Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Aplica-se a:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Important
Os Clusters de Big Data do Microsoft SQL Server 2019 foram desativados. O suporte para clusters de Big Data do SQL Server 2019 terminou em 28 de fevereiro de 2025. Para obter mais informações, consulte a postagem no blog de anúncios e as opções de Big Data na plataforma microsoft SQL Server.
A implantação de aplicativos permite que esse tipo de implantação ocorra nos Clusters de Big Data do SQL Server, fornecendo interfaces para criar, gerenciar e executar aplicativos. Os aplicativos implantados no Cluster de Big Data se beneficiam do poder computacional do cluster e podem acessar os dados disponíveis nele. Isso aumenta a escalabilidade e o desempenho dos aplicativos, ao mesmo tempo que gerencia os aplicativos nos quais os dados residem. Os runtimes do aplicativo compatíveis com os Clusters de Big Data do SQL Server são o R, o Python, o dtexec e o MLeap.
As seções a seguir descrevem a arquitetura e a funcionalidade da implantação de aplicativos.
Arquitetura da implantação de aplicativos
A implantação de aplicativos consiste em um controlador e manipuladores de runtime de aplicativo. Ao criar um aplicativo, um arquivo de especificação (spec.yaml) é fornecido. Esse arquivo spec.yaml contém tudo o que o controlador precisa saber para implantar o aplicativo com êxito. Este é um exemplo de conteúdo para spec.yaml:
#spec.yaml
name: add-app #name of your python script
version: v1 #version of the app
runtime: Python #the language this app uses (R or Python)
src: ./add.py #full path to the location of the app
entrypoint: add #the function that will be called upon execution
replicas: 1 #number of replicas needed
poolsize: 1 #the pool size that you need your app to scale
inputs: #input parameters that the app expects and the type
x: int
y: int
output: #output parameter the app expects and the type
result: int
O controlador inspeciona o runtime especificado no arquivo spec.yaml e chama o manipulador de runtime correspondente. O manipulador de runtime cria o aplicativo. Primeiro, um ReplicaSet do Kubernetes é criado contendo um ou mais pods, cada um contendo o aplicativo a ser implantado. O número de pods é definido pelo parâmetro replicas definido no arquivo spec.yaml do aplicativo. Cada pod pode ter um ou mais pools. O número de pools é definido pelo parâmetro poolsize definido no arquivo spec.yaml.
Essas configurações determinam a quantidade de solicitações que a implantação pode lidar em paralelo. O número máximo de solicitações em determinado momento é igual a replicas vezes poolsize. Se você tiver cinco réplicas e dois pools por réplica, a implantação poderá manipular dez solicitações em paralelo. Confira a imagem abaixo para obter uma representação gráfica de replicas e poolsize:
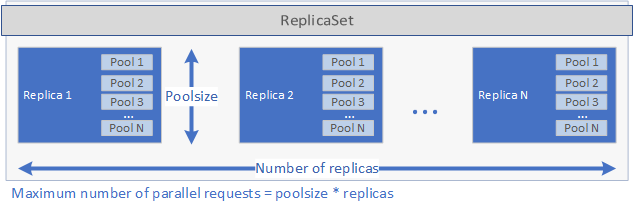
Depois que o ReplicaSet for criado e os pods forem iniciados, um trabalho do Cron será criado se um schedule tiver sido definido no arquivo spec.yaml. Por fim, um serviço de Kubernetes é criado e pode ser usado para gerenciar e executar o aplicativo (veja abaixo).
Quando um aplicativo é executado, o Serviço de Kubernetes do aplicativo executa as solicitações como proxy para uma réplica e retorna os resultados.
Considerações de segurança para implantações de aplicativos no OpenShift
O SQL Server 2019 CU5 habilita o suporte para a implantação de BDC no Red Hat OpenShift, e um modelo de segurança atualizado para o BDC, para que contêineres com privilégios não sejam mais necessários. Além de não privilegiados, os contêineres são executados como um usuário não raiz por padrão em todas as novas implantações usando o SQL Server 2019 CU5.
No momento do lançamento do CU5, a etapa de configuração dos aplicativos implantados com interfaces de implantação de aplicativo ainda será executada como usuário raiz. Isso é necessário porque, durante a instalação, são instalados pacotes extras que serão usados pelo aplicativo. Outro código de usuário implantado como parte do aplicativo será executado como usuário de baixo privilégio.
Além disso, a funcionalidade CAP_AUDIT_WRITE é uma funcionalidade opcional necessária para permitir o agendamento de aplicativos SSIS (SQL Server Integration Services) que usam trabalhos cron. Quando o arquivo de especificação YAML do aplicativo especifica um agendamento, o aplicativo será disparado por meio de um trabalho cron, que requer a funcionalidade extra. Como alternativa, o aplicativo pode ser disparado sob demanda com azdata app run por meio de uma chamada do serviço Web, que não requer a funcionalidade CAP_AUDIT_WRITE. Observe que a funcionalidade CAP_AUDIT_WRITE não é mais necessária para iniciar cronjob a partir da versão SQL Server 2019 CU8.
Note
O SCC personalizado no artigo de implantação do OpenShift não inclui essa funcionalidade pois ela não é exigida por uma implantação padrão do BDC. Para habilitar essa funcionalidade, você precisa primeiro atualizar o arquivo YAML do SCC personalizado para incluir CAP_AUDIT_WRITE.
...
allowedCapabilities:
- SETUID
- SETGID
- CHOWN
- SYS_PTRACE
- AUDIT_WRITE
...
Como trabalhar com a implantação de aplicativo dentro do Cluster de Big Data
As duas interfaces principais da implantação de aplicativos são:
-
Interface de Linha de Comando da CLI de Dados do Azure (
azdata) - Extensão do Azure Data Studio e Visual Studio Code
Também é possível executar um aplicativo usando um serviço Web RESTful. Para obter mais informações, confira Consumir aplicativos em Clusters de Big Data.
Cenários de implantação de aplicativos
A implantação de aplicativos permite que esse tipo de implantação ocorra no BDC do SQL Server, fornecendo interfaces para criar, gerenciar e executar aplicativos.
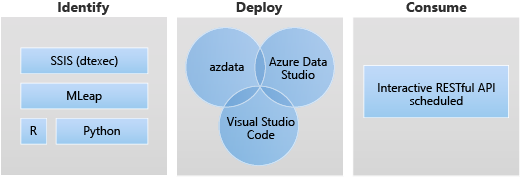
Estes são os seguintes cenários de destino para a implantação do aplicativo:
- Implantar os serviços Web do Python ou do R dentro do cluster de Big Data para lidar com vários casos de uso, como inferência de aprendizado de máquina, serviços de API etc.
- Criar um ponto de extremidade de inferência de aprendizado de máquina usando o mecanismo MLeap.
- Agendar e executar pacotes de arquivos do DTSX usando o utilitário dtexec para a transformação e a movimentação de dados.
Usar o runtime do Python para a implantação de aplicativos
Na implantação de aplicativos, o runtime de Python do Cluster de Big Data permite que o aplicativo Python dentro do cluster de Big Data resolva vários casos de uso, como inferência de aprendizado de máquina, serviços de API etc.
O runtime do Python de implantação de aplicativos usa o Python 3.8 nos Clusters de Big Data do SQL Server CU10 ou superiores.
Na implantação de aplicativos, spec.yaml é onde você fornece as informações que o controlador precisa saber para implantar o aplicativo. Os seguintes campos podem ser especificados:
-
name: nome do aplicativo -
version: versão do aplicativo, por exemplov1 -
runtime: runtime de implantação de aplicativos, deve ser especificado como:Python -
src: caminho para o aplicativo Python -
entry point: função de ponto de entrada no script src a ser executada para este aplicativo Python.
Além dos campos acima, você precisa especificar a entrada e a saída do seu aplicativo Python. Isso gera um arquivo spec.yaml semelhante ao seguinte:
#spec.yaml
name: add-app
version: v1
runtime: Python
src: ./add.py
entrypoint: add
replicas: 1
poolsize: 1
inputs:
x: int
y: int
output:
result: int
Você pode criar a pasta básica e a estrutura de arquivos que são necessárias para implantar um aplicativo Python em execução no cluster de Big Data:
azdata app init --template python --name hello-py --version v1
Para as próximas etapas, confira Como implantar um aplicativo nos Clusters de Big Data do SQL Server.
Limitações do runtime do Python para implantação de aplicativo
O runtime do Python para implantação de aplicativo não dá suporte ao cenário de agendamento. Depois que o aplicativo Python é implantado e executado no BDC, um ponto de extremidade RESTful é configurado para escutar as solicitações de entrada.
Usar o runtime do R de implantação de aplicativos
Na implantação de aplicativos, o runtime de Python do Cluster de Big Data permite que o aplicativo R dentro do cluster de Big Data resolva vários casos de uso, como inferência de aprendizado de máquina, serviços de API etc.
O runtime do R de implantação de aplicativos usa o (MRO) Microsoft R Open versão 3.5.2 nos Clusters de Big Data do SQL Server CU10 ou superiores.
Como usar
Na implantação de aplicativos, spec.yaml é onde você fornece as informações que o controlador precisa saber para implantar o aplicativo. Os seguintes campos podem ser especificados:
-
name: nome do aplicativo -
version: versão do aplicativo, por exemplov1 -
runtime: runtime de implantação de aplicativos, deve ser especificado como:R -
src: caminho para o aplicativo R -
entry point: ponto de entrada para executar o aplicativo R
Além dos campos acima, você precisa especificar a entrada e a saída do seu aplicativo R. Isso gera um arquivo spec.yaml semelhante ao seguinte:
#spec.yaml
name: roll-dice
version: v1
runtime: R
src: ./roll-dice.R
entrypoint: rollEm
replicas: 1
poolsize: 1
inputs:
x: integer
output:
result: data.fram
Você pode criar a pasta básica e a estrutura de arquivos que são necessárias para implantar um novo aplicativo R usando o seguinte comando:
azdata app init --template r --name hello-r --version v1
Para as próximas etapas, confira Como implantar um aplicativo nos Clusters de Big Data do SQL Server.
Limitações de runtime no R
Essas limitações dizem respeito ao Microsoft R Application Network, que foi desativado em 1.º de julho de 2023. Para obter mais informações e soluções alternativas, consulte Desativação do Microsoft R Application Network.
Utilizando o runtime do dtexec para implantação de aplicativos
Na implantação do aplicativo, o utilitário dtexec integrado do runtime do Cluster de Big Data é proveniente do SSIS no Linux (mssql-server-is). A implantação do aplicativo usa o utilitário dtexec para carregar pacotes de arquivos *.dtsx. Ele dá suporte à execução de pacotes do SSIS no agendamento de estilo cron ou sob demanda por meio de solicitações de serviço Web.
Esse recurso usa /opt/ssis/bin/dtexec /FILE do SQL Server Integration Services 2019 no Linux. Ele oferece suporte ao formato dtsx para o SQL Server Integration Services 2019 no Linux (mssql-server-is 15.0.2). Para saber mais sobre o utilitário dtexec, consulte Utilitário dtexec.
Na implantação de aplicativos, spec.yaml é onde você fornece as informações que o controlador precisa saber para implantar o aplicativo. Os seguintes campos podem ser especificados:
name:namedo aplicativoversion: versão do aplicativo, por exemplov1runtime: runtime de implantação de aplicativos, você precisa especificá-lo comoSSISpara executar o utilitário dtexec.entrypoint: um ponto de entrada, geralmente é o arquivo. dtsx em nosso caso.options: opções adicionais para/opt/ssis/bin/dtexec /FILE, por exemplo, para se conectar a um banco de dados com uma cadeia de conexão, ele seguiria o seguinte padrão:/REP V /CONN "sqldatabasename"\;"\"Data Source=xx;User ID=xx;Password=<password>\""Para obter detalhes sobre a sintaxe, consulte Utilitário dtexec.
schedule: frequência com que o trabalho precisa ser executado, por exemplo, ao usar expressão cron para especificar esse valor, especificar como "*/1 * * * *", o que significa que o trabalho está sendo executado em intervalos de minutos.
Você pode criar a pasta básica e a estrutura de arquivos que são necessárias para implantar um novo aplicativo SSIS usando o seguinte comando:
azdata app init --name hello-is –version v1 --template ssis
Isso gera um arquivo spec.yaml para o seguinte:
#spec.yaml
entrypoint: ./hello.dtsx
name: hello-is
options: /REP V
poolsize: 2
replicas: 2
runtime: SSIS
schedule: '*/2 * * * *'
version: v1
O exemplo também cria um pacote hello.dtsx de exemplo.
Todos os arquivos do aplicativo estão no mesmo diretório que o spec.yaml. O spec.yaml deve estar no nível raiz do diretório do código-fonte do aplicativo, incluindo o arquivo dtsx.
Para as próximas etapas, confira Como implantar um aplicativo nos Clusters de Big Data do SQL Server.
Limitações do runtime do utilitário dtexec
Todas as limitações e problemas conhecidos do SSIS (SQL Server Integration Services) no Linux são aplicáveis em Clusters de Big Data do SQL Server. Para saber mais, leia Limitações e problemas conhecidos do SSIS no Linux.
Como usar o runtime do MLeap para implantação de aplicativos
O runtime do MLeap de implantação de aplicativos dá suporte ao MLeap servindo v 0.13.0.
Na implantação de aplicativos, spec.yaml é onde você fornece as informações que o controlador precisa saber para implantar o aplicativo. Os seguintes campos podem ser especificados:
-
name: nome do aplicativo -
version: versão do aplicativo, por exemplov1 -
runtime: runtime de implantação de aplicativos, deve ser especificado como:Mleap
Além dos campos acima, você precisa especificar o bundleFileName do seu aplicativo MLeap. Isso gera um arquivo spec.yaml semelhante ao seguinte:
#spec.yaml
name: mleap-census
version: v1
runtime: Mleap
bundleFileName: census-bundle.zip
replicas: 1
Você pode criar a pasta básica e a estrutura de arquivos que são necessárias para implantar um novo aplicativo MLeap usando o seguinte comando:
azdata app init --template mleap --name hello-mleap --version v1
Para as próximas etapas, confira Como implantar um aplicativo nos Clusters de Big Data do SQL Server.
Limitações do runtime do MLeap
As limitações se alinham com a visão do projeto open-source do MLeap do Combust no GitHub.
Next steps
Para saber mais sobre como criar e executar aplicativos em Clusters de Big Data do SQL Server, confira o seguinte:
- Implantar aplicativos usando o azdata
- Implantar aplicativos usando a extensão de implantação de aplicativos
- Consumir aplicativos em Clusters de Big Data
Para saber mais sobre o Clusters de Big Data do SQL Server, confira a visão geral a seguir: