Recursos implantados com Clusters de Big Data do SQL Server
Aplica-se a: ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Importante
O complemento Clusters de Big Data do Microsoft SQL Server 2019 será desativado. O suporte para Clusters de Big Data do SQL Server 2019 será encerrado em 28 de fevereiro de 2025. Todos os usuários existentes do SQL Server 2019 com Software Assurance terão suporte total na plataforma e o software continuará a ser mantido por meio de atualizações cumulativas do SQL Server até esse momento. Para obter mais informações, confira a postagem no blog de anúncio e as opções de Big Data na plataforma do Microsoft SQL Server.
Este artigo descreve os recursos que o cluster de Big Data do SQL Server implanta.
Um Cluster de Big Data implanta pods com base no perfil de implantação. Para saber detalhes, veja Configurações padrão.
Este artigo descreve os pods implantados com o perfil aks-dev-test-ha e inclui um pool do Spark. Consulte o Kubernetes para ver os pods implantados no cluster. O exemplo a seguir retorna uma lista de pods em um namespace específico.
kubectl get pods -n <namespace>
Substitua <namespace> pelo nome do cluster de Big Data.
Para obter mais informações, confira Como implantar Clusters de Big Data do SQL Server no Kubernetes.
O diagrama a seguir mostra os componentes implantados em um cluster de Big Data:
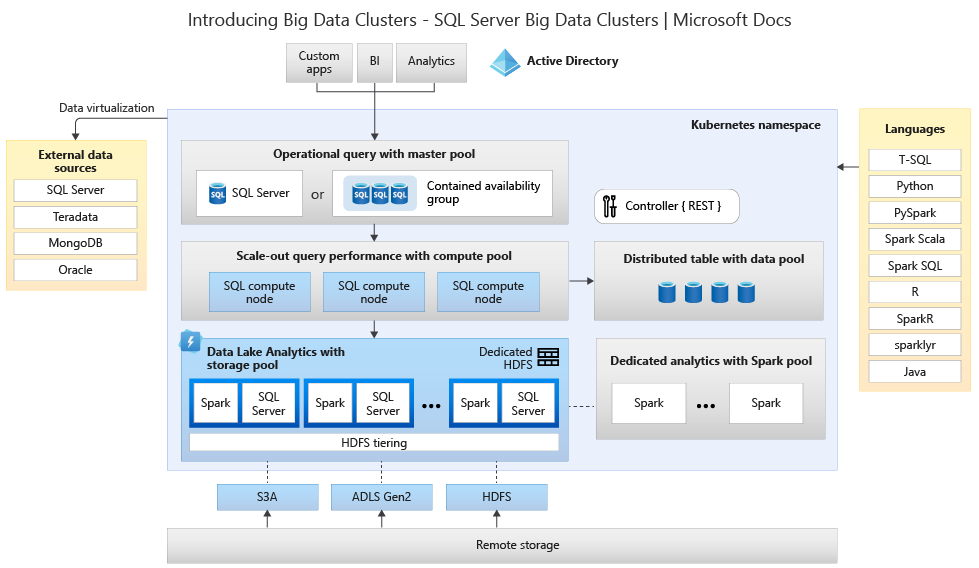
Para saber mais sobre a arquitetura, confira Introdução a Clusters de Big Data do SQL Server.
Pods implantados
A tabela a seguir lista os pods implantados em um cluster de Big Data.
| Nome | Área |
|---|---|
control-<nnnn> |
Controle |
controldb-<#> |
Controle |
controlwd-<nnnn> |
Controle |
logsdb-<#> |
Controle |
logsui-<nnnn> |
Controle |
metricsdb-<#> |
Controle |
metricsdc-<nnnn> |
Controle |
metricsui-<nnnn> |
Controle |
mgmtproxy-<nnnn> |
Controle |
zookeeper-<#> |
Controle |
dns-<nnnn> |
Controle |
master-<#n> |
Instância mestra |
operator-<nnnn> |
Instância mestra |
compute-<#n>-<#m> |
Pool de computação |
data-<#>-<#> |
Pool de dados |
storage-<#>-<#> |
Pool de armazenamento |
nmnode-<#>-<#> |
Pool de armazenamento |
sparkhead-<#> |
Pool de armazenamento |
appproxy-<#m> |
Pool de aplicativos |
gateway-<#> |
Serviço do gateway |
Nem todos os pods estão incluídos em todos os Clusters de Big Datas. As implantações com alta disponibilidade ou integração de diretórios ativas incluem pods específicos.
Pods específicos de alta disponibilidade:
operator-<nnnn>zookeeper-<#>
Pods específicos do Active Directory:
dns-<nnnn>
As seções a seguir descrevem os pods e listam os contêineres em cada pod.
Control
Os pods de controle fornecem o serviço de controle.
| Nome do pod | Contagem | Tipo de controlador do Kubernetes | Contêineres |
|---|---|---|---|
control-# |
1 | ReplicaSet | - controller- security-support- fluentbit |
controldb |
1 | StatefulSet | - mssql-server- fluentbit |
controlwd |
1 | ReplicaSet | - controlwatchdog |
logsdb-# |
1 | StatefulSet | - elasticsearch |
logsui |
1 | ReplicaSet | - kibana |
metricsdb-# |
1 | StatefulSet | - influxdb |
metricsdc |
1 por nó do Kubernetes. | DaemonSet | - telegraf |
metricsui-nnnn |
1 | ReplicaSet | - grafana |
mgmtproxy-nnnn |
1 | ReplicaSet | - service-proxy- fluentbit |
dns-nnnn |
0 ou 1 para a integração do Active Directory | ReplicaSet | - dns- fluentbit |
Instância principal
master-<#n> é a instância mestra do SQL Server.
- Gerencia o pool de dados via DDL
- Manipula dados no pool de dados por meio de DML
- Descarrega a execução de consulta analítica no pool de dados
| Nome do pod | Contagem | Tipo de controlador do Kubernetes | Contêineres |
|---|---|---|---|
master-<#n> |
1 ou mais para alta disponibilidade. | StatefulSet | - mssql-server- fluentbit- collectd- mssql-ha-supervisor * |
operator* |
0 ou 1 para alta disponibilidade | ReplicaSet | - mssql-ha-operator |
* Somente implantações de alta disponibilidade. O operador implementa e registra a definição do recurso personalizado para o SQL Server e os recursos do Grupo de Disponibilidade. Quando o operador é implantado, registra-se como ouvinte de notificações sobre os recursos do SQL Server sendo implantados no cluster do Kubernetes. mssql-ha-supervisor é compatível com o grupo de disponibilidade.
Cada pod master contém uma instância do SQL Server. Uma implantação de alta disponibilidade inclui três pods. Cada pod tem uma instância do SQL Server com bancos de dados em um Grupos de Disponibilidade Always On do SQL Server.
Inclua mais pods no tempo de implantação, de acordo com sua carga de trabalho.
Pool de computação
O pool de computação fornece uma instância do SQL Server para computação.
| Nome do pod | Contagem | Tipo de controlador do Kubernetes | Contêineres |
|---|---|---|---|
compute-<#n>-<#m> |
1 ou mais. | StatefulSet | - mssql-server- fluentbit- collectd |
#nidentifica o pool de computação.#midentifica a ID da instância no pool.
As instâncias do SQL Server para o pool de computação são sem estado. Eles só precisam de armazenamento para tempdb.
Inclua mais pods no tempo de implantação, de acordo com sua carga de trabalho.
Pool de dados
O pool de dados fornece instâncias do SQL Server para armazenamento e computação.
| Nome do pod | Contagem | Tipo de controlador do Kubernetes | Contêineres |
|---|---|---|---|
data-<#n>-<#m> |
0 ou mais | StatefulSet | - mssql-server - fluentbit- collectd |
#nidentifica o pool de dados.#midentifica a ID da instância no pool.
Inclua mais pods no tempo de implantação, de acordo com a carga de trabalho.
Pool de armazenamento
O pool de armazenamento fornece ingestão de dados por meio do Spark, armazenamento no HDFS, acesso a dados por meio do HDFS e pontos de extremidade do SQL Server.
| Nome do pod | Contagem | Tipo de controlador do Kubernetes | Contêineres |
|---|---|---|---|
storage-0-# |
1 ou mais. Inclua mais pods no tempo de implantação, de acordo com a carga de trabalho. | StatefulSet | - hadoop- mssql-server- fluentbit |
nmnode-0-# |
1 ou mais para alta disponibilidade | StatefulSet | - hadoop- fluentbit |
sparkehead-# |
1 ou mais para alta disponibilidade | StatefulSet | - hadoop-yarn-jobhistory- hadoop-livy-sparkhistory- hadoop-hivemetastore-- fluentbit |
zookeeper |
0 ou 3 para alta disponibilidade. | StatefulSet | - zookeeper- fluentbit |
Pool de aplicativos
O pool de aplicativos está incluído em alguns dos perfis de configuração de teste. O pool de aplicativos hospeda proxies de serviço de aplicativo que você define ao implantar aplicativos em clusters de Big Data.
appproxy é uma API Web que fica na frente dos aplicativos do pool de aplicativos. Ela autentica os usuários e, em seguida, roteia as solicitações até os aplicativos.
| Nome do pod | Tipo de controlador do Kubernetes | Contêineres |
|---|---|---|
appproxy |
ReplicaSet | - app-service-proxy- fluentbit |
Para saber mais, confira Introdução à Implantação de Aplicativos em um Cluster de Big Data.
Inclua mais pods no tempo de implantação, de acordo com a carga de trabalho.
Serviço do gateway
Os serviços de gateway fornecem o gateway do Knox para Spark, o HDFS, o Yarn, a interface do usuário do Yarn e a interface do usuário do Spark.
| Nome do pod | Tipo de controlador do Kubernetes | Contêineres |
|---|---|---|
gateway-<#> |
StatefulSet | - knox- fluentbit |
Somente um gateway é compatível.
Referências de contêiner open-source
Para projetos específicos de software livre e versões, confira Referência de software livre.
Próximas etapas
Para saber mais sobre o Clusters de Big Data do SQL Server, confira os seguintes recursos: