Identificar relatórios de bugs de segurança com base em títulos de relatório e dados com ruídos
| Mayana Pereira | Scott Christiansen |
|---|---|
| CELA Data Science | Segurança e confiança do cliente |
| Microsoft | Microsoft |
Resumo: a identificação de SBRs (relatórios de bugs de segurança) é uma etapa essencial no ciclo de vida do desenvolvimento de software. Em abordagens com base em Machine Learning supervisionado, é comum pressupor que os relatórios de bugs inteiros estejam disponíveis para treinamento e que seus rótulos não tenham ruído. Pelo que sabemos, este é o primeiro estudo a mostrar que a previsão de rótulo precisa é possível para SBRs mesmo quando apenas o título está disponível e há ruído no rótulo.
Termos do índice: Machine Learning, rotulagem incorreta, ruído, relatório de bugs de segurança, repositórios de bugs
A identificação de problemas relacionados à segurança entre os bugs relatados é uma necessidade urgente entre as equipes de desenvolvimento de software, pois esses problemas exigem correções mais urgentes para atender aos requisitos de conformidade e garantir a integridade dos dados de software e do cliente.
O Machine Learning e as ferramentas de inteligência artificial prometem tornar o desenvolvimento de software mais rápido, ágil e correto. Vários pesquisadores aplicaram o Machine Learning ao problema da identificação dos bugs de segurança [2], [7], [8], [18]. Os estudos publicados anteriormente consideraram que o relatório de bugs inteiro está disponível para treinamento e pontuação de um modelo de Machine Learning. Esse não é necessariamente o caso. Há situações em que não é possível disponibilizar o relatório de bugs por completo. Por exemplo, o relatório de bugs pode conter senhas, PII (informações de identificação pessoal) ou outros tipos de dados confidenciais, um caso que identificamos atualmente na Microsoft. Portanto, é importante estabelecer a precisão da identificação de bugs de segurança quando executada com menos informações, como quando apenas o título do relatório de bugs está disponível.
Além disso, os repositórios de bugs geralmente contêm entradas com rótulo incorreto [7]: relatórios de bugs não relacionados à segurança classificados como de segurança e vice-versa. Há várias razões para a ocorrência de erros de rótulo, desde a falta de experiência da equipe de desenvolvimento na área de segurança até a imprecisão de determinados problemas; por exemplo, é possível que os bugs não relacionados à segurança sejam explorados de uma maneira indireta para causar uma implicação de segurança. Esse é um problema grave, pois a rotulação incorreta de SBRs faz com que especialistas em segurança precisem analisar manualmente o banco de dados de bugs, uma atividade cara e demorada. Entender como o ruído afeta classificadores diferentes e como as técnicas de Machine Learning robustas (ou frágeis) diferentes estão na presença de conjuntos de dados contaminados por diferentes tipos de ruído é um problema que deve ser resolvido para que a classificação automática passe a ser uma prática na engenharia de software.
O trabalho preliminar argumenta que os repositórios de bugs são intrinsecamente ruidosos e que o ruído pode ter um efeito adverso nos classificadores de desempenho do Machine Learning [7]. No entanto, não há nenhum estudo sistemático e quantitativo de como diferentes níveis e tipos de ruído afetam o desempenho de diferentes algoritmos de Machine Learning supervisionado para o problema de identificação de SRBs.
Neste estudo, mostramos que a classificação dos relatórios de bugs pode ser executada mesmo quando o título está disponível apenas para treinamento e pontuação. Pelo que sabemos, este é o primeiro trabalho a abordar essa questão. Além disso, fornecemos o primeiro estudo sistemático do efeito de ruído na classificação do relatório de bugs. Fazemos um estudo comparativo de robustez das três técnicas de Machine Learning (regressão logística, Naive Bayes e AdaBoost) e ruído independente de classe.
Embora existam alguns modelos analíticos que capturam a influência geral do ruído para alguns classificadores simples [5], [6], esses resultados não fornecem limites rígidos sobre o efeito do ruído na precisão e são válidos somente para uma técnica de Machine Learning específica. Em geral, uma análise precisa do efeito de ruído em modelos de Machine Learning é executada por meio de experimentos computacionais. Essas análises foram executadas para vários cenários que variam de dados de medição de software [4] à classificação da imagem de satélite [13] e aos dados médicos [12]. No entanto, esses resultados não podem ser aproveitados em nosso problema específico devido à sua alta dependência na natureza dos conjuntos de dados e no problema de classificação subjacente. Pelo que sabemos, não há nenhum resultado publicado sobre o problema do efeito de conjuntos de dados com ruído na classificação do relatório de bugs de segurança em particular.
Treinamos classificadores para a identificação de SBRs com base apenas no título dos relatórios. Pelo que sabemos, este é o primeiro trabalho a abordar essa questão. Os trabalhos anteriores usaram o relatório de bugs completo ou aprimoraram o relatório de bugs com recursos complementares adicionais. A classificação de bugs com base apenas no bloco é particularmente relevante quando os relatórios de bugs completos não podem ser disponibilizados devido a questões de privacidade. Por exemplo, destacamos o caso de relatórios de bugs que contêm senhas e outros dados confidenciais.
Também fornecemos o primeiro estudo sistemático do rótulo de tolerância a ruídos de diferentes modelos de Machine Learning e técnicas usadas para a classificação automática de SBRs. Fazemos um estudo comparativo de robustez de três técnicas diferentes de Machine Learning (regressão logística, Naive Bayes e AdaBoosts) e ruídos dependentes e independentes de classe.
O restante do trabalho é apresentado da seguinte forma: na seção II, apresentamos alguns dos trabalhos anteriores na literatura. Na seção III, descrevemos o conjunto de dados e como são previamente processados. A metodologia é descrita na seção IV e os resultados de nossos experimentos são analisados na seção V. Por fim, nossas conclusões e futuros trabalhos são apresentados na seção VI.
Há trabalhos abrangentes sobre a aplicação da mineração de texto, o processamento de linguagem natural e o Machine Learning em repositórios de bugs em uma tentativa de automatizar tarefas trabalhosas, como detecção de bugs de segurança [2], [7], [8], [18], identificação de bugs duplicados [3], triagem de bugs [1], [11], entre outros. O ideal é que a combinação do Machine Learning (ML) e do processamento de linguagem natural reduza o trabalho manual necessário para organizar bancos de dados de bugs, reduzir o tempo necessário para realizar essas tarefas e aumentar a confiabilidade dos resultados.
Em [7], os autores propõem um modelo de linguagem natural para automatizar a classificação de SBRs com base na descrição do bug. Os autores extraem um vocabulário de toda as descrições do bug no conjunto de dados de treinamento e os coletam manualmente em três listas de palavras: palavras relevantes, palavras de parada (palavras comuns que parecem irrelevantes para classificação) e sinônimos. Eles comparam o desempenho do classificador de bugs de segurança treinado em dados que são avaliados por engenheiros de segurança e um classificador treinado em dados que foram rotulados por relatórios de bugs em geral. Embora seu modelo seja claramente mais eficaz quando treinado para dados revisados por engenheiros de segurança, o modelo proposto tem por base um vocabulário derivado manualmente, tornando-o dependente da seleção por humanos. Além disso, não há nenhuma análise de como os diferentes níveis de ruído afetam seu modelo, como classificadores diferentes respondem a ruído, e se o ruído em qualquer classe afeta o desempenho de maneira diferente.
Zou et. al [18] usa vários tipos de informações contidas em um relatório de bugs que envolvem campos não textuais de um relatório de bugs (metarrecursos, por exemplo, hora, gravidade e prioridade) e o conteúdo textual de um relatório de bugs (recursos textuais, ou seja, o texto em campos de resumo). Com base nesses recursos, eles criam um modelo para identificar automaticamente os SBRs por meio do processamento de linguagem natural e das técnicas de Machine Learning. Em [8] os autores executam uma análise semelhante, mas além disso, eles comparam o desempenho de técnicas de Machine Learning supervisionadas e não supervisionadas e estudam a quantidade de dados necessária para treinar seus modelos.
Em [2], os autores também exploram técnicas de Machine Learning diferentes para classificar bugs como SBRs ou NSBRs (relatório de bugs não relacionados à segurança) com base em suas descrições. Eles propõem um pipeline para o processamento de dados e o treinamento de modelo com base em TFIDF. Eles comparam o pipeline proposto com um modelo baseado no conjunto de palavras e Naive Bayes. Wijayasekara et al. [16] também usou técnicas de mineração de texto para gerar o vetor de recurso de cada relatório de bugs com base em palavras frequentes para identificar HIBs (bugs de impacto ocultos). Yang et al. [17] afirmou ter identificado relatórios de bug de alto impacto (por exemplo, SBRs) com a ajuda da frequência de termos (TF) e Naive Bayes. Em [9], os autores propõem um modelo para prever a gravidade de um bug.
O problema de lidar com conjuntos de dados com um ruído de rótulo foi amplamente estudado. Frenay e Verleysen propõem uma taxonomia de ruído de rótulo em [6] para distinguir diferentes tipos de rótulo com ruído. Os autores propõem três tipos diferentes de ruído: o ruído de rótulo que ocorre independentemente da classe verdadeira e dos valores dos recursos da instância; ruído de rótulo que depende apenas do verdadeiro rótulo; e o ruído de rótulo em que a probabilidade de rotulagem incorreta também depende dos valores do recurso. Em nosso trabalho, estudamos os dois primeiros tipos de ruído. Com base em uma perspectiva teórica, o ruído de rótulo geralmente diminui o desempenho de um modelo [10], exceto em alguns casos específicos [14]. Em geral, métodos robustos contam com o sobreajuste de contenção para manipular o ruído de rótulo [15]. O estudo de efeitos de ruído na classificação foi feito antes em muitas áreas, como classificação de imagem de satélite [13], classificação de qualidade de software [4] e classificação de domínio médico [12]. Pelo que sabemos, não há nenhum trabalho publicado que estude a quantificação precisa dos efeitos de rótulos com ruído no problema de classificação de SBRs. Nesse cenário, a relação precisa entre os níveis de ruído, os tipos de ruído e a degradação do desempenho não foi estabelecida. Além disso, vale a pena entender como classificadores diferentes se comportam na presença do ruído. Em geral, não estamos cientes de trabalhos que estudem sistematicamente o efeito de conjuntos de dados ruidosos no desempenho de diferentes algoritmos de Machine Learning no contexto de relatórios de bugs de software.
Nosso conjunto de dados consiste em 1.073.149 títulos de bugs, dos quais 552.073 correspondem a SBRs e 521.076 a NSBRs. Os dados foram coletados por várias equipes na Microsoft nos anos de 2015, 2016, 2017 e 2018. Todos os rótulos foram obtidos por sistemas de verificação de bugs com base em assinatura ou foram rotulados por pessoas. Os títulos de bugs em nosso conjunto de dados são textos muito curtos contendo aproximadamente 10 palavras com uma visão geral do problema.
R. Pré-processamento de dados Analisamos cada título de bug por seus espaços em branco, o que resulta em uma lista de tokens. Cada lista de tokens é processada da seguinte maneira:
Remoção de todos os tokens que são caminhos de arquivo
Divisão de tokens em que os seguintes símbolos estão presentes: {, (,),-,}, {, [,],}
Remoção de palavras irrelevantes, tokens compostos por caracteres numéricos somente e tokens que aparecem menos de cinco vezes em todo o corpus.
O processo de treinamento de nossos modelos de Machine Learning consiste em duas etapas principais: codificar os dados em vetores de recurso e treinar classificadores de Machine Learning supervisionados.
A primeira parte envolve a codificação de dados em vetores de recurso usando o termo algoritmo de frequência inversa no documento (TF-IDF), conforme usado em [2]. A TF-IDF é uma técnica de recuperação de informações que avalia a frequência de termos (TF) e sua frequência inversa no documento (IDF). Cada palavra ou termo tem sua respectiva pontuação de TF e IDF. O algoritmo TF-IDF atribui a importância à palavra com base no número de vezes que aparece no documento e, principalmente, verifica o grau de importância da palavra-chave em toda coleção de títulos no conjunto de dados. Treinamos e comparamos três técnicas de classificação: Naive Bayes (NB), árvores de decisão aumentadas (AdaBoost) e regressão logística (LR). Escolhemos essas técnicas porque tiveram bom desempenho na tarefa relacionada de identificar relatórios de bugs de segurança com base no relatório inteiro dos estudos. Esses resultados foram confirmados em uma análise preliminar, na qual esses três classificadores não têm suporte para máquinas de vetor e florestas aleatórias. Em nossos experimentos, utilizamos a biblioteca scikit-learn para codificação e treinamento de modelo.
O ruído estudado neste trabalho refere-se a ruídos no rótulo de classe nos dados de treinamento. Como consequência, na presença desse ruído, o processo de aprendizado e o modelo resultante são prejudicados por exemplos rotulados. Analisamos o impacto de diferentes níveis de ruído aplicados às informações de classe. Os tipos de ruído de rótulo foram discutidos anteriormente em estudos usando várias terminologias. Em nosso trabalho, analisamos os efeitos de dois ruídos de rótulo diferentes em nossos classificadores: ruído de rótulo independente de classe, que é introduzido ao selecionar instâncias aleatoriamente e inverter seu rótulo; e ruído dependente de classe, em que as classes têm uma probabilidade diferente de serem ruidosas.
a) Ruído independente de classe: refere-se ao ruído que ocorre independentemente da classe verdadeira das instâncias. Nesse tipo de ruído, a probabilidade de rotular pbr é a mesma para todas as instâncias no conjunto de dados. Apresentamos o ruído independente de classe em nossos conjuntos de dados, invertendo aleatoriamente cada rótulo presente neles com probabilidade pbr.
b) Ruído dependente de classe: refere-se ao ruído que depende da classe verdadeira das instâncias. Nesse tipo de ruído, a probabilidade de rotular incorretamente na classe SBR é pSBR e a probabilidade de rotular incorretamente na classe NSBR é pnsbr. Apresentamos o ruído dependente de classe em nosso conjunto de dados invertendo cada entrada no conjunto de dados para o qual o verdadeiro rótulo é SBR com probabilidade psbr. De forma análoga, invertemos o rótulo de classe das instâncias NSBR com probabilidade pnsbr.
c) Ruído de classe única: é um caso especial de ruído dependente de classe, em que pnsbr = 0 e psbr> 0. Observe que, para o ruído independente de classe, temos psbr = pnsbr = pbr.
C. Geração de ruído
Nossos experimentos investigam o impacto de diferentes tipos de ruído e níveis no treinamento de classificadores SBR. Em nossos experimentos, definimos 25% do conjunto de dados como dados de teste, 10% como validação e 65% como dados de treinamento.
Adicionamos ruído aos conjuntos de dados de treinamento e validação para diferentes níveis de pbr, psbr e pnsbr. O conjunto de dados de teste não é modificado. Os diferentes níveis de ruído usados são P = {0.05 × i|0 < i < 10}.
Em experimentos de ruído independentes de classe, para pbr ∈ P, fazemos o seguinte:
Gerar ruído para conjuntos de dados de treinamento e validação
Treinar a regressão logística, modelos de Naive Bayes e AdaBoost usando o conjunto de dados de treinamento (com ruído); * Ajustar modelos usando o conjunto de dados de validação (com ruído)
Testar modelos usando o conjunto de dados de teste (sem ruído)
Em experimentos de ruído dependentes de classe, para psbr ∈ P e pnsbr ∈ P, fazemos o seguinte para todas as combinações de psbr e pnsbr:
Gerar ruído para conjuntos de dados de treinamento e validação
Treinar a regressão logística, modelos de Naive Bayes e AdaBoost usando o conjunto de dados de treinamento (com ruído)
Ajustar modelos usando o conjunto de dados de validação (com ruído)
Testar modelos usando o conjunto de dados de teste (sem ruído)
Nesta seção, analise os resultados de experimentos realizados de acordo com a metodologia descrita na seção IV.
a) Desempenho de modelo sem ruído no conjunto de dados de treinamento: uma das contribuições deste documento é a proposta de um modelo de machine learning para identificar bugs de segurança usando apenas o título do bug como dados para a tomada de decisão. Isso possibilita o treinamento de modelos de Machine Learning mesmo quando as equipes de desenvolvimento não querem compartilhar relatórios de bugs por completo devido à presença de dados confidenciais. Comparamos o desempenho de três modelos de Machine Learning quando treinados usando apenas títulos de bugs.
O modelo de regressão logística é o classificador com melhor desempenho. É o classificador com o maior valor de AUC, de 0,9826, recall de 0,9353 para um valor de FPR de 0,0735. O classificador de Naive Bayes apresenta um desempenho um pouco menor do que o classificador de regressão logística, com um AUC de 0,9779 e um recall de 0,9189 para um FPR de 0,0769. O classificador AdaBoost tem um desempenho inferior em comparação com os dois classificadores mencionados anteriormente. Ele alcança um AUC de 0,9143 e um recall de 0,7018 para um FPR de 0,0774. A área sob a curva ROC (AUC) é uma boa métrica para comparar o desempenho de vários modelos, pois resume em um único valor a relação entre TPR e FPR. Na análise subsequente, vamos restringir nossa análise comparativa aos valores de AUC.

R. Ruído de classe: classe única
É possível imaginar um cenário em que todos os bugs são atribuídos à classe NSBR por padrão, e um bug será atribuído à classe SBR somente se houver um especialista em segurança revisando o repositório de bugs. Esse cenário é representado na configuração experimental de classe única, na qual presumimos que pnsbr = 0 e 0 < psbr< 0,5.
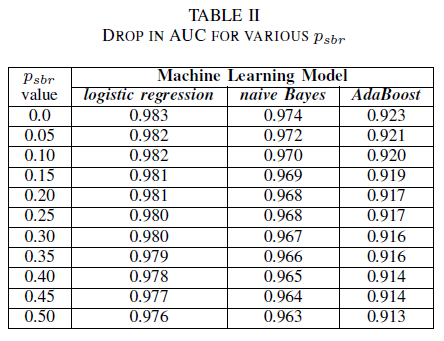
A tabela II mostra um impacto muito pequeno no AUC para todos os três classificadores. O AUC-ROC de um modelo treinado em psbr = 0 em comparação a um AUC-ROC do modelo em que psbr = 0,25 difere em 0,003 para regressão logística; 0,006 para Naive Bayes e 0,006 para AdaBoost. No caso de psbr = 0,50, o AUC medido para cada um dos modelos é diferente do modelo treinado com psbr = 0 em 0,007 para regressão logística; 0,011 para Naive Bayes e 0,010 para AdaBoost. O classificador de regressão logística treinado na presença de um ruído de classe única apresenta a menor variação em sua métrica de AUC, isto é, um comportamento mais robusto, quando comparado aos nossos classificadores Naive Bayes e AdaBoost.
B. Ruído de classe: independente de classe
Comparamos o desempenho de nossos três classificadores para o caso em que o conjunto de treinamento está corrompido por um ruído independente de classe. Medimos o AUC para cada modelo treinado com diferentes níveis de pbr nos dados de treinamento.
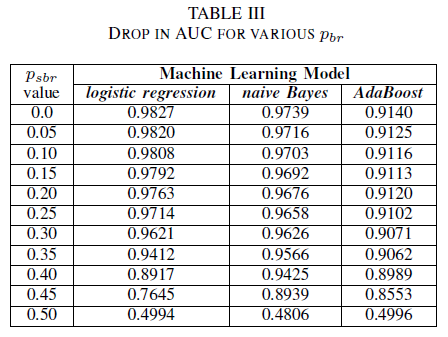
Na Tabela III, observamos uma diminuição na AUC-ROC para cada incremento de ruído no experimento. O AUC-ROC medido de um modelo treinado em dados sem ruído em comparação a um AUC-ROC do modelo treinado com ruído independente de classe com pbr = 0,25 difere em 0,011 para regressão logística; 0,008 para Naive Bayes e 0,0038 para AdaBoost. Observamos que o ruído do rótulo não afeta o AUC dos classificadores Naive Bayes e AdaBoost de forma significativa quando os níveis de ruído são inferiores a 40%. Por outro lado, o classificador de regressão logística identifica um impacto na medida de AUC para os níveis de ruído de rótulo acima de 30%.
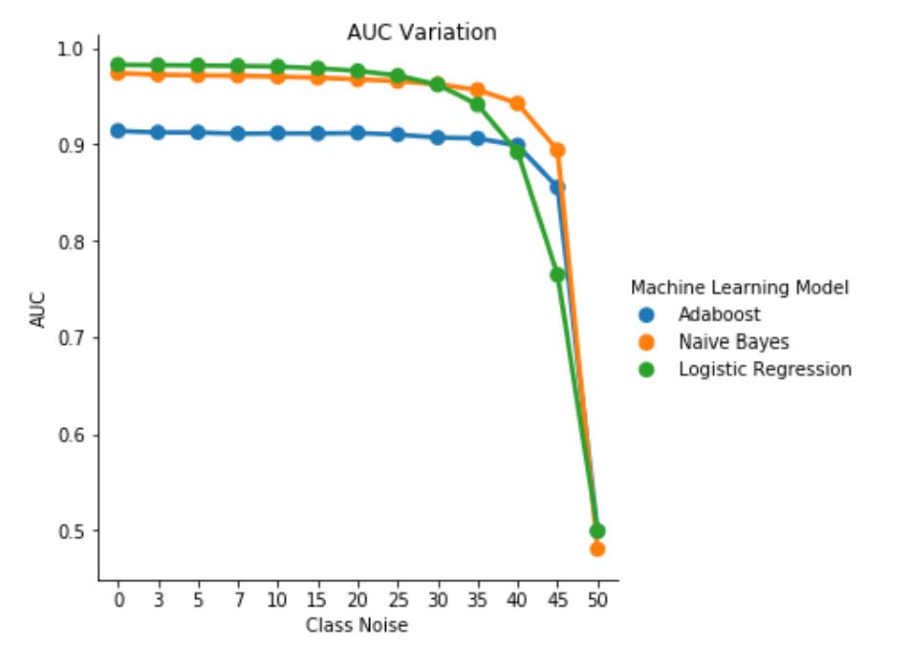
Figura 1. Variação de AUC-ROC em ruído independente de classe. Para um nível de ruído pbr = 0,5, o classificador age como um classificador aleatório, ou seja, AUC ≈ 0,5. Mas podemos observar que, para os níveis de ruído mais baixos (pbr ≤ 0,30), o aprendiz de regressão logística apresenta um melhor desempenho em comparação aos outros dois modelos. No entanto, para 0,35 ≤ pbr ≤ 0,45, o aprendiz de Naive Bayes apresenta métricas de AUCROC melhores.
C. Ruído de classe: dependente de classe
No conjunto final de experimentos, consideramos um cenário em que classes diferentes contêm diferentes níveis de ruído, ou seja, psbr ≠ pnsbr. Podemos incrementar sistematicamente o psbr e o pnsbr de forma independente em 0,05 nos dados de treinamento e observar a alteração no comportamento dos três classificadores.
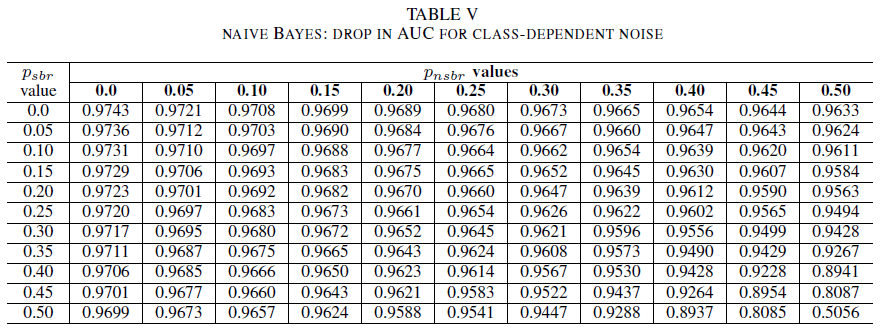
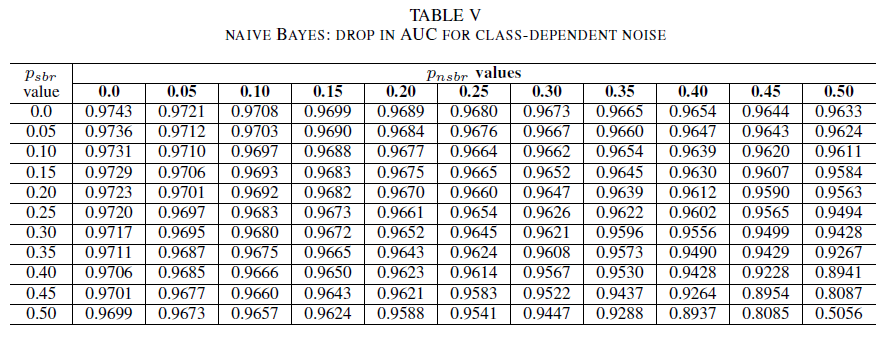
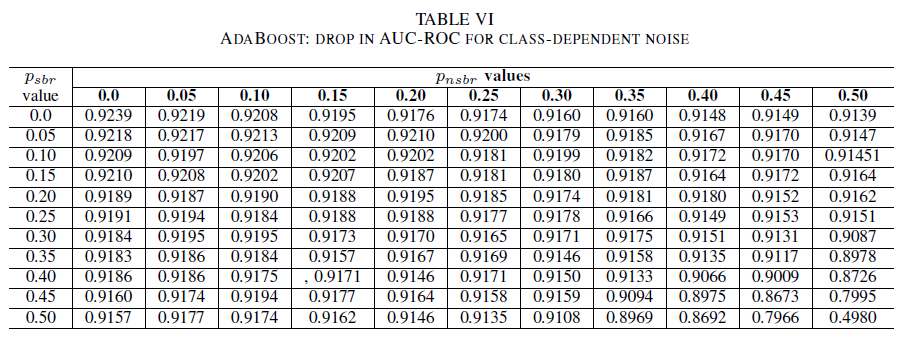
As tabelas IV, V, VI mostram a variação de AUC conforme o ruído é aumentado em diferentes níveis em cada classe para a regressão logística na tabela IV, para Naive Bayes na tabela V e para AdaBoost na tabela VI. Para todos os classificadores, percebemos um impacto na métrica AUC quando ambas as classes contêm nível de ruído acima de 30%. O Naive Bayes tem um comportamento mais robusto. O impacto em AUC é muito pequeno, mesmo quando 50% do rótulo na classe positiva é invertido, considerando que a classe negativa contenha 30% de rótulos com ruídos ou menos. Nesse caso, a queda de AUC é de 0,03. O AdaBoost apresentou o comportamento mais robusto de todos os três classificadores. Uma alteração significativa no AUC ocorrerá somente para níveis de ruído superiores a 45% em ambas as classes. Nesse caso, começamos a observar uma redução de AUC maior que 0,02.
D. Na presença de ruído residual no conjunto de dados original
Nosso conjunto de dados foi rotulado por sistemas automatizados com base em assinatura e por especialistas. Além disso, todos os relatórios de bugs foram revisados e fechados por especialistas. Embora esperemos que a quantidade de ruído em nosso conjunto de dados seja mínima e não estatisticamente significativa, a presença do ruído residual não invalida nossas conclusões. Na verdade, a título de ilustração, suponha que o conjunto de dados original seja corrompido por um ruído independente de classe igual a 0 < p < 1/2 independente e distribuído de forma idêntica (i.i.d) para cada entrada.
Se além do ruído original adicionarmos um ruído independente de classe com a probabilidade pbr i.i.d, o ruído resultante por entrada será p ∗ = p (1 − pbr) + (1 − p) pbr. Para 0 < p,pbr< 1/2, o ruído real por rótulo p∗ é estritamente maior que o ruído adicionado artificialmente ao conjunto de dados pbr. Assim, o desempenho de nossos classificadores seria ainda melhor se eles fossem treinados primeiro com um conjunto de dados completamente sem ruído (p = 0). Assim, a existência de ruído residual no conjunto de dados real significa que a resiliência contra o ruído de nossos classificadores é melhor do que os resultados apresentados aqui. Além disso, se o ruído residual em nosso conjunto de dados fosse estatisticamente relevante, o AUC de nossos classificadores se tornaria 0,5 (uma estimativa aleatória) para um nível de ruído estritamente menor que 0,5. Não observamos esse comportamento em nossos resultados.
Nossa contribuição neste trabalho é dupla.
Primeiro, mostramos a viabilidade da classificação do relatório de bugs de segurança tendo como base apenas o título do relatório de bugs. Isso é especialmente relevante em cenários em que o relatório de bugs inteiro não está disponível devido às restrições de privacidade. Por exemplo, em nosso caso, os relatórios de bugs continham informações particulares, como senhas e chaves de criptografia, e não estavam disponíveis para treinar os classificadores. Nosso resultado mostra que a identificação de SBR pode ser executada com alta precisão mesmo quando apenas os títulos de relatório estiverem disponíveis. Nosso modelo de classificação que utiliza uma combinação de TF-IDF e regressão logística é executado em um AUC de 0,9831.
Em segundo lugar, analisamos o efeito de dados de validação e de treinamento rotulados de modo incorreto. Comparamos três técnicas de classificação de Machine Translation conhecidas (Naive Bayes, regressão logística e AdaBoost) em termos de robustez em relação a diferentes tipos e níveis de ruído. Todos os três classificadores são robustos para ruído de classe única. O ruído nos dados de treinamento não tem um efeito significativo no classificador resultante. A redução de AUC é muito pequena (0,01) para um nível de ruído de 50%. Para o ruído presente em ambas as classes e que seja independente de classe, os modelos de Naive Bayes e AdaBoost somente apresentam variações significativas no AUC quando treinados com um conjunto de dados com níveis de ruído acima de 40%.
Por fim, o ruído dependente de classe afeta significativamente o AUC apenas quando há mais de 35% de ruído em ambas as classes. O AdaBoost apresentou mais robustez. O impacto em AUC é muito pequeno mesmo quando a classe positiva tem 50% de seus rótulos com ruído, desde que a classe negativa contenha 45% de rótulos com ruído ou menos. Nesse caso, a queda de AUC é menor que 0,03. Pelo que sabemos, este é o primeiro estudo sistemático sobre o efeito de conjuntos de dados com ruído para identificação do relatório de bugs de segurança.
Neste documento, começamos o estudo sistemático dos efeitos de ruído no desempenho de classificadores de Machine Learning para a identificação de bugs de segurança. Há várias continuações interessantes deste trabalho, entre eles o exame do efeito de conjuntos de dados com ruído na determinação do nível de gravidade de um bug de segurança, a compreensão do efeito do desequilíbrio de classe na resiliência dos modelos treinados em relação ao ruído e também o entendimento do efeito do ruído introduzido no conjunto de dados.
[1] John Anvik, Lyndon Hiew e Gail C Murphy. Quem deve corrigir este bug? Nas atividades da 28ª conferência internacional sobre engenharia de software, páginas 361 – 370. ACM, 2006.
[2] Diksha Behl, Sahil Handa e Anuja Arora. Uma ferramenta de mineração de bugs para identificar e analisar bugs de segurança usando naive bayes e tf-idf. Em Otimização, confiabilidade e tecnologia da informação (ICROIT), 2014 conferência internacional, páginas 294 – 299. IEEE, 2014.
[3] Nicolas Bettenburg, Rahul Premraj, Thomas Zimmermann e Sunghun Kim. Relatórios de bugs duplicados são considerados prejudiciais? Em Manutenção de Software, 2008. ICSM 2008. Conferência internacional IEEE em, páginas 337–345. IEEE, 2008.
[4] Andres Folleco, Taghi M Khoshgoftaar, Jason Van Hulse e Lofton Bullard. Identificação de aprendizes robustos para dados de baixa qualidade. Em Reutilização e Integração da Informação, 2008. IRI 2008. Conferência Internacional IEEE em, páginas 190–195. IEEE, 2008.
[5] Benoˆıt Frenay.´ Incerteza e ruído de rótulo no aprendizado de máquina. Tese de PhD, Universidade Católica de Louvain, Louvain-la-Neuve, Bélgica, 2013.
[6] Benoˆıt Frenay e Michel Verleysen. Classificação na presença do ruído do rótuló: uma pesquisa. Transações da IEEE em redes neurais e sistemas de aprendizado, 25(5):845 – 869, 2014.
[7] Michael Gegick, Pete Rotella e Tao Xie. Identificação dos relatórios de bugs de segurança por mineração de texto: um estudo de caso industrial. Em Repositórios de software de mineração (MSR), 2010 7ª Conferência de trabalho da IEEE em, páginas 11 – 20. IEEE, 2010.
[8] Katerina Goseva-Popstojanova e Jacob Tyo. Identificação de relatórios de bugs relacionados à segurança por meio da mineração de texto usando classificação supervisionada e não supervisionada. Em Conferência internacional da IEEE de 2018 sobre qualidade de software, confiabilidade e segurança (QRS), páginas 344 – 355, 2018.
[9] Ahmed Lamkanfi, Serge Demeyer, Emanuel Giger e Bart Goethals. Previsão da gravidade de um bug relatado. Em Repositórios de software de mineração (MSR), 2010 7ª Conferência de trabalho da IEEE em, páginas de 1 – 10. IEEE, 2010.
[10] Naresh Manwani e PS Sastry. Tolerância a ruídos sob redução de risco. Transações da IEEE em cibernética, 43(3):1146 – 1151, 2013.
[11] G Murphy e D Cubranic. Triagem de bug automático usando a categorização de texto. Em Atividades da 16ª conferência internacional sobre engenharia de software e engenharia de conhecimento. Citeseer, 2004.
[12] Mykola Pechenizkiy, Alexey Tsymbal, Seppo Puuronen e Oleksandr Pechenizkiy. Ruído de classe e aprendizagem supervisionada em domínios médicos: o efeito da extração de recursos. Em nulo, páginas 708–713. IEEE, 2006.
[13] Charlotte Pelletier, Silvia Valero, Jordi Inglada, Nicolas Champion, Claire Marais Sicre e Gerard Dedieu. Efeito do ruído do rótulo da classe de treinamento sobre o desempenho da classificação para o mapeamento de superfícies terrestres com a série temporal de imagens de satélite. Leitura remota, 9(2):173, 2017.
[14] PS Sastry, GD Nagendra e Naresh Manwani. Uma equipe de automação de aprendizado contínuo para aprendizado tolerante a ruído de meio-espaço. Transações da IEEE para sistemas, homem e cibernética, parte B (cibernética), 40 (1): 19 – 28, 2010.
[15] Choh-Man Teng. Uma comparação de técnicas de tratamento de ruído. Em Conferência FLAIRS, páginas 269 – 273, 2001.
[16] Dumidu Wijayasekara, Milos Manic e Miles McQueen. Identificação e classificação de vulnerabilidade por meio de bancos de dados de bugs de mineração de texto. Em Industrial Electronics Society, IECON 2014-40th Annual Conference of the IEEE (Industrial Electronics Society, IECON 2014-40ª conferência anual do IEEE, em tradução livre), páginas 3612–3618. IEEE, 2014.
[17] Xinli Yang, David Lo, Qiao Huang, Xin Xia e Jianling Sun. Identificação automatizada de relatórios de bugs de alto impacto aproveitando estratégias de aprendizado em desequilíbrio. Em Conferência de software de computador e aplicações (COMPSAC), 40ª anual da IEEE de 2016, volume 1, páginas 227 – 232. IEEE, 2016.
[18] Deqing Zou, Zhijun Deng, Zhen Li e Hai Jin. Identificação automática de relatórios de bugs de segurança por meio da análise de recursos de vários tipos. Em Conferência Australasiática sobre segurança de informações e privacidade, páginas 619 – 633. Springer, 2018.