Depurar e diagnosticar aplicativos Spark no Clusters de Big Data do SQL Server no Servidor de Histórico do Spark
Aplica-se a: ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Importante
O complemento Clusters de Big Data do Microsoft SQL Server 2019 será desativado. O suporte para Clusters de Big Data do SQL Server 2019 será encerrado em 28 de fevereiro de 2025. Todos os usuários existentes do SQL Server 2019 com Software Assurance terão suporte total na plataforma e o software continuará a ser mantido por meio de atualizações cumulativas do SQL Server até esse momento. Para obter mais informações, confira a postagem no blog de anúncio e as opções de Big Data na plataforma do Microsoft SQL Server.
Este artigo fornece orientações sobre como usar o Servidor de Histórico do Spark estendido para depurar e diagnosticar aplicativos Spark em um Cluster de Big Data do SQL Server. Essas funcionalidades de depuração e diagnóstico são internas do Servidor de Histórico do Spark e são da plataforma Microsoft. A extensão inclui guias de dados, de grafo e de diagnóstico. Na guia de dados, os usuários podem ver os dados de entrada e de saída do trabalho do Spark. Na guia de gráfico, os usuários podem ver o fluxo de dados e reproduzir o grafo do trabalho. Na guia de diagnóstico, o usuário pode consultar informações sobre Distorção de dados, Distorção de tempo e Análise de uso do executor.
Obter acesso ao Servidor de Histórico do Spark
A experiência do usuário com o servidor de histórico do Spark de software livre é aprimorada com informações, que incluem dados específicos do trabalho e a visualização interativa de grafos de trabalho e fluxos de dados do cluster de Big Data.
Abrir a interface do usuário da Web do Servidor de Histórico do Spark usando uma URL
Abra o Servidor de Histórico do Spark navegando até a URL a seguir, substitua <Ipaddress> e <Port> por informações específicas do cluster de Big Data. Em clusters implantados antes do SQL Server 2019 CU 5 em uma instalação de cluster de Big Data com autenticação Básica (nome de usuário/senha), você precisará fornecer a raiz do usuário quando for solicitado que faça logon em pontos de extremidade do gateway (Knox). Confira Implantar cluster de Big Data do SQL Server. A partir do SQL Server 2019 (15.x) CU 5, quando você implanta um novo cluster com a autenticação básica, todos os pontos de extremidade, incluindo o gateway, usam AZDATA_USERNAME e AZDATA_PASSWORD. Os pontos de extremidade em clusters que são atualizados para CU 5 continuam usando root como o nome de usuário para se conectar ao ponto de extremidade do gateway. Essa alteração não se aplica às implantações que usam a autenticação do Active Directory. Confira Credenciais para acessar serviços por meio do ponto de extremidade do gateway nas notas sobre a versão.
https://<Ipaddress>:<Port>/gateway/default/sparkhistory
A interface do usuário da Web do Servidor de Histórico do Spark se parece com:
Guia Dados no Servidor de Histórico do Spark
Selecione a ID do trabalho e clique em Dados no menu ferramenta para acessar a exibição de dados.
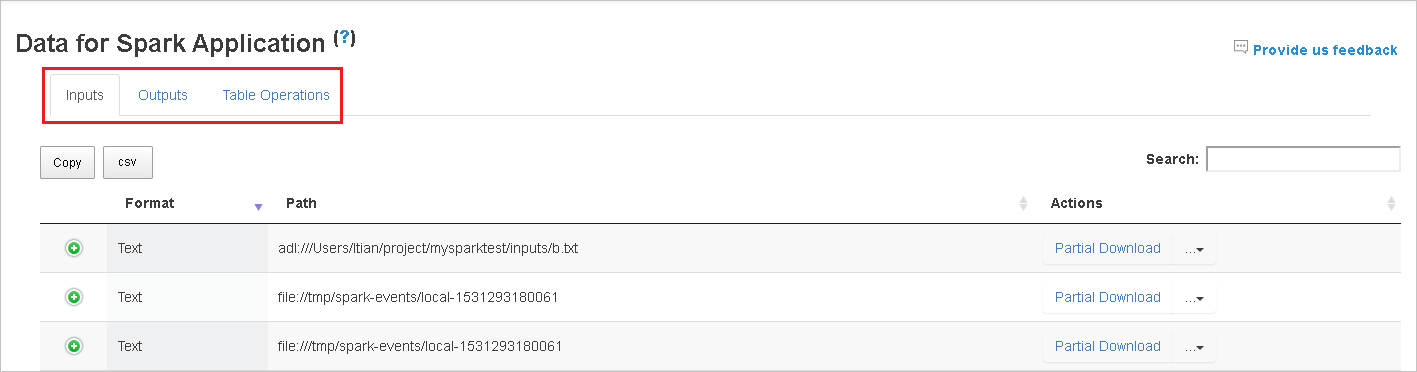
Confira as Entradas, as Saídas e as Operações de Tabelas selecionando as guias separadamente.
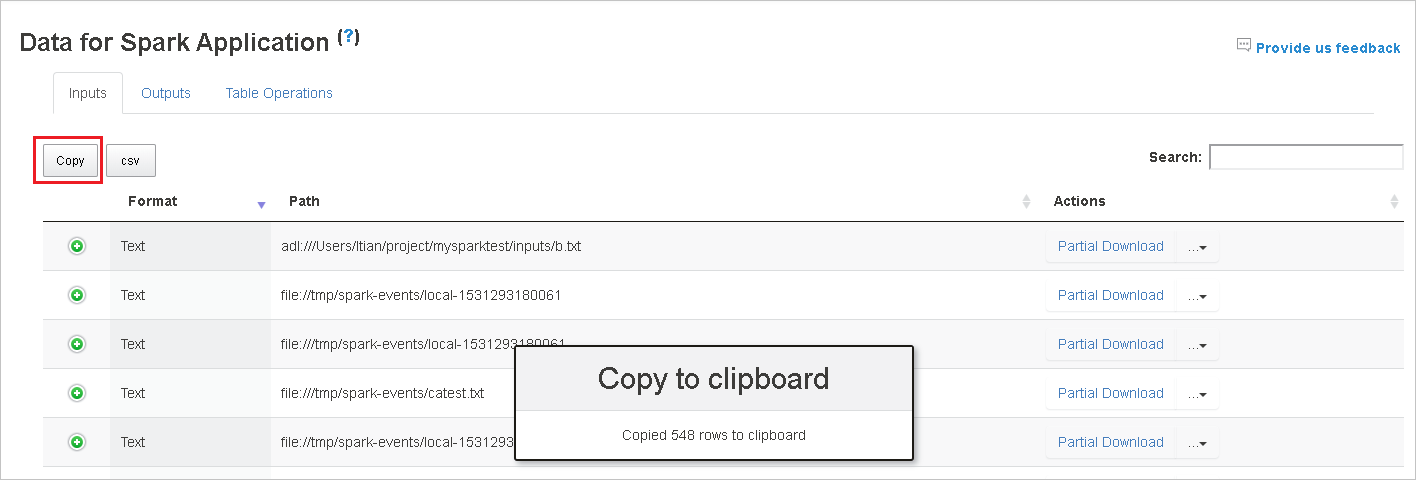
Copie todas as linhas clicando no botão Copiar.
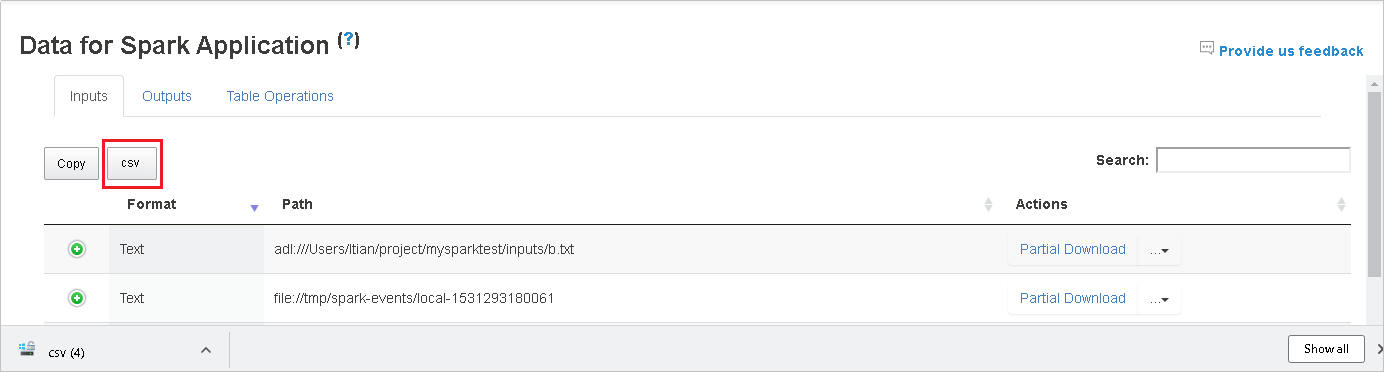
Salve todos os dados como um arquivo CSV clicando no botão csv.
Pesquise inserindo palavras-chave no campo Pesquisar; o resultado da pesquisa será exibido imediatamente.
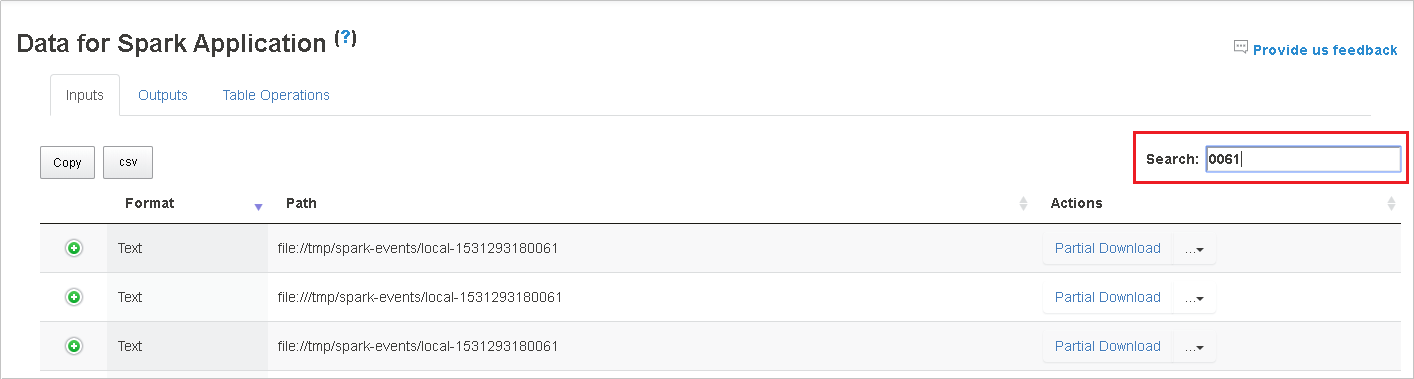
Clique no cabeçalho da coluna para classificar a tabela, clique no sinal de adição para expandir uma linha e mostrar mais detalhes ou clique no sinal de subtração para recolher uma linha.

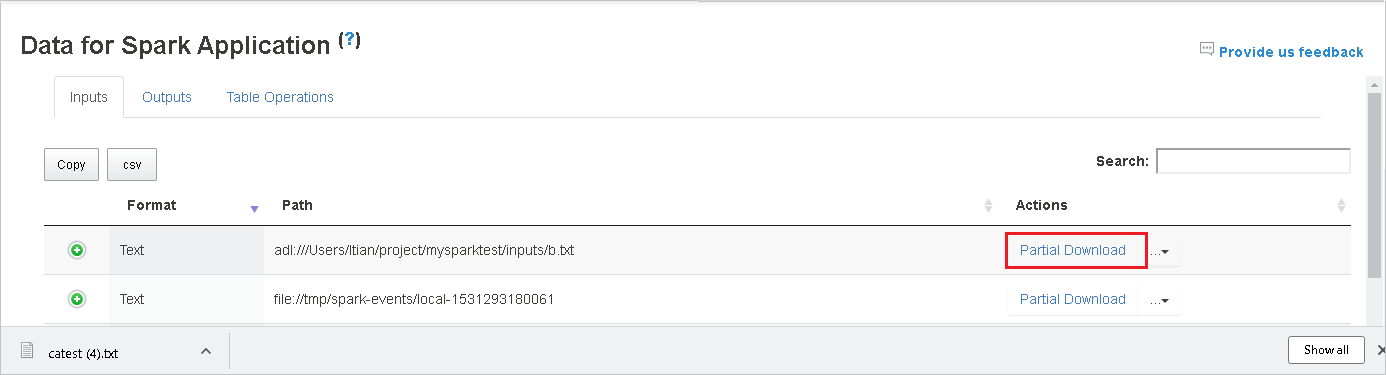
Baixe um único arquivo clicando no botão Download Parcial posicionado à direita. O arquivo selecionado será baixado para o local. Se o arquivo não existir mais, uma nova guia será aberta para mostrar as mensagens de erro.
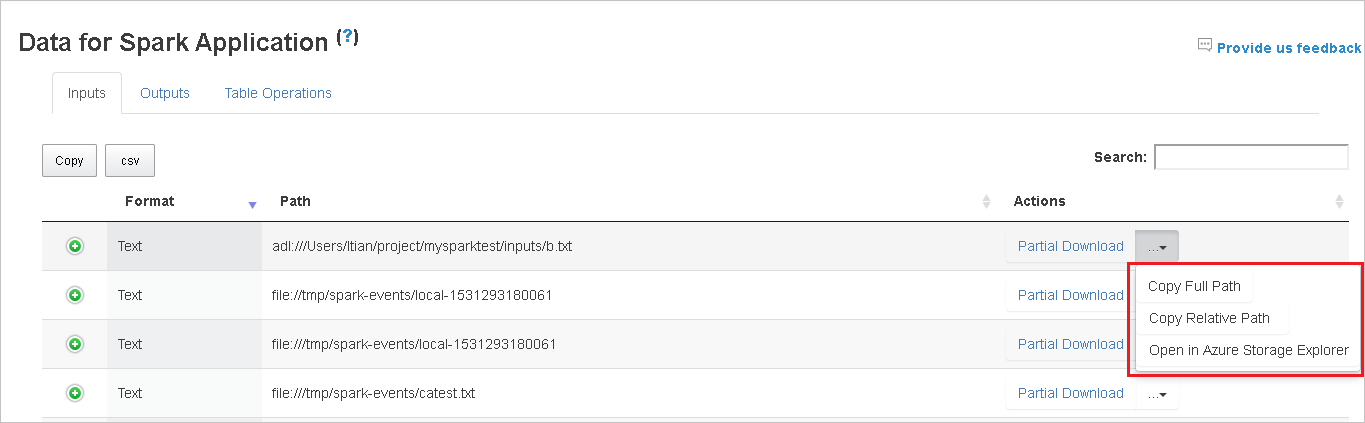
Copie o caminho completo ou o caminho relativo selecionando a opção Copiar Caminho Completo ou Copiar Caminho Relativo que se expande do menu de download. Para arquivos do Azure Data Lake Storage, clicar em Abrir no Gerenciador de Armazenamento do Azure iniciará o Gerenciador de Armazenamento do Azure. Localize a pasta exata ao entrar.
Clique no número sob a tabela para navegar pelas páginas quando houver linhas demais para serem exibidas em uma página.

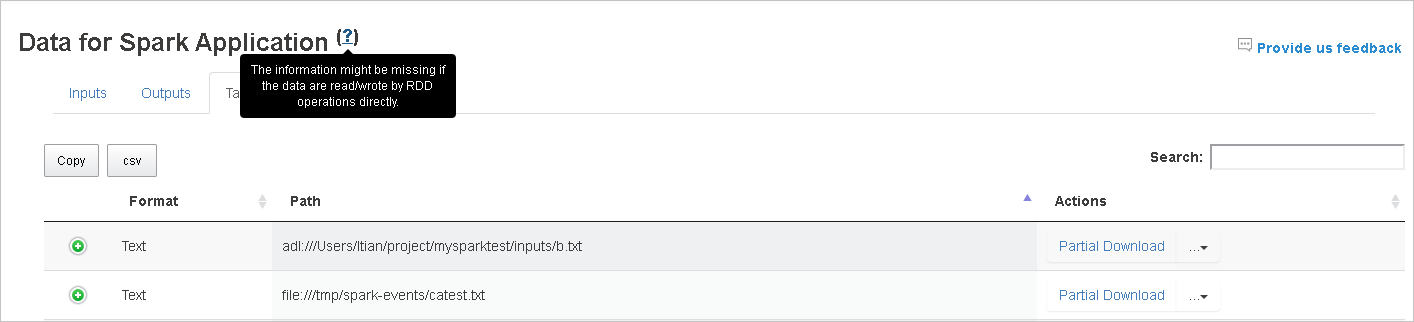
Focalize no ponto de interrogação ao lado de Dados para exibir a dica de ferramenta ou clique no ponto de interrogação para obter mais informações.
Envie comentários sobre problemas clicando em Fornecer comentários.
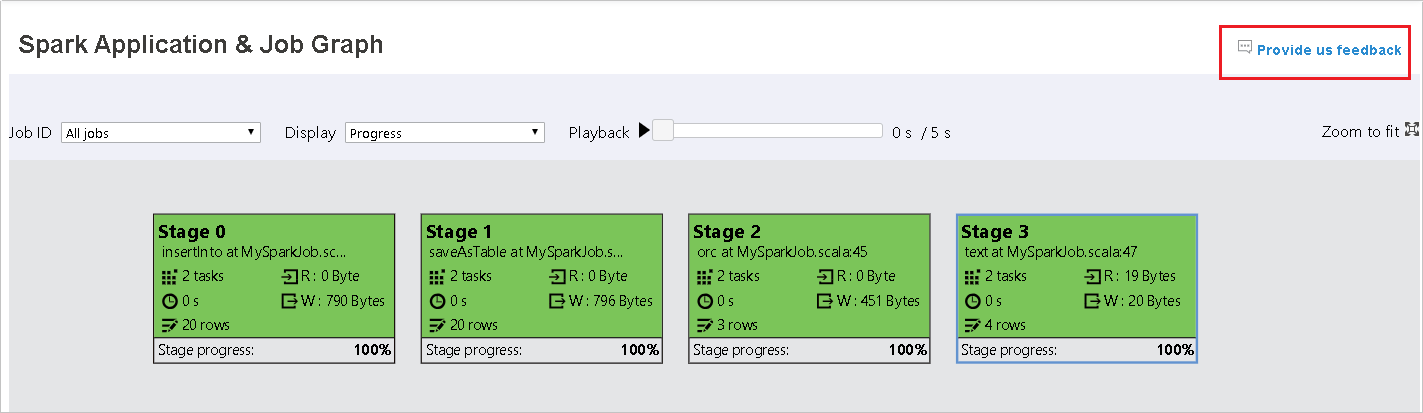
Guia Grafo no Servidor de Histórico do Spark
Selecione a ID do trabalho e clique em Grafo no menu ferramenta para acessar a exibição grafo do trabalho.
Tenha uma visão geral de seu trabalho com o grafo do trabalho que é gerado.
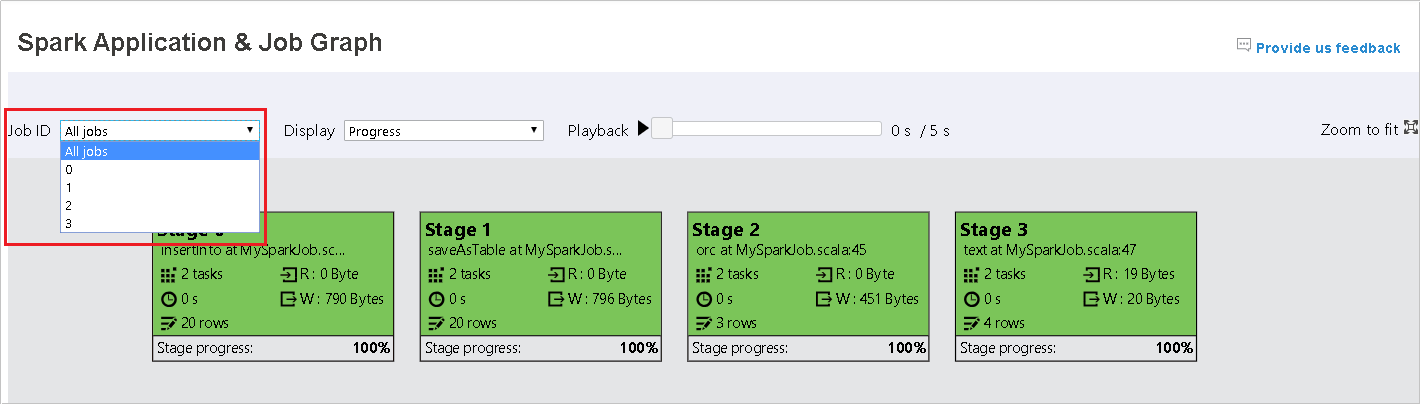
Por padrão, ele mostrará todos os trabalhos e poderá ser filtrado pela ID do Trabalho.
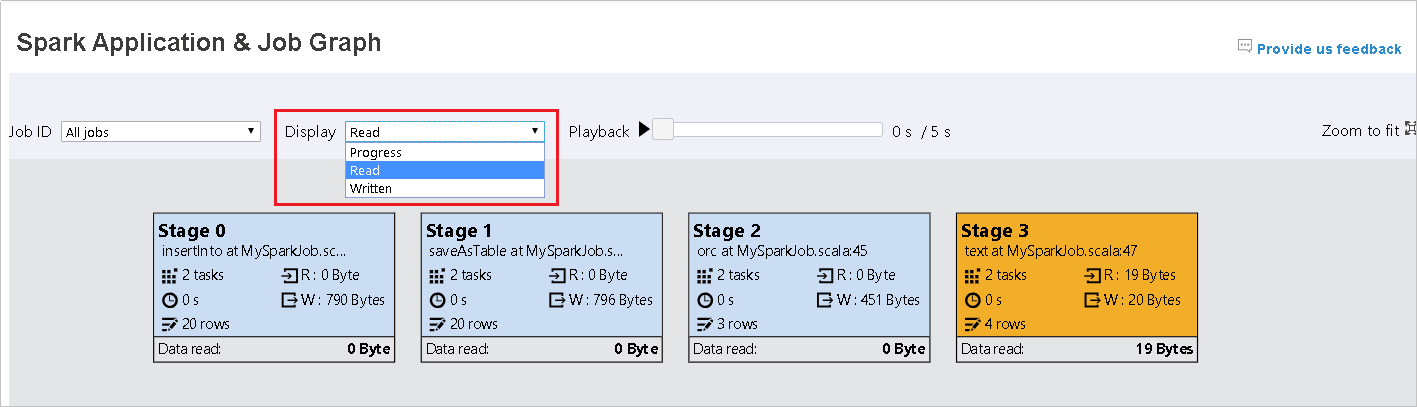
Deixamos Progresso como valor padrão. O usuário pode verificar o fluxo de dados selecionando Lido ou Gravado na lista suspensa Exibir.
O nó do grafo é exibido em cores que mostram o mapa de calor.

Reproduza o trabalho clicando no botão Reprodução e pare a qualquer momento clicando no botão parar. A tarefa é exibida em cores para mostrar diferentes status durante a reprodução:
- Verde para bem-sucedido: o trabalho foi concluído com êxito.
- Laranja para repetido: instâncias de tarefas que falharam, mas não afetam o resultado final do trabalho. Essas tarefas tiveram instâncias duplicadas ou repetidas que poderão ser bem-sucedidas mais tarde.
- Azul para em execução: a tarefa está em execução.
- Branco para em espera ou ignorado: a tarefa está aguardando para ser executada ou a fase foi ignorada.
- Vermelho para falha: a tarefa falhou.

A fase ignorada é exibida em branco.


Observação
É permitida a reprodução de cada trabalho. Para trabalhos incompletos, a reprodução não tem suporte.
Use rolagens do mouse para ampliar/reduzir o grafo do trabalho ou clica em Ajustar Nível de Zoom para ajustá-lo à tela.
Focalize o nó do grafo para ver a dica de ferramenta quando houver tarefas com falha e clique na fase para abrir a página referente a ela.
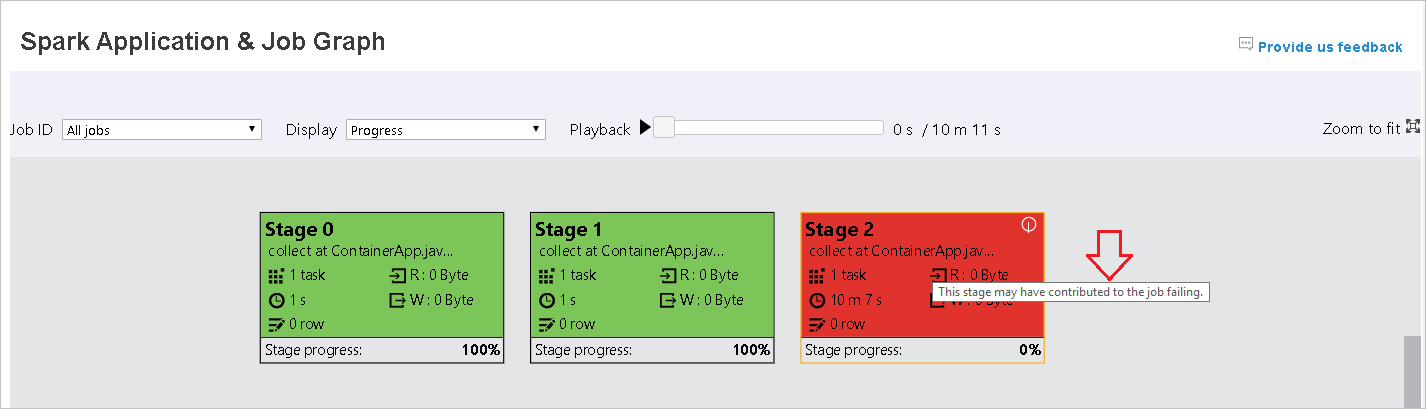
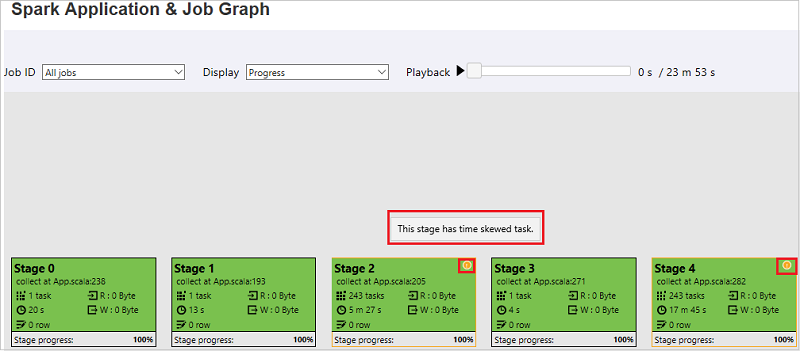
Na guia do grafo de trabalho, as fases terão a dica de ferramenta e um ícone pequeno exibidos se tiverem tarefas que atendam às condições abaixo:
- Distorção de dados: tamanho de leitura de dados > tamanho médio de leitura de dados de todas as tarefas dentro desta fase * 2 e tamanho de leitura de dados > 10 MB
- Distorção de tempo: tempo de execução > tempo médio de execução de todas as tarefas dentro desta fase * 2 e tempo de execução > 2 minutos
O nó do grafo do trabalho exibirá as seguintes informações de cada fase:
- ID.
- Nome ou descrição.
- Número total de tarefas.
- Leitura de dados: as somas do tamanho de entrada e do tamanho de leitura aleatória.
- Gravação de dados: as somas do tamanho de saída e do tamanho de gravação aleatória.
- Tempo de execução: o tempo entre a hora de início da primeira tentativa e a hora de conclusão da última tentativa.
- Contagem de linhas: a soma dos registros de entrada, registros de saída, registros de leitura aleatória e registros de gravação aleatória.
- Progresso.
Observação
Por padrão, o nó do grafo de trabalho exibirá informações sobre a última tentativa de cada fase (exceto pelo tempo de execução da fase), mas durante a reprodução, o nó do grafo mostrará informações sobre cada tentativa.
Observação
Para o tamanho dos dados de leitura e gravação, usamos 1MB = 1000 KB = 1000 * 1000 bytes.
Envie comentários sobre problemas clicando em Fornecer comentários.
Guia Diagnóstico no Servidor de Histórico do Spark
Selecione a ID do trabalho e clique em Diagnóstico no menu ferramenta para acessar a exibição de Diagnóstico do trabalho. A guia de diagnóstico inclui Distorção de dados, Distorção de tempo e Análise de uso do executor.
Confira as informações de Distorção de dados, Distorção de tempo e Análise de uso do executor selecionando as respectivas guias.
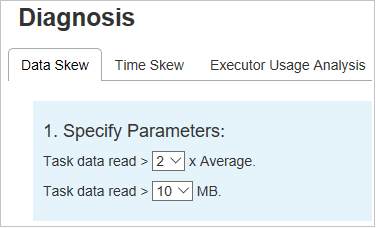
Distorção de dados
Clique na guia Distorção de dados; as tarefas distorcidas correspondentes são exibidas com base nos parâmetros especificados.
Especificar Parâmetros – a primeira seção exibe os parâmetros, que são usados para detectar a Distorção de dados. A regra interna é: a Leitura de Dados da Tarefa é maior que três vezes a média da leitura de dados da tarefa e a leitura de dados da tarefa é superior a 10 MB. Se quiser definir sua própria regra para tarefas distorcidas, você poderá escolher seus parâmetros e a Fase Distorcida; a seção Char Distorcido será atualizada de acordo com suas especificações.
Fase Distorcida – a segunda seção exibe as fases que têm tarefas distorcidas que atendem aos critérios especificados acima. Se houver mais de uma tarefa distorcida em uma fase, a tabela de fase distorcida exibirá apenas a tarefa mais distorcida (por exemplo, com os maiores dados para distorção de dados).
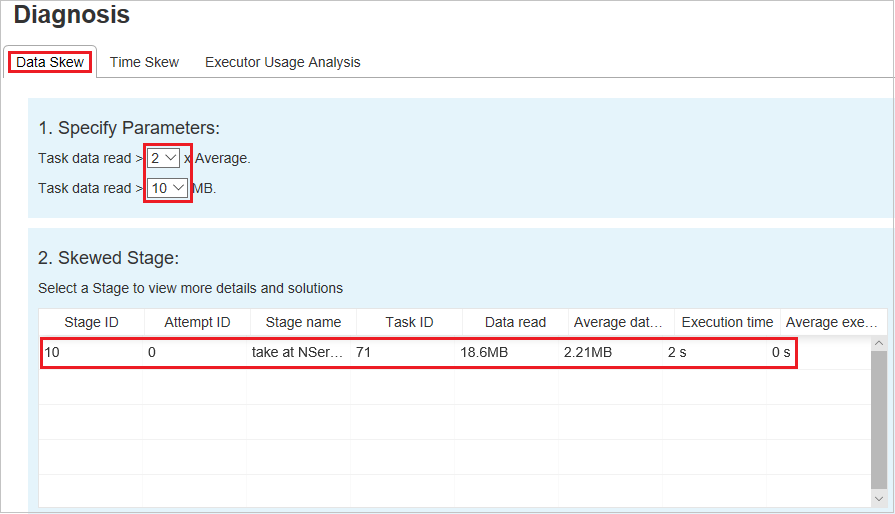
Gráfico de Distorção – quando uma linha na tabela da fase com distorção é selecionada, o gráfico de distorção exibe mais detalhes de distribuições da tarefa com base na leitura de dados e no tempo de execução. As tarefas distorcidas são marcadas em vermelho e as normais são marcadas em azul. Para não afetar o desempenho, o gráfico exibe no máximo 100 tarefas de exemplo. Os detalhes da tarefa são exibidos no painel inferior direito.
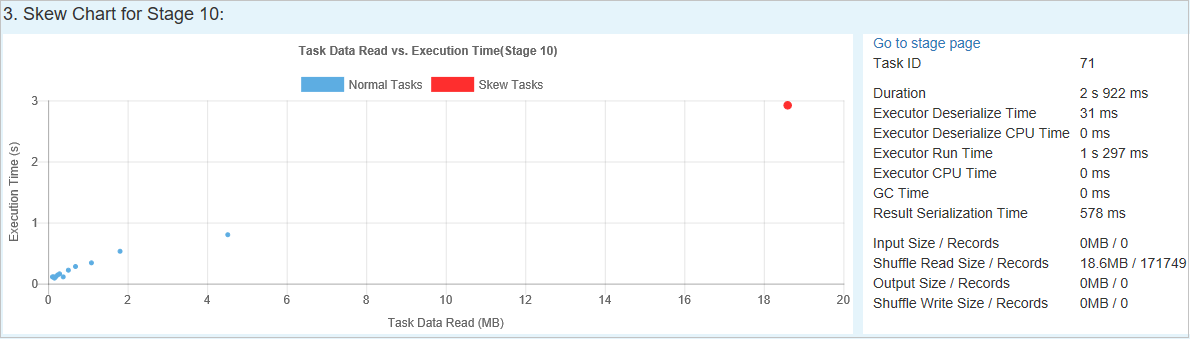
Distorção de tempo
A guia Distorção de Tempo exibe tarefas distorcidas com base no tempo de execução da tarefa.
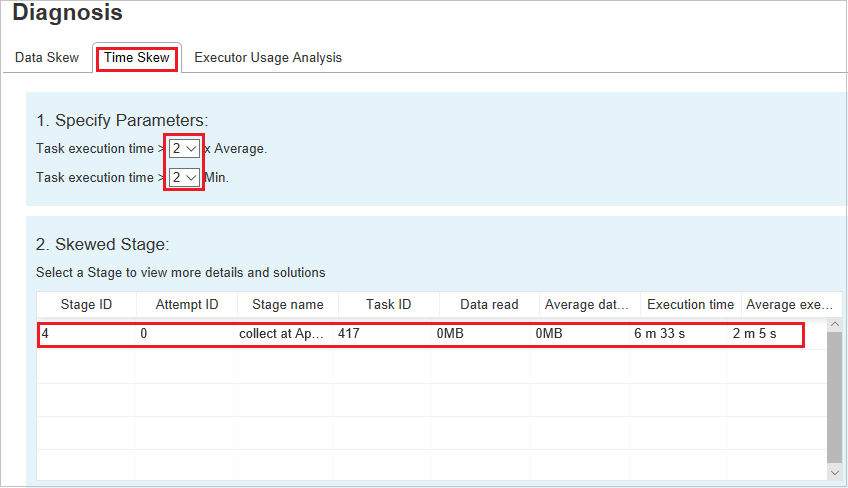
Especificar Parâmetros – a primeira seção exibe os parâmetros, que são usados para detectar a Distorção de tempo. Os critérios padrão para detectar a distorção de tempo são: o tempo de execução da tarefa é maior do que três vezes o tempo médio de execução e o tempo de execução da tarefa é maior que 30 segundos. Você pode alterar os parâmetros com base em suas necessidades. A Fase Distorcida e o Gráfico de Distorção exibem as informações sobre as fases e as tarefas correspondentes, assim como a guia Distorção de Dados acima.
Clique Distorção de Tempo e o resultado filtrado será exibido na seção Fase Distorcida de acordo com os parâmetros definidos na seção Especificar Parâmetros. Ao clicar em um item na seção Estágio Distorcido, o gráfico correspondente será exibido na seção 3 e os detalhes da tarefa serão exibidos no painel inferior direito.
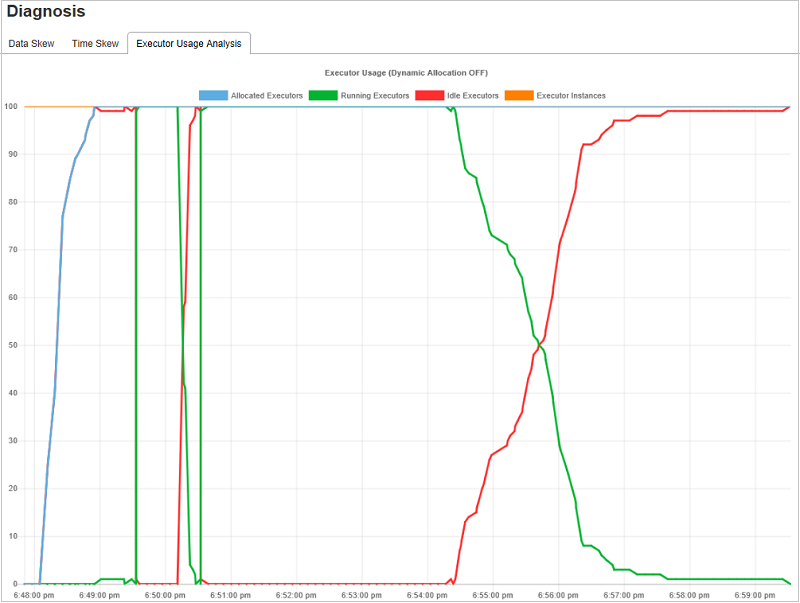
Análise de uso do executor
O Grafo de Uso do Executor visualiza a alocação do executor real do trabalho do Spark e o status da execução.
Clique Análise de Uso do Executor e, em seguida, traçaremos quatro tipos de curvas sobre o uso do executor. Elas incluem Executores Alocados, Executores em Execução, Executores Ociosos e Máx. de Instâncias do Executor. Com relação aos executores alocados, cada evento de "Executor adicionado" ou "Executor removido" aumentará ou diminuirá os executores alocados. Você pode verificar "Linha do tempo do evento" na guia "Trabalhos" para fazer mais comparações.
Clique no ícone colorido para selecionar ou desmarcar o conteúdo correspondente em todos os rascunhos.
Logs do Spark/Yarn
Além do Servidor de Histórico do Spark, você pode encontrar os logs para o Spark e Yarn aqui, respectivamente:
- Logs de eventos do Spark: hdfs:///system/spark-events
- Logs do Yarn: hdfs:///tmp/logs/root/logs-tfile
Observação: Ambos os logs têm um período de retenção padrão de sete dias. Se você quiser alterar o período de retenção, confira a página Configurar Apache Spark e Apache Hadoop. A localização não pode ser alterada.
Problemas conhecidos
O Servidor de Histórico do Spark tem os seguintes problemas conhecidos:
Atualmente, ele funciona apenas para o cluster do Spark 3.1 (CU13+) e o Spark 2.4 (CU12-).
Os dados de entrada/saída usando RDD não são mostrados na guia Dados.
Próximas etapas
- Introdução aos Clusters de Big Data do SQL Server
- Definir configurações do Spark
- Definir configurações do Spark