Introdução ao pool de armazenamento em Clusters de Big Data do SQL Server
Aplica-se a: ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Este artigo descreve a função do pool de armazenamento do SQL Server em um cluster de Big Data do SQL Server. As seções a seguir descrevem a arquitetura e a funcionalidade de um pool de armazenamento.
Importante
O complemento Clusters de Big Data do Microsoft SQL Server 2019 será desativado. O suporte para Clusters de Big Data do SQL Server 2019 será encerrado em 28 de fevereiro de 2025. Todos os usuários existentes do SQL Server 2019 com Software Assurance terão suporte total na plataforma e o software continuará a ser mantido por meio de atualizações cumulativas do SQL Server até esse momento. Para obter mais informações, confira a postagem no blog de anúncio e as opções de Big Data na plataforma do Microsoft SQL Server.
Arquitetura do pool de armazenamento
O pool de armazenamento é o cluster do HDFS local (Hadoop) em um cluster de Big Data do SQL Server. Ele fornece armazenamento persistente para dados não estruturados e semiestruturados. Arquivos de dados, como Parquet ou texto delimitado, podem ser armazenados no pool de armazenamento. Para persistir o armazenamento, cada pod no pool tem um volume persistente anexado a ele. Os arquivos do pool de armazenamento podem ser acessados via o PolyBase por meio do SQL Server ou diretamente usando um Gateway do Apache Knox.
Uma configuração do HDFS clássico consiste em um conjunto de computadores de hardware de mercadoria com armazenamento anexado. Os dados são distribuídos em blocos em todos os nós para fins de tolerância a falhas e aproveitamento do processamento paralelo. Um dos nós no cluster funciona como o nó de nome e contém as informações de metadados sobre os arquivos localizados nos nós de dados.
O pool de armazenamento consiste em nós de armazenamento que são membros de um cluster HDFS. Ele executa um ou mais pods do Kubernetes e cada pod hospeda os seguintes contêineres:
- Um contêiner Hadoop vinculado a um volume persistente (armazenamento). Todos os contêineres desse tipo juntos formam o cluster Hadoop. No contêiner Hadoop, há um processo do gerenciador de nós do YARN que pode criar processos de trabalho do Apache Spark sob demanda. O nó de cabeçalho do Spark hospeda o metastore do hive, o histórico do Spark e os contêineres do histórico de trabalhos do YARN.
- Uma instância do SQL Server para ler dados do HDFS usando a tecnologia OpenRowSet.
collectdpara coletar dados de métricas.fluentbitpara coletar dados de log.
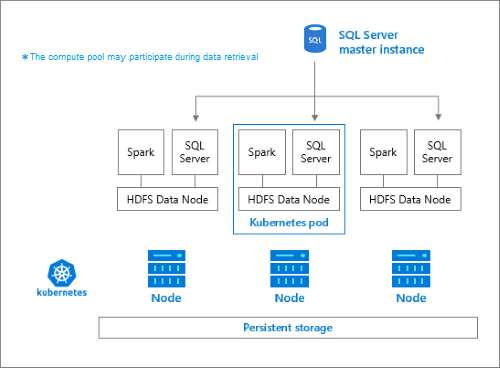
Responsabilidades
Os nós de armazenamento são responsáveis por:
- Ingestão de dados por meio do Apache Spark.
- Armazenamento de dados no HDFS (Parquet e formato de texto delimitado). O HDFS também fornece persistência de dados, pois os dados do HDFS são distribuídos em todos os nós de armazenamento no cluster no BDC do SQL.
- Acesso a dados por meio dos pontos de extremidade do HDFS e do SQL Server.
Accessing data
Os principais métodos para acessar os dados no pool de armazenamento são:
- Trabalhos do Spark.
- Utilização de tabelas externas do SQL Server para permitir a consulta de dados usando nós de computação do PolyBase e as instâncias de SQL Server em execução nos nós do HDFS.
Você também pode interagir com o HDFS usando:
- Azure Data Studio.
- CLI de Dados do Azure (
azdata). - O kubectl para emitir comandos para o contêiner Hadoop.
- Gateway de HTTP do HDFS.
Próximas etapas
Para saber mais sobre o Clusters de Big Data do SQL Server, confira os seguintes recursos:
Comentários
Em breve: Ao longo de 2024, eliminaremos os problemas do GitHub como o mecanismo de comentários para conteúdo e o substituiremos por um novo sistema de comentários. Para obter mais informações, consulte https://aka.ms/ContentUserFeedback.
Enviar e exibir comentários de