(rxGetOption("sampleDataDir"), "AirlineDemoSmall.csv")
# set factor levels
colInfo <- list(DayOfWeek = list(type = "factor",
levels = c("Monday", "Tuesday", "Wednesday", "Thursday", "Friday", "Saturday", "Sunday")))
# load data and create an XDF
airXdfData <- rxImport(inData=mysource, outFile="c:/Users/Temp/airExample.xdf", missingValueString="M",
rowsPerRead=200000, colInfo = colInfo, colClasses=c(ArrDelay="integer"), overwrite=TRUE)
# add a custom variable
airXdfData <- rxDataStep(inData = airXdfData, outFile = "c:/Users/Temp/airExample.xdf",
transforms=list(VeryLate = (ArrDelay > 120 | is.na(ArrDelay))), overwrite = TRUE)
# create a second dataset with extra variables
airExtraDS <- rxDataStep(inData=airXdfData, outFile="c:/users/temp/ADS2.xdf",
transforms=list(
Late = ArrDelay > 15,
DepHour = as.integer(CRSDepTime),
Night = DepHour >= 20 | DepHour <= 5), overwrite=TRUE)
# read metadata on the airExtraDS data source
rxGetInfo(airExtraDS, getVarInfo=TRUE, numRows=5)
# read metadata on the airXdfData data source
rxGetInfo(airXdfData, getVarInfo=TRUE)
How to fit a model
This section of the tutorial demonstrates several approaches for fitting a model to the sample data.
Fit a linear model
Use the rxLinMod function to fit a linear model using airXdfData from the previous tutorial. Use a single dependent variable, the factor DayOfWeek:
arrDelayLm1 <- rxLinMod(ArrDelay ~ DayOfWeek, data=airXdfData)
summary(arrDelayLm1)
The resulting output is:
Call:
rxLinMod(formula = ArrDelay ~ DayOfWeek, data = airXdfData)
Linear Regression Results for: ArrDelay ~ DayOfWeek
File name: C:\Users\Temp\airExample.xdf
Dependent variable(s): ArrDelay
Total independent variables: 8 (Including number dropped: 1)
Number of valid observations: 582628
Number of missing observations: 17372
Coefficients: (1 not defined because of singularities)
Estimate Std. Error t value Pr(>|t|)
(Intercept) 10.3318 0.1330 77.673 2.22e-16 ***
DayOfWeek=Monday 1.6938 0.1872 9.049 2.22e-16 ***
DayOfWeek=Tuesday 0.9620 0.2001 4.809 1.52e-06 ***
DayOfWeek=Wednesday -0.1753 0.1980 -0.885 0.376
DayOfWeek=Thursday -1.6738 0.1964 -8.522 2.22e-16 ***
DayOfWeek=Friday 4.4725 0.1957 22.850 2.22e-16 ***
DayOfWeek=Saturday 1.5435 0.1934 7.981 2.22e-16 ***
DayOfWeek=Sunday Dropped Dropped Dropped Dropped
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 40.65 on 582621 degrees of freedom
Multiple R-squared: 0.001869
Adjusted R-squared: 0.001858
F-statistic: 181.8 on 6 and 582621 DF, p-value: < 2.2e-16
Condition number: 10.5595
Using the cube argument and plotting results
If you are using categorical data in your regression, you can use the cube argument. If cube is set to TRUE and the first term of the regression is categorical (a factor or an interaction of factors), the regression is done using a partitioned inverse, which may be faster and use less memory than standard regression computation. Averages/counts of the category "bins" can be computed in addition to standard regression results. The intercept will also be automatically dropped so that each category level will now have an estimated coefficient. If cube is set to TRUE and the first term is not categorical, you get an error message.
Re-estimate the linear model, this time setting cube to TRUE. Print a summary of the results:
arrDelayLm2 <- rxLinMod(ArrDelay ~ DayOfWeek, data = airXdfData,
cube = TRUE)
summary(arrDelayLm2)
You should see the following output:
Call:
rxLinMod(formula = ArrDelay ~ DayOfWeek, data = airXdfData, cube = TRUE)
Cube Linear Regression Results for: ArrDelay ~ DayOfWeek
File name: C:\Users\Temp\airExample.xdf
Dependent variable(s): ArrDelay
Total independent variables: 7
Number of valid observations: 582628
Number of missing observations: 17372
Coefficients:
Estimate Std. Error t value Pr(>|t|) | Counts
DayOfWeek=Monday 12.0256 0.1317 91.32 2.22e-16 *** | 95298
DayOfWeek=Tuesday 11.2938 0.1494 75.58 2.22e-16 *** | 74011
DayOfWeek=Wednesday 10.1565 0.1467 69.23 2.22e-16 *** | 76786
DayOfWeek=Thursday 8.6580 0.1445 59.92 2.22e-16 *** | 79145
DayOfWeek=Friday 14.8043 0.1436 103.10 2.22e-16 *** | 80142
DayOfWeek=Saturday 11.8753 0.1404 84.59 2.22e-16 *** | 83851
DayOfWeek=Sunday 10.3318 0.1330 77.67 2.22e-16 *** | 93395
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 40.65 on 582621 degrees of freedom
Multiple R-squared: 0.001869 (as if intercept included)
Adjusted R-squared: 0.001858
F-statistic: 181.8 on 6 and 582621 DF, p-value: < 2.2e-16
Condition number: 1
The coefficient estimates are the mean arrival delay for each day of the week.
When the cube argument is set to TRUE and the model has only one term as an independent variable, the "countDF" component of the results object also contains category means. This data frame can be extracted using the rxResultsDF function, and is particularly convenient for plotting.
countsDF <- rxResultsDF(arrDelayLm2, type = "counts")
countsDF
You should see the following output:
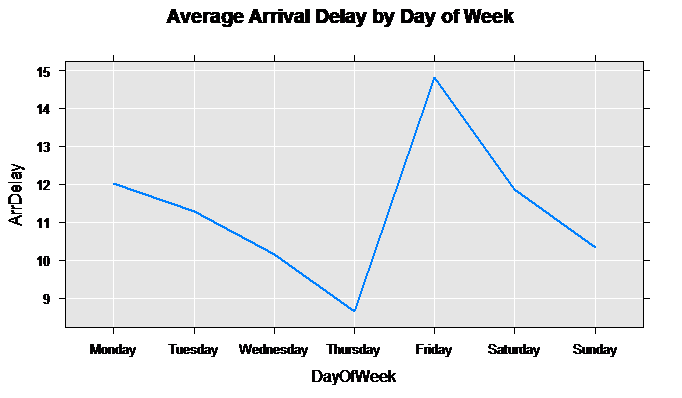
DayOfWeek ArrDelay Counts
1 Monday 12.025604 95298
2 Tuesday 11.293808 74011
3 Wednesday 10.156539 76786
4 Thursday 8.658007 79145
5 Friday 14.804335 80142
6 Saturday 11.875326 83851
7 Sunday 10.331806 93395
Now plot the average arrival delay for each day of the week:
rxLinePlot(ArrDelay~DayOfWeek, data = countsDF,
main = "Average Arrival Delay by Day of Week")
The following plot is generated, showing the lowest average arrival delay on Thursdays:
Linear model with multiple independent variables
We can run a more complex model examining the dependency of arrival delay on both day of week and the departure time. We’ll estimate the model using the F expression to have the CRSDepTime variable interpreted as a categorical or factor variable.
F() is not an R function, although it looks like one when used inside RevoScaleR formulas. An F expression tells RevoScaleR to create a factor by creating one level for each integer in the range (floor(min(x)), floor(max(x))) and binning all the observations into the resulting set of levels. You can look up the rxFormula for more information.
By interacting DayOfWeek with F(CRSDepTime) we are creating a dummy variable for every combination of departure hour and day of the week.
arrDelayLm3 <- rxLinMod(ArrDelay ~ DayOfWeek:F(CRSDepTime),
data = airXdfData, cube = TRUE)
arrDelayDT <- rxResultsDF(arrDelayLm3, type = "counts")
head(arrDelayDT, 15)
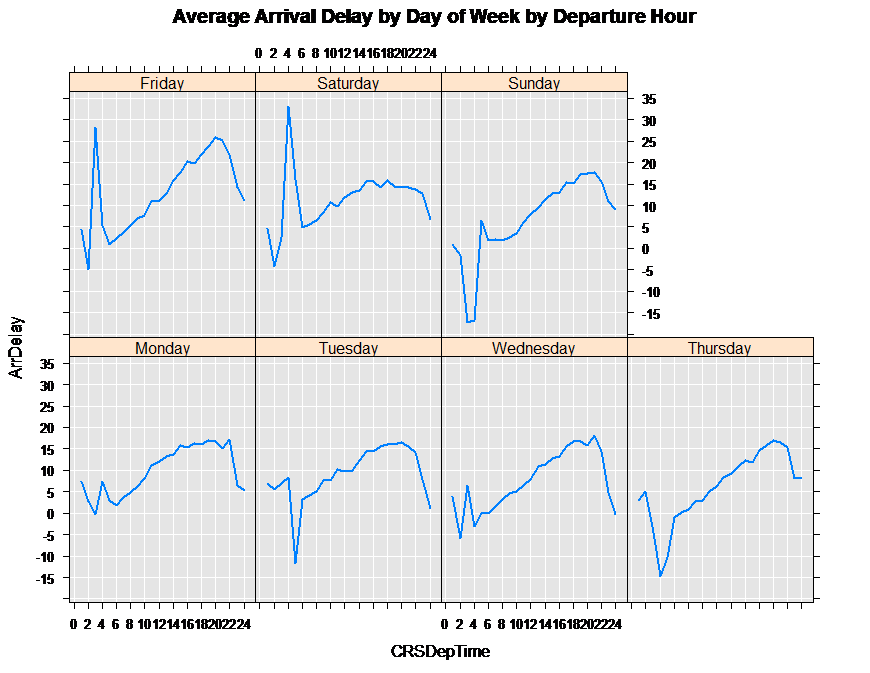
The output shows the first fifteen rows of the counts data frame. The variable CRSDepTime gives the hour of the departure time and ArrDelay shows the average departure delay for that hour for that day of week. Counts gives the number of observations that contain that combination of day of week and departure hour.
DayOfWeek CRSDepTime ArrDelay Counts
1 Monday 0 7.4360902 133
2 Tuesday 0 7.0000000 107
3 Wednesday 0 3.7857143 98
4 Thursday 0 3.0097087 103
5 Friday 0 4.4752475 101
6 Saturday 0 4.5460993 141
7 Sunday 0 0.9243697 119
8 Monday 1 2.6590909 44
9 Tuesday 1 5.5428571 35
10 Wednesday 1 -5.9696970 33
11 Thursday 1 5.1714286 35
12 Friday 1 -4.9062500 32
13 Saturday 1 -4.2727273 44
14 Sunday 1 -1.7368421 38
15 Monday 2 -0.2000000 15
Now plot the results:
rxLinePlot( ArrDelay~CRSDepTime|DayOfWeek, data = arrDelayDT,
title = "Average Arrival Delay by Day of Week by Departure Hour")
You should see the following plot:
Subset the data and compute a crosstab
Create a new data set containing a subset of rows and variables. This is convenient if you intend to do lots of analysis on a subset of a large data set. To do this, we use the rxDataStep function with the following arguments:
- outFile: the name of the new data set
- inData: the name of an .xdf file or an RxXdfData object representing the original data set you are subsetting
- varsToDrop: a character vector of variables to drop from the new data set, here CRSDepTime
- rowSelection: keep only the rows where the flight was more than 15 minutes late
The resulting call is as follows:
airLateDS <- rxDataStep(inData = airXdfData, outFile = "c:/Users/Temp/ADS1.xdf",
varsToDrop = c("CRSDepTime"),
rowSelection = ArrDelay > 15)
ncol(airLateDS)
nrow(airLateDS)
You will see that the new data set has only two variables and has dropped from 600,000 to 148,526 observations.
Compute a crosstab showing the mean arrival delay by day of week.
myTab <- rxCrossTabs(ArrDelay~DayOfWeek, data = airLateDS)
summary(myTab, output = "means")
The results show that in this data set “late” flights are on average over 10 minutes later on Tuesdays than on Sundays:
Call:
rxCrossTabs(formula = ArrDelay ~ DayOfWeek, data = airLateDS)
Cross Tabulation Results for: ArrDelay ~ DayOfWeek
File name: C:\YourWorkingDir\ADS1.xdf
Dependent variable(s): ArrDelay
Number of valid observations: 148526
Number of missing observations: 0
Statistic: means
ArrDelay (means):
means means %
Monday 56.94491 13.96327
Tuesday 64.28248 15.76249
Wednesday 60.12724 14.74360
Thursday 55.07093 13.50376
Friday 56.11783 13.76047
Saturday 61.92247 15.18380
Sunday 53.35339 13.08261
Col Mean 57.96692
Run a logistic regression on the new data
The function rxLogit takes a binary dependent variable. Here we will use the variable Late, which is TRUE (or 1) if the plane was more than 15 minutes late arriving. For dependent variables we will use the DepHour, the departure hour, and Night, indicating whether or not the flight departed at night.
logitObj <- rxLogit(Late~DepHour + Night, data = airExtraDS)
summary(logitObj)
You should see the following results:
Call:
rxLogit(formula = Late ~ DepHour + Night, data = airExtraDS)
Logistic Regression Results for: Late ~ DepHour + Night
File name: C:\Users\Temp\ADS2.xdf
Dependent variable(s): Late
Total independent variables: 3
Number of valid observations: 582628
Number of missing observations: 17372
-2*LogLikelihood: 649607.8613 (Residual deviance on 582625 degrees of freedom)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -2.0990076 0.0104460 -200.94 2.22e-16 ***
DepHour 0.0790215 0.0007671 103.01 2.22e-16 ***
Night -0.3027030 0.0109914 -27.54 2.22e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Condition number of final variance-covariance matrix: 3.0178
Number of iterations: 4
Using the same function, let's estimate whether or not a flight is “very late” depending on the day of week:
logitResults <- rxLogit(VeryLate ~ DayOfWeek, data = airXdfData )
summary(logitResults)
Call:
rxLogit(formula = VeryLate ~ DayOfWeek, data = airXdfData)
Logistic Regression Results for: VeryLate ~ DayOfWeek
File name:
C:\Users\Temp\airExample.xdf
Dependent variable(s): VeryLate
Total independent variables: 8 (Including number dropped: 1)
Number of valid observations: 6e+05
Number of missing observations: 0
-2*LogLikelihood: 251244.7201 (Residual deviance on 599993 degrees of freedom)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -3.29095 0.01745 -188.64 2.22e-16 ***
DayOfWeek=Monday 0.40086 0.02256 17.77 2.22e-16 ***
DayOfWeek=Tuesday 0.84018 0.02192 38.33 2.22e-16 ***
DayOfWeek=Wednesday 0.36982 0.02378 15.55 2.22e-16 ***
DayOfWeek=Thursday 0.29396 0.02400 12.25 2.22e-16 ***
DayOfWeek=Friday 0.54427 0.02274 23.93 2.22e-16 ***
DayOfWeek=Saturday 0.48319 0.02282 21.18 2.22e-16 ***
DayOfWeek=Sunday Dropped Dropped Dropped Dropped
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Condition number of final variance-covariance matrix: 16.7804
Number of iterations: 3
The results show that in this sample, a flight on Tuesday is most likely to be very late or canceled, followed by flights departing on Friday. In this model, Sunday is the control group, so that coefficient estimates for other days of the week are relative to Sunday. The intercept shown is the same as the coefficient you would get for Sunday if you omitted the intercept term:
logitResults2 <- rxLogit(VeryLate ~ DayOfWeek - 1, data = airXdfData )
summary(logitResults2)
Call:
rxLogit(formula = VeryLate ~ DayOfWeek - 1, data = airXdfData)
Logistic Regression Results for: VeryLate ~ DayOfWeek - 1
File name:
C:\Users\Temp\airExample.xdf
Dependent variable(s): VeryLate
Total independent variables: 7
Number of valid observations: 6e+05
Number of missing observations: 0
-2*LogLikelihood: 251244.7201 (Residual deviance on 599993 degrees of freedom)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
DayOfWeek=Monday -2.89008 0.01431 -202.0 2.22e-16 ***
DayOfWeek=Tuesday -2.45077 0.01327 -184.7 2.22e-16 ***
DayOfWeek=Wednesday -2.92113 0.01617 -180.7 2.22e-16 ***
DayOfWeek=Thursday -2.99699 0.01648 -181.9 2.22e-16 ***
DayOfWeek=Friday -2.74668 0.01459 -188.3 2.22e-16 ***
DayOfWeek=Saturday -2.80776 0.01471 -190.9 2.22e-16 ***
DayOfWeek=Sunday -3.29095 0.01745 -188.6 2.22e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Condition number of final variance-covariance matrix: 1
Number of iterations: 7
Computing predicted values
You can use the object returned from the call to rxLogit in the previous section to compute predicted values. In addition to the model object, we specify the data set on which to compute the predicted values and the data set in which to put the newly computed predicted values. In the call below, we use the same dataset for both. In general, the data set on which to compute the predicted values must be similar to the original data set used to estimate the model in the following ways; it should have the same variable names and types, and factor variables must have the same levels in the same order.
predictDS <- rxPredict(modelObject = logitObj, data = airExtraDS,
outData = airExtraDS)
rxGetInfo(predictDS, getVarInfo=TRUE, numRows=5)
You should see the following information:
File name: C:\Users\Temp\ADS2.xdf
Number of observations: 6e+05
Number of variables: 7
Number of blocks: 2
Compression type: zlib
Variable information:
Var 1: ArrDelay, Type: integer, Low/High: (-86, 1490)
Var 2: CRSDepTime, Type: numeric, Storage: float32, Low/High: (0.0167, 23.9833)
Var 3: DayOfWeek
7 factor levels: Monday Tuesday Wednesday Thursday Friday Saturday Sunday
Var 4: Late, Type: logical, Low/High: (0, 1)
Var 5: DepHour, Type: integer, Low/High: (0, 23)
Var 6: Night, Type: logical, Low/High: (0, 1)
Var 7: Late_Pred, Type: numeric, Low/High: (0.0830, 0.3580)
Data (5 rows starting with row 1):
ArrDelay CRSDepTime DayOfWeek Late DepHour Night Late_Pred
1 6 9.666666 Monday FALSE 9 FALSE 0.1997569
2 -8 19.916666 Monday FALSE 19 FALSE 0.3548931
3 -2 13.750000 Monday FALSE 13 FALSE 0.2550745
4 1 11.750000 Monday FALSE 11 FALSE 0.2262214
5 -2 6.416667 Monday FALSE 6 FALSE 0.1645331
Next steps
This tutorial demonstrated how to use several important functions, but on a small data set. Next up are additional tutorials that explore RevoScaleR with bigger data sets, and customization approaches if built-in functions are not quite enough.
- Analyze large data with RevoScaleR and airline flight delay data
- Example: Analyzing loan data with RevoScaleR
- Example: Analyzing census data with RevoScaleR
- Write custom chunking algorithms
Try demo scripts
Another way to learn about ScaleR is through demo scripts. Scripts provided in your Machine Learning Server installation contain code that's very similar to what you see in this tutorial. You can highlight portions of the script, right-click Execute in Interactive to run the script in RTVS.
Demo scripts are located in the demoScripts subdirectory of your Machine Learning Server installation. On Windows, this is typically:
C:\Program Files\Microsoft\R Client\R_SERVER\library\RevoScaleR\demoScripts
See Also
RevoScaleR Getting Started with Hadoop RevoScaleR Getting Started with SQL server Machine Learning Server How-to guides in Machine Learning Server RevoScaleR Functions