Virtualizar dados CSV do pool de armazenamento (Clusters de Big Data)
Importante
O complemento Clusters de Big Data do Microsoft SQL Server 2019 será desativado. O suporte para Clusters de Big Data do SQL Server 2019 será encerrado em 28 de fevereiro de 2025. Todos os usuários existentes do SQL Server 2019 com Software Assurance terão suporte total na plataforma e o software continuará a ser mantido por meio de atualizações cumulativas do SQL Server até esse momento. Para obter mais informações, confira a postagem no blog de anúncio e as opções de Big Data na plataforma do Microsoft SQL Server.
Os Clusters de Big Data do SQL Server podem virtualizar dados de arquivos CSV no HDFS. Esse processo permite que os dados permaneçam em seu local original, mas possam ser consultados de uma instância do SQL Server como qualquer outra tabela. Esse recurso usa conectores do PolyBase e minimiza a necessidade de processos de ETL. Para saber mais sobre virtualização de dados, confira Introdução à virtualização de dados com o PolyBase
Pré-requisitos
Selecionar ou carregar um arquivo CSV para virtualização de dados
No ADS (Azure Data Studio), conecte-se à instância mestra do SQL Server do Cluster de Big Data. Uma vez conectado, expanda os elementos do HDFS no Pesquisador de Objetos para localizar os arquivos CSV cujos dados gostaria de virtualizar.
Para os fins deste tutorial, crie um diretório chamado Dados.
- Clique com o botão direito do mouse no menu de contexto do diretório raiz do HDFS.
- Selecione Novo diretório.
- Dê ao novo diretório o nome Dados.
Carregar os dados de exemplo. Para um passo a passo simples, use um arquivo de dados CSV de exemplo. Este artigo usa os dados de causas de atrasos de companhias aéreas do Departamento de Transporte dos EUA. Baixe os dados brutos e extraia-os no computador. Nomeie o arquivo airline_delay_causes. csv.
Para carregar o arquivo de exemplo após extraí-lo:
- No Azure Data Studio, clique com o botão direito do mouse no novo diretório criado.
- Selecione Carregar arquivos.
O Azure Data Studio carrega os arquivos no HDFS no Cluster de Big Data.
Criar a fonte de dados externa do pool de armazenamento no banco de dados de destino
A fonte de dados externa do pool de armazenamento não é criada em um banco de dados por padrão no Cluster de Big Data. Antes de criar a tabela externa, crie a fonte de dados externa SqlStoragePool padrão no banco de dados de destino com a consulta Transact-SQL a seguir. Primeiro, altere o contexto da consulta para o banco de dados de destino.
-- Create the default storage pool source for SQL Big Data Cluster
IF NOT EXISTS(SELECT * FROM sys.external_data_sources WHERE name = 'SqlStoragePool')
CREATE EXTERNAL DATA SOURCE SqlStoragePool
WITH (LOCATION = 'sqlhdfs://controller-svc/default');
Criar a tabela externa
No ADS, clique com o botão direito do mouse no arquivo CSV e selecione Criar Tabela Externa do Arquivo CSV no menu de contexto. Você também poderá criar tabelas externas de arquivos CSV de um diretório no HDFS se os arquivos no diretório seguirem o mesmo esquema. Isso permitirá a virtualização dos dados em um nível de diretório sem necessidade de processar arquivos individuais e obter um conjunto de resultados unido sobre os dados combinados. O Azure Data Studio orienta você nas etapas para criar a tabela externa.
Especifique o banco de dados, a fonte de dados, um nome de tabela, o esquema e o nome do formato de arquivo externo da tabela.
Selecione Avançar.
Visualizar Dados
O Azure Data Studio fornece uma visualização dos dados importados.
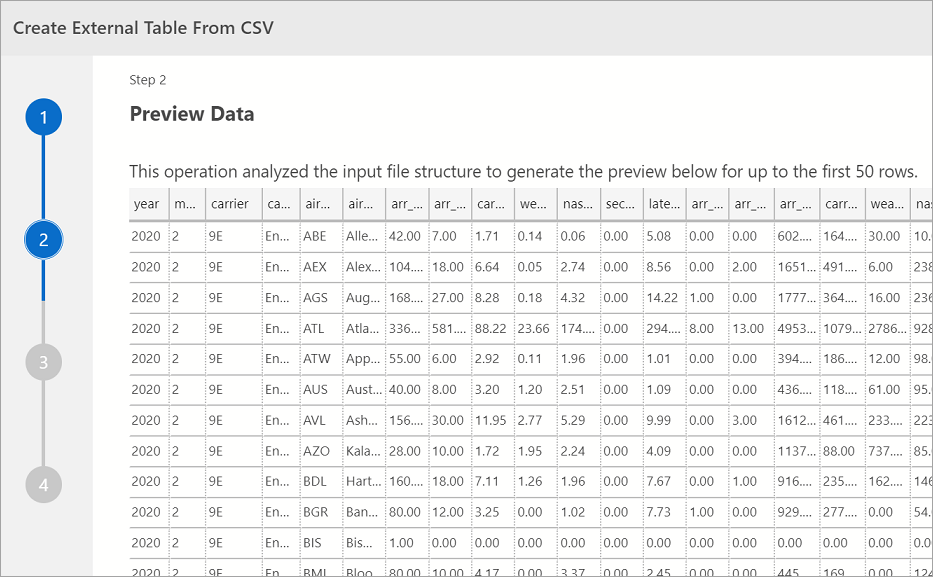
Quando terminar a pré-visualização, selecione Avançar para continuar
Modificar Colunas
Na próxima janela, você poderá modificar as colunas da tabela externa que pretende criar. É possível alterar o nome da coluna, alterar o tipo de dados e permitir linhas anuláveis.
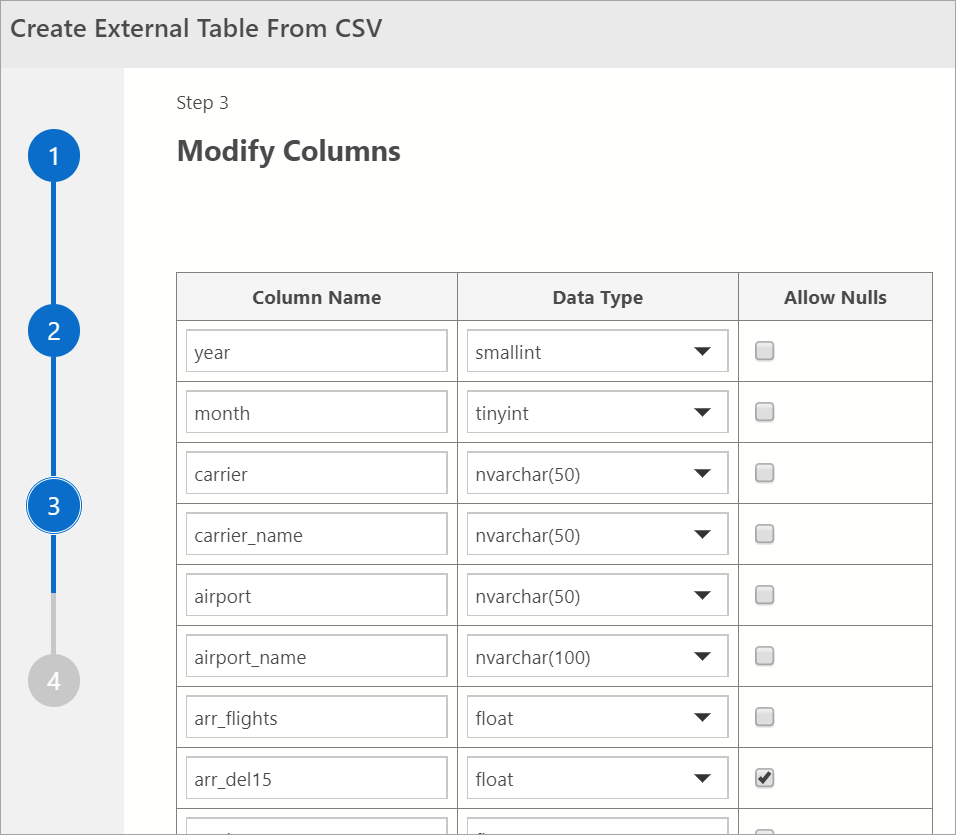
Depois de verificar as colunas de destino, selecione Avançar.
Resumo
Essa etapa fornece um resumo das suas seleções. Ela fornece o nome do SQL Server, o nome do banco de dados, o nome da tabela, o esquema da tabela e as informações da tabela externa. Nesta etapa, você tem a opção de gerar um script ou criar uma tabela. Gerar Script cria um script no T-SQL para criar a fonte de dados externa. Criar Tabela cria a fonte de dados externa.
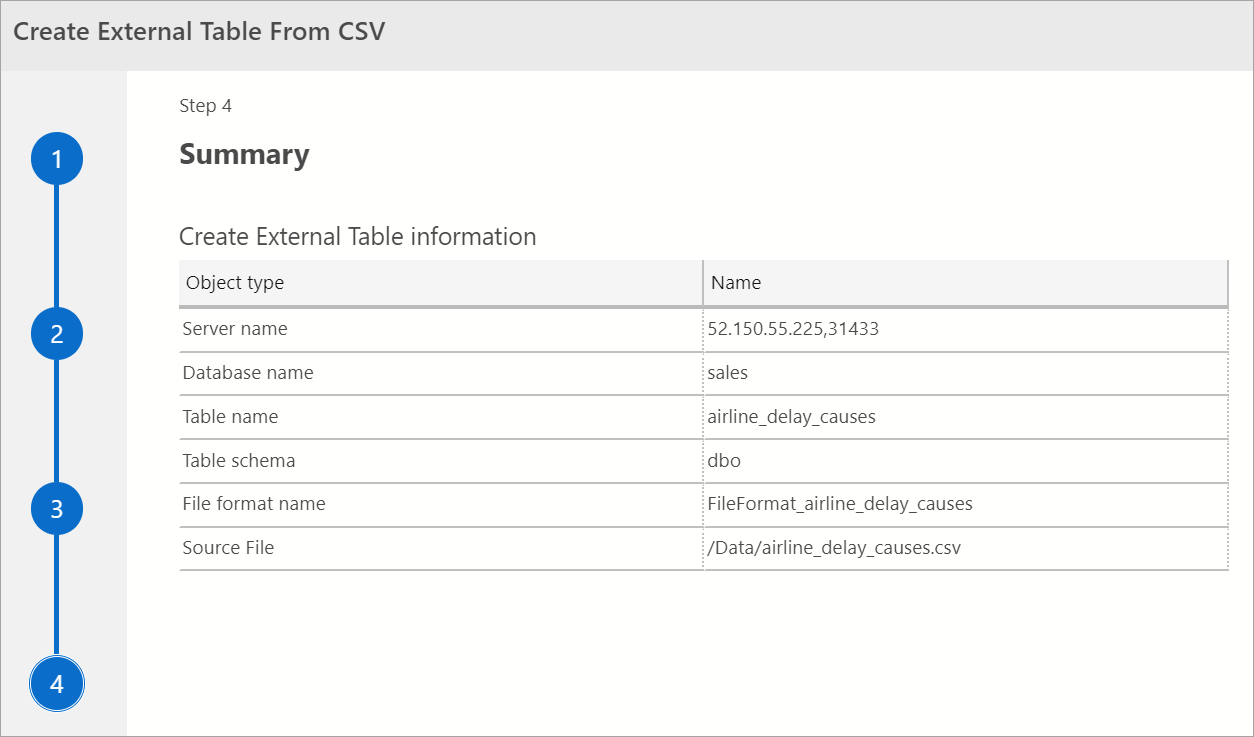
Se você selecionar Criar Tabela, o SQL Server criará a tabela externa no banco de dados de destino.
Se você selecionar Gerar Script, o Azure Data Studio criará a consulta T-SQL para criar a tabela externa.
Depois de criada, a tabela pode ser consultada diretamente usando o T-SQL na instância do SQL Server.
Próximas etapas
Para saber mais sobre o Cluster de Big Data do SQL Server e os cenários relacionados, confira Introdução a Clusters de Big Data do SQL Server.