Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Aplica-se a:![]() SQL Server 2017 (14.x) e versões posteriores
SQL Server 2017 (14.x) e versões posteriores
Este artigo explica as etapas para criar um AG (Grupo de Disponibilidade) Always On com uma réplica em um Windows Server e a outra réplica em um servidor Linux.
Importante
Os grupos de disponibilidade multiplataforma do SQL Server, que incluem réplicas heterogêneas com suporte completo para alta disponibilidade e recuperação de desastre, estão disponíveis com o DH2i DxEnterprise. Para obter mais informações, confira Grupos de disponibilidade do SQL Server com sistemas operacionais mistos.
Veja o vídeo a seguir para saber mais sobre grupos de disponibilidade multiplataforma com DH2i.
Essa configuração é multiplataforma porque as réplicas estão em sistemas operacionais diferentes. Use essa configuração para migrar de uma plataforma para a outra ou para DR (recuperação de desastre). Essa configuração não dá suporte à alta disponibilidade.
Antes de continuar, você deve estar familiarizado com a instalação e a configuração para instâncias do SQL Server no Windows e no Linux.
Cenário
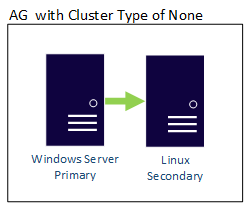
Neste cenário, dois servidores estão em sistemas operacionais diferentes. Um Windows Server 2022 chamado WinSQLInstance hospeda a réplica primária. Um servidor Linux chamado LinuxSQLInstance hospeda a réplica secundária.
Configurar o AG
As etapas para criar o AG são as mesmas que as etapas para criar um AG de cargas de trabalho de escala de leitura. O tipo de cluster do AG é NONE, porque não há nenhum gerenciador de cluster.
Para os scripts neste artigo, colchetes angulares < e > identificam os valores que você precisa substituir para o seu ambiente. Os colchetes angulares em si não são necessários para os scripts.
Instale o SQL Server 2022 (16.x) no Windows Server 2022, habilite os Grupos de Disponibilidade Always On no SQL Server Configuration Manager e defina a autenticação de modo misto.
Dica
Se você estiver validando essa solução no Azure, coloque ambos os servidores no mesmo conjunto de disponibilidade para garantir que eles estejam separados no data center.
Habilitar Grupos de Disponibilidade
Para obter instruções, consulte Habilitar ou desabilitar o recurso de grupo de disponibilidade Always On.
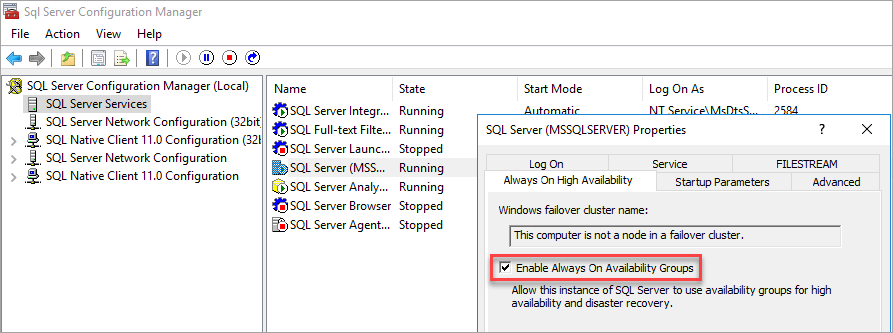
O SQL Server Configuration Manager observa que o computador não faz parte de um nó em um cluster de failover.
Depois de habilitar os Grupos de Disponibilidade, reinicie o SQL Server.
Definir autenticação de modo misto
Para obter instruções, confira Alterar o modo de autenticação do servidor.
Instale o SQL Server 2022 (16.x) no Linux. Para obter instruções, confira Diretrizes de instalação para o SQL Server no Linux. Habilitar
hadrcommssql-conf.Para habilitar
hadrpor meiomssql-confde um prompt de shell, emita o seguinte comando:sudo /opt/mssql/bin/mssql-conf set hadr.hadrenabled 1Depois de habilitar
hadr, reinicie a instância do SQL Server:sudo systemctl restart mssql-server.serviceConfigure o arquivo
hostsnos dois servidores ou registre os nomes de servidor no DNS.Abra portas de firewall para TPC 1433 e 5022 no Windows e no Linux.
Na réplica primária, crie um logon de banco de dados e uma senha.
CREATE LOGIN dbm_login WITH PASSWORD = '<password>'; CREATE USER dbm_user FOR LOGIN dbm_login; GOCuidado
Sua senha deve seguir a política de senha padrão do SQL Server. Por padrão, a senha precisa ter pelo menos oito caracteres e conter caracteres de três dos seguintes quatro conjuntos: letras maiúsculas, letras minúsculas, dígitos de base 10 e símbolos. As senhas podem ter até 128 caracteres. Use senhas longas e complexas.
Na réplica primária, crie uma chave mestra e um certificado e, em seguida, faça backup do certificado com uma chave privada.
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<master-key-password>'; CREATE CERTIFICATE dbm_certificate WITH SUBJECT = 'dbm'; BACKUP CERTIFICATE dbm_certificate TO FILE = 'C:\Program Files\Microsoft SQL Server\MSSQL16.MSSQLSERVER\MSSQL\DATA\dbm_certificate.cer' WITH PRIVATE KEY ( FILE = 'C:\Program Files\Microsoft SQL Server\MSSQL16.MSSQLSERVER\MSSQL\DATA\dbm_certificate.pvk', ENCRYPTION BY PASSWORD = '<private-key-password>' ); GOCuidado
Sua senha deve seguir a política de senha padrão do SQL Server. Por padrão, a senha precisa ter pelo menos oito caracteres e conter caracteres de três dos seguintes quatro conjuntos: letras maiúsculas, letras minúsculas, dígitos de base 10 e símbolos. As senhas podem ter até 128 caracteres. Use senhas longas e complexas.
Copie o certificado e a chave privada para o servidor Linux (réplica secundária) em
/var/opt/mssql/data. Você pode usar opscppara copiar os arquivos para o servidor Linux.Defina o grupo e a propriedade da chave privada e o certificado como
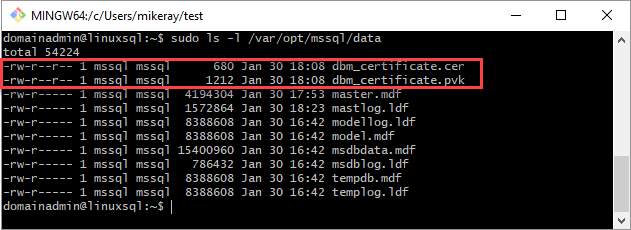
mssql:mssql.O script a seguir define o grupo e a propriedade dos arquivos.
sudo chown mssql:mssql /var/opt/mssql/data/dbm_certificate.pvk sudo chown mssql:mssql /var/opt/mssql/data/dbm_certificate.cerNo diagrama a seguir, a propriedade e o grupo são definidos corretamente para o certificado e a chave.
Na réplica secundária, crie um logon de banco de dados e uma senha e crie uma chave mestra.
CREATE LOGIN dbm_login WITH PASSWORD = '<password>'; CREATE USER dbm_user FOR LOGIN dbm_login; GO CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<master-key-password>'; GOCuidado
Sua senha deve seguir a política de senha padrão do SQL Server. Por padrão, a senha precisa ter pelo menos oito caracteres e conter caracteres de três dos seguintes quatro conjuntos: letras maiúsculas, letras minúsculas, dígitos de base 10 e símbolos. As senhas podem ter até 128 caracteres. Use senhas longas e complexas.
Na réplica secundária, restaure o certificado que você copiou para
/var/opt/mssql/data.CREATE CERTIFICATE dbm_certificate AUTHORIZATION dbm_user FROM FILE = '/var/opt/mssql/data/dbm_certificate.cer' WITH PRIVATE KEY ( FILE = '/var/opt/mssql/data/dbm_certificate.pvk', DECRYPTION BY PASSWORD = '<private-key-password>' ); GONo exemplo anterior, substitua
<private-key-password>pela mesma senha usada ao criar o certificado na réplica primária.Na réplica primária, crie um endpoint.
CREATE ENDPOINT [Hadr_endpoint] AS TCP ( LISTENER_IP = (0.0.0.0), LISTENER_PORT = 5022 ) FOR DATABASE_MIRRORING ( ROLE = ALL, AUTHENTICATION = CERTIFICATE dbm_certificate, ENCRYPTION = REQUIRED ALGORITHM AES ); ALTER ENDPOINT [Hadr_endpoint] STATE = STARTED; GRANT CONNECT ON ENDPOINT::[Hadr_endpoint] TO [dbm_login]; GOImportante
O firewall deve estar aberto para a porta TCP do ouvinte. No script anterior, a porta é 5022. Use qualquer porta TCP disponível.
Na réplica secundária, crie o endpoint. Repita o script anterior na réplica secundária para criar o endpoint.
Na réplica primária, crie o AG com
CLUSTER_TYPE = NONE. O script de exemplo usaSEEDING_MODE = AUTOMATICpara criar o AG.Observação
Quando a instância do SQL Server do Windows usa caminhos diferentes para arquivos de dados e de log, a propagação automática apresenta falha na instância do SQL Server do Linux porque esses caminhos não existem na réplica secundária. Para usar o script a seguir para um AG multiplataforma, o banco de dados requer o mesmo caminho para os arquivos de log e de dados no Windows Server. Como alternativa, você pode atualizar o script para definir
SEEDING_MODE = MANUALe, em seguida, fazer backup e restaurar o banco de dados comNORECOVERYpara propagar o banco de dados.Esse comportamento se aplica a imagens do Azure Marketplace.
Para saber mais sobre a propagação automática, confira Propagação Automática – Layout de Disco.
Antes de executar o script, atualize os valores para seus AGs.
Substitua
<WinSQLInstance>pelo nome do servidor da instância do SQL Server da réplica primária.Substitua
<LinuxSQLInstance>pelo nome do servidor da instância do SQL Server da réplica secundária.
Para criar o AG, atualize os valores e execute o script na réplica primária.
CREATE AVAILABILITY GROUP [ag1] WITH (CLUSTER_TYPE = NONE) FOR REPLICA ON N'<WinSQLInstance>' WITH ( ENDPOINT_URL = N'tcp://<WinSQLInstance>:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, SEEDING_MODE = AUTOMATIC, FAILOVER_MODE = MANUAL, SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL) ), N'<LinuxSQLInstance>' WITH ( ENDPOINT_URL = N'tcp://<LinuxSQLInstance>:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, SEEDING_MODE = AUTOMATIC, FAILOVER_MODE = MANUAL, SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL); );Para obter mais informações, confira CREATE AVAILABILITY GROUP.
Na réplica secundária, ingresse no GA.
ALTER AVAILABILITY GROUP [ag1] JOIN WITH (CLUSTER_TYPE = NONE); ALTER AVAILABILITY GROUP [ag1] GRANT CREATE ANY DATABASE; GOCrie um banco de dados para o AG. As etapas de exemplo usam um banco de dados chamado
TestDB. Se você estiver usando propagação automática, defina o mesmo caminho para os arquivos de dados e de log.Antes de executar o script, atualize os valores para seu banco de dados.
Substitua
TestDBpelo nome do seu banco de dados.Substitua
<F:\Path>pelo caminho do banco de dados e dos arquivos de log. Use o mesmo caminho para os arquivos de log e de banco de dados.
Você também pode usar os caminhos padrão.
Para criar seu banco de dados, execute o script.
CREATE DATABASE [TestDB] CONTAINMENT = NONE ON PRIMARY (NAME = N'TestDB', FILENAME = N'<F:\Path>\TestDB.mdf') LOG ON (NAME = N'TestDB_log', FILENAME = N'<F:\Path>\TestDB_log.ldf'); GOFaça um backup completo do banco de dados.
Se você não estiver usando a propagação automática, restaure o banco de dados no servidor de réplica secundária (Linux). Migrar um banco de dados do SQL Server do Windows para o Linux usando o recurso de backup e restauração. Restaure o banco de dados
WITH NORECOVERYna réplica secundária.Adicione o banco de dados ao AG. Atualize o script de exemplo. Substitua
TestDBpelo nome do seu banco de dados. Na réplica primária, execute a consulta T-SQL para adicionar o banco de dados ao AG.ALTER AG [ag1] ADD DATABASE TestDB; GOVerifique se o banco de dados está sendo preenchido na réplica secundária.

Fazer failover da réplica primária
Cada grupo de disponibilidade tem apenas uma réplica primária. A réplica primária permite leituras e gravações. Para alterar qual réplica é a primária, faça failover. Em um grupo de disponibilidade típico, o gerenciador de cluster automatiza o processo de failover. Em um grupo de disponibilidade com o tipo de cluster NONE, o processo de failover é manual.
Há duas maneiras de fazer failover da réplica primária em um grupo de disponibilidade com o tipo de cluster NONE:
- Um failover manual sem perda de dados
- Failover manual forçado com perda de dados
Failover manual sem perda de dados
Use esse método quando a réplica primária estiver disponível, mas você precisar alterar temporária ou permanentemente a instância que hospeda a réplica primária. Para evitar a perda potencial de dados, antes de emitir o failover manual, verifique se a réplica secundária de destino está atualizada.
Para fazer failover manualmente sem perda de dados:
Torne a réplica atual primária e a de destino secundária do
SYNCHRONOUS_COMMIT.ALTER AVAILABILITY GROUP [AGRScale] MODIFY REPLICA ON N'<node2>' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT);Para identificar que as transações ativas foram confirmadas na réplica primária e em pelo menos uma réplica secundária síncrona, execute a consulta a seguir:
SELECT ag.name, drs.database_id, drs.group_id, drs.replica_id, drs.synchronization_state_desc, ag.sequence_number FROM sys.dm_hadr_database_replica_states drs, sys.availability_groups ag WHERE drs.group_id = ag.group_id;A réplica secundária é sincronizada quando
synchronization_state_descéSYNCHRONIZED.Atualize
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMITpara 1.O script a seguir define
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMITcomo 1 em um grupo de disponibilidade chamadoag1. Antes de executar o script a seguir, substituaag1pelo nome do seu grupo de disponibilidade:ALTER AVAILABILITY GROUP [AGRScale] SET (REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT = 1);Essa configuração garante que todas as transações ativas são confirmadas na réplica primária e em, pelo menos, uma réplica secundária síncrona.
Observação
Essa configuração não é específica do failover e deve ser definida com base nos requisitos do ambiente.
Defina a réplica primária e as réplicas secundárias que não participam do failover offline para se prepararem para a alteração de função:
ALTER AVAILABILITY GROUP [AGRScale] OFFLINEPromova a réplica secundária de destino para a primária.
ALTER AVAILABILITY GROUP AGRScale FORCE_FAILOVER_ALLOW_DATA_LOSS;Atualize a função da réplica primária antiga e outras secundárias para
SECONDARYe execute o seguinte comando na instância do SQL Server que hospeda a réplica primária antiga:ALTER AVAILABILITY GROUP [AGRScale] SET (ROLE = SECONDARY);Observação
Para excluir um grupo de disponibilidade, use DROP AVAILABILITY GROUP. Para um grupo de disponibilidade criado com o tipo de cluster NONE ou EXTERNAL, execute o comando em todas as réplicas que fazem parte do grupo de disponibilidade.
Retome a movimentação de dados, execute o seguinte comando para cada banco de dado no grupo de disponibilidade da instância de SQL Server que hospeda a réplica primária:
ALTER DATABASE [db1] SET HADR RESUMECrie novamente qualquer ouvinte criado para fins de escala de leitura e que não seja gerenciado por um gerenciador de clusters. Se o listener original apontar para o antigo primário, descarte-o e crie-o novamente para apontar para o novo primário.
Failover manual forçado com perda de dados
Se a réplica primária não estiver disponível e não puder ser recuperada imediatamente, você precisará forçar um failover para a réplica secundária com perda de dados. No entanto, se a réplica primária original for recuperada após o failover, ela assumirá a função primária. Para evitar que cada réplica esteja em um estado diferente, remova a primária original do grupo de disponibilidade após um failover forçado com perda de dados. Quando a primária original voltar a ficar online, remova-a totalmente do grupo de disponibilidade.
Para forçar um failover manual com perda de dados da réplica primária N1 para a réplica secundária N2, siga estas etapas:
Na réplica secundária (N2), inicie o failover forçado:
ALTER AVAILABILITY GROUP [AGRScale] FORCE_FAILOVER_ALLOW_DATA_LOSS;Na nova réplica primária (N2), remova a primária original (N1):
ALTER AVAILABILITY GROUP [AGRScale] REMOVE REPLICA ON N'N1';Valide se todo o tráfego do aplicativo está direcionado para o listener e/ou para a nova réplica primária.
Se a primária original (N1) ficar online, coloque imediatamente o grupo de disponibilidade AGRScale offline na primária original (N1):
ALTER AVAILABILITY GROUP [AGRScale] OFFLINESe houver dados ou alterações não sincronizadas, preserve esses dados por meio de backups ou de outras opções de replicação de dados que atendam às suas necessidades de negócios.
Em seguida, remova o grupo de disponibilidade do servidor primário original (N1):
DROP AVAILABILITY GROUP [AGRScale];Exclua o banco de dados do grupo de disponibilidade na réplica primária original (N1):
USE [master] GO DROP DATABASE [AGDBRScale] GO(Opcional) Se desejar, agora você poderá adicionar a N1 de volta como uma nova réplica secundária ao grupo de disponibilidade AGRScale.
Este artigo revisou os passos para criar um Grupo de Disponibilidade (AG) multiplataforma, com o objetivo de dar suporte a cargas de trabalho de migração ou de escala de leitura. Ele pode ser usado para recuperação manual de desastres. Ele também explicou como fazer failover do AG. Um AG multiplataforma usa o tipo de cluster NONE e não dá suporte à alta disponibilidade.