Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Aplica-se a:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Important
Os Clusters de Big Data do Microsoft SQL Server 2019 foram desativados. O suporte para clusters de Big Data do SQL Server 2019 terminou em 28 de fevereiro de 2025. Para obter mais informações, consulte a postagem no blog de anúncios e as opções de Big Data na plataforma microsoft SQL Server.
O SQL Server fornece uma extensão para o Azure Data Studio que inclui notebooks de implantação. Um notebook de implantação inclui documentação e código que você pode usar no Azure Data Studio para criar um cluster de Big Data do SQL Server.
Implementados inicialmente como um projeto de software livre, os notebooks foram implementados no Azure Data Studio. Você pode usar markdown de texto nas células de texto e um dos kernels disponíveis para escrever código nas células de código.
Você pode usar notebooks para implantar o Clusters de Big Data do SQL Server.
Prerequisites
Os pré-requisitos a seguir são necessários para também iniciar o notebook:
- Versão mais recente do build do Azure Data Studio Insiders instalada
Além disso, a implantação do cluster de Big Data também requer:
Iniciar o notebook
Iniciar o Azure Data Studio.
Na guia Conexões, selecione as reticências ( ... ) e, em seguida, selecione Implantar SQL Server... .
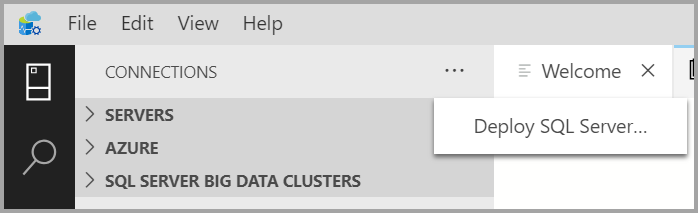
Nas opções de implantação, selecione Cluster de Big Data do SQL Server.
No Destino da Implantação, em Opções, selecione Novo cluster do Kubernetes do Azure ou Cluster existente do Serviço de Kubernetes do Azure.
Aceite os termos de licença e privacidade.
Essa caixa de diálogo também verifica se as ferramentas necessárias para o tipo de implantação do SQL escolhido existem no host. O botão Selecionar não estará habilitado até que a verificação de ferramentas seja bem-sucedida.
Selecione o botão Selecionar . Essa ação inicia a experiência de implantação.
Definir modelo de configuração de implantação
Você pode personalizar as configurações do perfil de implantação seguindo as instruções abaixo.
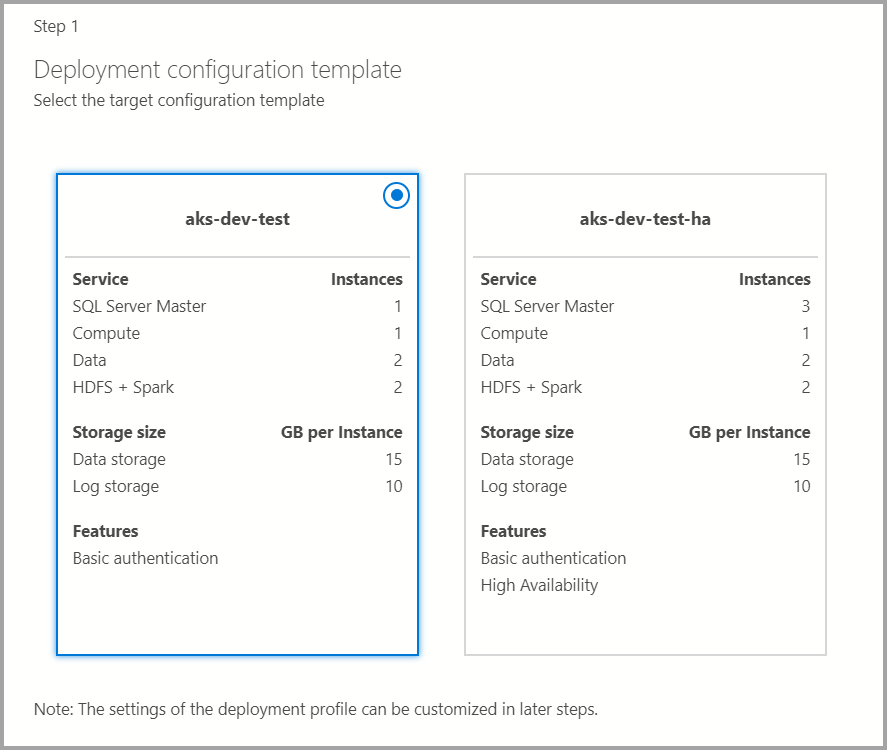
Modelo de configuração de destino
Selecione o modelo de configuração de destino entre os modelos disponíveis. Os perfis disponíveis são filtrados dependendo do tipo de destino de implantação escolhido na caixa de diálogo anterior.
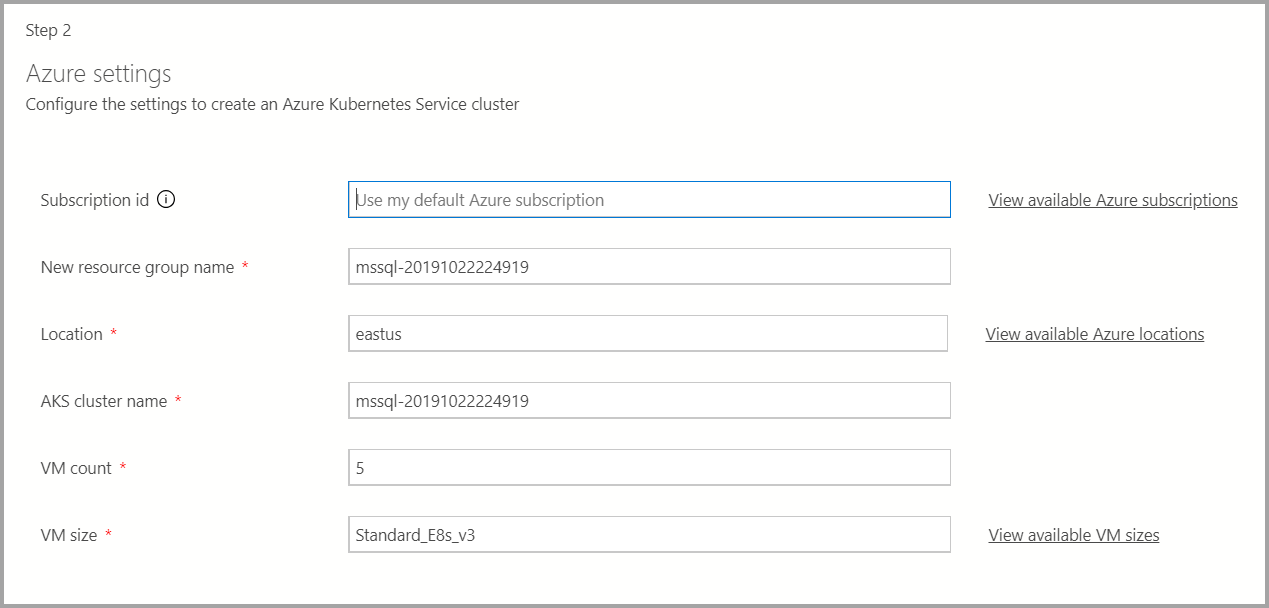
Azure settings
Se o destino de implantação for um novo AKS (Azure Kubernetes Service), informações adicionais, como a ID de Assinatura do Azure, grupo de recursos, nome do cluster do AKS, contagem de VMs, tamanho e outras informações adicionais, serão necessárias para criar o cluster do AKS.
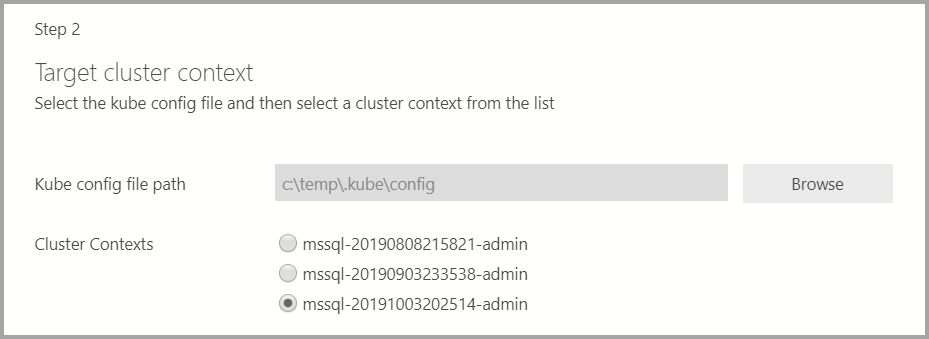
Se o destino de implantação for um cluster Kubernetes existente, o assistente solicitará o caminho para o arquivo de configuração de kube para importar as configurações do cluster do Kubernetes. Verifique se o contexto do cluster apropriado está selecionado em um local em que o cluster de Big Data do SQL Server 2019 possa ser implantado.
Configurações de cluster, Docker e AD
Insira o nome do cluster para o cluster de Big Data, um nome de usuário administrador e uma senha. A mesma conta é usada para o controlador e o SQL Server.
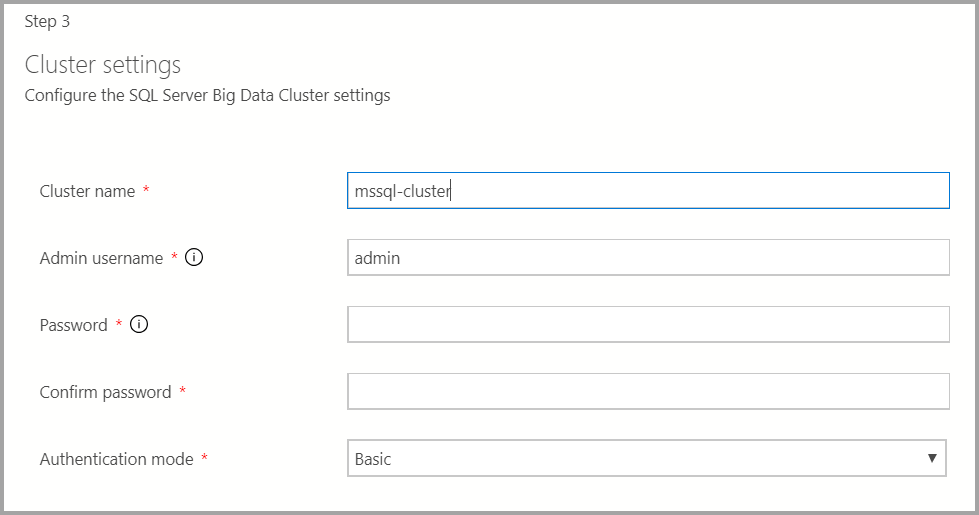
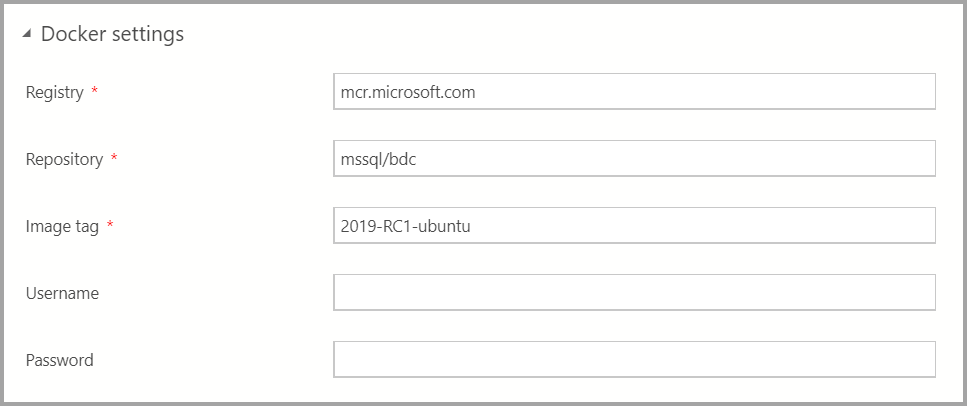
Insira as configurações do Docker conforme apropriado.
Important
Garanta que o campo de marca da imagem seja o mais recente: 2019-CU13-ubuntu-20.04
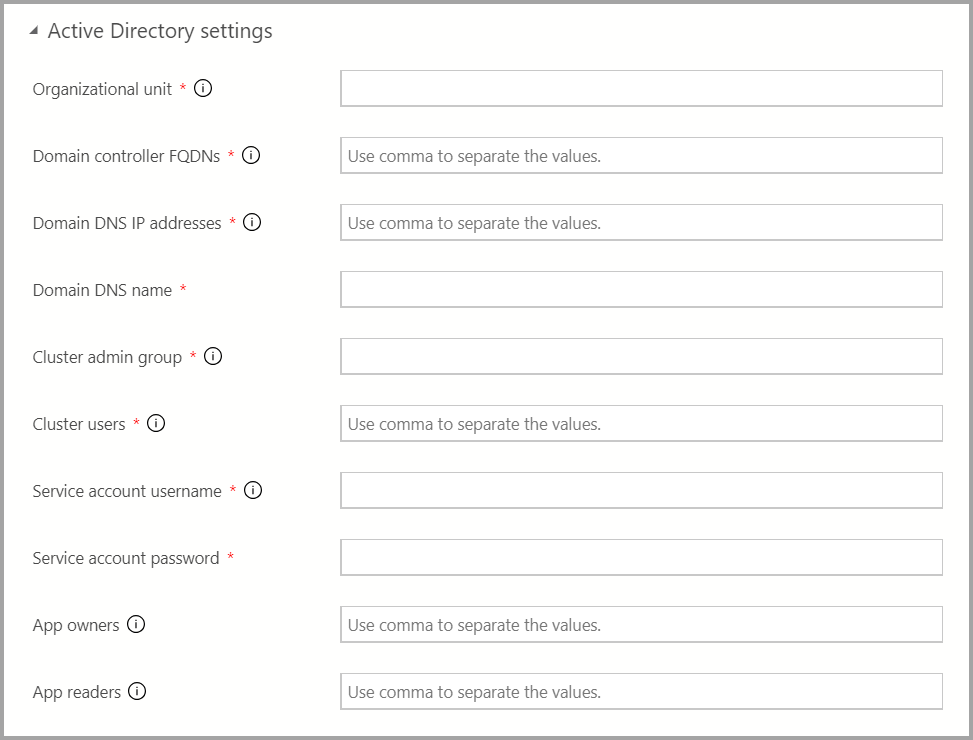
Se a autenticação do AD estiver disponível, insira as configurações do AD.
Service settings
Esta tela tem entradas para várias configurações, como Escala, Pontos de Extremidade, Armazenamento e outras Configurações de armazenamento avançadas. Insira os valores apropriados e selecione Avançar.
Scale settings
Insira o número de instâncias de cada um dos componentes no Cluster de Big Data.
Uma instância do Spark pode ser incluída junto com o HDFS. Ela é incluída no pool de armazenamento ou sozinha no Pool do Spark.
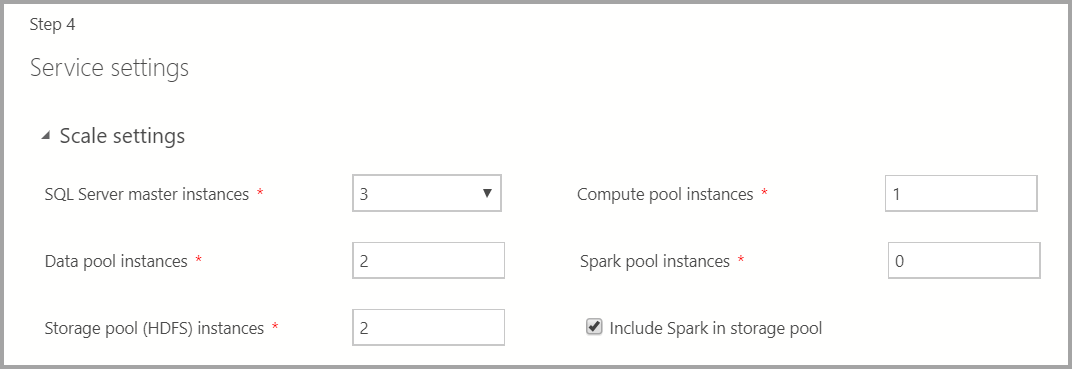
Para obter mais informações sobre cada um desses componentes, você pode consultar instância mestra, pool de dados, pool de armazenamento ou pool de computação.
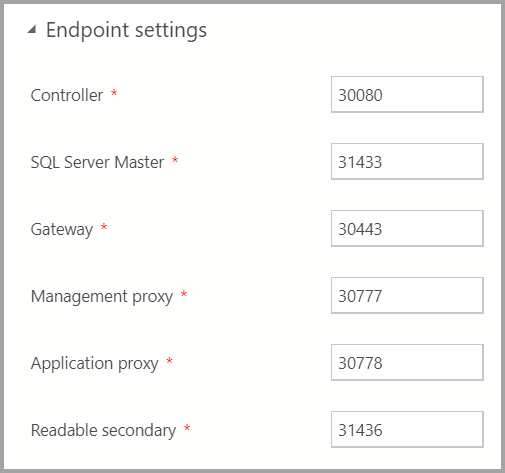
Endpoint settings
Os pontos de extremidade padrão foram preenchidos previamente. No entanto, eles podem ser alterados conforme apropriado.
Storage settings
As configurações de armazenamento incluem classe de armazenamento e tamanho de declaração para Dados e Logs. As configurações podem ser aplicadas em Armazenamento, Dados e pool mestre do SQL Server.

Configurações avançadas de armazenamento
Você pode adicionar configurações de armazenamento em Configurações avançadas de armazenamento
Pool de armazenamento (HDFS)
Data pool
SQL Server Mestre

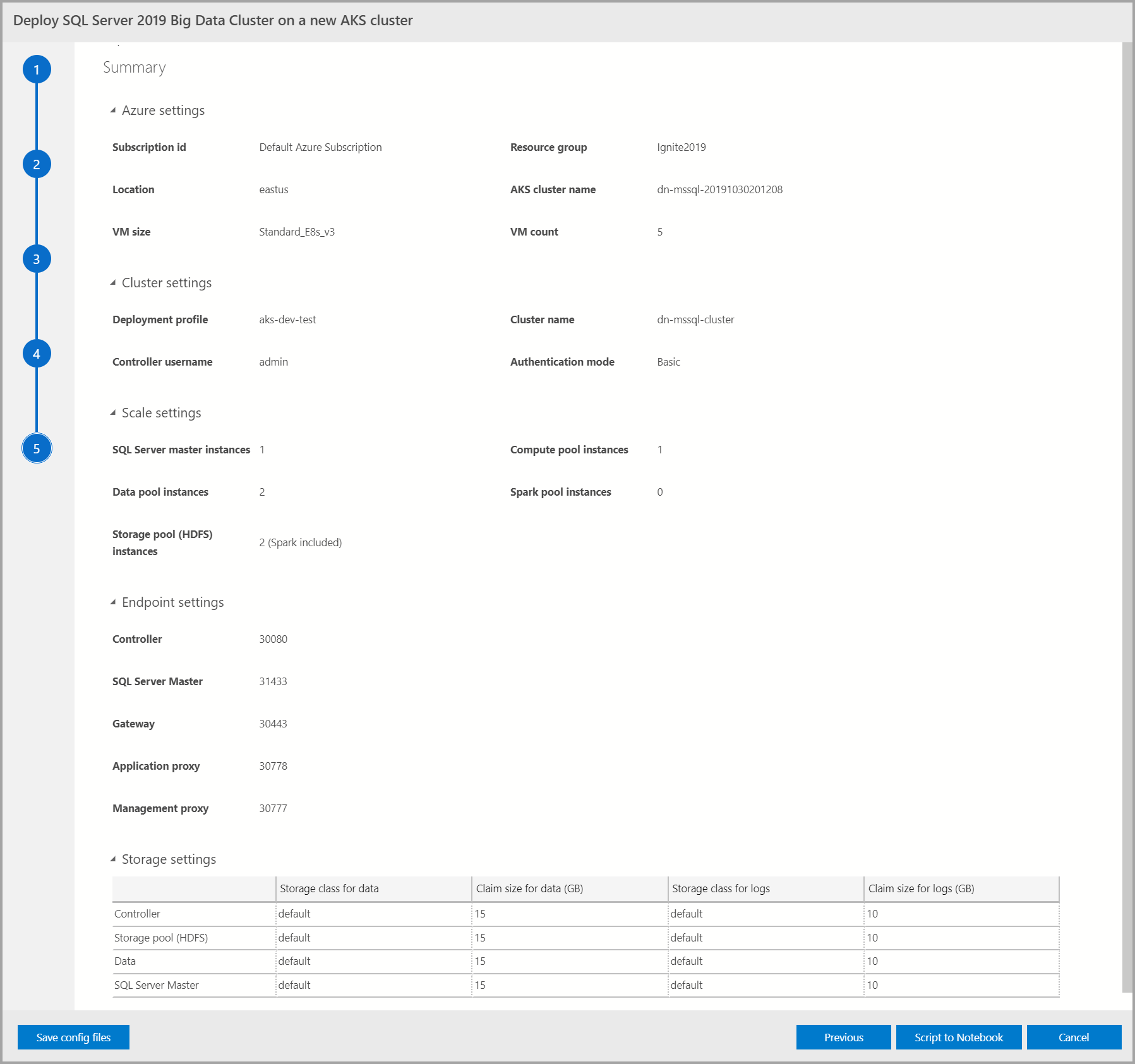
Summary
Esta tela resume todas as entradas fornecidas para implantar o cluster de Big Data. Os arquivos de configuração podem ser baixados usando o botão Salvar arquivos de configuração. Selecione Script para Notebook para gerar script de toda a configuração de implantação em um notebook. Quando o notebook estiver aberto, selecione Células de Execução para iniciar a implantação do cluster de Big Data no destino selecionado.
Next steps
Para obter mais informações sobre a implantação, confira as diretrizes de implantação para Clusters de Big Data do SQL Server.