Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Diferenças em configurações de hardware, de software e de cluster, assim como diferentes requisitos de aplicativo para tempo de atividade e desempenho exigem uma configuração específica para valores de tempo limite de concessão, de cluster e de verificação de integridade. Determinados aplicativos e cargas de trabalho exigem um monitoramento mais agressivo para limitar o tempo de inatividade após falhas de disco rígido. Outros exigem mais tolerância para problemas de rede transitórios e espera de alto uso de recursos e permitem failovers mais lentos.
Vários serviços em cada nó de trabalho para detectar falhas. O serviço de cluster pode detectar perda de quorum, a DLL de recurso pode detectar um problema exibido pela detecção de integridade Always On ou o failover manual pode ser iniciado diretamente na instância principal. O serviço de cluster, o host do recurso e a instância do SQL Server sincronizam-se uns com os outros por meio do RPC, da memória compartilhada e do T-SQL. Na maioria dos cenários, esses serviços comunicam-se com êxito, porém essa comunicação não é perfeitamente confiável, até mesmo entre serviços no mesmo computador. Além disso, o AG (grupo de disponibilidade) precisa ser capaz de dar suporte a eventos que abrangem todo o sistema, como falhas de disco e de rede, que podem impedir a comunicação ou interromper a funcionalidade. Com muitos casos de falha e sem a comunicação entre serviços totalmente confiável, o grupo de disponibilidade depende de vários mecanismos de detecção de failover para detectar e responder a falhas independentemente uns dos outros para que o estado do cluster seja sempre consistente para todos os nós.
Diagnóstico de tempo limite de verificação de integridade aprimorado do SQL Server 2025
Restrições de recursos, como alta CPU, latência no disco ou esgotamento de memória, podem disparar um tempo limite de concessão (lease timeout) do grupo de disponibilidade Always On. Quando uma expiração de concessão é relatada no log do cluster, os dados mais recentes do monitor de desempenho para utilização da CPU, utilização de memória e latência de leitura e gravação de disco são relatados no Log do Cluster de Failover do Windows, juntamente com a expiração de concessão.
Da mesma forma, as restrições de recurso também podem disparar um tempo limite de verificação de integridade. A partir do SQL Server 2025 (17.x), os mesmos contadores de desempenho agora são relatados no Log do Cluster de Failover do Windows quando um tempo limite de verificação de saúde é detectado, semelhante à saída de diagnóstico de tempo limite de concessão.
Veja a seguir um exemplo da saída aprimorada do Log de Cluster de Failover do Windows para um tempo limite de verificação de integridade:
[Verbose] 000035b8.00001a64::2024/04/18-23:56:35.536 ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, diagnostics heartbeat is lost
[Verbose] 000035b8.00001a64::2024/04/18-23:56:35.536 WARN [RES] SQL Server Availability Group: [hadrag] AG health check failed, logging perf counter data collected so far
[Verbose] 000035b8.00001a64::2024/04/18-23:56:35.536 WARN [RES] SQL Server Availability Group: [hadrag] Date/Time, Processor time(%), Available memory(bytes), Avg disk read(secs), Avg disk write(secs)
[Verbose] 000035b8.00001a64::2024/04/18-23:56:35.536 WARN [RES] SQL Server Availability Group: [hadrag] 4/18/2024 23:55:25.0, 21.857418, 3248349184.000000, 0.000000, 0.000253
[Verbose] 000035b8.00001a64::2024/04/18-23:56:35.536 WARN [RES] SQL Server Availability Group: [hadrag] 4/18/2024 23:55:35.0, 11.442071, 3255394304.000000, 0.000907, 0.000382
[Verbose] 000035b8.00001a64::2024/04/18-23:56:35.536 WARN [RES] SQL Server Availability Group: [hadrag] 4/18/2024 23:55:45.0, 9.979768, 3253981184.000000, 0.000415, 0.000549
[Verbose] 000035b8.00001a64::2024/04/18-23:56:35.536 WARN [RES] SQL Server Availability Group: [hadrag] 4/18/2024 23:55:55.0, 9.762850, 3251232768.000000, 0.001989, 0.000638
[Verbose] 000035b8.00001a64::2024/04/18-23:56:35.536 WARN [RES] SQL Server Availability Group: [hadrag] 4/18/2024 23:56:5.0, 9.827234, 3250462720.000000, 0.002250, 0.001418
Nó de cluster e detecção de recurso
Cada nó no cluster executa um único serviço de cluster, que opera o cluster de failover e monitora todos os recursos de cluster. O host de recurso opera como um processo separado e é a interface entre o serviço de cluster e os recursos de cluster. O host de recurso executa operações em recursos de cluster quando chamada pelo serviço de cluster. Aplicativos com reconhecimento de cluster, como o SQL Server, oferecem interfaces personalizadas para o monitor de recursos por meio de DLLs de recurso. A DLL de recurso implementa operações online e offline e o monitoramento de integridade para recursos personalizadas. O host de recurso é um processo filho do serviço de cluster e é interrompido sempre que o serviço de cluster é interrompido.
Para o SQL Server, a DLL de recurso do grupo de disponibilidade determina a integridade do grupo de disponibilidade com base no mecanismo de concessão do grupo de disponibilidade e na detecção de integridade Always On. A DLL de recurso do grupo de disponibilidade expõe a integridade de recursos por meio da operação IsAlive. O monitor de recursos pesquisa IsAlive no intervalo de pulsação do cluster, definido pelos valores CrossSubnetDelay e SameSubnetDelay que abrangem todo o cluster. Em um nó principal, o serviço de cluster inicia failovers sempre que a chamada IsAlive à DLL de recurso retorna que o grupo de disponibilidade não é íntegro.
O serviço de cluster envia pulsações a outros nós no cluster e confirma pulsações recebidas deles. Quando um nó detecta uma falha de comunicação de uma série de pulsações não confirmadas, ele transmite uma mensagem que faz todos os nós acessíveis reconciliarem suas exibições de integridade do nó de cluster. Esse evento, chamado de um evento de reagrupamento, mantém a consistência do estado do cluster entre nós. Após um evento de reagrupamento, se o quorum for perdido, então todos os recursos de cluster, incluindo grupos de disponibilidade nessa partição, ficarão offline. Todos os nós nesta partição fazem a transição para um estado de resolução. Se houver uma partição, que contém um quorum, o grupo de disponibilidade será atribuído a um nó na partição e se tornará a réplica primária, enquanto todos os outros nós serão réplicas secundárias.
Detecção de integridade Always On
A DLL de recurso Always On monitora o status de componentes internos do SQL Server. O sp_server_diagnostics relata a integridade desses componentes do SQL Server em um intervalo controlado pelo HealthCheckTimeout. O sp_server_diagnostics relata o status de integridade dos cinco componentes de nível de instância: sistema, recurso, processamento de consulta, subsistema de E/S e eventos. Ele também relata a integridade de cada grupo de disponibilidade. Após cada atualização, a DLL de recurso atualiza o status de integridade do recurso do AG com base no nível de falha do grupo de disponibilidade. Quando os dados são retornados pelo sp_server_diagnostics, ele mostra cada componente como em um estado de erro, aviso, limpo ou desconhecido com alguns dados XML que descrevem o estado do componente. Para a detecção de integridade, a DLL de recurso só entrará em ação se um componente estiver em um estado de erro.
Se a detecção de integridade não relatar uma atualização para a DLL de recurso para vários intervalos, então o grupo de disponibilidade será determinado não íntegro e relatará falhas em chamadas IsAlive.
Mecanismo de concessão
Ao contrário de outros mecanismos de failover, a instância do SQL Server desempenha um papel ativo no mecanismo de concessão. O mecanismo de concessão é usado como uma validação Looks-Alive entre o host de recursos de Cluster e o processo do SQL Server. O mecanismo é usado para garantir que os dois lados (o Serviço de Cluster e o SQL Server) estejam em contato frequente, verificando o estado um do outro e, por fim, impedindo um cenário de separação. Ao colocar o grupo de disponibilidade online como a réplica primária, a instância do SQL Server gera um thread de trabalho de concessão dedicado para o grupo de disponibilidade. O trabalho de concessão compartilha uma pequena região da memória com o host de recurso que contém eventos de renovação e de interrupção da concessão. O trabalho de concessão e o host de recurso trabalham de maneira circular, sinalizando o respectivo evento de renovação da concessão e, em seguida, entrando em suspensão e aguardando a outra parte sinalizar seu próprio evento de renovação da concessão ou o evento de interrupção. O host do recurso e o thread de concessão do SQL Server mantêm um valor de vida útil, atualizado cada vez que o thread é ativado após ser sinalizado por outro thread. Se a vida útil for atingida enquanto aguarda o sinal, a concessão expirará e, em seguida, a réplica fará a transição para o estado de resolução para esse grupo de disponibilidade específico. Se o evento de interrupção da concessão for sinalizado, então a réplica fará a transição para uma função de resolução.
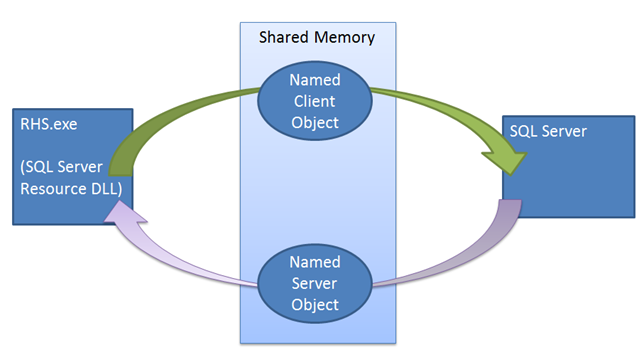
O mecanismo de concessão impõe a sincronização entre o SQL Server e o Cluster de Failover do Windows Server. Quando um comando de failover é emitido, o serviço de cluster faz uma chamada Offline para a DLL de recurso da réplica primária atual. A DLL de recurso tenta primeiro colocar o grupo de disponibilidade offline usando um procedimento armazenado. Se esse procedimento armazenado falhar ou atingir o tempo limite, a falha será relatada de volta para o serviço de cluster, que emitirá um comando de encerramento. O encerramento tenta novamente executar o mesmo procedimento armazenado, mas, desta vez, o cluster não aguarda a DLL de recurso relatar êxito ou falha antes de colocar o grupo de disponibilidade online em uma nova réplica. Se a segunda chamada de procedimento falhar, então o host do recurso precisará contar com o mecanismo de concessão para colocar a instância offline. Quando a DLL de recurso for chamada para colocar o grupo de disponibilidade offline, a DLL de recurso sinalizará o evento de interrupção da concessão, ativando o thread de trabalho de concessão do SQL Server para colocar o grupo de disponibilidade offline. Mesmo se esse evento de interrupção não for sinalizado, a concessão expirará e a réplica fará a transição para o estado de resolução.
A concessão é sobretudo um mecanismo de sincronização entre a instância primária e o cluster, mas também pode criar condições de falha onde não houve necessidade de fazer failover. Por exemplo, alta utilização da CPU, condições de memória insuficiente (memória virtual baixa, paginação de processo), falta de resposta do processo SQL ao gerar um despejo de memória, falta de resposta do sistema, cluster (WSFC) offline (por exemplo, por perda de quorum) podem impedir a renovação da concessão da instância do SQL e provocar uma reinicialização ou um failover.
Diretrizes para valores de tempo limite de cluster
Considere com atenção as compensações e entenda as consequências de usar um monitoramento menos agressivo do cluster do SQL Server. Aumentar os valores de tempo limite do cluster aumenta a tolerância de problemas de rede transitórios, mas retarda as reações a falhas de disco rígido. Aumentar tempos limite para lidar com a pressão de recursos ou com a grande latência geográfica aumentará o tempo de recuperação do disco rígido ou as falhas não recuperáveis também. Embora isto seja aceitável para muitos aplicativos, não é ideal em todos os casos.
As configurações padrão são otimizadas para oferecer reação rápida a sintomas de falhas de disco rígido e limitação do tempo de inatividade, mas essas configurações também podem ser muito agressivas para determinadas cargas de trabalho e configurações. Não é recomendável reduzir LeaseTimeout, CrossSubnetDelay, CrossSubnetThreshold, SameSubnetDelay, SameSubnetThreshold ou HealthCheckTimeout para além de seus valores padrão. As configurações corretas para cada implantação variarão e provavelmente levarão um tempo maior de ajuste para descoberta. Ao fazer alterações em qualquer um desses valores, faça-as gradualmente e considerando as relações e dependências entre esses valores.
Relação entre o tempo limite do cluster e o tempo limite de concessão
A função principal do mecanismo de concessão é usar o recurso offline do SQL Server caso o serviço de cluster não possa se comunicar com a instância ao executar um failover em outro nó. Quando o cluster executa a operação offline no recurso de cluster do grupo de disponibilidade, o serviço de cluster faz uma chamada RPC a rhs.exe para colocar o recurso offline. A DLL de recurso usa procedimentos armazenados para informar o SQL Server para colocar o grupo de disponibilidade offline, mas esse procedimento armazenado pode falhar ou atingir o tempo limite. O host de recursos também interrompe seu próprio thread de renovação de leasing durante a chamada off-line. No pior caso, o SQL Server faz a concessão expirar em metade de LeaseTimeout e fará a transição da instância para um estado de resolução. Os failovers podem ser iniciados por várias partes diferentes, mas é extremamente importante que a exibição do estado de cluster seja consistente entre o cluster e entre as instâncias do SQL Server. Por exemplo, imagine um cenário em que a instância primária perde a conexão com o restante do cluster. Cada nó no cluster determinará uma falha em momentos semelhantes devido a valores de tempo limite do cluster, mas apenas o nó primário poderá interagir com a instância primária do SQL Server para forçá-lo a desistir da função primária.
Da perspectiva do nó principal, o serviço de cluster perde o quorum e o serviço começa a ser encerrado sozinho. O serviço de cluster emite uma chamada RPC ao host do recurso para encerrar o processo. Essa chamada de encerramento é responsável por colocar o grupo de disponibilidade offline na instância do SQL Server. Essa chamada offline é realizada por meio do T-SQL, mas não pode garantir que a conexão será estabelecida com sucesso entre o SQL e a DLL de recurso.
Da perspectiva do restante do cluster, não há nenhuma réplica primária no momento, portanto, o cluster vota e estabelece um único novo primário para os nós restantes no cluster. Se o procedimento armazenado que foi chamado pela DLL de recurso falhar ou atingir o tempo limite, o cluster poderá estar vulnerável a um cenário de dupla personalidade.
O tempo de concessão impede cenários de dupla personalidade diante de erros de comunicação. Mesmo se toda a comunicação falhar, o processo de DLL de recurso encerrará e não será possível atualizar a concessão. Quando a concessão expirar, ela colocará o grupo de disponibilidade offline sozinha. A instância do SQL Server precisa estar ciente de que ela não hospedará mais a réplica primária antes que o cluster estabeleça uma nova. Desde que o restante do cluster, responsável por escolher uma nova réplica primária, não tem meios de se coordenar com a réplica primária atual, os valores de tempo limite garantem que uma nova réplica primária não seja estabelecida antes que a primária atual se coloque offline.
Quando o cluster faz failover, a instância do SQL Server que hospeda a réplica primária anterior deve fazer a transição para um estado de resolução antes que a nova réplica primária fique online. O thread de concessão do SQL Server em qualquer ponto tem uma vida útil remanescente de metade de LeaseTimeout, porque sempre que a concessão é renovada a nova vida útil é atualizada para LeaseInterval ou para metade de LeaseTimeout. Se o serviço de cluster ou o host de recurso for paralisado ou encerrado sem sinalizar o evento de interrupção de concessão, o cluster declarará o nó primário inativo após SameSubnetThreshold\ SameSubnetDelay milissegundos. Dentro desse período, a concessão deverá expirar para que a primária tenha garantia de estar offline. Como o valor de vida útil para o tempo limite da concessão é de metade de LeaseTimeout, metade de LeaseTimeout deve ser menor do que SameSubnetThreshold * SameSubnetDelay.
SameSubnetThreshold \<= CrossSubnetThreshold e SameSubnetDelay \<= CrossSubnetDelay devem ser verdadeiros para todos os clusters do SQL Server.
Operação de tempo limite da verificação de integridade
O tempo limite de verificação de integridade é mais flexível, porque nenhum outro mecanismo de failover depende dele diretamente. O valor padrão de 30 segundos define o intervalo de sp_server_diagnostics em 10 segundos, com um valor mínimo de 15 segundos para tempo limite e um intervalo de 5 segundos. Geralmente, o intervalo de atualização de sp_server_diagnostics sempre é de 1/3 de HealthCheckTimeout. Quando a DLL de recurso não recebe um novo conjunto de dados de integridade em um intervalo, ela continuará usando os dados de integridade do intervalo anterior para determinar o grupo de disponibilidade atual e a integridade da instância. Aumentar o valor de tempo limite de verificação da integridade tornará a primária mais tolerante com a pressão da CPU, que pode impedir o sp_server_diagnostics de fornecer novos dados em cada intervalo. Contudo, ele contará com verificações de integridade de dados desatualizadas por mais tempo. Independentemente do valor de tempo limite, depois que os dados forem recebidos, indicando que a réplica não está íntegra, a próxima chamada do IsAlive retornará que essa instância não está íntegra e que o serviço de cluster iniciará um failover.
O nível de condição de falha do grupo de disponibilidade altera as condições de falha para a verificação de integridade. Para qualquer nível de falha, se o elemento do grupo de disponibilidade for relatado não íntegro pelo sp_server_diagnostics, então a verificação de integridade falha. Cada nível herda todas as condições de falha dos níveis abaixo dele.
| Nível | Condição sob a qual a instância é considerada inativa |
|---|---|
| 1: OnServerDown | A verificação de integridade não executará nenhuma ação se qualquer recurso, além do grupo de disponibilidade, falhar. Caso os dados do grupo de disponibilidade não sejam recebidos dentro de cinco intervalos ou 5/3 de HealthCheckTimeout |
| 2: OnServerUnresponsive | Se nenhum dado for recebido do sp_server_diagnostics para o HealthCheckTimeout |
| 3: OnCriticalServerError | (Padrão) Se o componente do sistema relatar um erro |
| 4: OnModerateServerError | Se o componente do recurso relatar um erro |
| 5: EmQualquerCondiçãoDeFalhaQualificada | Se o componente de processamento de consulta relatar um erro |
Atualizando os valores do cluster e de tempo limite Always On
Valores do cluster
Há quatro valores na configuração WSFC responsáveis por determinar os valores de tempo limite do cluster:
- SameSubnetDelay
- SameSubnetThreshold
- CrossSubnetDelay
- CrossSubnetThreshold
Os valores de atraso determinam o tempo de espera entre pulsações do serviço de cluster, e os valores limite definem o número de pulsações que não podem receber nenhuma confirmação do nó de destino ou do recurso antes que o objeto seja declarado inativo pelo cluster. Se não houver nenhuma pulsação bem-sucedida entre nós na mesma sub-rede por mais de SameSubnetDelay \* SameSubnetThreshold milissegundos, então o nó será determinado inativo. O mesmo é verdadeiro para a comunicação de sub-rede cruzada usando os valores de sub-rede cruzados.
Para listar todos os valores de cluster atuais, em qualquer nó no cluster de destino, abra um terminal do PowerShell com privilégios elevados. Execute o comando a seguir:
Get-Cluster | fl *
Para atualizar qualquer um desses valores, execute o seguinte comando em um terminal do PowerShell com privilégios elevados:
(Get-Cluster).<ValueName> = <NewValue>
Ao aumentar o produto de Limite x Atraso para tornar o tempo limite do cluster mais tolerante, é mais eficaz aumentar primeiro o valor do atraso antes de aumentar o limite. Aumentando o atraso, aumenta-se o tempo entre cada pulsação. Mais tempo entre pulsações possibilita mais tempo para que os problemas de rede transitórios resolvam a si mesmos e diminuam o congestionamento da rede com relação ao envio de mais pulsações no mesmo período.
Tempo limite de concessão
O mecanismo de concessão é controlado por um único valor específico para cada grupo de disponibilidade em um cluster WSFC. Um tempo limite de concessão pode resultar nos seguintes erros:
Error 35201:
A connection timeout has occurred while attempting to establish a connection to availability replica 'replicaname'
Error 35206:
A connection timeout has occurred on a previously established connection to availability replica 'replicaname'
Para modificar o valor do tempo limite de concessão, use o Gerenciador de Cluster de Failover e siga estas etapas:
Na guia de funções, localize a função de grupo de disponibilidade de destino. Selecione a função do AG de destino.
Clique com o botão direito do mouse no recurso do grupo de disponibilidade na parte inferior da janela e selecione Propriedades.

Na janela pop-up, navegue até a guia propriedades para ver uma lista de valores específicos para esse grupo de disponibilidade. Selecione o valor LeaseTimeout para alterá-lo.
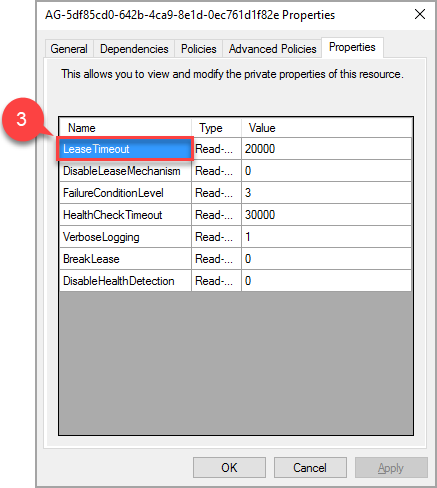
Dependendo da configuração do grupo de disponibilidade, pode haver mais recursos para ouvintes, discos compartilhados, compartilhamentos de arquivo, etc. Esses recursos não exigem nenhuma configuração adicional.
Observação
O novo valor da propriedade 'LeaseTimeout' entrará em vigor depois que o recurso for colocado offline e colocado online novamente.
Valores de verificação de integridade
Dois valores controlam a verificação de integridade do Always On: FailureConditionLevel e HealthCheckTimeout. O FailureConditionLevel indica o nível de tolerância para condições de falha específicas relatadas por sp_server_diagnostics, e o HealthCheckTimeout configura o tempo que a DLL de recurso pode prosseguir sem receber uma atualização de sp_server_diagnostics. O intervalo de atualização para sp_server_diagnostics é sempre HealthCheckTimeout/3.
Para configurar o nível de condição de failover, use a opção FAILURE_CONDITION_LEVEL = <n> da instrução CREATE ou ALTERAVAILABILITY GROUP, em que <n> é um inteiro entre 1 e 5. O comando a seguir define o nível de condição de falha como 1 para o grupo de disponibilidade 'AG1':
ALTER AVAILABILITY GROUP AG1 SET (FAILURE_CONDITION_LEVEL = 1);
Para configurar o tempo limite da verificação de integridade, use a opção HEALTH_CHECK_TIMEOUT das instruções CREATE ou ALTERAVAILABILITY GROUP. O comando a seguir define o tempo limite da verificação de integridade como 60.000 milissegundos para o grupo de disponibilidade AG1:
ALTER AVAILABILITY GROUP AG1 SET (HEALTH_CHECK_TIMEOUT =60000);
Resumo das diretrizes de tempo limite
Não é aconselhável reduzir os valores de tempo limite abaixo de seus valores padrão.
O intervalo de concessão (metade de LeaseTimeout) deve ser mais curto do que SameSubnetThreshold vezes SameSubnetDelay
SameSubnetThreshold <= CrossSubnetThreshold
SameSubnetDelay <= CrossSubnetDelay
| Configuração de tempo limite | Finalidade | Entre | Usos | IsAlive e LooksAlive | Causas | Resultado |
|---|---|---|---|---|---|---|
| Tempo limite de concessão Padrão: 20000 |
Impede dupla personalidade. | Primária para o Cluster (HADR) |
Objetos de evento do Windows | Usado em ambos | Falta de resposta do sistema operacional, memória virtual insuficiente, paginação de conjunto de trabalho, geração de despejo de memória, CPU vinculada, cluster WSFC inoperante (perda de quorum) | Recurso do grupo de disponibilidade offline-online, failover |
| Tempo limite da sessão Padrão: 10000 |
Informar sobre o problema de comunicação entre a primária e a secundária | Secundária para primária (HADR) |
Soquetes TCP (mensagens enviadas por meio do ponto de extremidade DBM) | Usado em nenhum dos dois | Comunicação de rede, Problemas na secundária – inoperante, falta de resposta do sistema operacional, contenção de recursos |
Secundária – desconectada |
| Tempo limite de HealthCheck Padrão: 30000 |
Indique o tempo limite ao tentar determinar a integridade da réplica primária | Cluster para primária (FCI e HADR) |
sp_server_diagnostics T-SQL | Usado em ambos | Condições de falha atendidas, falta de resposta do sistema operacional, memória virtual insuficiente, corte do conjunto de trabalho, geração de despejo, WSFC (perda de quorum), problemas no agendador (agendadores com deadlock) | Recurso de AG Offline-online ou Failover, reinicialização/failover de FCI |